






来,你先把手机音量打开,然后去“听”下面一段视频:
你是不是一脸懵逼?不知道我想表达什么?
视频是AI生成的并不奇怪,但你可能没法相信,这个视频的音效,也是AI生成的。
火车鸣笛
你要是不信,可以继续听几个(音效和视频均由AI生成):
松鼠4K
等下,这个声音配的有点怪,也可能是我喇叭坏了,换一个...
再来个动物进食的。
小兔进食
我天,这音效配的,不止是没把剪映放眼里,连影视行业的音效师(Sound Designer)都要忍不住颤抖了。
这是智谱新推出的音效模型 CogSound ,本月即将在“智谱清言”里上线。
以后啊,忘掉你的音效素材库吧。视频和音效一把儿出,只想配音也没问题(偶尔遇到翻车的甚至更有喜感,有望成为一个新的流量赛道)。
我仔细玩了下,CogSound 对于视频语义和情感有不错的理解能力,音画同步也做的很流畅。像爆炸、动物叫声、乐器、城市噪声等比较常见的声音等,可以达到很高的可用性。但如果是一些人都不知道会发出啥声音的场景,就可能让AI蚌住。
比如给孟加拉巨蜥配音,我翻遍了整个Youtube也没找到一只开口叫出声的孟加拉巨蜥。这种就别为难AI了,它也是主要通过互联网数据来模仿学习动物叫声的
我还去扒了下CogSound的技术实现,直接挑重点讲下。
一方面,它采用优化后的U-Net结构作为扩散模型的核心框架,将音频生成从高维原始空间转到低维潜空间,大幅降低了计算复杂度,保证音频生成的高质量和高效率。
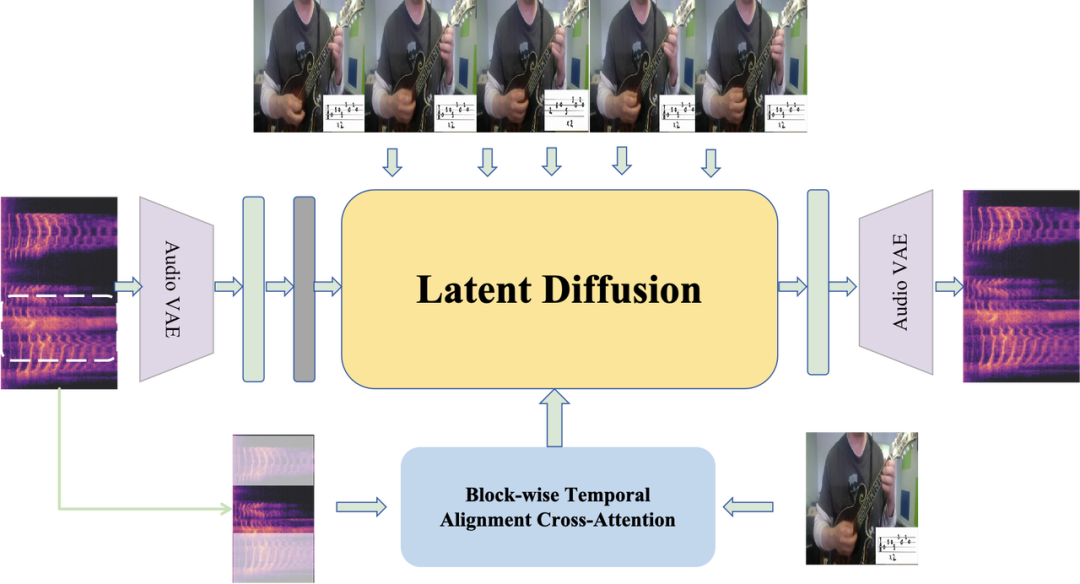
另一方面,引入了“分块时序对齐交叉注意力机制”,这个机制让CogSound能精准地将视频帧和音频特征对应起来,实现了画面和声音的完美同步;CogSound还用到了旋转位置编码,来确保生成的音频前后连贯,过渡自然。这个是音效流畅、过渡自然的重要因子。
从CogSound的这一波操作中,我更加能坚信一个事情。那就是,但凡某个工作,需要人去检索、扒拉的,理论上都能用生成式范式给定义一个新的任务出来,把用户检索query->满足用户query的内容构造成训练集,选择合适的大模型架构训个模型出来,然后本来要花大量时间去检索扒拉内容的那个工种,就因此被提效了。
