






 本文介绍了RoBERTa模型,它是BERT的改进版本,通过增大模型规模、调整训练参数、移除NSP任务和采用动态掩码策略,提升模型性能。实验结果显示,RoBERTa在某些任务设置中表现优于BERT,尤其是全句子和不跨文档的采样方式。
本文介绍了RoBERTa模型,它是BERT的改进版本,通过增大模型规模、调整训练参数、移除NSP任务和采用动态掩码策略,提升模型性能。实验结果显示,RoBERTa在某些任务设置中表现优于BERT,尤其是全句子和不跨文档的采样方式。
参考:RoBERTa 详解_roberta模型-CSDN博客
【深度学习】BERT变体—RoBERTa_动态掩码-CSDN博客
RoBERTa (A Robustly Optimized BERT)模型是BERT 的改进版
目录
RoBERTa相比BERT的改进
在模型规模、算力和数据上有以下几点改进:
- 更大的模型参数量(论文提供的训练时间来看,模型使用 1024 块 V100 GPU 训练了 1 天的时间)
- 更大bacth size。(BERT预训练的batch size为256,训练了1M步。RoBERTa 在训练过程中使用了更大的bacth size。尝试过从 256 到 8000 不等的bacth size,训练了500000-300000步)
- 更多的训练数据(包括:CC-NEWS 等在内五个数据集共 160GB 纯文本。而最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练)
在训练方法上有以下改进:
- 去掉下一句预测(NSP)任务
- 动态掩码。原版的 BERT 实现在数据预处理期间执行一次掩码mask,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
- 文本编码。BERT 实现使用字符级别的WordPiece分词器,词表大小为 30K。RoBERTa用更大的 byte 级别BBPE分词器,词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
去掉下一句预测(NSP)任务
1.SEGMENT-PAIR+NSP: NSP任务保留。每个输入是段落(segment),每个片段由多个自然句子组成,最大长度为512;
2.SENTENCE-PAIR+NSP:NSP任务保留。每个输入是一对自然句子,每个自然句子可是一个文本的连续部分,也可以是不同文本。因为这些输入显然少于512,因此增加了批大小,让一个批次总的单词数和SEGMENT-PAIR+NSP差不多。同时保留NSP loss;
3.FULL-SENTENCES: 每个输入都包含从一个或多个文档中连续采样的完整句子,因此总长度差不多512个单词。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界标记。移除NSP loss;
4.DOC-SENTENCES: 每个输入都包含从一个连续采样的完整句子,输入格式和FULL-SENTENCES类似,除了它们不会跨域文档边界。在文档末尾附近采样的输入可能短于 512 个单词,所以动态增加了批大小让单词总数和FULL-SENTENCES类似。移除NSP loss;
实验结果如下图所示:
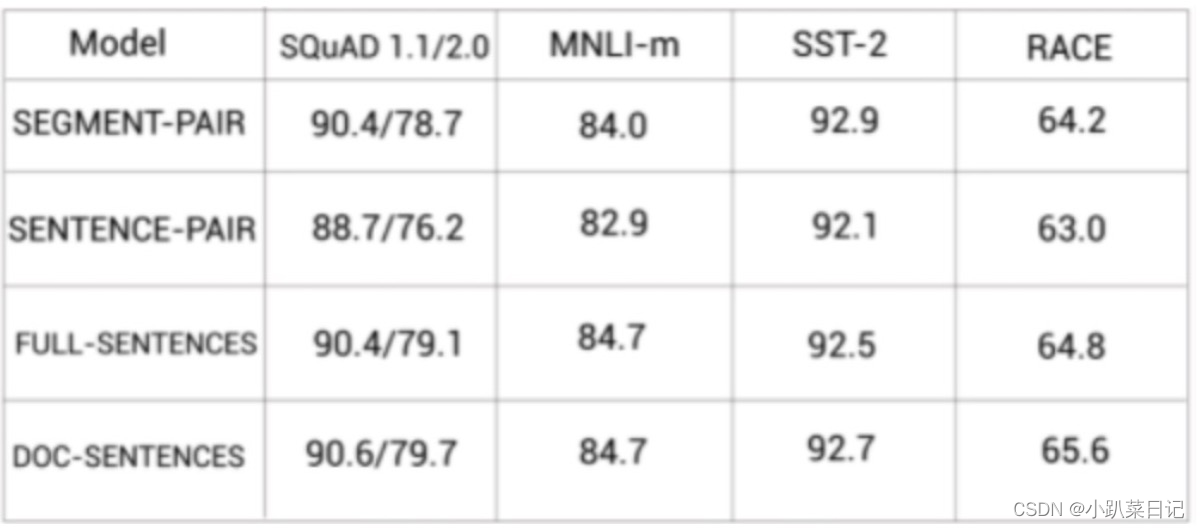
从实验结果看,BERT在FULL-SENTENCES和DOC-SENTENCES设定中表现的更好,这两者都剔除了NSP任务。对比FULL-SENTENCES和DOC-SENTENCES,DOC-SENTENCES只从一篇文档中采样,此种设定的表现比FULL-SENTENCES在多篇文档中采样要好。但在RoBERTa中,作者使用了FULL-SENTENCES,因为DOC-SENTENCES导致批大小变化很大。
动态掩码
RoBERTa使用动态掩码。BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,也就是静态mask的方式。RoBERTa的训练过程中使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新随机mask,其中每个句子被mask的token不同:即拥有不同的masked tokens。
MASK结果如下所示:
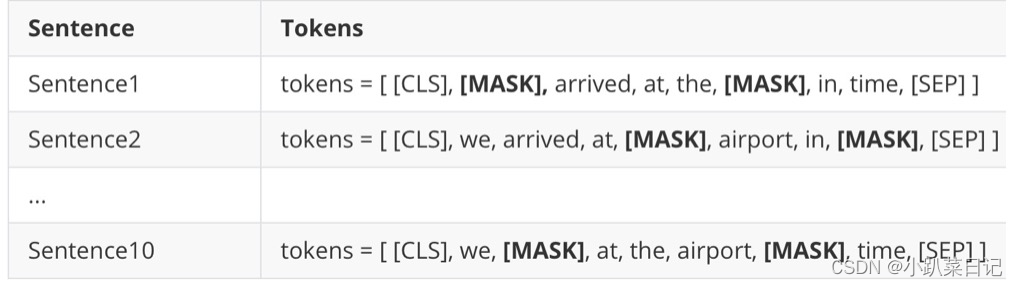
在模型训练时,对于每个epoch,使用不同标记被[MASK]的句子喂给模型。这样模型只会在训练10个epoch之后看到具有同样掩码标记的句子。比如,句子1会被epoch1,epoch11,epoch21和epoch31看到。这样,我们使用动态掩码而不是静态掩码去训练RoBERTa模型。

















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









