







我个人比较喜欢看各种小段子,但是又碍于麻烦,还要到处找,于是自己利用python写了一个小爬虫来抓取煎蛋网上的段子信息,并将其存储到mysql数据库中,如下图所示

同时由于煎蛋网采用了一定的反爬虫技术,所以当抓取一定页面之后会发现,我们的ip已经被暂时封了。所以想要解决问题,我们必须采用动态ip的策略来应对.
1.动态ip获取
网上有很多匿名的免费的动态ip库,但是多数不稳定.这里由于我们的需求也不是很大,只有大概1500个页面请求,所以我们并没有对ip库进行过滤测试有效性等。我们从http://www.xicidaili.com/nn/{page_number}上获取ip信息,获取动态ip库代码如下:
from lxml import etree
import urllib.request
from urllib.request import Request
import urllib.error
import re
"""
@Page_count:为提取ip地址的页数
"""
def get_proxyIp(Page_count):
url = "http://www.xicidaili.com/nn/{0}"
begin=1
iplist = []
for bein in range(1,Page_count):
urlprefix=url.format(str(begin))
req = urllib.request.Request(urlprefix)
req.add_header('User-Agent', 'Mozilla/5.0')
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
#采用lxml解析网页内容并获取ip信息
content=etree.HTML(html)
trlist=content.xpath("//table[@id='ip_list']/tr")
#print(len(trlist))
index=0
for tr in trlist:
td=tr.xpath("./td")
if len(td)>0:
ip=td[1].text
port=td[2].text
speed=td[6].xpath("./div[@class='bar']")[0].get('title')
speed=re.search("([0-9\.]+)",speed).group(0)
connectionTime=td[7].xpath("./div[@class='bar']")[0].get("title")
connectionTime=re.search("([0-9\.]+)",speed).group(0)
liveTime=td[8].text
#过滤掉分钟、小时生存期较短的ip
if liveTime.find("天")!=-1:
#liveTime=re.search("([0-9\.]+)",liveTime).group(0)
index=index+1
# print("ip-->%s" %ip)
# print("port-->%s" %port)
reallyip=ip+":"+port
iplist.append(reallyip)
#print("speed-->%s"%speed)
#print("connectionTime-->%s" %connectionTime)
#print("liveTime-->%s" %liveTime)
#print("the length of ip %d" %len(iplist))
return iplist 2.设置代理,获取网页内容
我们将一系列工具方法封装在util.py模块中,以便以后进行代码重用。
(1)设置代理
""
install opener
@ip:代理ip地址
"""
def install_opener(ip):
proxy_support = urllib.request.ProxyHandler({'http': ip})
opener = urllib.request.build_opener(proxy_support)
# 设置模拟浏览器
opener.addheaders = [('User-agent', 'Mozilla/5.0 ')]
urllib.request.install_opener(opener)(2)获取网页内容
""
get the content of url
@url:访问网址
@return:网页内容字节流,未解码
"""
def get_html(url):
html=""
try:
response = urllib.request.urlopen(url,timeout=10)
html = response.read()
except:
#print(e.reason)
html=""
return html3.解析网页内容,获得段子信息
这里我们不采用正则来提取段子信息,而是采用lxml来提取。因为其中的xpath语法比较简单好学,而且功能比较强大。
这里我使用liebao提供的审查元素功能来定位我们需要解析的内容,每个段子所有信息都是包装在li元素中,这里我们需要获取段子的作者和段子内容信息,最终定位到如下位置:
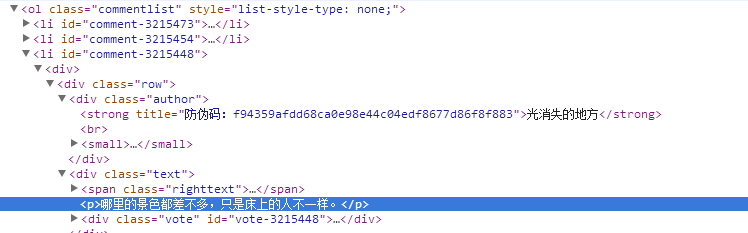
实现代码如下:
#对html进行解码
html=html.decode('utf-8')
page=etree.HTML(html)
li_list=page.xpath("//li[contains(@id,'comment')]")
for li in li_list:
#解析作者
author="".join(li.xpath("./*/*/div[@class='author']/
strong/text()"))
#解析内容信息
content="".join(li.xpath("./*/*/div[@class=
'text']/p/text()"))4.存储
将mysql的所有工具方法封装在util.py中
create Table duan(
page int
author varchar(50)
content text
)import pymysql
class pysqlHelp():
hostname=’localhost’
port=3306
user=’root’
passwd=’xxxxxx’
db=’mytest’
def get_connection(self):
try:
conn = pymysql.connect(host=self.hostname,port=self.port,user=self.user,passwd=self.passwd,db=self.db,charset=’utf8’)
