






题目1 : 打印一个字符串的全部子序列
题目分析:
解法1:非递归方法
我们通过一个实例来理解题意,假设字符串str = “abc”,那么它的子序列都有那些呢?" ", “a”, “b”,“ab”,"c","ac","bc","abc", 一共8个,其中有一个是空串。怎么得到这个结果的?我的眼就是尺,看一眼就知道了。但如果这个字符串的长度是10呢,30呢?看一眼怎么够!除了多看几眼,是不是也要找个纸、笔写写画画呢?
第一笔: a 的存在情况有两种:存在 或 不存在;

第二笔: b 的存在情况有两种:存在 或 不存在;
第三笔: c 的存在情况有两种:存在 或 不存在;
这三笔当然不能各自为营的画在纸上,第二笔和第三笔是在前一笔的基础上画出的。
第二笔:画出b的情况
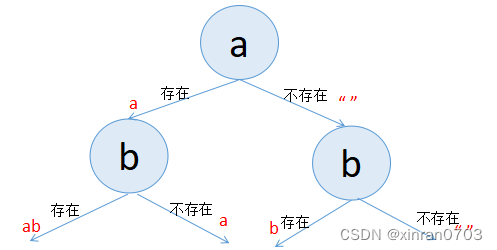
第三笔:画出c的情况

现在,通过上图我们得到了子字符串的所有结果,"abc","ab","ac","a","bc","b","c","", 如果字符串str = "abcd",我们也有思路落下第四笔,即在'c' 的下方,给每一个字符串补充上d的存在与不存在这两个情况,于此同时,我们也总结出了计算子字符串的规律:
1. 从原字符串str 的index== 0 开始遍历字符串,直到index == 原字符串长度 结束。 (即:‘a’‘c’)
2. 当index == i 时, str[i] 的两种情况(存在或不存在)是添加到index == i-1 所得出的子串基础上的,这一条规律也是迭代的关键。
代码实现
//代码段1
#include <string>
#include <List>
using std::string;
using std::list;
class SubStr {
public:
void process_1(string strPre, list<string>& ans);
};
void SubStr::process_1(string strPre,list<string>& ans) {
if (strPre.length() < 1) return;
string str = "";
str = str + strPre[0];
ans.push_back(str);
ans.push_back("");
for (size_t j = 1; j < strPre.length(); j++) {
int count = ans.size();
for (list<string>::iterator item = ans.begin(); item != ans.end(); item++) {
ans.push_back(*item + strPre[j]);
count--;
if (!count)break;
}
}
return;
}
#define SUBSTR
int main() {
#ifdef SUBSTR
SubStr subStrObj;
string str = "abc";
list<string> ans;
subStrObj.process_1(str, ans);
for (list<string>::iterator item = ans.begin(); item != ans.end(); item++) {
std::cout << *item << std::endl;
}
#endif
return 0;
}运行结果

