







目录
2.1、两种因素(数据的值与数据的分布)导致训练错误率与开发错误率相差甚大
2.2、引入训练-开发集,排除数据分布不一致因素导致训练/开发错误率差异性较大的问题。
第一章、简介
- 本文基于吴恩达人工智能课程做学习笔记、并融入自己的见解(若打不开请复制到浏览器中打开)https://study.163.com/courses-search?keyword=吴恩达。
- 本文第二章将介绍 如何找出不匹配数据因素(即数据分布不一致因素),导致算法的偏差问题和方差问题。
第二章、在不同的划分上进行训练并测试
2.1、两种因素(数据的值与数据的分布)导致训练错误率与开发错误率相差甚大
- 估计学习算法的偏差和方差 ,真的可以帮你确定接下来应该优先做的方向。
- 但是,当你的训练集来自和开发集/测试集不同分布时,分析偏差和方差的方式可能不一样。
- 我们来看为什么,我们继续用猫分类器为例,我们说人类在这个任务上能做到几乎完美,所以贝叶斯错误率或者说贝叶斯最优错误率几乎是 0%。
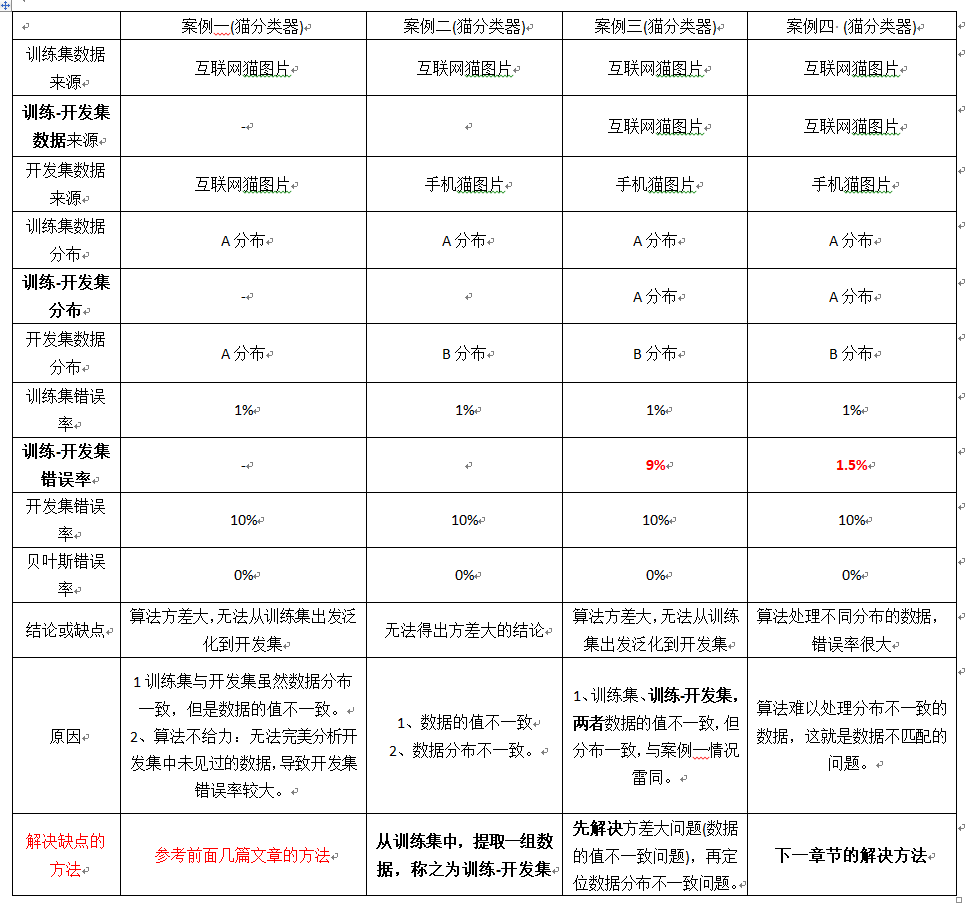
- 所以要进行错误率分析,你通常需要看训练错误率,也要看看开发集的错误率,比如说在猫分类器这个例子中,你的训练集错误率是1%,你的开发集错误是率10%。
- 如果你的开发集来自和训练集一样的分布,你可能会说这里存在很大的方差问题,你的算法不能很好的从训练集出发泛化,它处理训练集很好,但处理开发集就突然间效果很差了。
- 但如果你的训练数据和开发数据来自不同的分布,你就不能再放心下这个结论了,特别是算法在开发集上做得不错,可能因为训练集很容易识别,因为训练集都是高分辨率图片、很清晰的图像,但开发集要难以识别得多,所以也许软件没有方差问题,这只不过反映了开发集包含更难准确分类的图片。
- 所以这个分析的问题在于,当你看训练错误率,再看开发错误率,有两件事变了。
- 首先,算法只见过训练集数据、没见过开发集数据(我这里定义为数据的值)。
- 第二,开发集数据来自不同的分布(数据的分布)。
- 而且因为你同时改变了两件事情,很难确认这增加的 9% 错误率,有多少是因为算法没看到开发集中的数据导致的,这是问题方差的部分,有多少是因为开发集数据分布不一致导致的。
2.2、引入训练-开发集,排除数据分布不一致因素导致训练/开发错误率差异性较大的问题。
- 但为了分辨清楚两个因素的影响,定义一组新的数据是有意义的,我们称之为训练-开发集。
- 所以这是一个新的数据子集,我们应该从训练集的分布里挖出来,但你不会用来训练你的网络,我的意思是我们已经设立过这样的训练集,开发集和测试集了,并且开发集和测试集来自相同的分布,但训练集来自不同的分布。
- 我们要做的是随机打散训练集,然后分出一部分训练集作为训练-开发集,就像开发集和测试集来自同一分布,训练集和训练-开发集也来自同一分布,但不同的地方是,现在你只在训练集训练你的神经网络,你不会让神经网络,在训练-开发集上跑后向传播。