print(“连接mysql server 成功”)
return conn
except Exception as e:
print(“连接mysql server出现异常”)
print(e)
def create_table(con):
mycuror=con.cursor()
try:
mycuror.execute(“””
CRETAE TABLE duan(
page INT,
author VARCHAR(50),
content text
)
“”“)
con.commit()
except:
print(“创建表失败”)
finally:
mycuror.close()
con.close()
#查询所有数据
def load(self,con):
mylist=[]
mycuror=con.cursor()
mycuror.execute(“select f_head from duan”)
data=mycuror.fetchall()
for d in data:
#print(“f_head–>%s” %d[0].split(‘/’)[-1])
mylist.append(d[0].split(‘/’)[-1])
mycuror.close()
return mylist
def search(self,con):
mycuror = con.cursor()
search_sql=”select min(page) from duan”
mycuror.execute(search_sql)
data=mycuror.fetchone()
mycuror.close()
con.close()
return data[0]
#插入数据
def insert(self,con,page,author,content):
mycuror = con.cursor()
insert_sql="INSERT INTO duan(page,author,content) VALUES('%s','%s','%s')" %(page,author,content)
try:
mycuror.execute(insert_sql)
#print("插入成功")
except Exception as e:
print("插入失败")
print(e)
finally:
mycuror.close()
5.完整代码:
import urllib.request
import re
import os
import random
import util
import time
import time
from lxml import etree
from util import pysqlHelp
ip=0
if name==’main‘:
#从数据库中加载当前需要开始解析的页面
sqlhelp = pysqlHelp()
con = sqlhelp.get_connection()
maxpage=sqlhelp.search(con)-1
print(“load the duanzi frome the page of %d” %maxpage)
changeip=0
html=””
iplist=[]
iplist=util.get_proxyIp()
ip=random.choice(iplist)
print(ip)
#绑定代理ip,并添加头部信息
#util.install_opener(ip)
urlprefix = “http://jandan.net/duan/page-{0}#comments”
for each in range(maxpage,0,-1):
#print(“这是第%d轮抓取” %(maxpage-each+1))
url = urlprefix.format(str(each))
html=util.get_html(url)
change=0
while html==”“:
#如果连续更换20次依然无法访问,则停止爬虫
if change>20:
print(“已经连续八次更换ip都无法访问,爬虫已经被网站封了”)
print(“change ip for %d” %change)
exit(-1)
ip=random.choice(iplist)
changeip += 1
util.install_opener(ip)
print(“这是第%d次更换ip地址” % changeip)
print(“更换后的ip地址为%s” %ip)
html = util.get_html(url)
print(“能正常执行”)
change+=1
if html!=”“:
change=0
#将该页面写入文件中
print(“该处理页为%s”%each)
try:
html=html.decode(‘utf-8’)
page=etree.HTML(html)
li_list=page.xpath(“//li[contains(@id,’comment’)]”)
con = sqlhelp.get_connection()
duanlen=0
for li in li_list:
author=”“.join(li.xpath(“.///div
[@class=’author’]/strong/text()”))
content=”“.join(li.xpath(“./*/
*/div[@class=’text’]/p/text()”))
if author!=”” and content!=”“:
duanlen+=1
sqlhelp.insert(con,each,author,content)
con.commit()
con.close()
print(“第%d页成功加载%d个段子到数据库中” %(each,duanlen))
time.sleep(3)
except Exception as e:
print(“处理页面出现错误%s” %e)
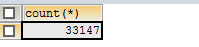
6.效果
最后我们一共抓取了3w+个段子信息
(1)总数为3w+
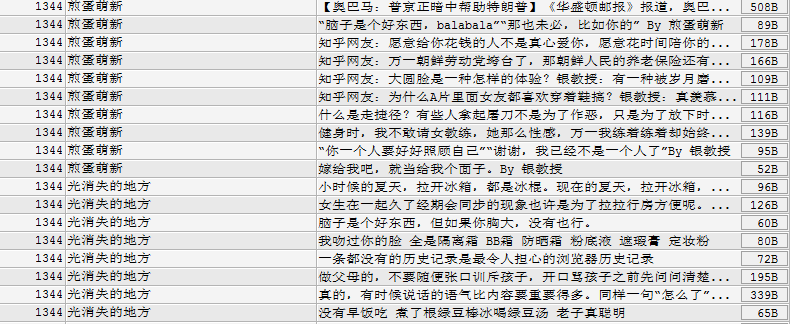
(2)段子具体信息
7.感悟
本来想用scrapy框架来进行段子信息抓取,但是他自身的反爬虫机制并不是很完善,我用scrapy来爬虫,竟然连一个页面都提取不到,我不知道为什么?所以最后决定自己写一个小爬虫来解决问题。框架只是为我们程序开发节省了大量时间,但是它未必是最高效的,有些需求对于框架来说还是比较难实现的。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









