









本篇博客展示了k_means算法的一种改进。通过在圆内随机产生待归类的数据集;为简单起见,我们把数据点散落到四个半径不一的圆盘内。因为是机器随机生成的点的分布很均匀。
首先是头文件:这里主要是bmp文件结构信息,因为我们要把分类的结果以图片的形式展示出来。
#ifndef K_MEANS_H
#define K_MEANS_H
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include<time.h>
#include<iostream>
using namespace std;
#define M_PI 3.1415926
typedef struct { double x, y; int group; } point_t, *point;
#define LENGTH_NAME_BMP 100//bmp图片文件名的最大长度
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned int DWORD;
typedef long LONG;
//位图文件头定义;
//其中不包含文件类型信息(由于结构体的内存结构决定,
//要是加了的话将不能正确读取文件信息)
typedef struct tagBITMAPFILEHEADER {
WORD bfType;//文件类型,必须是0x424D,即字符“BM”
DWORD bfSize;//文件大小
WORD bfReserved1;//保留字
WORD bfReserved2;//保留字
DWORD bfOffBits;//从文件头到实际位图数据的偏移字节数
}BITMAPFILEHEADER;
typedef struct tagBITMAPINFOHEADER {
DWORD biSize;//信息头大小
LONG biWidth;//图像宽度
LONG biHeight;//图像高度
WORD biPlanes;//位平面数,必须为1
WORD biBitCount;//每像素位数
DWORD biCompression; //压缩类型
DWORD biSizeImage; //压缩图像大小字节数
LONG biXPelsPerMeter; //水平分辨率
LONG biYPelsPerMeter; //垂直分辨率
DWORD biClrUsed; //位图实际用到的色彩数
DWORD biClrImportant; //本位图中重要的色彩数
}BITMAPINFOHEADER; //位图信息头定义
//本例没有用到调色板
typedef struct tagRGBQUAD {
BYTE rgbBlue; //该颜色的蓝色分量
BYTE rgbGreen; //该颜色的绿色分量
BYTE rgbRed; //该颜色的红色分量
BYTE rgbReserved; //保留值
}RGBQUAD;//调色板定义
//像素信息
typedef struct tagIMAGEDATA
{
BYTE red;
BYTE green;
BYTE blue;
}IMAGEDATA;
#endif
然后是随机生成待分类的数据集:
#pragma warning(disable:4996)
#pragma pack(2)//2字节对齐
#include"k_means.h"
double rand_range(double m)
{
return m * rand() / (RAND_MAX + 1.);
}
//产生count个点
point gen_point(int count, double radius)
{
double ang, r;
point p, pt =(point)malloc(sizeof(point_t) * count);
/* note: this is not a uniform 2-d distribution */
srand((unsigned int)time(NULL));
for (p = pt + count-1; p >=pt;p--){ //这里在四个圆内随机产生点
int c = (int)rand_range(4.0);
ang = rand_range(2 * M_PI);
double rd = radius*0.5;
switch (c){
case 0:
r = rand_range(radius*0.52);
p->x = r * cos(ang)+rd;
p->y = r * sin(ang)+rd;
break;
case 1:
r = rand_range(radius*0.45);
p->x = r * cos(ang) - rd;
p->y = r * sin(ang) + rd;
break;
case 2:
r = rand_range(radius*0.38);
p->x = r * cos(ang) - rd;
p->y = r * sin(ang) - rd;
break;
case 3:
r = rand_range(radius*0.46);
p->x = r * cos(ang) + rd;
p->y = r * sin(ang) - rd;
break;
}
}
return pt;
