






自定义数据集必须定义的三个函数
class Pokemon(Dataset):
# 划分训练与测试集
def __init__(self, training=True):
if training:
self.samples = list(range(1,1001))
else:
self.samples = list(range(1001,1501))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]其余见代码文件
主要思路:
- 定义数据集(引入参数、划分数据集、索引、生成图片与标签)
- 生成CSV文件(生成images列表、写入CSV、读取CSV)
- 预处理(设置预处理参数和visdom)
- 迁移学习
自编码器
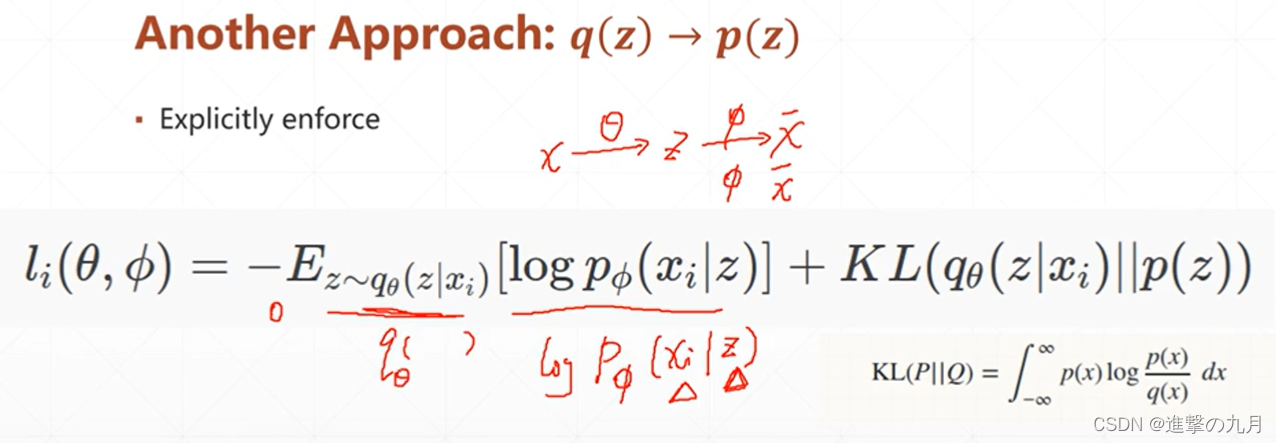
让p尽可能大
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# [b, 784] => [b, 20]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b, 20] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x: [b, 1, 28, 28]
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x, Noneclass VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] => [b, 20]
# u: [b, 10]
# sigma: [b, 10]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b, 20] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
self.criteon = nn.MSELoss()
def forward(self, x):
"""
:param x: [b, 1, 28, 28]
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
# [b, 20], including mean and sigma
h_ = self.encoder(x)
# [b, 20] => [b, 10] and [b, 10]
# μ和σ
mu, sigma = h_.chunk(2, dim=1)
# reparametrize trick, epison~N(0, 1)
h = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(h)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# 计算KL函数,1e-8是为了限幅
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz*28*28)
return x_hat, kldimport torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torchvision import transforms, datasets
from ae import AE
from vae import VAE
import visdom
def main():
mnist_train = datasets.MNIST('mnist', True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True)
x, _ = iter(mnist_train).next()
print('x:', x.shape)
device = torch.device('cuda')
# model = AE().to(device)
model = VAE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
viz = visdom.Visdom()
for epoch in range(1000):
for batchidx, (x, _) in enumerate(mnist_train):
# [b, 1, 28, 28]
x = x.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = - loss - 1.0 * kld
loss = - elbo
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item(), 'kld:', kld.item())
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
x_hat, kld = model(x)
viz.images(x, nrow=8, win='x', opts=dict(title='x'))
viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))
VAE(Variational Autoencoder)简单推导及理解_cjh_jinduoxia的博客-CSDN博客_vae推导
个人理解的VAE:原图采样成z,将z(符合标准正态分布)的结果映射到x(符合高斯分布μσ),目标是是logP(x)尽可能大














 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









