






还记得前段时间刷屏朋友圈的Sora吗?它将生成视频的时长从几秒惊人地延长到前所未有的整整一分钟,惊艳了AI视频圈,不少人预言AI生成长达数小时的电影也指日可待。
这不,浙江大学带着MovieDreamer走来了,再次刷新了视频生成的极限,将时长推向了小时级。MovieDreamer不仅可以塑造鲜活生动的角色,编织出连贯流畅的故事线,在画面上精雕细琢,每一帧的细节更是拉满。
先来欣赏一下MovieDreamer生成的大作:
下图是MovieDreamer生成的泰坦尼克号的场景,非常逼真。且人物的面部、发型等在长时间内保持统一,这对生成自然逼真的长视频非常重要。

再来看看生成的视频demo:
,时长01:11
,时长01:03
,时长01:07
整个视频从画面到人物造型,都展现出了惊人的连贯性和协调性,叙事结构和情节进展复杂精细,虽然动态的面部表情仍略显僵硬,但瑕不掩瑜,这让我们对未来AI电影进一步发展充满了信心~
更多更长的视频详见:
https://aim-uofa.github.io/MovieDreamer/
论文标题:
MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequences
论文链接:
https://arxiv.org/pdf/2407.16655

框架
本文提出了一个专门用来制作更长的视频的新颖框架,巧妙融合了自回归模型在时间连贯性上的长处与扩散模型在图像渲染质量上的优势。先来速览一下该框架的大致流程:
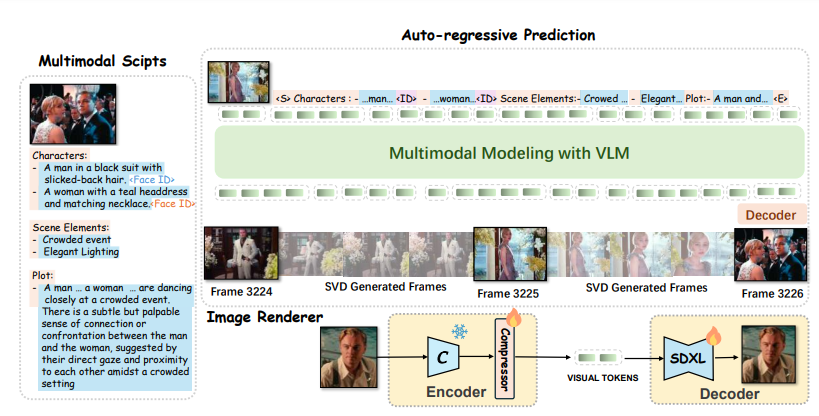
该框架以多模态脚本为条件,通过自回归方式预测关键帧的tokens,随后以这些关键帧为基准,生成完整的视频内容。
不仅能够实现zero-shot视频生成;还能在给定样本条件下,创作出符合特定风格的视频作品。该框架在多模态脚本构思、自回归预测训练以及扩散渲染技术的各个环节中,均不遗余力地维护和强化了角色身份的一致性与情节发展的连贯性。
1. 通过扩散自编码器作关键帧标记
为了创建简洁且准确的图像表示,此处采用了扩散自编码器。编码器集成了预训练的CLIP视觉模型和Transformer Token压缩器,将图像编码为压缩后的Token 。随后,解码器利用这些Token,结合预训练的SDXL扩散模型,重建出分辨率为的高质量图像。在解码过程中,潜在图像Token通过交叉注意力机制融入扩散解码器,以增强重建效果。
训练过程仅优化压缩器和解码器,保持 CLIP 视觉模型不变。扩散自编码器的训练损失公式为:
![]()
后续实验表明,仅用两个token就能充分表征关键帧的主要语义。
2. 自回归关键帧Token生成
本文采用LLaMA2-7B构建了自回归模型。与传统的 LLMs 不同,它根据多模态脚本和历史信息预测连续的视觉令tokens,表示为: 。
鉴于传统LLMs使用交叉熵损失只能处理离散输出,本文的模型处理的是连续图像token,作者引入了k-混合高斯混合模型(GMM)来建模Tokens的分布,通过2kd个均值、方差和k个混合系数参数化GMM。
模型训练时,最小化负对数似然损失,以优化token预测的准确性。
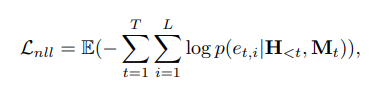
