






数组的定义
import math
import numpy as np
import random
from timeit import timeit
# 定义
arr = np.array([1, 2])
print(arr)
随机数组的生成
# rand
rand = np.random.rand(100, 100)
print(rand)
数组的形状
# 判断形状
print(rand.size)
print(rand.shape)
np的意义
np=1.1735659999999999, python=20.3648931
def np_log():
rand = np.random.rand(1000, 10000)
x = np.log(rand)
def python_log():
rand = []
for i in range(1000):
cur = []
for j in range(10000):
cur.append(random.random())
rand.append(cur)
for cur in rand:
# print(cur)
cur = [math.log(x) for x in cur]
# python_log()
# 定时
np_t = timeit('np_log()', 'from __main__ import np_log', number=10)
py_t = timeit('python_log()', 'from __main__ import python_log', number=10)
print(f"np={np_t}, python={py_t}")
def np_log():
rand = np.random.rand(1000, 1000)
x = np.log(rand)
def python_log():
rand = []
for i in range(1000):
cur = []
for j in range(1000):
cur.append(random.random())
rand.append(cur)
for cur in rand:
print(cur)
cur = [math.log(x) for x in cur]
# python_log()
# 定时
np_t = timeit('np_log()', 'from __main__ import np_log', number=10)
py_t = timeit('python_log()', 'from __main__ import python_log', number=10)
print(f"np={np_t}, python={py_t}")
视频地址
https://www.bilibili.com/video/BV1Wy4y1h7ii/?spm_id_from=333.337.search-card.all.click&vd_source=82dc2acb60a90c43a2ac0d4023a2cd34
定义数组的几种方式
import numpy as np
# 定义数组
a = np.array([1,3,4,5])
print(f"define arr {a}")
z_3_2 = np.zeros((3, 2)) # 3 第一位 也就是多少行 3行2列
print(f"z_3_2 is {z_3_2}")
ar = np.arange(2, 8) # 类似于 range
print(f"a range is {ar}")
ls = np.linspace(0, 1, 5)
print(f"linspace is {ls}")
rad = np.random.rand(2, 4)
print(f"rand is {rad}")
"""
define arr [1 3 4 5]
z_3_2 is [[0. 0.]
[0. 0.]
[0. 0.]]
a range is [2 3 4 5 6 7]
linspace is [0. 0.25 0.5 0.75 1. ]
rand is [[0.08905149 0.89795301 0.665294 0.93021576]
[0.84545149 0.70275937 0.4369173 0.17938872]]
"""
- array, 由python数组转过来
- zeros ones 注意传过来的是一个元组
- rand 注意传过来的是两个参数
- arange
- linspace
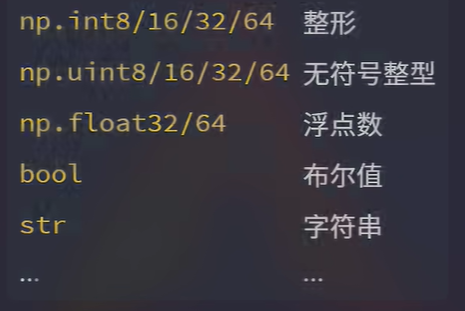
数据的类型
-
默认是np.float64
-
查看方式
a.dtype -
可以在定义的时候指定,
np.zeros((4, 2), dtype=np.int32) -
类型的转化
b = a.astype(int) -
常用类型
基本运算
-
同位置 ±*/
-
dot 点乘
-
np.sin cos, log power(a, 3), sqrt 每个元素
-
arr * 常数 广播
-
@ 矩阵乘法