}第三k_means++算法对集合的初始质心的选择进行了优化。 步1,随机选择第一个质心cent[0];此时只有一个质心
步2,计算所有点到已求出质心的最短距离d[i],并求他们的总和sum;
步3,根据sum,与各个点的d[i]值,通过类似罗盘赌的方式,从点集当中选出一个点作为下一个质心;
步4,重复2、3两步,直到得到质心数量达到要分的类数。
inline double dist2(point a, point b)
{
double x = a->x - b->x, y = a->y - b->y;
return x*x + y*y;
}
inline int
classify(point pt, point cent, int n_cluster, double *d2)
{//给点pt归类
int i, min_i;
point c;
double d, min_d;
# define for_n for (c = cent, i = 0; i < n_cluster; i++, c++)
min_d = HUGE_VAL;
min_i = pt->group;
for_n{//查找与点pt最近的质点
if (min_d >(d = dist2(c, pt))) {
min_d = d; min_i = i;
}
}
if (d2) *d2 = min_d;//d2是地址,判断非空
return min_i;
}
void init_seed_classify(point pts, int len, point cent, int n_cent)
{
# define for_len for (j = 0, p = pts; j < len; j++, p++)
int j;
int n_cluster;
double sum, *d = (double *)malloc(sizeof(double) * len);
point p;
srand((unsigned)time(NULL));
cent[0] = pts[rand() % len];//随机选择第一个seed
for (n_cluster = 1; n_cluster < n_cent; n_cluster++) {//依次产生剩下的seed,\即各个初始类质心
sum = 0;
for_len{
classify(p, cent, n_cluster, d + j);
sum += d[j];
}
sum = rand_range(sum);
for_len{
if ((sum -= d[j]) > 0) continue;//类似于轮盘赌
cent[n_cluster] = pts[j];
break;
}
}
for_len p->group = classify(p, cent, n_cluster, 0); //初始分类
free(d);
}
void showBmp(point pts, int len, point cent, int n_cluster, int k)
{
// Define BMP Data Size
const int height = 1024;
const int width = 1024;
const int size = height * width * sizeof(IMAGEDATA);
BITMAPFILEHEADER FileHead;
BITMAPINFOHEADER InfoHead;
BYTE red, blue, green;
int i, j, pix, piy;
int shift = 512;
point p, c;
char buf[LENGTH_NAME_BMP];
//Create Bitmap File Header
FileHead.bfType = 0x4D42;
FileHead.bfReserved1 = 0;
FileHead.bfReserved2 = 0;
FileHead.bfSize = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + size;
FileHead.bfOffBits = sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER);
//Create Bitmap Info Header
InfoHead.biSize = sizeof(BITMAPINFOHEADER);
InfoHead.biHeight = height;
InfoHead.biWidth = width;
InfoHead.biPlanes = 1;
InfoHead.biBitCount = 24;
InfoHead.biSizeImage = size;
InfoHead.biCompression = 0; //BI_RGB
InfoHead.biXPelsPerMeter = 1024;
InfoHead.biYPelsPerMeter = 1024;
InfoHead.biClrUsed = 0;
InfoHead.biClrImportant = 0;
// Create bmp Data
IMAGEDATA *bits = (IMAGEDATA *)malloc(size);
// white board