比如,众所周知,程序员这个工作就是去百度/谷歌搜索别人的代码片段(误),然后就有了编程大模型。
回到正题,CogSound是我认为智谱这波的AI视频生成升级中一个非常惊艳的feature,这也将使智谱清言成为国内首个告别默片、生成有声AI影片的产品。
除了CogSound外,清影也做了一波升级。
升级后的新清影现在可以生成更长、更高清的自带音效的视频。
-
10s时长:由5s增加到10s,16s视频也正在路上;
-
4K、60帧超高清画质;
-
支持任意比例的视频生成:比如9:16竖版视频,16:9横版视频,还有1:1、4:3、3:4。
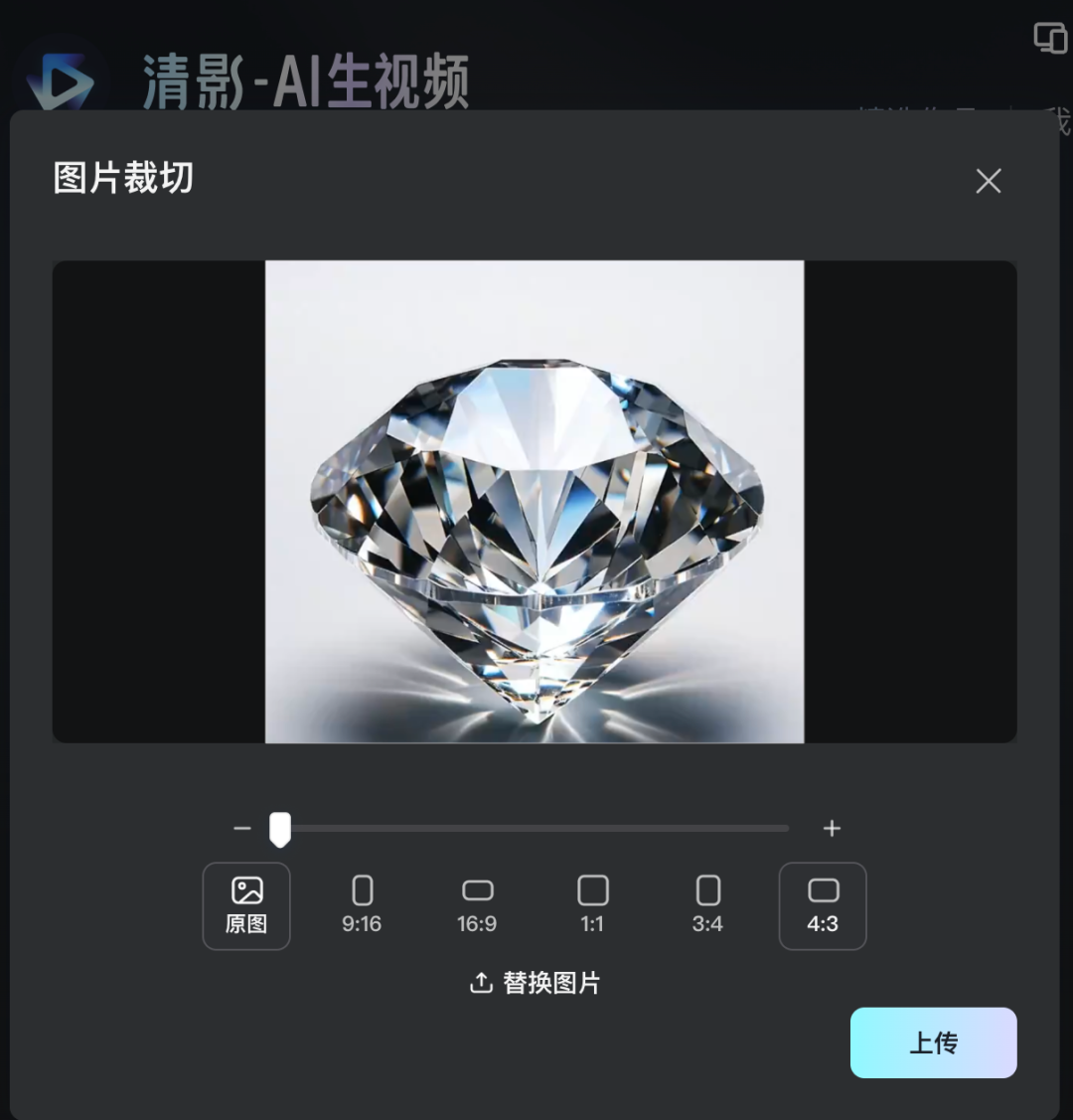
除了基础功能升级外,我玩下来感知这次的图生视频功能也有了非常惊艳的进化,在质量、美学表现、运动合理性以及复杂提示词语义理解能力都有显著增强。
贴个我生成的视频给你们感受下:
人手的纹理和蜥蜴的皮肤纹理呈现的特别清晰,和现实几乎无异。
赛车
比如,飙车这种大幅的场景变化推进非常合理自然。
PS:新清影即日起就会在智谱清言网页和App 上线。
CogSound也会在本月上线,两者一起玩,说不定会打开新的流量密码
你要问为啥效果变得这么好了,一句话解释——
因为新清影背后的模型又又又升级了!这个进化速度简直让摩尔定律都汗颜。
为了拿到优质的训练数据,智谱专门构建了一个自动化的数据筛选框架,还训了一个用于标注视频数据的视频理解模型 CogVLM2-caption,来为视频生成高质量描述。
而且,这次在内容连贯性、可控性和训练效率上都进行了多项创新。自研了一个高效的三维变分自编码器结构(3D VAE),可以把原视频空间压缩至 2%,大大降低训练难度。另外,自研的transformer 架构融合文本、时间、空间3个维度,可以更好地将视觉信息与语义信息对齐。
必须要提的是,这次最新升级的CogVideoX 1.5,毫不意外的——
开源!