a = np.array([[1, 2], [3, 4]]) b = np.array([[2, 0], [0, 2]]) print(f"a={a} \n b={b}") print(f"np.dot([1, 2], [1, 2]) {np.dot([1, 2], [1, 2])}") print(f"* multiply {a * b}") # 等同于 np.multiply(), 逐个元素运算 print(f"@ matmul {b @ a}") # 等同于 np.matmul() 矩阵乘法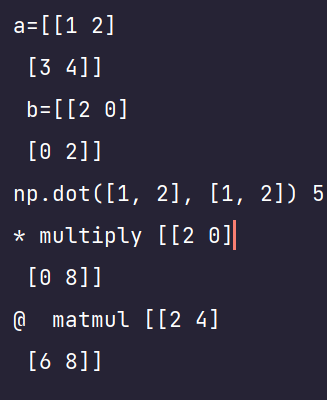
-
特殊的计算方式
-
乘以一个常数 — 广播
-
一个行矩阵可以和一个列矩阵直接相乘
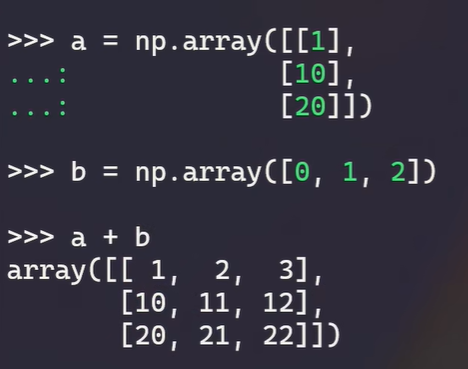
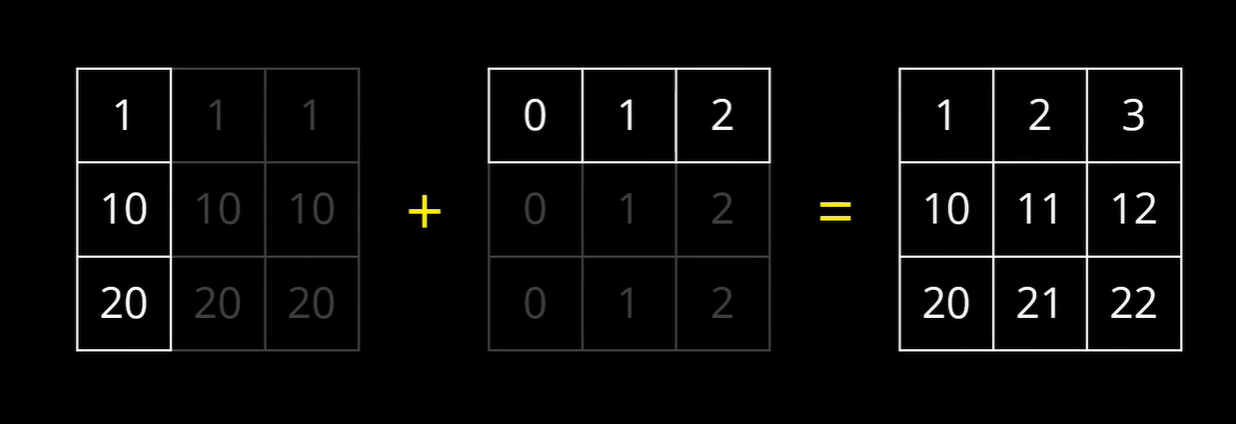
统计类的运算
-
np.max
-
np.argmax 索引
-
np.sum
-
np.mean
-
np.median
-
a.var() 方差
-
a.std() 标准差
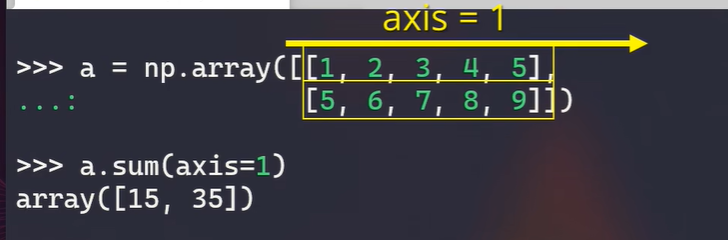
多维矩阵的统计 axis
-
axis = 0,表示沿着行的方向计算

-
axis = 1, 沿着列的方向计算
获取某个元素
a = np.array([[1, 2, 3,],
[2, 5, 6]])
a[0, 1] # 0 行 1列的元素
筛选元素
a = np.arange(10) # array([0, 1, 2 ....9])
a[a<3] # array([0, 1, 2])
a[ (a>3) & (a % 2 == 0)] # array([4, 6, 8]) 大于3而且是偶数
切片语法
第0行的前面两列元素。a[0, 0:2]
第一行 a[1, :] 或者 a[1]
切片 a[::-1]
numpy 处理图片
from PIL import Image
import numpy as np
i = Image.open('dog.jpg')
im = np.array(i)
# print(im)
print(im.shape)
print(im[100, 100])
im_r = im[:, :, 0]
# Image.fromarray(im_r).show() # 图片的显示
im_g = im[:, :, 1]
im_b = im[:, :, 2]
im_big = np.concatenate((im_r, im_g, im_b), axis=1) # 图片的拼接
# Image.fromarray(im_big).show()
im_blend = im_r * 0.4 + im_g * 0.6 # 图像的混合
im_blend = im_blend.astype(np.uint8)
# Image.fromarray(im_blend).show()
im_downsample = im[::2, ::2, :] # 降采样
# Image.fromarray(im_downsample).show()
im_flipped = im[::-1, :, :] # 翻转
Image.fromarray(im_flipped).show()
声音采集的例子
def get_wave_to_time(source_file_name, wave_one_pip_sample_count = 3000, should_plt = False, head_trim_time = 3, threhold = 0.07):
time, signal, fps = play_audio_with_py_av_lib(source_file_name, should_plt, threhold)
len = time.size
samples_exceeding_threshold = np.where(signal > threhold)[0]
filter_big_gap = np.diff(samples_exceeding_threshold) > wave_one_pip_sample_count
filter_big_gap = np.insert(filter_big_gap, 0, True)
samples_exceeding_threshold = samples_exceeding_threshold[filter_big_gap]
# samples_exceeding_threshold = samples_exceeding_threshold / fps
return time, signal, fps, time[samples_exceeding_threshold]
opencv 的例子
怎么应用:
https://stackoverflow.com/questions/47501249/implement-opencv-method-warpperspective
todo
import cv2
import numpy as np
img = cv2.imread("cards.jpg")
width,height = 250,350
pts1 = np.float32([[111,219],[287,188],[154,482],[352,440]])
pts2 = np.float32([[0,0],[width,0],[0,height],[width,height]])
def using_opencv():
