







目录
一、实验目的
掌握
DPCM
编解码系统的基本原理。初步掌握实验用
C/C++/Python
等语言编程实现
DPCM编码器,并分析其压缩效率。
二、实验原理
1、DPCM编解码原理
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器。 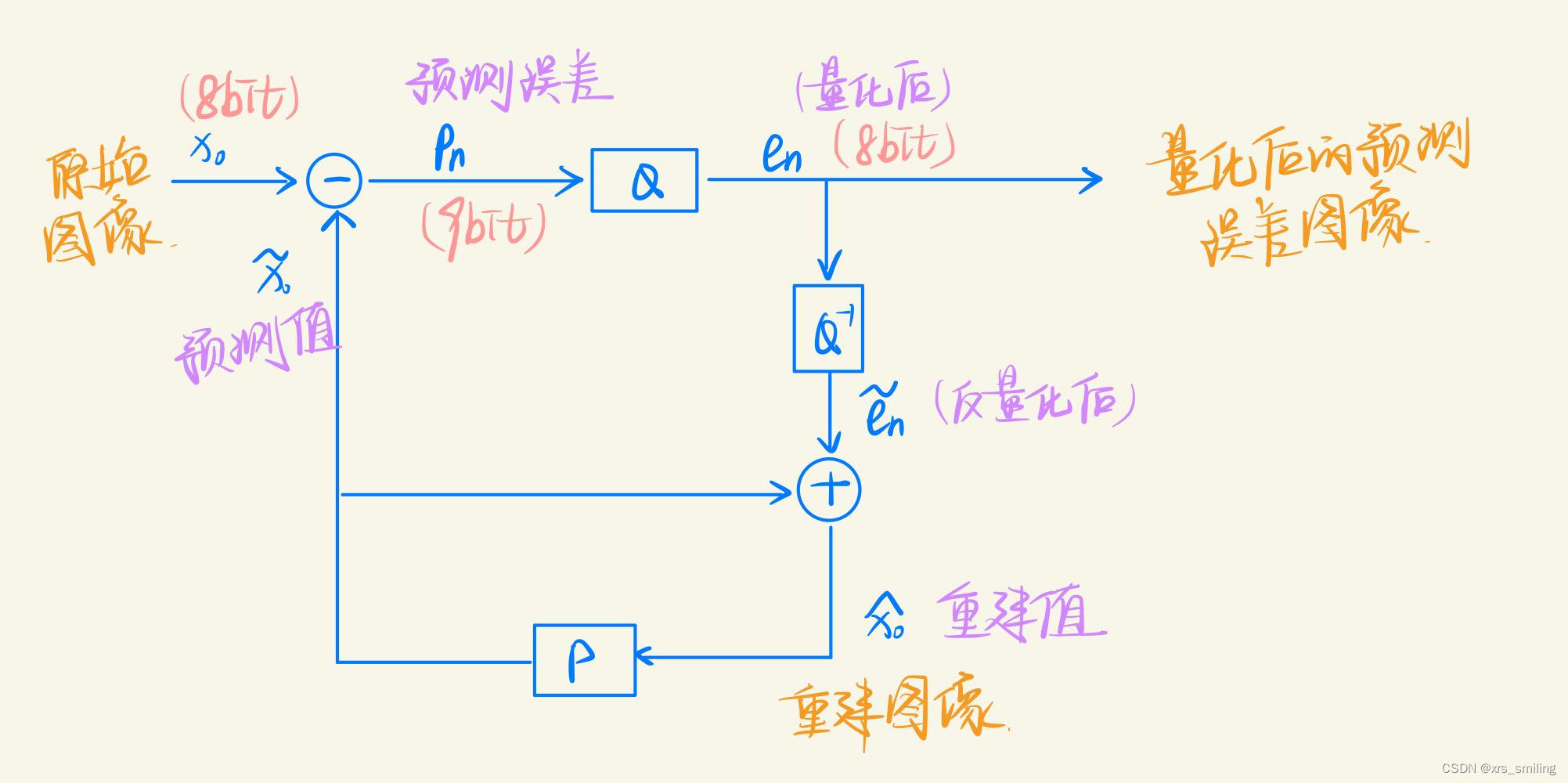
2、PSNR峰值信噪比
PSNR是一种评价图像的客观标准。给定一张大小为m × n 的原始干净图像C,和一张同大小的重建的噪声图像N 。我们计算它俩之间的均方误差 MSE为:
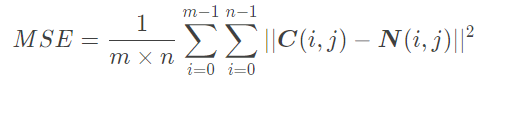
然后我们计算出原始图像可能出现的最大像素值。对于8位图像数据,这个值为255 。最后,我们定义PSNR(dB)为:
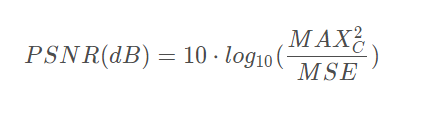
PSNR值越大,就代表失真越少:
- 高于40dB说明图像质量极好(即非常接近原始图像)
- 在30—40dB通常表示图像质量是好的(即失真可以察觉但可以接受)
- 在20—30dB说明图像质量差
三、实验步骤
- 首先读取一个 256级的灰度图像,采用左测预测方式计算预测误差,并对预测误差进行8bit、4bit、2bit与1bit均匀量化。
- 在DPCM编码器实现的过程中同时输出预测误差图像和重建图像。
-
将预测误差图像写入文件并将该文件输入Huffman 编码器,得到输出码流、给出概率分布图并计算压缩比。
-
将原始图像文件输入 Huffman 编码器,得到输出码流、给出概率分布图并计算压缩比。
-
比较两种系统(1.DPCM+熵编码和2.仅进行熵编码)之间的编码效率(压缩比和图像质量),压缩质量以PSNR进行计算。
四、实验代码
1、DPCM
void DPCMLeft(int width, int height, unsigned char* y_buffer, unsigned char* pre_buffer, unsigned char* re_buffer, int bits)
{
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
if (j == 0)//向左进行预测时,图像最左边一列的像素值与128进行预测
{
int error = y_buffer[i * width + j] - 128; //预测误差
pre_buffer[i * width + j] = (error + 255) / (512 / pow(2, bits)); //对预测误差进行(bits)比特的量化
int Qerror = pre_buffer[i * width + j] * (512 / pow(2, bits)) - 255; //对预测误差进行量化+反量化后的值
re_buffer[i * width + j] = Qerror + 128; //重建值
}
else//当不是最左边一列的像素时,进行DPCM
{
