









前言:
以本人的三台虚机:10.97.22.3、10.97.22.4、10.97.22.5为例,分别部署zookeeper和kafka集群环境
一、部署Zookeeper:
1、进入到 /usr/local/kafka/目录中:
cd /usr/local/kafka/
2、下载 zookeeper-3.4.10.tar.gz:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
3、解压缩 zookeeper-3.4.10.tar.gz:
tar -zxvf zookeeper-3.4.10.tar.gz
4、进入到 /usr/local/kafka/zookeeper-3.4.10/conf 目录中:
cd zookeeper-3.4.10/conf/
5、复制 zoo_sample.cfg 文件的并命名为为 zoo.cfg:
cp zoo_sample.cfg zoo.cfg
6、用 vim 打开 zoo.cfg 文件并修改其内容为如下:
vi zoo.cfg
修改之后 :wq 保存退出
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/kafka/zookeeper-3.4.10/data
dataLogDir=/data/zookeeper
clientPort=2181
server.1=10.97.22.3:2888:3888
server.2=10.97.22.4:2888:3888
server.3=10.97.22.5:2888:3888
7、保存并关闭 zoo.cfg 文件:
8、用 vim 打开 /etc/ 目录下的配置文件 profile:
vi /etc/profile
并在其尾部追加如下内容:
# idea - zookeeper-3.4.10 config start - 2016-09-08
export ZOOKEEPER_HOME=/usr/local/kafka/zookeeper-3.4.10/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export PATH
# idea - zookeeper-3.4.10 config start - 2016-09-08
9、使 /etc/ 目录下的 profile 文件即可生效:
source /etc/profile
10、启动 zookeeper 服务:
zkServer.sh start
如打印如下信息则表明启动成功:
ZooKeeper JMX enabled by default
Using config: /usr/local/kafka/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
11、查询 zookeeper 状态:
zkServer.sh status
12、关闭 zookeeper 服务:
zkServer.sh stop
如打印如下信息则表明成功关闭:
ZooKeeper JMX enabled by default
Using config: /usr/local/kafka/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
13、重启 zookeeper 服务:
zkServer.sh restart
如打印如下信息则表明重启成功:
ZooKeeper JMX enabled by default
Using config: /usr/local/kafka/zookeeper-3.4.10/bin/../conf/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /usr/local/kafka/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
ZooKeeper JMX enabled by default
Using config: /usr/local/hikvision/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
14、分布式 zookeeper 环境:
(1)、在每台机子的hosts中都加上如下的映射:
vi /etc/hosts
10.97.22.3 server-1
10.97.22.4 server-2
10.97.22.5 server-3
(2)、切记在zookeeper的data目录下,创建一个myid的文本文件,里面为每台机子配上不同的id,如:
10.97.22.3服务器上zookeeper的data目录下的myid文件中只要写上一个字符“1”就好了
10.97.22.4服务器上zookeeper的data目录下的myid文件中只要写上一个字符“2”就好了
10.97.22.5服务器上zookeeper的data目录下的myid文件中只要写上一个字符“3”就好了
(4)、最后分别重启zookeeper服务,会发现三台机子中,有两台的mode:follower,一台的mode:leader,这样zookeeper就部署成功了!
二、部署kafka:
1、下载 kafka_2.11-1.1.0.tgz:
wget http://mirrors.hust.edu.cn/apache/kafka/1.1.0/kafka_2.11-1.1.0.tgz
2、解压缩 kafka_2.11-1.1.0.tgz:
tar -zxvf kafka_2.11-1.1.0.tgz
3、配置日志:进入到/usr/local/kafka/kafka_2.11-1.1.0/config目录创建日志目录;
cd /data
mkdir kafka
4、修改kafka配置文件:
进入到/usr/local/kafka/kafka_2.11-1.1.0/config目录,修改server.properties。
cd /usr/local/kafka/kafka_2.11-1.1.0/config
vi server.properties 替换以下配置,具体host.name、port和broker.id,根据实际情况修改
broker.id=1
port=9092
host.name=10.97.22.3
delete.topic.enable=true
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.97.22.3:2181,10.97.22.4:2181,10.97.22.5:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
:wq! #保存退出
5、修改日志配置文件:
进入到/data/kafka目录,修改meta.properties。
cd /data/kafka
vi meta.properties #修改为如下配置,注意broker.id应与server.properties中的broker.id一致
broker.id=1
version=0
6、Kafka操作:
(1)、启动kafka命令:
cd /usr/local/kakfa/kafka_2.11-1.1.0/bin
nohup ./kafka-server-start.sh /usr/local/kafka/kafka_2.11-1.1.0/config/server.properties &
(2)、停止kafka命令:
./kafka-server-stop.sh
(3)、创建Topic:(创建一个名为test的topic,只有一个副本,一个分区。)
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic test
(4)、列出所有Topic:
./kafka-topics.sh -list -zookeeper 127.0.0.1:2181
(5)、启动Producer并发送消息:
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
(输入相应的消息,eg:hello kafka;按Ctrl+C结束)
(6)、启动Consumer并接收消息:
./kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --topic test --from-beginning
7、Kafka配置集群:
(1)、在每台机子的配置文件中的broker.id都设置成唯一,如:
10.97.22.3服务器上kafka的server.properties文件中broker.id=1
10.97.22.4服务器上kafka的server.properties文件中broker.id=2
10.97.22.5服务器上kafka的server.properties文件中broker.id=3
(2)、因为前面在zookeeper的部署说明中,已经把每台集群服务host文件设置了,所以只需在每台服务的server.properties文件中配上:zookeeper.connect=10.97.22.3:2181,10.97.22.4:2181,10.97.22.5:2181
(3)、重启kafka,集群部署完毕!