matrix = cv2.getPerspectiveTransform(pts1, pts2)
print(matrix)
imgOutput = cv2.warpPerspective(img, matrix, (width, height))
# cv2.imshow("Image", img)
# cv2.imshow("Output", imgOutput)
# cv2.waitKey(0)
# https://blog.csdn.net/stf1065716904/article/details/92795238 根本的做法
# ndarry的 基本使用
def caculate(src, dst):
assert src.shape[0] == dst.shape[0] and src.shape[0] >= 4
nums = src.shape[0]
A = np.zeros((2 * nums, 8)) # A*warpMatrix=B
B = np.zeros((2 * nums, 1))
for i in range(0, nums):
A_i = src[i, :]
B_i = dst[i, :]
A[2 * i, :] = [A_i[0], A_i[1], 1,
0, 0, 0,
-A_i[0] * B_i[0], -A_i[1] * B_i[0]]
B[2 * i] = B_i[0]
A[2 * i + 1, :] = [0, 0, 0,
A_i[0], A_i[1], 1,
-A_i[0] * B_i[1], -A_i[1] * B_i[1]]
B[2 * i + 1] = B_i[1]
A = np.mat(A)
warpMatrix = A.I * B # 求出a_11, a_12, a_13, a_21, a_22, a_23, a_31, a_32
# 之后为结果的后处理
aa = np.array(warpMatrix)
# warpMatrix = aa.T[0]
warpMatrix = aa.reshape(-1)
warpMatrix = np.insert(warpMatrix, warpMatrix.shape[0], values=1.0, axis=0) # 插入a_33 = 1
warpMatrix = warpMatrix.reshape((3, 3))
print(warpMatrix)
return warpMatrix
using_opencv()
caculate(pts1, pts2)
[[ 1.51412424e+00 -2.47556434e-01 -1.13852931e+02]
[ 2.90344820e-01 1.64840930e+00 -3.93229912e+02]
[-4.56552320e-05 5.83742088e-04 1.00000000e+00]]
[[ 1.51412424e+00 -2.47556434e-01 -1.13852931e+02]
[ 2.90344820e-01 1.64840930e+00 -3.93229912e+02]
[-4.56552320e-05 5.83742088e-04 1.00000000e+00]]
numpy 书籍
https://www.labri.fr/perso/nrougier/from-python-to-numpy
从python 到numpy
python技巧
zen
import this
具体情况
fruit = [x for x in fruit if x.startswith("a")] # 列表解析式 在最开始 ,if 在最后面
# 7 字典的合并 ** 叫做解包
a = {"a":1, "b":2}
b = {"z":26, "y":25}
c = {**a, **b}
for index, x in enumerate(reversed(fruit)) # # 6 逆向遍历
for index, x, in enumerate(sorted(fruit)) # 6.2 排序
for index, x in enumerate(fruit): # 5 得到
x = "a" if a = 1 else "b" # 8
# 9 解包
name = "San zhang"
name, xing = name.split()
a, b = tuple
a, b = range(2)
a, b = b, a #1
f"a is {a}" #2
fruit = ["apple", "pear", "banana"]
fruit = [x.upper() for x in fruit] # 4,列表生成式 列表解析式

yield 具体例子
def fibonacci(n):
a = 0
b = 1
for _ in range(n):
yield a # 生成器,在for循环过程中得到一个值就可以返回回去
# 产出, return需要都做完再返回, yield中途可以返回
a, b = b, a+b
for i in fibonacci(10):
print(i)
线上的练习环境
http://repl.it














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