同时,为简化连续token的学习,我们额外引入了预测token和真实token之间的 和 损失:
![]()
对抗过拟合
面对高质量长视频数据稀缺的挑战,本文还采取了多种策略来防止过拟合,提升模型的泛化能力:
-
数据增强:通过随机水平翻转视频和逆转视频帧顺序,增加训练数据的多样性。
-
面部嵌入随机化:随机选择同一角色的不同面部嵌入,避免模型仅依赖面部信息记忆训练帧。
-
高dropout率:采用50%的dropout率,增强模型从有限数据中学习的泛化能力。
-
Token masking:在因果注意掩码中随机mask部分输入token,迫使模型通过上下文推断缺失信息,进一步提升其泛化性能。
专为自回归模型设计的结构化的多模态脚本
本文转为自回归模型设计了一种结构化的多模态脚本,如下图所示,它融合了角色、场景元素和故事弧线等多个维度。鉴于纯文本难以全面刻画角色外观,还结合了文本描述与面部嵌入,为角色提供更为详尽的呈现。
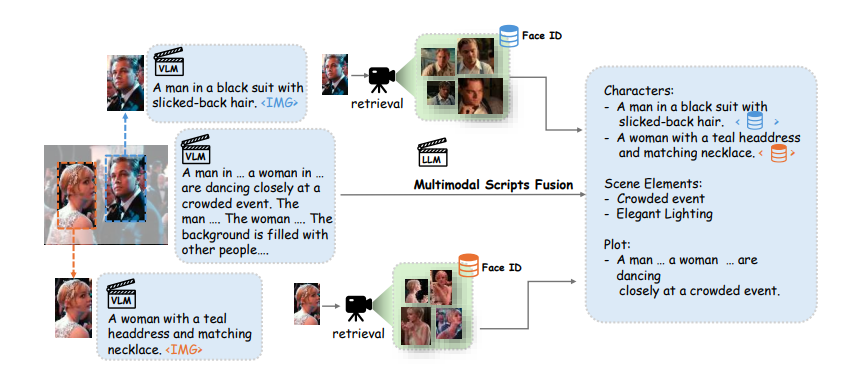
对于非文本模态(如面部嵌入和压缩token),利用多层感知器将其映射至LLaMA的嵌入空间,以实现无缝整合。
针对文本数据中长序列导致的token空间消耗问题,将文本分为“标识符”与“描述符”两种模态。标识符用于构建脚本框架,而描述符则承载详细属性描述。每个描述符通过CLIP编码为单个[CLS],并映射至统一输入空间,此举极大地拓展了训练时的上下文容量。然后采用LongCLIP作为描述符的文本编码器,支持高达248Token的输入,显著增强了处理复杂叙事内容的能力。
因此,时间步 处的多模态脚本和之前的历史数据表示为:
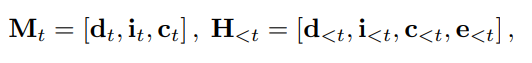
其中, 分别表示描述符、标识符和角色面部嵌入的嵌入,$e_{<t}$ 表示之前预测的压缩帧token。负对数似然损失公式为:<="" p="">
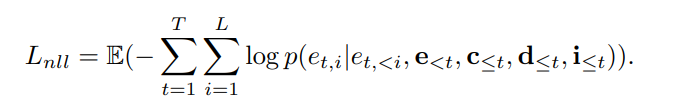
个性化生成的few-shot训练
为推进个性化电影内容的创作,还引入了基于上下文学习的few-shot学习方法。训练阶段,随机抽取每集内容的10个帧,编码为视觉Token,并巧妙地将这些token融入该集的视觉token序列中。
此策略不仅增强了模型的上下文理解能力,使之能依据参考帧定制内容,还作为有效的数据增强手段,减轻了过拟合问题。
3. 强化ID保持的扩散渲染
尽管本文的主要扩散解码器擅长重建目标图像,但由于压缩token导致了部分细节损失。为此,作者强化了内的交叉注意力模块,集成了多模态脚本中的描述性文本嵌入和面部嵌入。
为进一步提升模型对关键细节的关注度,还实施了随机掩码策略,选择性遮蔽部分输入token,激励解码器更加依赖面部和文本线索,以更高精度重建图像,特别是在保持身份特征上。
4. 基于关键帧的视频生成
在获取电影中的关键帧后,我们可以基于这些关键帧生成电影的视频片段。为了生成更长的电影片段,作者提出了一种简单而有效的方案:在视频扩展过程中始终使用第一帧的特征作为“锚点”,以增强模型对原始图像分布的感知能力。在实际操作中,在生成后续视频时,使用原始输入图像的CLIP特征,而不是先前视频的最后一帧,来进行交叉注意力交互。
实验
故事生成质量:

作者将MovieDreamer生成的结果与那些展现出高泛化能力的方法进行比较,如上图所示,其他方法的一致性较差。比如StoryDiffusion生成的角色发型不一致,且第77个关键帧中的角色与第968个关键帧中的角色不一致。StoryGen甚至生成了异常结果。
相比之下,本文方法能够在保持多个角色之间短期和长期一致性的同时,生成极长的内容。下表中的量化结果也证实了这一点:
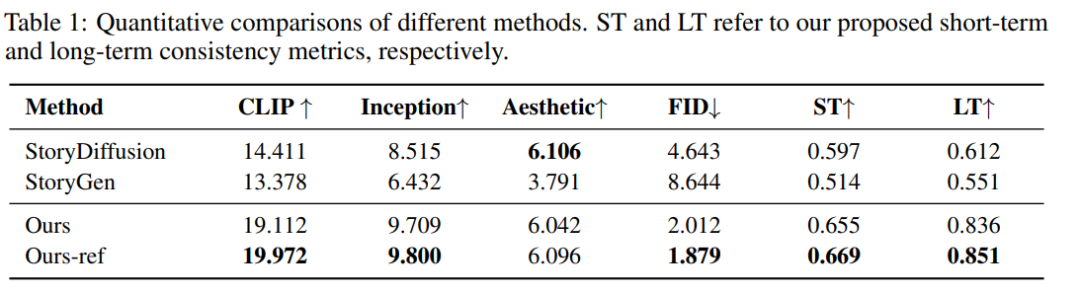
本文的方法在LT(长期一致性)和ST(短期一致性)上都取得了高分。此外,更高的CLIP分数表明生成的结果与故事情节高度一致。更好的IS(初始分数)、AS(美学评分)和FID(弗雷歇图像距离)分数证明了生成图像的高质量。
视频结果质量
作者详细比较了我们的方法与现有方法在生成长视频方面的表现。对于文本到视频的方法使用详细描述作为输入。对于图像到视频使用我们方法生成的关键帧作为输入。
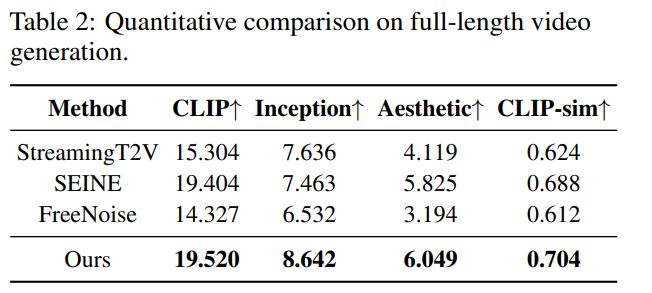
本文方法在质量上显著优于之前的开源模型,展现出强大的泛化能力。最重要的是,该方法能够生成长达数小时的视频,同时质量损失很小,达到SOTA。
消融实验
抗过拟合策略
自回归模型虽然学习能力强,但也容易对数据集产生过拟合现象。如下图所示,当模型过拟合时,它生成的内容会过分依赖输入的角色信息,即使面对不同的文本提示,输出的视觉内容也相似度极高。

作者为此设计了一系列抗过拟合策略,减少角色ID与目标图像之间的直接关联,避免模型简单地记忆和复制。可以看到,这显著提高了生成内容的多样性和质量,使其更加贴近文本描述。
多模态电影剧本的增强
为了进一步提升生成内容的一致性,作者在多模态电影剧本中引入了面部嵌入技术。

从上图中可以看到:当去除面部嵌入时,生成的人物面部在不同帧下明显不一致。相比之下,面部嵌入为模型提供了比文本更细致、更精确的信息,使得模型在生成内容时能够同时保持短期和长期的角色一致性。
ID保持渲染的改进
虽然解码器在未启用ID保持渲染前已经能够重建目标图像,但对于训练集之外的图像,由于信息压缩导致的细节丢失,重建的角色外观可能与预期略有偏差。
在引入了ID保持渲染技术后,显著增强了解码器在保持角色身份方面的能力,使得生成的图像更加准确和逼真。
从下图中可以看出,使用该方法后,角色的面部特写更加细腻真实。

few-shot个性化生成的能力
本文方法具备强大的上下文学习能力,能够在few-shot情况下,生成与这些样本风格或角色高度一致的内容。如下图所示,在zero-shot时已经表现很出色了,few-shot训练之后,画面细节、面部特征更加精细!

结论
MovieDreamer巧妙地结合了自回归和扩散模型的优势,精心设计的多模态剧本,确保在生成的视频序列中,角色的形象始终保持一致。模型强大的上下文建模能力加持下引入ID保持渲染技术,使得在few-shot下也能创作出角色鲜明、连贯的长视频。
总而言之,MovieDreamer为未来的AI长视频制作开启了无限可能,相信能让视频创作变得更加简单、高效。


















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