- 为了进行错误分析,你应该做的是看看分类器在训练集上的错误,训练-开发集上的错误、还有开发集上的错误。
- 比如说上面猫分类器的这个例子中,训练错误是 1%,我们说训练-开发集上的错误是 9%,然后开发集错误是 10% 。你就可以从这里得到结论,当你从训练数据变到训练-开发集数据时,错误率真的上升了很多。
- 而训练数据和训练-开发数据的差异在于,你的神经网络能看到第一部分数据,并直接在上面做了训练,但没有在训练-开发集上直接训练,这就告诉你 算法存在方差问题,因为训练-开发集的错误率,是在和训练集来自同一分布的数据中测得的,所以你知道尽管你的神经网络在训练集中表现良好,但无法泛化到来自相同分布的训练-开发集里,它无法很好地泛化推广到来自同一分布但以前没见过的数据中,所以在这个例子中我们确实有一个方差问题(注意训练集、训练-开发集数据来自同一分布)。
2.3、算法只能处理同一分布数据,称之为 数据不匹配的问题
- 我们来看一个不同的例子,假设训练错误率为1%,训练-开发错误率为 1.5%,但当你开始处理开发集时,错误率上升到 10%,现在你的方差问题就很小了,因为当你从见过的训练数据转到训练-开发集数据,神经网络还没有看到的数据,错误率只上升了一点点。
- 但当你转到开发集时,错误率就大大上升了,所以这是数据不匹配的问题,因为你的学习算法,没有直接在训练-开发集或者开发集训练过,但是这两个数据集来自不同的分布,但不管算法在学习什么,它在训练-开发集上做的很好,但开发集上做的不好,所以总之你的算法擅长处理和你关心的数据不同的分布,我们称之为数据不匹配的问题。
2.4、举例说明算法的偏差、方差、数据不匹配问题
- 一个例子,假如我们说训练错误率是10%,训练-开发错误率是11%,开发错误率为 12%,要记住,人类水平对贝叶斯错误率的估计大概是0%,如果你得到了这种等级的表现,那就真的存在偏差问题了,存在可避免偏差问题。因为算法做的比人类水平差很多,所以这里的偏差真的很高。
- 另一个例子,如果你的训练集错误率是10%、你的训练-开发错误率是 11%、开发错误率是20%,那么这其实有两个问题:
- 第一个问题是可避免偏差相当高,因为你在训练集上都没有做得很好,而人类能做到接近0%的错误率,但你的算法在训练集上错误率为 10%(即偏差高)。
- 第二个问题这里方差似乎很小,但数据不匹配问题很大,所以对于这个例子 我说,如果你有很大的偏差或者可避免偏差问题,还有数据不匹配问题。
- 我们再看看下面的小结,然后写出一般的原则。
- 已知人类水平错误率、训练集错误率、训练-开发集错误率这三个错误率,我们来看看你的开发集错误率取决于这三个错误率之间差距有多大。
- 你可以大概知道可避免偏差、方差,数据不匹配问题各自有多大,我们说人类水平错误率是 4%的话,你的训练错误率是 7%,而你的训练-开发错误是 10%,而开发错误是 12%,这样你就大概知道可避免偏差有多大(可避免偏差 = 3% = 7% - 4%),因为你希望你的算法至少要在训练集上的表现接近人类,而这大概表明了方差大小(方差大小 = 3% = 10% - 7%)。
