







NLP-统计分词-隐马尔可夫模型实现
一、HMM分词思想
HMM是将分词作为字在字串中的序列标注任务来实现的。
其基本思路是:每个字在构造一个特定的词语时,都占据着一个确定的构词位置(即词位)。现规定每个字最多只有四个构词位置,即
B
B
B(词首)、
M
M
M(词中)、
E
E
E(词尾)和
S
S
S(单独成词)。
二、HMM模型构建
1. 模型状态集合
Q Q Q = { B B B, M M M, E E E, S S S}, N N N = 4
2. 观察状态集合
V V V = { 我 我 我, 爱 爱 爱, … } ,句子的集合。
3.观察状态和状态序列
观察序列:小 明 是 中 国 人
状态序列:
B
,
E
,
S
,
B
,
M
,
E
B, E, S, B, M, E
B,E,S,B,M,E
4. 状态转移概率分布矩阵
在中文分词中就是状态序列
Q
Q
Q = {
B
B
B,
M
M
M,
E
E
E,
S
S
S} 的转移概率,这个状态概率矩阵是在训练阶段参数估计中得到。
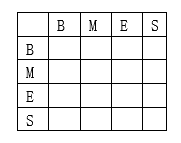
5. 观测状态概率矩阵(发射概率)
在中文分词中发射概率指的是每一个字符对应状态序列
Q
Q
Q = {
B
B
B,
M
M
M,
E
E
E,
S
S
S} 中每一个状态的概率,通过对训练集每个字符对应状态的频数统计得到。
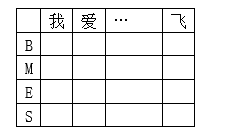
6. 初始概率
在中文分词初始状态概率指的是每一句话第一个字符的对应状态概率。
{
B
B
B:xxx,
M
M
M: xxx,
E
E
E: xxx,
S
S
S: xxx}
7. 目标

max =
m
a
x
P
(
i
1
,
i
2
,
i
3
.
.
.
,
i
T
∣
o
1
,
o
2
,
o
3
.
.
.
,
o
T
)
maxP(i_1, i_2, i_3...,i_T | o_1,o_2,o_3... ,o_T)
maxP(i1,i2,i3...,iT∣o1,o2,o3...,oT)
其中:
T
T
T 为句子长度,
o
i
o_i
oi 是句子的每一个字,
i
i
i_i
ii 是每个字的标记。
根据贝叶斯公式:
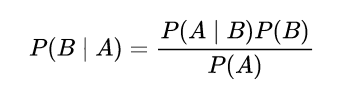
P
(
i
∣
o
)
P(i | o)
P(i∣o) =
P
(
o
∣
i
)
P
(
o
)
P(o | i) P(o)
P(o∣i)P(o) /
P
(
i
)
P(i)
P(i)
根据齐性HMM:
P
(
o
)
=
p
(
o
1
)
p
(
o
2
∣
o
1
)
.
.
.
p
(
o
t
∣
o
t
−
1
)
P(o) = p(o1)p(o_2| o_1)...p(o_{t}| o_{t-1})
P(o)=p(o1)p(o2∣o1)...p(ot∣ot−1), 状态转移概率。
P
(
o
∣
i
)
=
p
(
o
1
∣
i
1
)
.
.
.
p
(
o
t
∣
i
t
)
P(o | i) = p(o_1| i_1)...p(o_{t}| i_{t})
P(o∣i)=p(o1∣i1)...p(ot∣it) , 即观测状态生成的概率(发射概率)。
使 P ( o ) P ( o ∣ i ) P(o) P(o | i) P(o)P(o∣i)概率最大。
三、语料库
人民日报语料库,每行一句话,每个词以空格分隔。