int error = y_buffer[i * width + j] - re_buffer[i * width + j - 1]; //预测误差
pre_buffer[i * width + j] = (error + 255) / (512 / pow(2, bits)); //对预测误差进行(bits)比特的量化
int Qerror = pre_buffer[i * width + j] * (512 / pow(2, bits)) - 255; //对预测误差进行量化+反量化后的值
re_buffer[i * width + j] = Qerror + re_buffer[i * width + j - 1]; //重建值
}
}
}
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
// 保护电平(16,235)
if (re_buffer[i * width + j] > 235)
re_buffer[i * width + j] = 235;
if (re_buffer[i * width + j] < 16)
re_buffer[i * width + j] = 16;
}
}
}2、PSNR
double PSNR(int width, int height, unsigned char* y_buffer, unsigned char* re_buffer)
{
double MSE, PSNR;
double sum = 0;
for (int i = 0; i < width * height; i++)
{
sum += pow((double)(y_buffer[i] - re_buffer[i]), 2);
}
MSE = sum / (width * height);
PSNR = 10.0 * log10((255.0 * 255.0) / MSE);
return PSNR;
}3、主函数
int main(int argc, char** argv)
{
char* ori_FileName = argv[1];//原始图像文件
FILE* ori_File = NULL;
char* pre_FileName = argv[2];//预测误差文件
FILE* pre_File = NULL;
unsigned char* pre_buffer = NULL;
char* re_FileName = argv[3];//重建图像文件
FILE* re_File = NULL;
unsigned char* re_buffer = NULL;
int width = atoi(argv[4]); //原始文件的宽
int height = atoi(argv[5]); //原始文件的高
int bits = atoi(argv[6]); //量化比特数
ori_File = fopen(ori_FileName, "rb");// 打开原始图像文件
if (ori_File == NULL)
{
cout << "Cannot open the ori_File." << endl;
