






pandas作为最优秀的python数据处理工具之一,对于非专业人士做自动化办公、数据统计分析方面的工作非常友好。本文章总结工作中使用pandas的经验,汇总部分常用API,以供自己回头温习。
目录
修改索引:Dataframe.rename(columns/index)
用sql查询语句由mysql数据库数据生成dataframe
pandas常用功能
1、获取数据:从数据库、excel、csv、网页、剪贴板等快速获取数据为python可操作的对象。
2、重构数据结构:数据和合并、拆分、轴变换变换等。
3、统计数据:通过pandas的方法快速定位数据范围、对数据进行分组聚合、求统计值。
4、数据清洗:去重、处理缺失值、补全、极端值处理、对符合条件的数据重新赋值等。
pandas的数据构成解析
1、数据结构
2、处理构成数据的方法
tips:多维数据结构这里就直接忽略了,非专业工作用不到,这里只记录二维。
python列表
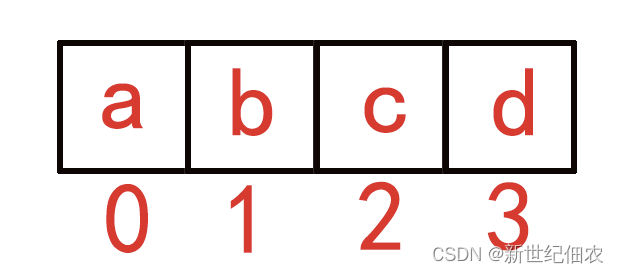
列表python内置的基本类型,列表对象的元素个数不定,元素的类型不定,以所在位置的序列号为索引。列表常用方法如下:
直接声名列表元素生成列表: list_demo = ["a","b","c"] # [x for x in "abc" ]
添加元素:list_demo.apend("d")
len(list) 获取列表长度
list_demo.pop(index) 从列表中去除指定索引的数据
list[index] 指定索引访问元素
for x in list: # 遍历列表
numpy数组
类似python的列表,但numpy库对多维数组、数学逻辑的处理十分强大,是pandas数据结构和运算的基础,这部分内容想成为大神的可以去研究。
python字典
python字典类型类似json,但支持比json更多的内容。

由键值对构成,dict.key()返回可迭代的key对象,dict.values()、dict.items()同理。
Series系列

Series是带标签和索引的一维数组,系列的索引是可自定义的,在同一个命名空间中Series标签不能相。上面两个Series对象虽然元素和索引相同,但标签不同(系列1、系列2),所以不是两个相同的Series,Series标签和实际值的关系类似字典的键值对(标签是键,内容是值)。
DataFrame
二维的dataframe简单讲就是excel表,就不做图了,有行索引和行索引和数据内容之分。从不同方向上看:每一行数据都是以行索引为标签、列索引为索引的Series数据,同时每一列也是以列索引为标签、行索引为索引的Series数据;从整体上看就是一个数据框架。
数据基本结构如下:
1、索引(index)、列名(columns)
一张excel表,左边的行号1、2、3、4.....就是索引,上面的A,B,C,D...就是列名,不同领域索引也称为行号、行名称等,列名也成为字段、列索引等等。
生成一个索引:pandas.Index(list)
行和列的索引都是pandas.Index类的对象,同时索引对象拥有Series对象的所有属性和方法。
this_index = pandas.Index([1, 2, 3])
print(type(this_index))
print("*"*5)
print(this_index)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
<class 'pandas.core.indexes.numeric.Int64Index'>
*****
Int64Index([1, 2, 3], dtype='int64')
进程已结束,退出代码0pandas指定列索引-参数:columns
this_index = pandas.Index(["国籍", "爱好", "等级"])
data = [["中国", "你好世界", "13"],
["美国", "reign on the earth", "15"],
["韩国", "나의 세계","6"]]
df = pandas.DataFrame(data=data, columns=this_index)
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
国籍 爱好 等级
0 中国 你好世界 13
1 美国 reign on the earth 15
2 韩国 나의 세계 6
进程已结束,退出代码0pandas指定行索引-参数:index
this_columns = pandas.Index(["国籍", "爱好", "等级"])
this_index = pandas.Index(["a", "b", "c"])
data = [["中国", "你好世界", "13"],
["美国", "reign on the earth", "15"],
["韩国", "나의 세계","6"]]
df = pandas.DataFrame(data=data, columns=this_columns,index=this_index)
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
国籍 爱好 等级
a 中国 你好世界 13
b 美国 reign on the earth 15
c 韩国 나의 세계 6
进程已结束,退出代码0Dataframe直译就是数据框架,行列索引用以标记框架单元的位置。这里不讨论多层索引和多维数据结构因为大部分人用不到这玩意需要用也用别的工具去了。
将第一行数据指定为列索引。
修改索引:Dataframe.rename(columns/index)
接上面的代码
dict_columns = dict()
for key, value in zip(this_columns.tolist(), ["国家", "性格", "成长"]):
dict_columns[key] = value
print(dict_columns)
print("修改后")
df = df.rename(columns=dict_columns)
print(df)
dict_ = {"国家": "国名"}
