







NLP-文本表示-词向量
一、词嵌入概述
词嵌入定义:词嵌入(word embedding)是一种词的类型表示,具有相似意义的词具有相似的表示,是将词汇映射到实数向量的方法总称。
one-hot:它忽略了词之间的相关性,当词过多时,维度比较高。
词嵌入:降低维度,使相似的词具有相似的向量表征。

词嵌入生成的方法:

二、词嵌入模型
1、模型的输入输出
模型需要学到句子词与词之间的先后顺序,所以输入为前几个次,预测下一个次的概率。
例如:给定三个单词 Thou shalt not …
模型输入:Thou, shalt
模型输出: not
单词表有 10000 个次就是 10000 分类。

2、词嵌入矩阵建立
明确了输入、输出后。接下来,需要建立一个词嵌入矩阵。
词嵌入矩阵维度:有 10000 个单词,词嵌入的维度是 4,那么词嵌入矩阵的维度就是(10000, 4),每一个单词对应矩阵的一行。
矩阵初始值:随机初始化。
每一次训练,根据输入的单词,在词嵌入矩阵中找到对应的词向量,进行多分类任务训练,反向传播,更新权重,最重要的一点是:模型还会更新词嵌入矩阵权重。

一种查找单词对应词向量的方法: 使用先将所有单词转化 one-hot 编码,用单词的 one-hot 编码与词嵌入矩阵相乘,得到对应单词的词向量。
例如:orange 的 one-hot 编码,除了 6357 为 1,其余位置全为 0。orange 的在词嵌入矩阵的位置同样是 6357。两个矩阵相乘, orange 的 one-hot 编码 只有 6357 为 1, 所以得到 (300,1)的 orange 的词向量。

3、模型数据集的构建
1)简单方式 -NNLM
选择合适适当的窗口,前几个次作为输入,最后一个次做为输出。

具体流程:使用将单词转换为 one-hot 编码,通过one-hot 编码转为对应的词向量,接入线性层,经过 softmax,进行训练。

网络结构:

2)word2vec: CBOW
上述方式只考虑了前面单词,没有考虑后面单词的顺序。
CBOW : 通过上下文的单词来预测目标单词。

3)word2vec: skip-gram
skip-gram : 通过当前单词,预测周围的词

4、负采样
以 skip-gram 为例:当输入分别单词为 not, make, a,machine, in,输出对应如下图:

最终进行多分类任务:

反向传播更新参数和词向量矩阵:

上述任务中,最后一层,需要添加 softmax 层,当词表过大时,计算相当慢。
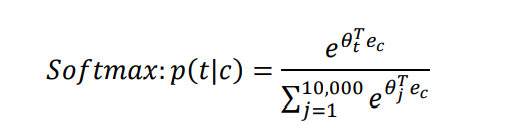
初始方案:假设用一个次预测后一个单词,是一个 10000 分类任务。当把两个单词同时作为输入时,预测两者同时出现的概率,就是一个二分类问题。

上述的数据集转换成如下形式:

数据集中全是正样本,训练效果不好,因此需要增加负样本,即负采样。


由此,每次迭代不是 10000 分类, 而是转为 5 个二分类任务,提高计算效率。
三、整体流程
1、初始化词向量矩阵

2、根据输入查找对应的词向量

3、反向传播更新权重参数以及输入的词向量

















 1605
1605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











