







论文介绍
论文链接:https://arxiv.org/abs/2106.02745
论文代码:https://github.com/waterhorse1/nac
论文发表于NeurIPS 2021,属于多智能体强化学习领域。目前我还没有找到介绍这篇paper的相关博客。写一点自己的心得就当作是抛砖引玉了。

在多智能体强化学习训练过程中,常常会创建agent的种群,通过对“对手种群策略”的best response(BR)来更新迭代自身策略,如NFSP、Double Oracal等。在这种算法框架下,“与谁玩”和“如何学习BR”就成了绕不过去的点。
相比以往的工作,本文提出的NAC是一种对手选择策略,解决的是“和谁玩”这个问题。通过神经网络学习对手选择,不需要人手动设计就可以达到相比目前Sota算法(PSRO等)还要好的学习效果。
核心算法
相关知识
Meta-Game
可以简单理解成,对手是固定种群的游戏。也就是说,对手的策略可以近似认为是固定策略,该策略是所有对手策略的平均。
Meta-Solver
神经网络,细节不展开讲了。
Best Response Oracle
一旦Meta-Game被确定,对手种群固定,当前的求解目标就变成了求解该对手种群策略下的BR。
学到的新BR策略会被不断地加入到种群中,形成新的种群。
学习目标
学习目标就是策略可利用度的最小化。花体m表示可利用度,花体exp表示策略可利用度。当可利用度为0时,策略已经最优,学习过程结束。
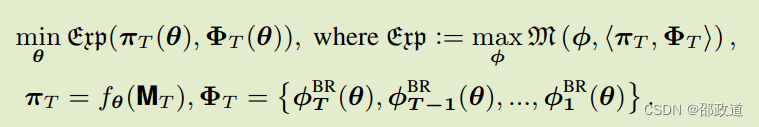
通过元梯度优化元求解器
这是本文最核心的地方。因为改变了对手meta-policy的选取方式,所以反向梯度传播就成了问题,这里主要是解决梯度反传这个问题的数学方法。
基于上面可利用度最小化的那个式子,mata-solver其实就是求解:
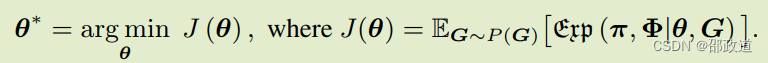
这样一来,就可以用梯度下降方式进行BR的求解。
将梯度进行展开如下:
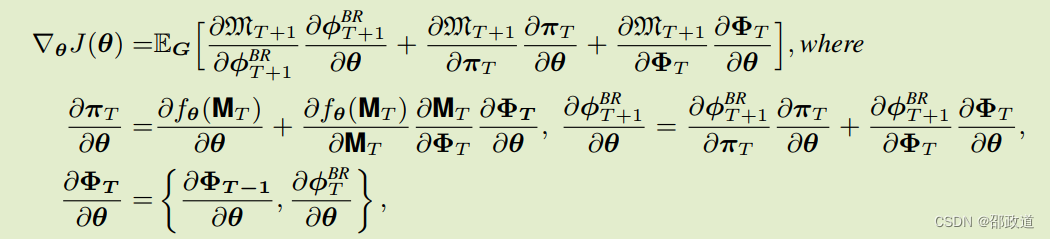
其中上面的第三行等式,明示了是用递归法迭代求解。
在用强化学习求解BR过程中,用到了DICE算法。DICE是一种无偏高阶梯度估计器,与自动微分完全兼容。H为trajectory的长度,⊥是pytorch.detach(),将variable参数从网络中隔离开,不参与参数更新。
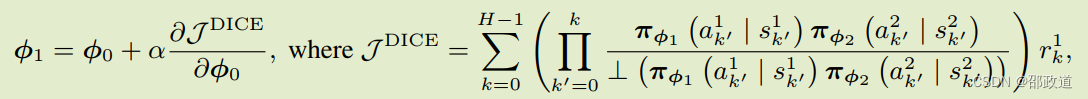
通过ES算法求解梯度
Evolutionary Strategies(ES)版本的NAC。区别就是每次计算meta-gradient的时候,不是使用梯度求解,而是引入一些小幅度的“策略突变”,用策略突变后的期望收益来表征梯度。
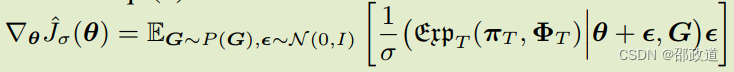
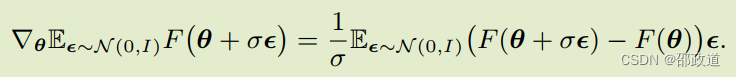
这种算法的好处就在于,即使是一些不太容易用反向传播自动求导的情况,也可以用ES算法求出梯度。
算法伪代码

算法框图
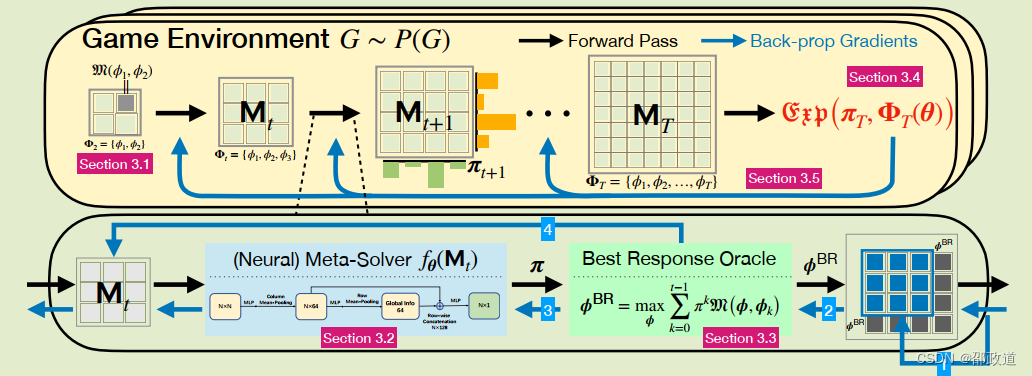
这张图一开始理解起来可能会有点困难,所以我把它放到结尾再解释每一步作用(可以结合伪代码一起理解)。总的来说,算法循环部分主要在于 元博弈求解、BR求解和策略池扩张这三个模块。
图片分为上下两层。
上层体现的是meta game中种群策略不断增加的,优化目标为策略的可利用度。
元博弈求解使用下层的Meta-Solver进行计算,得到种群中各个策略的概率分布,实现解决“和谁玩”的问题。BR求解则用神经网络解决。
NAC里面解决“和谁玩”这个问题的概率分布,就是上层中央图中橙色和绿色的柱状图。
总结
文章核心就是解决“who to compete with”这个问题。用神经网络在对手池中进行对手策略的选取,并设计了梯度求导的办法。
具体执行时,使用MAML的方式对一个环境分布上的固定T次迭代后的Exploitability的期望优化,得到meta-solver的参数,不同的参数可以视作不同的meta-solver。
肉眼可见,该算法和PSRO的计算复杂度是在同一数量级的(大于等于,因为多了meta-policy生成这一个步骤),解决思路也是比较直观的,难点在于数学公式推导,以及和PSRO一样,非常消耗训练资源。















 2509
2509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