df = df.rename(columns=dict_)
print("修改后")
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
{'国籍': '国家', '爱好': '性格', '等级': '成长'}
修改后
国家 性格 成长
a 中国 你好世界 13
b 美国 reign on the earth 15
c 韩国 나의 세계 6
修改后
国名 性格 成长
a 中国 你好世界 13
b 美国 reign on the earth 15
c 韩国 나의 세계 6
进程已结束,退出代码0
行索引同方法。
索引对象方法:
pataframe的index和columns都是索引对象。
Index.tolist() 遍历索引元素生成一个列表。索引对象其实是对Series的进一步封装。
Index.is_unique 是否不重复。
Index.dtype 索引的数据类型
Index.size 索引的元素数量。
生成Dataframe相关API
由python数据生成dataframe
由列表构成的二维数组生成dataframe:
数据为二维数组,二维数组中的每个数组是一条数据。
columns = ["a", "b", "c"]
data = [
[1, 2, 3],
[4, 5, 6]
]
df = pandas.DataFrame(data=data, columns=columns)
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
a b c
0 1 2 3
1 4 5 6
进程已结束,退出代码0由字典生成dataframe:
字典生成DataFrame相当于Serise集合生成DataFrame
Serise即带标签、索引的一维数组。如
a = pandas.Series([1, 2, 3], name="标签a")
b = pandas.Series([1, 2, 3], name="标签b")
print(a)
print(b)
c = pandas.Series([1, 2, 3], name="标签c",index=["第一行索引","第二行索引","第三行索引"])
print(c)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
0 1
1 2
2 3
Name: 标签a, dtype: int64
0 1
1 2
2 3
Name: 标签b, dtype: int64
第一行索引 1
第二行索引 2
第三行索引 3
Name: 标签c, dtype: int64
进程已结束,退出代码0将Serise转换为字典(Series.to_dict())即丢弃标签后行索引为键、行的值为值的键值对,组成的字典。
D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
{'第一行索引': 1, '第二行索引': 2, '第三行索引': 3}
进程已结束,退出代码0DataFrame的每一列数据都是一个Series,列名即Sries标签名,df的索引即series的索引,所以字典相对于DataFrame的结构,也就是键名=标签=列名,值为键值对,键为索引值为值,如下:
columns = ["a", "b", "c"]
data = {"第一列": {"第一行索引": "a", "第二行索引": "b", "第三行索引": "c"},
"第二列": {"第一行索引": "1", "第二行索引": "2", "第三行索引": "3"}
}
df = pandas.DataFrame(data=data)
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
第一列 第二列
第一行索引 a 1
第二行索引 b 2
第三行索引 c 3
进程已结束,退出代码0可以看出用二维数组生成DataFrame更符合人的逻辑,而用字典生成dataframe则更符合计算机的逻辑。
由外部数据生成DataFrame
pandas读取CSV文件生成dataframe
注意:CSV文件有个坑是会破坏时间格式。从数据库导出带有时间戳字段的表为CSV,读取成dataframe再写回数据库,会报时间戳类型错误,需要手动修改类型或format。
pandas.red_CSV(文件路径)。不需引擎直接打开。index参数为布尔类型表示行索引,CSV一般没有行索引。文件路径可以是URL(调用requests从url下载csv文本)。
可选参数:
usecols=["列名1",“列名2”] 或 [0,1],可限制读取的csv的列范围。
skiprows=range(2) 跳过前两行。
skiprows=[1,3] 跳过第1、3行。
sep=",",指定csv分隔符。
读取excel有同样的参数。
pandas读取excel:
pandas没有集成openpyxl,需自行安装:pip install openpyxl
老版本不需指定engine参数也可打开excel,但是部分版本必须指定,所以最好直接指定。
df = pandas.read_excel("./2023-03-10.xlsx", engine="openpyxl")
print(df)sheet_name参数可设置读取哪个工作簿。如果sheet_name为非负数,则为工作簿的索引。


df_tableOne = pandas.read_excel("./demo.xlsx", engine="openpyxl", sheet_name=0)
print(df_tableOne)
df_tableTwo = pandas.read_excel("./demo.xlsx", engine="openpyxl", sheet_name=1)
print(df_tableOne)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
字段1 字段2 字段3
0 a1 a2 a3
1 b1 b2 b3
2 c1 c2 c3
字段1 字段2 字段3
0 a1 a2 a3
1 b1 b2 b3
2 c1 c2 c3
进程已结束,退出代码0
也可直接指定工作簿的名称