- 所以你从训练集泛化推广到训练-开发集时效果如何? 而这告诉你数据不匹配的问题大概有多大(数据不匹配大小 = 2% = 12% - 10%)
- 技术上你还可以再加入一个测试集表现12%,我们写成测试集错误率,你不应该在测试集上开发,因为你不希望对测试集过拟合。如果开发集表现和测试集表现有很大差距,那么你可能对开发集过拟合了。
- 所以也许你需要一个更大的开发集,对吧,要记住你的开发集和测试集来自同一分布,所以这里存在很大差距的话,如果算法在开发集上做的很好,比测试集好得多,那么你就可能对开发集过拟合了,如果是这种情况,那么你可能要往回退一步,然后收集更多开发集数据。
2.5、处理语音识别,开发集错率可能比训练错误率更低
- 这里还有个例子,也许人类的表现是 4%、训练错误率是 7%、训练-开发错误率是 10%、开发集错率也许是 6%、测试集错误率也许是 6%,如果你见到这种现象,比如说在处理语音识别任务时发现这样,其中训练数据其实比你的开发集和测试集难识别得多,所以训练错误率和训练-开发错误率这两个是从训练集分布评估的。
- 而开发集错率和测试集错误率这两个是从开发测试集分布评估的,所以有时候如果你的开发测试集分布比你应用实际处理的数据要容易得多,那么这些错误率可能真的会下降,所以如果你看到这样的有趣的事情,可能需要比这个分析更普适的分析,我在下面快速快速解释一下。
2.6、将以上小结讨论的 偏差、方差、数据不匹配问题 汇总
- 我们就以语音激活后视镜为例子,事实证明,我们一直写出的数字可以放到一张表里,在水平轴上 我要放入不同的数据集,比如说 你可能从一般语音识别任务里得到很多数据,所以你可能会有一堆数据,来自小型智能音箱的语音识别问题的数据,你购买的数据等等,然后你收集了和后视镜有关的语音数据,在车里录的,所以这是表格的x轴 不同的数据集,在另一条轴上,我要标记处理数据不同的方式或算法,首先 人类水平,人类处理这些数据集时准确度是多少,然后这是神经网络训练过的数据集上,达到的错误率,然后还有神经网络没有训练过的数据集上,达到的错误率。
小结
- 所以我们讲了如何使用来自和开发集/测试集不同分布的训练数据,可能可以给你提供更多训练数据,因此有助于提高你的学习算法的性能,但是潜在问题就不只是偏差和方差问题,这样做会引入第三个潜在问题数据不匹配
- 如果你做了错误分析并发现数据不匹配是大量错误的来源,
- 那么你怎么解决这个问题呢? 但结果很不幸,并没有特别系统的方法去解决数据不匹配问题,但你可以做一些尝试,可能会有帮助,我们来看下一段视频。
- 本文的结晶,我总结如下:















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











