







NLP-tansformer
一、Transformer 整体结果
Transformer源于2017年谷歌的一篇论文Attention is all you need,这篇论文极具创新性,提出了新的Transformer结构,此后在此基础上又出现了GPT、Bert等优秀模型。
Transformer 本质上是一个 Seq2seq模型。以机器翻译i为例,输入一种语言然后将它翻译成其他语言。

其中,Transformer 包含两个部分,Encoders 和 Decoders。

编码组件是一堆编码器(纸上将其中六个堆叠在一起——数字 6 并没有什么神奇之处,当然可以尝试其他排列方式)。解码组件是一堆相同数量的解码器。
编码器在结构上都是相同的,但它们不共享权重。

二、Encoder 结构
Encoder主要作用: 一个输入对应一个输出,可以有多种实现方式,CNN、RNN、self-Attention。在 transformer 中使用的就是 self-Attention (前一篇博客已经详细讲解其实现过程) 。

Encoder主要由两个部分组成: self-Attention 和 Feed Forward

在上述两部分中,都分别包含 残差连接 和 层标准化,即图中的 Add & Norm,两者都是构建有效的深度架构的关键。
具体如下图所示:

计算公式如下:
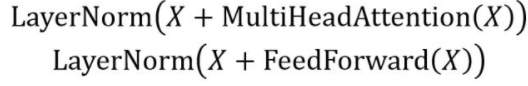
层规范化: 通常用于 RNN 结构,层规范化会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
残差连接:通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,
在 ResNet 中经常用到:
Feed Forward 是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数。
X是输入,Feed Forward 最终得到的输出矩阵的维度与 X 一致, max 代表Relu函数。
对应的公式如下:
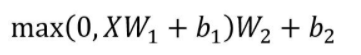
在进一步探索其内部计算方式,我们可以将上面图层可视化为下图:

三、Decoder 结构
1、第一种 decoder - Autoregressive(AT)
Autoregressive 在语音辨识中的运行过程: 机器学习的语音输入到 Encoder 中,输出对应的向量,Decoder 产生语音辨识的结果。Decoder 需要读入 Encoder 的输出(暂不关心)。

接下来,先给 Decoder 一个 START 的特殊字符,Decoder 输出一个词典(哪些需要的输出)长度的向量,经过 softmax,选择概率最大的。
得到的预测结果和之前的输入一起再进行训练,如下图所示:

2、tansformer - decoder结构(使用AT)
Decoder 具体结构如下:

除了中间部分: Decoder 和 Encoder 结构基本一样, 多了Masked.

Masked作用: 前面讲过 Encoder Self-Attention,生成
b
1
b^1
b1 时,会考虑全部句子的信息,而在Decoder 中,不能考虑当前节点后面句子的信息,具体如下图所示:

这么设计原因: Decoder 数据生成的是由 a 1 a^1 a1 到 a 4 a^4 a4,生成 a 1 a^1 a1 时,并不知道后面的信息,因此不能将 a 1 a^1 a1 与后面数据的相关性作为输入。
3、Decoder Autoregressive 停止输出
decoder 需要自己决定输出句子的长度,机器需要自己学到什么该停止。上述结构中,decoder 不知道何时停止输出。
我们要加一个特殊的结束符,告诉 Decoder 停止输出。

我们期望,Decoder 辨识完 “习” 时, 输出 “END”, 这就是 Autoregressive(AT) 的运作方式。

4、第二种 Decoder Non-autoregressive(NAT)
AT:给一个 START,依次输出 w 1 w_1 w1 、 w 2 w_2 w2、 … 、 E N D END END
NAT: 给多个 START, 一起输出 w 1 w_1 w1 、 w 2 w_2 w2、 … 、 E N D END END、… w n w_n wn
NAT无法知道句子的长度,我们应该输入几个 START?
1、decoder 根据 encoder 的输出,该输出代表 decoder 句子长度。
2、输入较长的 START,截取 END 左边的句子。
优点: 平行化,能够控制输出的长度。
缺点: 性能比 AT 差。

6、Encoder - Decoder
tansformer 中 Encoder 和 Decoder 是怎么产生联系的呢?
通过 Cross attention 结构:该结构 两个输入由 Encoder 提供, 一个输入由 Decoder 提供。

decoder 的
q
q
q 和 encoder 的
k
k
k、
v
v
v 进行计算。

四、训练
Decoder 的输入时,是正确的答案。每次生成一个字符与标签对比,使损失函数最小。

最后,要使整句话的平均损失函数值最小。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











