






- 正文前感谢昇腾各位工作人员,没有你们的辛勤就没有我们的进步
- 本文立意交流大赛ScatterSub算子编译过程
- 这道题难点在于
- 如何划分tiling,是以哪个输入变量shape作为划分的标准,从而获得相对应tileLength
- 如何设计copy_in来满足对var数据的sub操作,是否需要对var数据进行读入
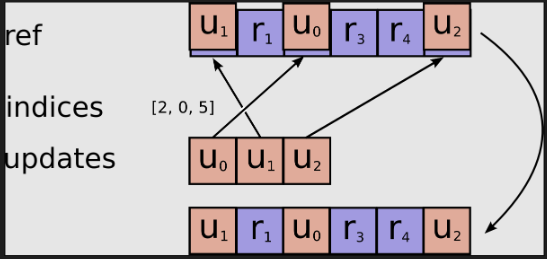
- 参考了0xcccccccc大神的代码,只能用一个字来形容,妙呀,短小精悍
- 对原子操作SetAtomicAdd有独到见解
- 对copy_in数据流设计不需要引入var,并修改var,通过datacopy将updates数据施加原子加法操作,导入Indices指定位置
- 参考了blankcat代码
- 比较喜欢DataCopyPadCustom_GM2UB,DataCopyPadCustom_UB2GM 两个API构建
- gen_data.py的设计
- 开发板并不兼容tensorflow.自行编译步骤繁琐,而且真的太耗费编译时间。个人尝试编译1天1夜也无功而返
- 使用电脑进行同代码生成数据时,发现导出数据错误,input_var 与golden出现数据偏差
- 所以只能自行改写gen_data.py,摒弃tensorflow操作,使用pytorch进行数据的生成与导出
import torch
import numpy as np
def is_integer_dto(dtype):
return dtype in [torch.int8, torch.int16, torch.int32, torch.int64]
def is_float_dto(dtype):
return dtype in [torch.float16, torch.float32, torch.float64]
def gen_golden_data_simple2():
dtype = torch.float32
if(is_float_dto(dtype)):
var = torch.randn(1024* 1024).reshape(1024, 1024).to(dtype)*20-10
indices = torch.randint(0, 1023, (1024,)).to(torch.int64)
updates = torch.randn(1024* 1024).reshape(1024, 1024).to(dtype)*20-10
else:
var = torch.randint(-10, 10, (3, 41, 52, 63)).to(dtype)
indices = torch.randint(0, 3, (3,)).to(torch.int64)
updates = torch.randint(-10, 10, (3, 41, 52, 63)).to(dtype)
golden = var.clone()
for i in range(indices.size(0)):
index = indices[i]
golden[index] = golden[index] - updates[i]
var.to(dtype).detach().cpu().numpy().tofile("./input/input_var.bin")
indices.to(torch.int32).detach().cpu().numpy().tofile("./input/input_indices.bin")
updates.to(dtype).detach().cpu().numpy().tofile("./input/input_updates.bin")
golden.to(dtype).detach().cpu().numpy().tofile("./output/golden.bin")
if __name__ == "__main__":
gen_golden_data_simple2()
复制- SetAtomicAdd操作如下
__aicore__ inline void CopyOut(int32_t indices,int32_t j,int32_t progress) {
LocalTensor<DTYPE_VAR> varLocal = outQueueVar.DeQue<DTYPE_VAR>();