return 0;
}
pre_File = fopen(pre_FileName, "wb");// 打开预测误差图像文件
if (pre_File == NULL)
{
cout << "Cannot open the pre_File." << endl;
return 0;
}
re_File = fopen(re_FileName, "wb"); // 打开重建图像文件
if (re_File == NULL)
{
cout << "Cannot open the re_File." << endl;
return 0;
}
// 色差信号
unsigned char* y_buffer = (unsigned char*)malloc(width * height * sizeof(unsigned char));
unsigned char* u_buffer = (unsigned char*)malloc(width * height / 4 * sizeof(unsigned char));
unsigned char* v_buffer = (unsigned char*)malloc(width * height / 4 * sizeof(unsigned char));
pre_buffer = (unsigned char*)malloc(width * height * sizeof(unsigned char));
re_buffer = (unsigned char*)malloc(width * height * sizeof(unsigned char));
// 读取原始文件yuv数据
fread(y_buffer, 1, width * height, ori_File);
fread(u_buffer, 1, (width * height) / 4, ori_File);
fread(v_buffer, 1, (width * height) / 4, ori_File);
// DPCM
DPCMLeft(width, height, y_buffer, pre_buffer, re_buffer, bits);
//memset(u_buffer, 128, (width * height) / 4);
//memset(v_buffer, 128, (width * height) / 4);
// 将数据写入文件
fwrite(pre_buffer, 1, width * height, pre_File);
fwrite(u_buffer, 1, (width * height) / 4, pre_File);
fwrite(v_buffer, 1, (width * height) / 4, pre_File);
fwrite(re_buffer, 1, width * height, re_File);
fwrite(u_buffer, 1, (width * height) / 4, re_File);
fwrite(v_buffer, 1, (width * height) / 4, re_File);
