






背景
细粒度图像识别是图像分类中的一个颇具挑战性的任务,它的目标是在一个大类中的众多子类中正确的识别目标。但是相同子类中物体的动作和姿态步态可能相同,不同子类间又有可能有着相同的姿态,这是识别的一大难点。
总的来说,细粒度图像分类是寻找一些细微差别的局部区域,并利用这些局部区域的特性对原图进行分类。当然,如何有效的对前景对象进行检测,并从中发现重要的局部区域信息,成为了细粒度图像分类算法要结局的关键问题。
对于细粒度图像模型,可以按照其使用的监督信息的强弱,分为“基于强监督信息的分类模型“和“基于弱监督信息的分类模型“两大类
基于强监督信息的细粒度图像分类模型
思想:
为了获得更好的分类精度,除了图像的类别标签外,还使用了物体的标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,这些标注信息主要包括物体的前景图片和物体本身重要区别部位的标注。
———-
处理流程举例:
一、
利用Selective Search 算法在细粒度图像上产生物体或者物体部位可能出现的候选框(Object Proposal)
二 、
按照R-CNN的流程进行物体检测,借助细粒度图像中的Object Bounding Box 和 Part Annotation 可以训练处3 个检测模型:一个对应细粒度物体级别的检测;一个对应物体头部检测,另一个对应物体的身体躯干的检测。
这里先介绍一下R-CNN的算法流程
RCNN算法分为4个步骤
- 一张图像生成1K~2K个候选区域
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM 分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
R-CNN候选区域生成
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。基本思路如下:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
-
候选区域生成和后续步骤相对独立,实际可以使用任意算法进行
R-CNN合并规则
优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在其BBOX中所占比例大的
合并后的区域特征可以直接由子区域特征计算而来,速度较快。
特征提取
R-CNN预处理
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。
此处有一些细节可做变化:外扩的尺寸大小,形变时是否保持原比例,对框外区域直接截取还是补灰。会轻微影响性能。
R-CNN预训练
网络结构
基本借鉴Hinton 2012年在Image Net上的分类网络2,略作简化3。
这里写图片描述
此网络提取的特征为4096维,之后送入一个4096->1000的全连接(fc)层进行分类。
学习率0.01。
R-CNN训练数据
使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号。
R-CNN调优训练
网络结构如下:
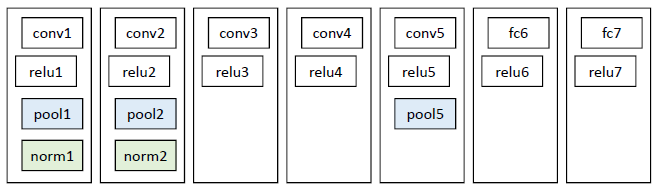
同样使用上述网络,最后一层换成4096->21的全连接网络。
学习率0.001,每一个batch包含32个正样本(属于20类)和96个背景。
R-CNN训练数据
使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
考察一个候选框和当前图像上所有标定框重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
R-CNN类别判断
分类器
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的4096维特征,输出是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本
本类的真值标定框。
负样本
考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
R-CNN位置精修
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。
回归器
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
三、
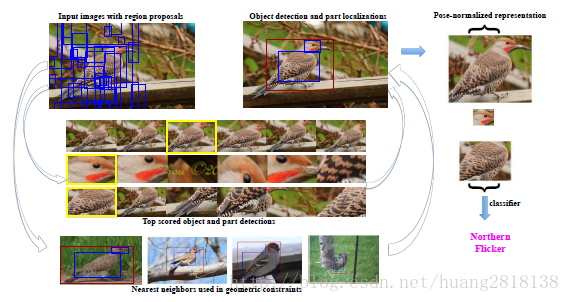
以上是R-CNN的进本流程,现在我们接着来讲基于强监督信息的细粒度图像分类模型**处理流程的第三步:
对三个检测模型得到的检测框加上几何位置的约束,如图:**















 2869
2869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