memset(bits, 0xFF, size);
for_len{
pix = (int)(p->x * 20) + shift;
piy = (int)(p->y * 20) + shift;
switch (p->group) {
case 0:
red = 255;
blue = 0;
green = 0;
break;
case 1:
red = 0;
blue = 255;
green = 0;
break;
case 2:
red = 0;
blue = 0;
green = 255;
break;
case 3:
red = 255;
blue = 255;
green = 0;
}
bits[piy * width + pix].red = red;
bits[piy * width + pix].blue = blue;
bits[piy * width + pix].green = green;
}
for_n{//质心黑色显示
pix = (int)(c->x * 20) + shift;
piy = (int)(c->y * 20) + shift;
bits[piy * width + pix].red = 0;
bits[piy * width + pix].blue = 0;
bits[piy * width + pix].green = 0;
}
// Write to file
sprintf(buf, "%d_%s", k, "result.bmp");
FILE *output = fopen(buf, "wb");
if (output == NULL)
{
cout << "Cannot open file!\n";
}
else
{
fwrite(&FileHead, sizeof(BITMAPFILEHEADER), 1, output);
fwrite(&InfoHead, sizeof(BITMAPINFOHEADER), 1, output);
fwrite(bits, size, 1, output);
fclose(output);
}
}
point k_means(point pts, int len, int n_cluster)
{
int i, j,k, min_i;
int changed;
point p,c;
point cent =(point)malloc(sizeof(point_t) * n_cluster);
/* assign init grouping randomly */
//for_len p->group = j % n_cluster;//一般初始化
/* or call k++ init */
init_seed_classify(pts, len, cent, n_cluster);//k-means++初始化
k = 0;
do {//标准的k-means聚类算法
/* group element for centroids are used as counters */
for_n{ c->group = 0; c->x = c->y = 0; }
for_len{
c = cent + p->group;//p->group所在类的质心
c->group++;//计数
c->x += p->x; c->y += p->y;
}
for_n{ c->x /= c->group; c->y /= c->group; }//各个类的所有点的纵/横坐标的平均值作为新质心
changed = 0;
/* find closest centroid of each point */
for_len{
min_i = classify(p, cent, n_cluster, 0);
if (min_i != p->group) {
changed++;
p->group = min_i;
}
}
showBmp(pts,len,cent,n_cluster,k);
cout << "第" << k << "次迭代完成" << endl;
k++;
} while (changed > (len >> 10)); /* stop when 99.9% of points are good */
for_n{ c->group = i; }
return cent;
}
#define PTS 100000
#define K 4
int main()
{
srand((unsigned int)time(NULL));
point v = gen_point(PTS, 20);//点集个数PTS个,分布在以原点为圆心,10为半径的园内
point c = k_means(v, PTS, K);//分成K个类
system("pause");
return 0;
}第一次迭代 迭代2 迭代3 迭代4
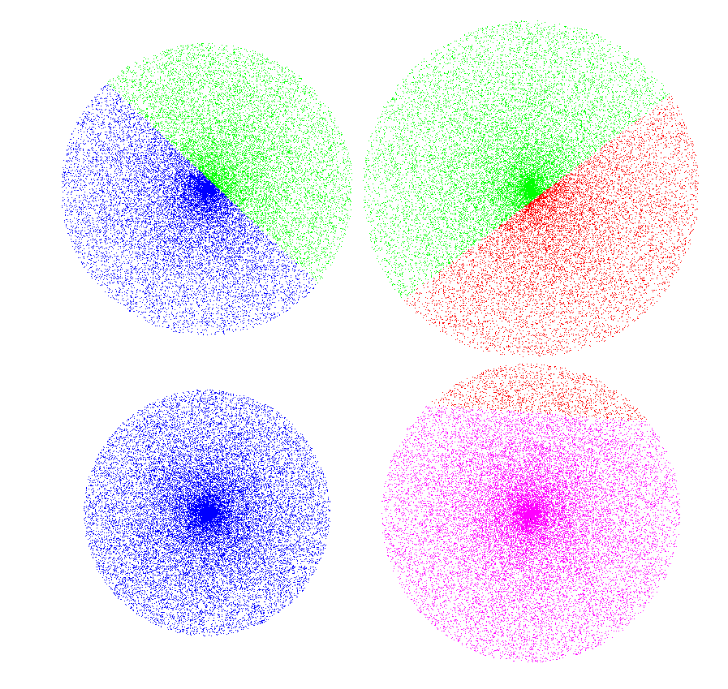
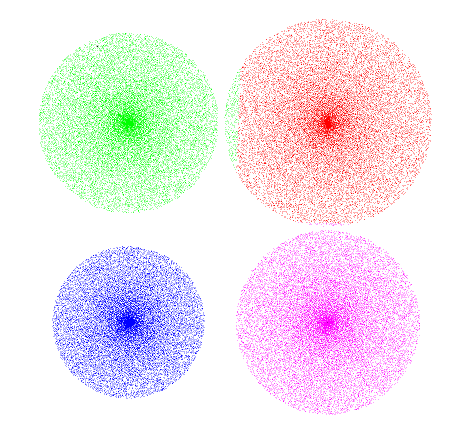

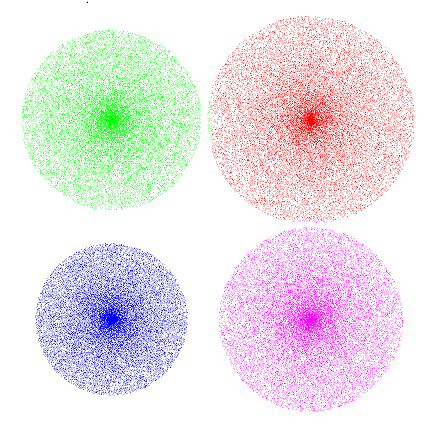















 8751
8751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