解法2:递归方法
在解法1中我们已经明白了子序列的含义,也明白了对于字符串str上任意位置上的字符str[i] 在子序列中都有两种可能性,即存在与不存在。假设 str = “abc”, 初始状态就是str[0~2] 字符都不存在的状态,即空串。
我们用枚举的方式,找到所有可能性,见表1.
我们给出的初始状态是各位都不存在,那么对于str[2] 来说,str[0~1] 不存在是确定的,是不可更改的事实,但是str[2]可选择,可以是不存在,例如子序列1;也可以是存在,例如子序列2.
到此,在str[0~1]不存在的条件下,所有的可能性都找到了:ans = {“”, “c”}
继续枚举,str[0]不存在,str[1]存在的条件下,str[2] 的可能性?见子序列3 和 子序列4.
ans = {"", "c", "b", "bc"};
继续枚举,str[0]存在,其后str[1~2] 的各种可能性:子序列5 ~ 子序列8;
ans={"", "c", "b", "bc", "a", "ac","ab","abc"}
表二中给出了当字符串的长度增加的枚举情况,str= "abcd";
| 表1 | ||||
| 子序列 | a | b | c | 子序列值 |
| 1 | " " | |||
| 2 | c | |||
| 3 | b | |||
| 4 | bc | |||
| 5 | a | |||
| 6 | ac | |||
| 7 | ab | |||
| 8 | abc | |||
| 表2 | |||||
| 子序列 | a | b | c | d | 子序列值 |
| 1 | " " | ||||
| 2 | d | ||||
| 3 | c | ||||
| 4 | cd | ||||
| 5 | b | ||||
| 6 | bc | ||||
| 7 | bc | ||||
| 8 | bcd | ||||
| 9 | a | ||||
| 10 | ad | ||||
| 11 | ac | ||||
| 12 | acd | ||||
| 13 | ab | ||||
| 14 | abc | ||||
| 15 | abc | ||||
| 16 | abcd | ||||
通过两个表的枚举情况,我们可以得出这样的结论:
1. 每一个子串都隐含了各个字符的存在情况,比如表2中的子序列3 == ”c“, 其实用真值表值来表示的话,它就是0010, 第3位为1,表示c存在,其他位为0,表示不存在,也就是说我们遍历,产生子序列的时候,是对原字符串的每个字符都会遍历到的,只是选择它在子序列中存在或不存在。
2. 当遍历到第i位时, 我们认为 0 ~ i-1 位的情况是已经确定的,第i位以及其后面的各位的情况是有待枚举的。例如表2中子序列13~ 16, str[0~1] 已经确定,即存在,枚举出str[2~3] 的所有情况。
代码实现
//代码段2
#include <string>
#include <List>
using std::string;
using std::list;
class SubStr {
public:
void process_2(string strPre, int index, list<string>& ans, string path);
};
/*
strPre: 原字符串
index:表示字符串的下标,即位置,当然来到了strPre[index];
ans:存放子序列
path:strPre[0~index-1] 的字符情况
*/
void SubStr::process_2(string strPre, int index, list<string>& ans, string path) {
if (index == strPre.length()){ //已经遍历完了整个路径,即strPre[0 ~ strPer.length()-1]都遍历了,确定了各位的存在与否, 将这个路径存入结构体
ans.push_back(path);
return;
}
process_2(strPre, index + 1, ans, path); // 此子序列中strPre[index]不存在,即没有要strPre[index]字符
process_2(strPre, index + 1, ans, path + strPre[index]);// 此子序列中strPre[index]存在,即要了strPre[index]字符
}
#define SUBSTR
int main() {
#ifdef SUBSTR
string str = "abc";
list<string> ans;
string path = "";
SubStr subStrObj;
subStrObj.process_2(str, 0, ans, path);
std::cout << "子序列的数量是:" << ans.size() << std::endl;
int count = 0;
for (list<string>::iterator item = ans.begin(); item != ans.end(); item++) {
std::cout <<"sub string " << ++count << ": "<< * item << std::endl;
}
#endif
return 0;
}运行结果:
表1:

表2:

小技巧:
代码中使用了STL容器来存放结果ans, 但是为什么使用list 而不是vector呢?在编写代码时具体使用什么数据结构,需要根据实际的数据类型、数据规模以及其对数据所要执行的操作特点来决定。
vector具有连续的内存空间,支持随机访问,如果需要高效的随机访问,而很少使用插入和删除的操作,使用vector
list 具有一段不连续的内存空间,如果需要高频次的插入和删除操作,较少执行随机存取,使用list。
本题目的场景更适合使用list。
补充问题:打印一个字符串的全部子序列,要求不出现重复子序列。
问题分析:
这个问题可以分两个思路来解决:
1. 使用代码段2中的函数process_2 找到所有的子序列,在打印时做去重处理;
2. 定义函数precess_3, 函数实现思路与process_2一样,只是用于存放子序列的数据结构由list改为set, 因为set 不存放相同的数据元素。
我们完成process_3 的代码实现。
代码实现:
//代码段3
#include <string>
#include <List>
#include <set>
using std::string;
using std::list;
using std::set;
class SubStr {
public:
void process_3(string strPre, int index, set<string>& ans, string path);
};
/*
strPre: 原字符串
index:表示字符串的下标,即位置,当然来到了strPre[index];
ans:存放子序列
path:strPre[0~index-1] 的字符情况
*/
void SubStr::process_3(string strPre, int index, list<string>& ans, string path) {
if (index == strPre.length()){ //已经遍历完了整个路径,即strPre[0 ~ strPer.length()-1]都遍历了,确定了各位的存在与否, 将这个路径存入结构体
ans.insert(path);
return;
}
process_3(strPre, index + 1, ans, path); // 此子序列中strPre[index]不存在,即没有要strPre[index]字符
process_3(strPre, index + 1, ans, path + strPre[index]);// 此子序列中strPre[index]存在,即要了strPre[index]字符
}
#define SUBSTR
int main() {
#ifdef SUBSTR
string str = "abcc";
set<string> ans;
string path = "";
SubStr subStrObj;
subStrObj.process_3(str, 0, ans, path);
for (list<string>::iterator item = ans.begin(); item != ans.end(); item++) {
std::cout << *item << std::endl;
}
#endif
return 0;
}运行结果:

如果用代码段2(没有去重功能)打印str="abcc" 的子序列:

















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