SetAtomicAdd<DTYPE_VAR>();
if (progress == this->tileNum - 1) {
if (progress == 0) {
//如果只有一包,则搬运的起始地址为0,tileLength为实际分块的数据量
DataCopy(varGm[indices * this->lastdim ], varLocal, this->tileLength);
} else {
//将最后一个分块的起始地址向前移动tileLength-lasttileLength
DataCopy(varGm[indices * this->lastdim + (progress - 1) * this->tileLength + this->lasttileLength], varLocal, this->tileLength);
}
} else {
DataCopy(varGm[indices * this->lastdim + progress * this->tileLength], varLocal, this->tileLength);
}
SetAtomicNone();
outQueueVar.FreeTensor(varLocal);
}复制- 通过DataCopyPadCustom_GM2UB进行数据搬迁,注意单包情况
- 实际需要传输的是dimLength,其余都置0
__aicore__ inline void CopyIn(int32_t indices, int32_t j,int32_t progress) {
LocalTensor<DTYPE_UPDATES> updatesLocal = inQueueUpdates.AllocTensor<DTYPE_UPDATES>();
if (progress == this->tileNum - 1) {
if (progress == 0) {
DataCopyPadCustom_GM2UB(updatesLocal,updatesGm[j * this->lastdim],this->dimLength);
for(int i = this->dimLength; i < this->tileLength; i++)
{
updatesLocal(i) = static_cast<DTYPE_UPDATES>(0);
}
} else {
DataCopy(updatesLocal[0], updatesGm[j * this->lastdim + (progress - 1) * this->tileLength + this->lasttileLength], this->tileLength);
}
} else {
DataCopy(updatesLocal[0], updatesGm[j * this->lastdim + progress * this->tileLength], this->tileLength);
}
inQueueUpdates.EnQue(updatesLocal);
}复制-
所谓的this->dimLength = lastdim/GetBlockNum();
-
lastdim为所有非0轴的其他轴shape,也就是乘积,以此为tiling分割
-
最终贴出测试结果
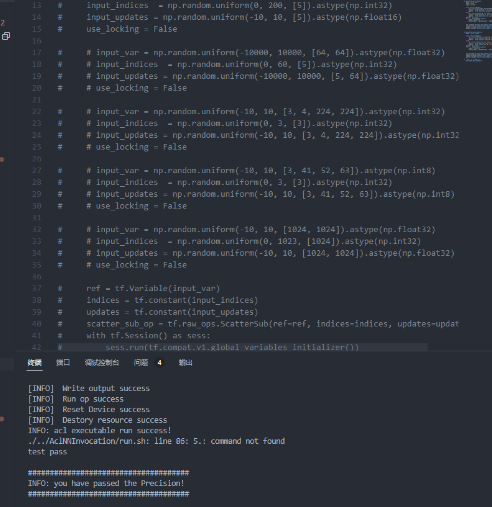
- 第一个测试案例
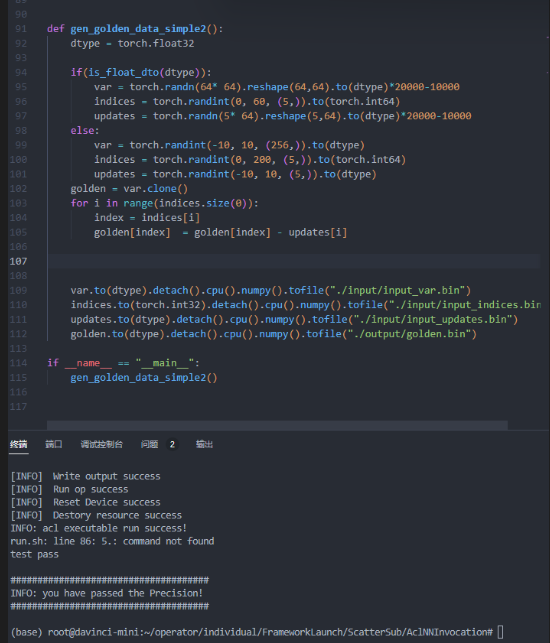
- 第二个测试案例
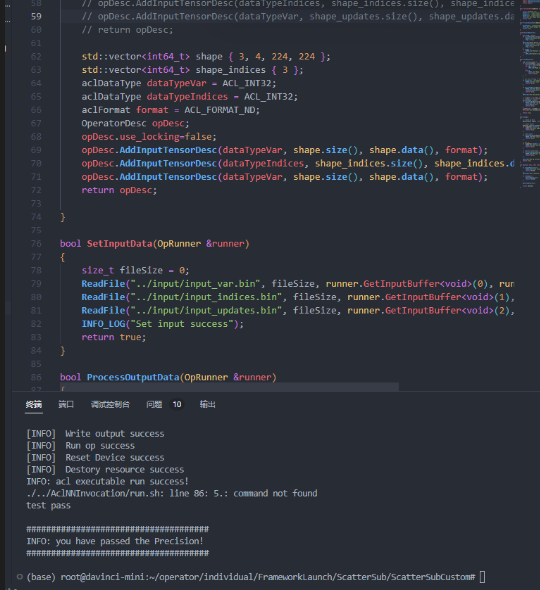
- 第三个测试案例
- 第四个测试案例
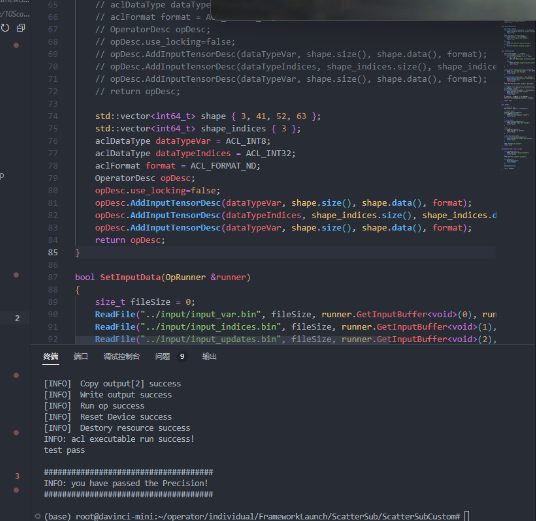
- 第五个测试案例
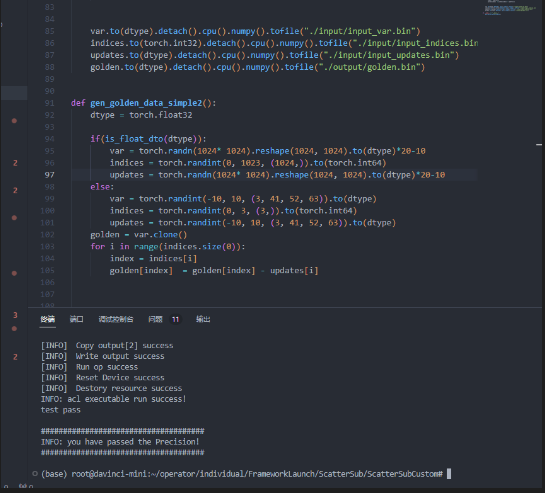















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