df_tableOne = pandas.read_excel("./demo.xlsx",
engine="openpyxl",
sheet_name="tableOne")
print(df_tableOne)
df_tableTwo = pandas.read_excel("./demo.xlsx",
engine="openpyxl",
sheet_name="tableTwo")
print(df_tableTwo)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
字段1 字段2 字段3
0 a1 a2 a3
1 b1 b2 b3
2 c1 c2 c3
field1 field2 field3 field4
0 x1 x2 x3 x4
1 y1 y2 y3 y4
2 z1 z2 z3 z4
3 i1 i2 i3 i4
进程已结束,退出代码0用sql查询语句由mysql数据库数据生成dataframe
pandas.read_sql()
engine参数:新版加入了数据库引擎,可以直接传连接信息。
如:
self.db_engine_info = f"""mysql+pymysql://{user}:{password}@{host}:{port}/{db}?charset=utf8"""
pandas.read_sql(sql, self.db_engine_info)
以上是最直接简洁的方式,但实际使用时往往需要对数据库做除查询外的更多操作,所以需要pymysql或SQLAlchemy构建操作数据库的类,然后pandas引用其engine。
需要pymysql或SQLAlchemy库提供mysql引擎支持,官方支持SQLAlchemy(SQLAlchemy还是用了pymysql做的引擎连接mysql,相当于绕了一圈又回到pymysql),但这东西真的很垃圾,比如你sql错了,给你提示的是SQLAlchemy团队自己写的异常,没法定位具体哪里错,pymysql则直接返回数据库报的异常,甲骨文团队做的sql诊断可比SQLAIchemy强太多,还有很多坑用着用着就不行了。。。无奈几乎所有的python后端框架集成的都是SQLAIchemy。
pip install SQLAlchemy
准备数据
DROP TABLE IF EXISTS `demo`;
CREATE TABLE `demo` (
`id` int(100) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键,不用管',
`data_value` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '值',
`test_time` datetime NOT NULL COMMENT '时间',
`is_delete` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '0' COMMENT '未删除:0/已删除:1',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2177559 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;sysalchemy读取数据库需要先实例化引擎对象,由引擎对象创建连接对象,用连接对象的执行方法向数据库传输sql语句。
实例化mysql引擎对象的传入语句如下,大家自行更改填空:
con_info = f'mysql+pymysql://root:mima123@127.0.0.1:3306/demo_db?charset=utf8'
con_info = f'mysql+pymysql://root:mima123@127.0.0.1:3306/demo_db?charset=utf8'
db_engine = sqlalchemy.create_engine(con_info)
with db_engine.connect() as con:
for x in range(3):
sql = f"""
INSERT INTO demo VALUES(0,"{x}","2023-02-02 1{x}:10:10",0)
"""
print(con.execute(sql))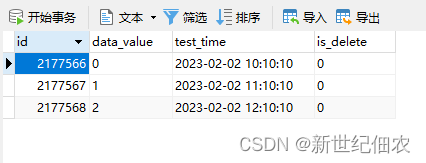
数据准备好了。pandas.read_sql()第一个参数是sql语句,第二个参数是引擎,其他参数少用。
sql = """
SELECT * FROM `demo`
"""
df = pandas.read_sql(sql, db_engine)
print(df)D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
id data_value test_time is_delete
0 2177566 0 2023-02-02 10:10:10 0
1 2177567 1 2023-02-02 11:10:10 0
2 2177568 2 2023-02-02 12:10:10 0
进程已结束,退出代码0由二维数组和sql读取数据生成DataFrame的方式并比较常用,其他这里并不介绍了,还有一种从json读取数据的其规则和字典是一样的。
获取Dataframe内的信息
以下以df代替dataframe
len(df) 查看df的行数。
df.info() 如下,可以看行和列的数量和类型(列的类型即索引类型),调试用。
D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 3 non-null int64
1 data_value 3 non-null object
2 test_time 3 non-null datetime64[ns]
3 is_delete 3 non-null object
dtypes: datetime64[ns](1), int64(1), object(2)
memory usage: 224.0+ bytes
进程已结束,退出代码0df.size df的属性之一,即有多少个数据(包括空值)。
获取某行:loc\iloc