//计算PSNR
double psnr = PSNR(width, height, y_buffer, re_buffer);
cout << "The psnr = " << psnr << endl;
// 计算原始图像文件的概率分布
double frequency_ori[256];
memset(frequency_ori, 0.0, sizeof(double) * 256);
for (int i = 0; i < width * height; i++)
{
frequency_ori[y_buffer[i]]++;
}
for (int i = 0; i < 256; i++)
{
frequency_ori[i] = frequency_ori[i] / (width * height);
}
ofstream oFile1;
char cvs_name[256 * 256] = "E:\\学习资料\\1数据压缩原理与应用\\DPCM\\original.cvs";
oFile1.open(cvs_name, ios::out | ios::trunc);
for (int i = 0; i < 256; i++)
oFile1 << i << ',' << frequency_ori[i] << endl;
oFile1.close();
// 计算预测误差文件的概率分布
double frequency_pre[256];
memset(frequency_pre, 0.0, sizeof(double) * 256);
for (int i = 0; i < width * height; i++)
{
frequency_pre[pre_buffer[i]]++;
}
for (int i = 0; i < 256; i++)
{
frequency_pre[i] = frequency_pre[i] / (width * height);
}
ofstream oFile2;
char cvs_name2[256 * 256] = "E:\\学习资料\\1数据压缩原理与应用\\DPCM\\predict.cvs";
oFile2.open(cvs_name2, ios::out | ios::trunc);
for (int i = 0; i < 256; i++)
oFile2 << i << ',' << frequency_pre[i] << endl;
oFile2.close();
fclose(ori_File);
fclose(pre_File);
fclose(re_File);
free(pre_buffer);
free(re_buffer);
free(y_buffer);
free(u_buffer);
free(v_buffer);
}五、实验结果与分析
1、压缩质量
以下图为例

| 量化比特数 | 预测误差图像 | 重建图像 | PSNR |
| 8bit | 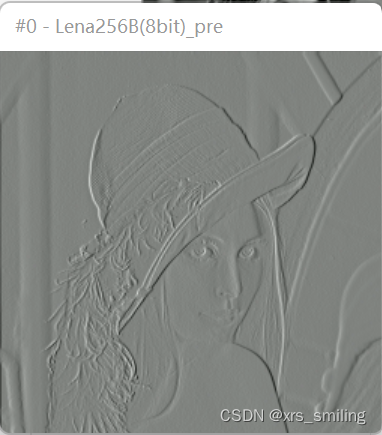 |  | 51.2566 |