四.python代码实现
1. 初始化类
class HMM(object):
def __init__(self):
# 主要是用于存取算法中间结果,不用每次都训练模型
self.model_file = './data/hmm_model.pkl'
# 状态值集合
self.state_list = ['B', 'M', 'E', 'S']
# 参数加载,用于判断是否需要重新加载model_file
self.load_para = False
# 统计状态出现次数,求p(o)
self.Count_dic = {}
# 统计预料总行数
self.line_num = 0
2. 决定是否重新训练
def try_load_model(self, trained):
"""
用于加载已计算的中间结果,当需要重新训练时,需初始化清空结果
:param trained: 是否训练
:return:
"""
if trained:
with open(self.model_file, 'rb') as f:
self.A_dic = pickle.load(f)
self.B_dic = pickle.load(f)
self.Pi_dic = pickle.load(f)
self.load_para = True
else:
# 状态转移概率(状态->状态的条件概率)
self.A_dic = {}
# 发射概率(状态->词语的条件概率)
self.B_dic = {}
# 状态的初始概率
self.Pi_dic = {}
self.load_para = False
3. 初始化参数
def init_parameters(self):
"""
初始化参数
:return:
"""
for state in self.state_list:
self.A_dic[state] = {s: 0.0 for s in self.state_list}
self.Pi_dic[state] = 0.0
self.B_dic[state] = {}
self.Count_dic[state] = 0
4. 输入的句子做标注
@staticmethod
def make_label(text):
"""
将词语按照 B、M、E、S 标注
B: 词首
M: 词中
E: 词尾
S: 单独成词
:param text:
:return:
"""
out_text = []
if len(text) == 1:
out_text.append('S')
else:
out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']
return out_text
5. 训练
def train(hmm, path):
# 观察者集合,主要是字以及标点等
words = set()
line_num = -1
with open(path, encoding='utf8') as f:
for line in f:
line_num += 1
line = line.strip()
if not line:
continue
# 获取每一行的字并更新字的集合
word_list = [i for i in line if i != ' ']
words |= set(word_list)
# 每一行按照空格切分,分词的结果
line_list = line.split()
line_state = []
for w in line_list:
line_state.extend(hmm.make_label(w))
assert len(word_list) == len(line_state)
# ['B', 'M', 'M', 'M', 'E', 'S']
for k, v in enumerate(line_state):
hmm.Count_dic[v] += 1 # 统计状态出现的次数
if k == 0:
hmm.Pi_dic[v] += 1 # 每个句子的第一个字的状态,用于计算初始状态概率
else:
# {'B': {'B': 0.0, 'M': 0.0, 'E': 0.0, 'S': 0.0}, ...}
# A矩阵更新:第二个状态"M", 获取前一个状态"B", B -> M :加一
# {'B': {'B': 0.0, 'M': 1.0, 'E': 0.0, 'S': 0.0}, ...}
hmm.A_dic[line_state[k - 1]][v] += 1 # 计算转移概率
# {'B': {}, 'M': {}, 'E': {}, 'S': {}}
# ['1', '9', '8', '6', '年', ',']
# {'B': {}, 'M': {'9': 1.0}, 'E': {}, 'S': {}}
hmm.B_dic[line_state[k]][word_list[k]] = hmm.B_dic[line_state[k]].get(word_list[k], 0) + 1.0 # 计算发射概率
hmm.line_num = line_num
# A_dic
# {'B': {'B': 0.0, 'M': 162066.0, 'E': 1226466.0, 'S': 0.0},
# 'M': {'B': 0.0, 'M': 62332.0, 'E': 162066.0, 'S': 0.0},
# 'E': {'B': 651128.0, 'M': 0.0, 'E': 0.0, 'S': 737404.0},
# 'S': {'B': 563988.0, 'M': 0.0, 'E': 0.0, 'S': 747969.0}
# }
# B_dic
# {'B': {'中': 12812.0, '儿': 464.0, '踏': 62.0},
# 'M': {'中': 12812.0, '儿': 464.0, '踏': 62.0},
# 'E': {'中': 12812.0, '儿': 464.0, '踏': 62.0},
# 'S': {'中': 12812.0, '儿': 464.0, '踏': 62.0},
# }
# Count_dic: {'B': 1388532, 'M': 224398, 'E': 1388532, 'S': 1609916}
calculate_probability(hmm)
# 计算概率
def calculate_probability(hmm):
# 求概率,句首状态概率
hmm.Pi_dic = {k: v * 1.0 / hmm.line_num for k, v in hmm.Pi_dic.items()}
# 求概率,转移状态概率
hmm.A_dic = {k: {k1: v1 / hmm.Count_dic[k] for k1, v1 in v.items()} for k, v in hmm.A_dic.items()}
# 加1平滑
hmm.B_dic = {k: {k1: (v1 + 1) / hmm.Count_dic[k] for k1, v1 in v.items()} for k, v in hmm.B_dic.items()}
with open(hmm.model_file, 'wb') as f:
pickle.dump(hmm.A_dic, f)
pickle.dump(hmm.B_dic, f)
pickle.dump(hmm.Pi_dic, f)
6. 维特比算法标注,根据标注分词
def viterbi(self, text, states, start_p, trans_p, emit_p):
V = [{}]
path = {}
for y in states:
V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({})
newpath = {}
# 检验训练的发射概率矩阵中是否有该字
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
for y in states:
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0 # 设置未知字单独成词
(prob, state) = max(
[(V[t - 1][y0] * trans_p[y0].get(y, 0) *
emitP, y0)
for y0 in states if V[t - 1][y0] > 0])
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
if emit_p['M'].get(text[-1], 0) > emit_p['S'].get(text[-1], 0):
(prob, state) = max([(V[len(text) - 1][y], y) for y in ('E', 'M')])
else:
(prob, state) = max([(V[len(text) - 1][y], y) for y in states])
return prob, path[state]
def cut(self, text):
import os
if not self.load_para:
self.try_load_model(os.path.exists(self.model_file))
prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic)
begin, next = 0, 0
for i, char in enumerate(text):
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
yield text[begin: i + 1]
next = i + 1
elif pos == 'S':
yield char
next = i + 1
if next < len(text):
yield text[next:]
7. 测试
if __name__ == '__main__':
hmm = HMM()
hmm.try_load_model(True)
# 初始化状态转移矩阵
hmm.init_parameters()
# print(hmm.A_dic)
# print(hmm.B_dic)
# print(hmm.Pi_dic)
train(hmm, './data/trainCorpus.txt_utf8')
text = '这是一个非常棒的方案!'
res = hmm.cut(text)
print(text)
print(str(list(res)))
8. 结果

















 124
124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