dataframe.loc[index] 获取某个index行的数据,返回Series对象。
dataframe.iloc[1] 获取第一行的数据,返回Series对象。
获取某列
dataframe[clumns] 直接通过列名获取到整列,返回Series。
获取某列某个范围行的数据
my_df.iloc[0:10,1] 行范围是从第1行开始到第11行,获取第2列的数据,返回Series。
df.head()查看前10行
Dataframe拆分与合并
拆分即选择部分dataframe赋值给一个新的dataframe
合并:
df_merged = pd.concat([df1, df2]) 将两个dataframe放到列表中传给concat函数,要求两个df字段相同。如果需要左右合并,参数axis=1,此时不要求字段和行索引相同。
df.merge(df2, left_on='lkey', right_on='rkey', how='left') #两个df以左右键连接成一个新的df,类似sql的关联查询,how参数指定主表是做还是右。
行列互换:
df = df.T
两列互换
df['col1'], df['col2'] = df['col2'], df['col1'] 两列互相赋值,实现两列互换,行互换同理。
由上,生成dataframe和改变dataframe的基本方法已经写完,后面是删选、聚合、统计的API操作。
DataFrame筛选数据
范围筛选:
df[['小a', '小b']] # 筛选小A、小B两列的数据。
df = df.loc[1:3, '小a':'小b''] # 行索引1~3,列名为从小a~小b(包括两端)的数据。
df = df.iloc[1:3, 0:2] # 第2~4行,0~3列数据。
条件筛选:
df = df[df["国籍"]=="中国"] # 解释:首先df["国籍"]=="中国"返回一个Series,其索引与df一致,条件判断为真的Series索引的对应值为Ture,反之为Fales,根据这个Series筛选df,返会值为Ture的索引行构成的新的df。
df["列名"].drop_duplicates() 显示某列,并且去重,即以某列为条件去重,如果对全部列为条件不做列赛选即可。
值的比较筛选:
df = [df['age']>10, df['con']<=90] #age列大于10,con列小于90
逻辑筛选:
&是或, 逗号是与,~是非
df[(table_df['小a']=="a") & (df['小b']=="b")]
df = df.loc[~(df['小a'] == 'a')] # 筛选df的“小a”列的值不是“a”的数据构成的df
字符串模糊筛选:
df[df['小a'].str.contains('a')] 筛选df中'小a'列(字符串类型)包含“a”字符串的df。
df.filter()过滤器:
df.filter(regex="^2",axis=0).filter(like="a",axis=1) # 筛选索引中以2开头的、列名中有“a”字段。
以上几种筛选组合使用,足以随心所欲筛选出特定数据。
分组聚合
df_group = df.groupby("国籍") # 以国籍分组
chinese = df_group.getgroup(“中国”) # 获取分组后,中国组的df.
dict_group= dict(list(df_group)).get("中国") # 获取分组后,中国组的df.可见将分组对象转为列表再转为字典,即可获得组别为键、对应值为df的字典,后续对分组结果处理更方便。
chinese = dict_group.get(“中国”)
chinese["data_value"].mean() 分组的均值
修改dataframe数据
df.loc[inedx, column] = new_value 修改某个单元格的数据,用loc指定单元格。
df.loc[df['column_name'] == 'value', 'column_name'] = new_value 根据条件赋予新值,条件的语法和上面筛选一致。示例的意思是:df中的'column_name'列中,值是'value'行构成一个df,这各df的'column_name' 列的值将被赋予新值,然后依照这个df更新原来的df。
df.iloc[2:5, 0:3] = new_value 将某个范围内的值改为某值
统计
df一列数据的最大值、最小值、平均值,即Sries的最大值、最小值、平均值。
df.mean() 返回每列数据的平均值构成的Series。
df["data_value"].mean() data_value列的平均值
df.mean(axis=1) 每一行的平均值。返回一个Series,可以再按索引获取想要的行。
df.set_index("前五行").mean(axis=1).head() 前5行的平均值和"前五行"为标签构成的Sries.
df.mode() 众数
df.max() 最大值,方法于mean()类似
df.min() 最大值,方法于mean()类似
df["data_value"].idxmax() data_value列的最大值的索引。其他最小值、中位数同。
df.sum() 求和。
DataFrame计算API
均值计算,要确定Series类型是否为浮点数:
df.mean()
print(df["data_value"].mean())
df['data_value'] = df['data_value'].astype({"data_value": "int"})
print(df["data_value"].mean())
df["data_value"] = df["data_value"] + 1
print(df["data_value"].mean())D:\miniconda\envs\four\python.exe C:\Users\10179\Desktop\5g\try.py
2.6694101508768173e+55
8.8
9.8
进程已结束,退出代码0















 4976
4976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