三、部署kafka-manager:
1、下载好kafka-manager编译好的压缩包,我这里下的是“kafka-manager-1.3.3.7.zip”,并在10.86.22.3上创建目录/usr/local/services/kafka-manager
2、上传kafka-manager-1.3.3.7.zip到跳板机
3、在跳板机上执行:scp kafka-manager-1.3.3.7.zip root@10.86.22.3:/usr/local/services/kafka-manager
4、解压:unzip kafka-manager-1.3.3.7.zip
5、定位到conf下的application.conf文件,修改配置信息如下:
kafka-manager.zkhosts=10.97.22.3:2181,10.97.22.4:2181,10.97.22.5:2181
6、在解压的目录中运行:
nohup bin/kafka-manager &
7、在浏览器中输入10.86.22.3:9000,弹出kafka-manager的管理界面,选择Add Cluster
8、Cluster Name随便输一个,如“test-kafka-cluster”,Cluster Zookeeper Hosts输入:
10.97.22.3:2181,10.97.22.4:2181,10.97.22.5:2181
选择保存(其他没啥好填的,有需要的以后再更改)弹出Add Cluster Done的界面
9、再次回到10.97.22.3:9000,可以看到界面上已经有个名为test-kafka-cluster的集群了,点进去可以看到zookeepers的数目和topics的数目,继续点进去可以查看每个topic的状态!
四、部署kafka-offset-monitor:
1、下载包:wget https://github.com/quantifind/KafkaOffsetMonitor/releases/download/v0.2.1/KafkaOffsetMonitor-assembly- 0.2.1.jar
2、安装解压工具:yum install -y unzip zip
3、安装jar工具:yum install java-devel
4、解压到test文件夹:unzip KafkaOffsetMonitor-assembly-0.2.1.jar -d test
5、下载下来的包里,含有直接连google的angularjs的配置,所以要改成国内的。进入offsetapp目录,打开index.html,找到google
的angularjs,分别替换为:
https://code.angularjs.org/1.2.9/angular.js
https://code.angularjs.org/1.2.9/angular-route.js
https://code.angularjs.org/1.2.9/angular-resource.js
6、重新打包:
jar cvfm KafkaOffsetMonitor-saas.jar ./META-INF/MANIFEST.MF ./
7、创建自启动脚本:vi kafka-monitor-start.sh
java -cp KafkaOffsetMonitor-saas.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--offsetStorage kafka \
--zk 10.97.22.3:2181,10.97.22.4:2181,10.97.22.5:2181 \
--port 9900 \
--refresh 10.seconds \
--retain 2.days
8、给自启动脚本授权:chmod +x kafka-monitor-start.sh
9、后台启动:nohup ./kafka-monitor-start.sh >/dev/null 2>&1 &
10、查看进程:ps -ef|grep KafkaOffsetMonitor
11、浏览器输入http://ip:9900 即可查看
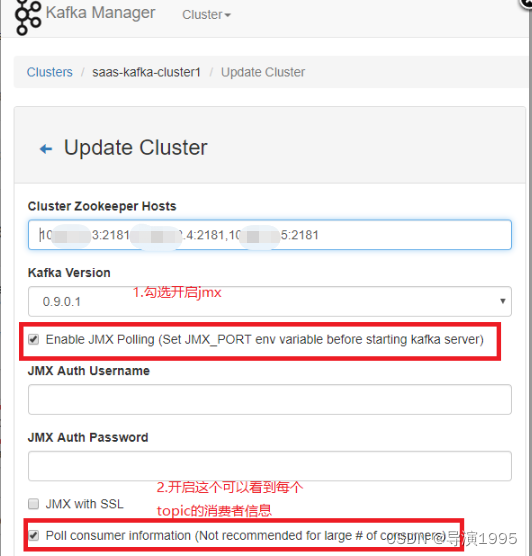
五:开启kafka JMX
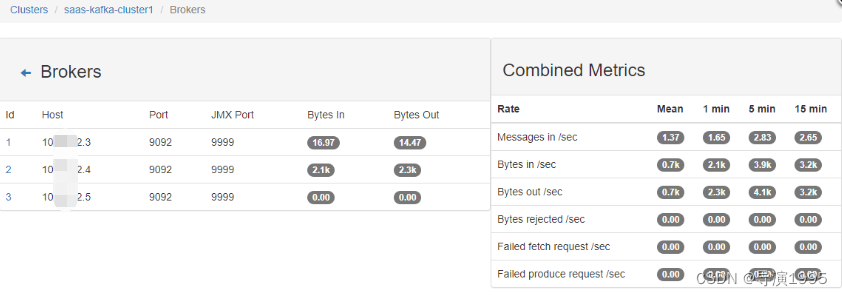
开启kafka的JMX后,可以直接在kafka manager里面直接观察集群的吞吐量、单topic的吞吐量等信息。
开启方法:
1.启动kafka前,执行命令:export JMX_PORT=9999 ,端口号随意,但是别和其他进程冲突。
2.进入kafka manager,编辑集群配置。
3.结果展示















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