直接附上你们需要的传送门:
https://github.com/thudm/cogvideo
讲个比较恐怖的故事,一年多前世界上最先进的AI生成出来的视频还是很生硬的。如今,全链路自研的国产AI视频产品“智谱清影”,已经做到了音画同步地步, 这个进展速度还是牛的。
看到智谱这波在视频生成的升级,说真的很开心,也很骄傲,我们与国外的差距正在以超预期的速度在缩小。
智谱、可灵这几位国产代表,正在逐渐拉近与国际水平的差距。不止如此,开源文化虽起源于美国,但在这波AI大模型的开源速度&进化速度上,我觉得智谱是国内的开源No.1。追OpenAI的人,成为Open AI。
而如果我们将目光从视频生成,拉远到整个多模态领域,你又会惊恐的发现一件事儿——
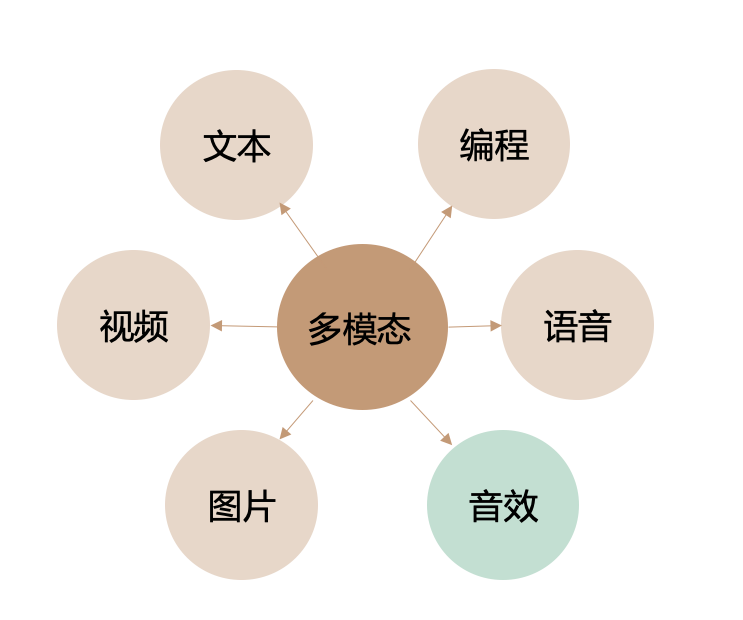
我觉得智谱的多模态模型生态真的快要“闭环”了。
除了智谱之外,我就没听说哪家模型同时有公开可用的文生图+文生视频+图生视频+音效生成+音乐生成+情感语音生成这一系列的多模态模型的。这个布局广度确实让我不禁好奇,等智谱把这个全链路打通后,是不是会引发什么神奇的化学反应,产生一系列AI新玩法。
从当前的技术积累就不难看出,沿着当前的速度继续迭代下去,可能用不了两年,我们或许只需要一个想法+一张底图,就能生成一段自带bgm、音效甚至配音的高可用视频。这不止影响的是影视行业的生产效率,这可能对于整个新媒体生态都会是一个巨大的冲击和机遇。
如今AI视频生成技术不够成熟,反物理的AI视频都能一波又一波的成为流量密码。随着技术的持续成熟,AI视频生成会逐渐从一个娱乐尝鲜的工具,蜕变成真正的生产力工具。
而对于我们大部分人来说,即便没有机遇去搞懂锤子是怎么造出来的,但若是能深谙锤子的用法和特性,或许,也能跟随AI浪潮迎风起飞。
速去智谱清言体验~




















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