| 4bit |  |  | 15.3675 |
| 2bit |  |  | 7.81937 |
| 1bit |  |  | 7.73251 |
注:对于4、2、1bit的情况下,因为量化后电平较低,因此所得的预测误差图像几乎无法分辨,因此上表中的图像均为将电平抬高128后的。
其他图片
| 原始图像 | 预测误差图像 | 重建图像 | PSNR |
 |  |  | 51.3159 |
 |  |  | 51.1449 |
 | 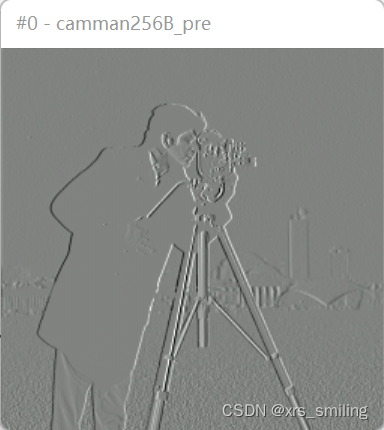 |  | 51.9624 |
结果
- 由实验结果可以看出,采用8bit量化有较好的压缩质量,重建后的图像值还原度较高。采用8bit量化的PSNR值均在50以上,也说明图像质量极好,即非常接近原始图像,人眼无法察觉区别。
- 随着量化比特数的减少,图像的压缩质量随之降低,PSNR值也随之下降。由实验结果看出,量化比特数低于4bit时,PSNR值已小于20,重建图像失真明显,图像质量差。
2、Huffman编码效率对比
不同图像、不同量化比特数的效率对比
| 原始图像 | 仅进行熵编码的编码效率 | 量化bit数 | DPCM+熵编码的编码效率 |
| Lena256B | 1.391 | 8 bit | 2.087 |
| Lena256B | 1.391 | 4 bit | 4.000 |
| Lena256B | 1.391 | 2 bit | 4.174 |
| Lena256B | 1.391 | 1 bit | 4.267 |
| Fruit256B | 1.315 | 8 bit | 2.286 |
| Clown256B | 1.297 | 8 bit | 2.000 |
| camman256B | 1.477 | 8 bit | 2.400 |
结果
- 由对比可以看出,DPCM+Huffman编码的压缩效率优于Huffman编码。
- 随着量化比特数的减小,压缩效率也随之升高,但是弊端是重建图像的质量会逐渐降低。
3、原图与8bit预测误差图像的概率分布图
随机选取两幅图像展示
| 图像名称 | 原始图像 | 预测误差图像 |
| Lena256B | 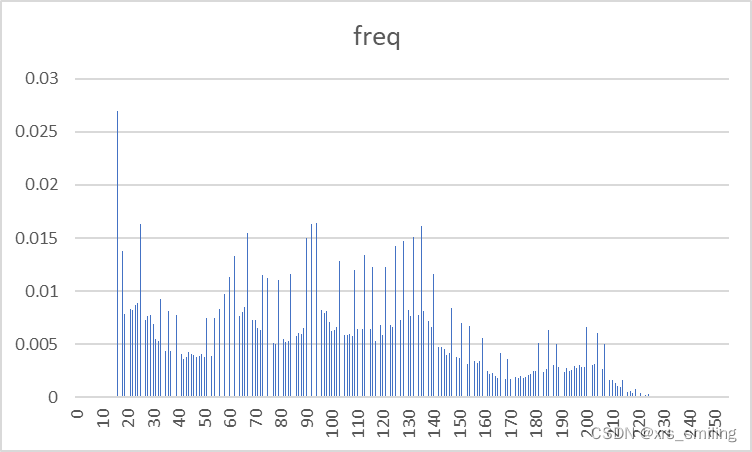 | 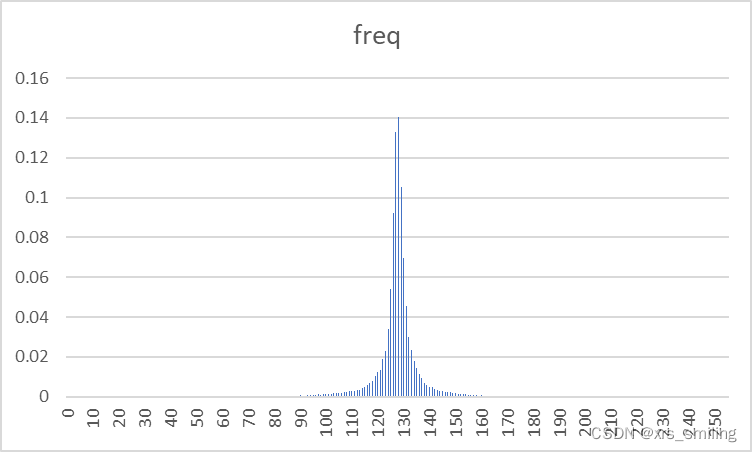 |
| Clown256B | 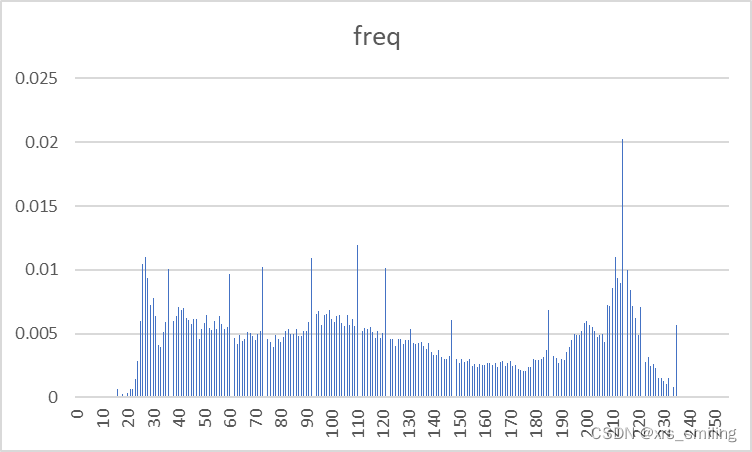 | 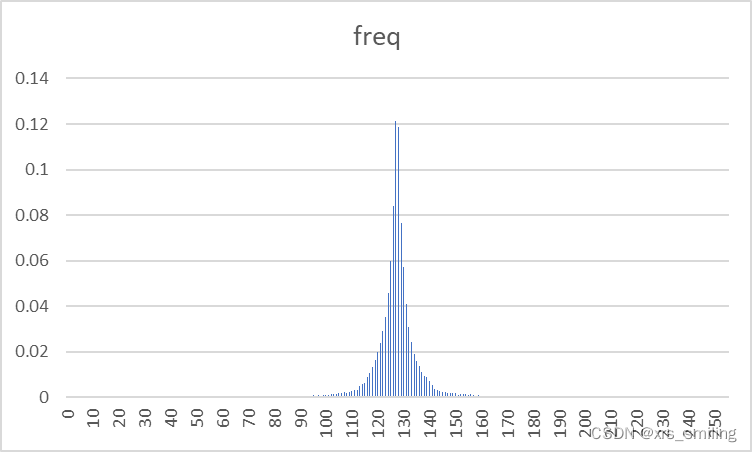 |
结果
- 通过图像像素概率分布图我们可以明显看出残差图的像素值集中分布在一个小像素值区间中,这对霍夫曼编码压缩是极为有利的。
- 和实际信号的分布相比,预测误差是关于0的高尖峰。因此,预测误差具有比原始密度更小的熵。这意味着预测的过程把样值间的大部分冗余去掉了。















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









