背景介绍
文章标题:Fine-Grained Change Detection of Misaligned Scenes with Varied Illuminations,ICCV 2015,暂无主页,PDF,Code&Dataset1。
本文贡献
所有的变化检测都是针对大尺度、且识别的主体具有显著性的图片进行检测,本文提出的方法可以在毫米级别对差异进行检测。本文起点是相机已经对同一场景拍摄了两组照片2,每组照片相机参数不变,环境光变化。这样子变化检测就可以认为只由一下三个方面影响:
- 环境光
- 相机+镜头的几何畸变
- 被拍摄物体的真实变化
本文就针对以上三点提出了一种从粗到精细、最终使用最小化rank进行变化检测的方法。
实现方法
在讲述方法前,先回顾一下本文目标、前提条件、以及难点。目标是做精细的变化检测,前提条件是相同位置拍摄的两组图片,且两幅图片位置相差几乎很小,每组照片有
K+1
幅图像构成,分别为单纯环境光,与加上了
K
个方向的有向光拍摄,这样子好处就是可以对细微变化检测(并且简单方便够便宜)3,见图1。

难点就是上面说的三个影响因素,我们记一下符号表示:
| 意义 | 符号 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
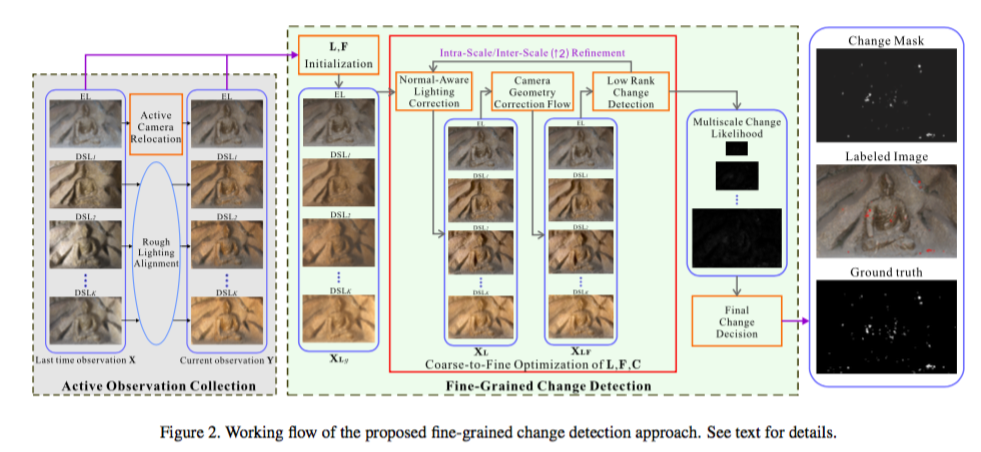
| 上一次的照片组 | 本文使用到的方法是coarse-to-fine的方法迭代的对上面的三个影响因素求解。为保证结果的准确性,先简单介绍了一下相机重定位的原理。整体流程见图2。 1. 数据采集就是相机重定位的过程,假设上一次拍了一组照片 X ,这次需要排到几乎相同位置的一组照片 Y ,相信很多有摄影经验的人都知道这是很困难的,因为手抖一下相片都会模糊,这时隔好几个月或者一年的两张照片怎么能一样。这里我们通过不断的调整相机的姿态完成,使用到了单应矩阵(homography matrix),假设上一次拍的图片是 Rb ,这一次当前图片 Rr ,相机姿态是 Ic ,我们有单应矩阵使得 Rr=HRb ,通过单应矩阵 H 来调整相机姿态是 Ic ,循环拍摄-调整几次之后我们就得到了一个基本相同的 Rb 和 Rr 。 2. F 的初始化因为
X
和
Y
中图片的光照是一一对应的,可以先假设有一个全局的环境光打在一幅图片
xi∈R3×N
上,形成
Aixi+bi
,即
yi
的近似。其中的
[A^i,b^i]=argminAi,bi||Aix~i+bi−y~i||2F
其中 x~i 和 y~i 是SIFT匹配点对的RGB值形成的矩阵。这个方程就是一个最小二乘法求映射的,把 X 转化为了 XF 。 3. Normal-aware lighting correction上小节假设加的是全局环境光,本小节假设加了局域光,用到Lambertian reflectance model,对每个像素
p
,有
xLFp=∫⟨np,ω⟩ρp(Lx(ω)+Lv(ω))dω=xFp+Lvp=yp
第二个等号后面,第一项 xFp 是上小节处理过后的图片的像素 p 位置的值,第二项
Li=argminLv∑p(xiFp+Lvp−yip)2exp(−Cpσ)+α∑p∼qωpq(Lvp−Lvq)2
第一个求和符号保证的是拟合程度高,其中 Cp 表示上次检测时,此像素变化情况,如果接近1则表示上次变化很大,进而 exp(−Cpσ) 接近于零。也就是说,对于变化区域不用追求光照一致化,免得光照矫正把微小变化给搞没了。 第二个求和符号项鼓励局域光平滑性好。 p∼q 表示相邻的像素, ωpq 就是两个像素的相似度,求法是使用色度(照片颜色除以光强)。 于是我们得到局域光调整过后的图片 XL 。 4. 相机几何校正引用自Sift flow: Dense correspondence across scenes and its applications,改了一下能量方程:
E(F)=∑i,p||xiL(p+Fp)−yi(p)||1exp(−Cpσ)+β∑p||Fp||22+∑p∼qmin(γ||Fp−Fq||1,d)
具体实现可以看一下被引用的文章 4。本文里说使用1小节中的方法就可以初始化 F 了。 此步骤后图片的标记变为 XLF 。 5. Low-rank变化检测重点来啦,各位请打起精神,这一节我们就会得到一个变化概率图像。 然后建立了目标方程:
argminZ,E||Z||∗+λ||E||1+κ||TE||2Fs.t.O=Z+E
Z 表示不变部分, E 表示非常离散的变化部分, T=diag(A,A,A) 表示像素的相邻关系,如果两个像素 pq 相邻,有 App=Aqq=1,Apq=Aqp=−1 ,使用拉格朗日乘子法,目标方程变为:
argminZ,E||Z||∗+λ||J||1+κ||TE||2F+Φ(Y1,O−Z−E)+Φ(Y2,Y−E)
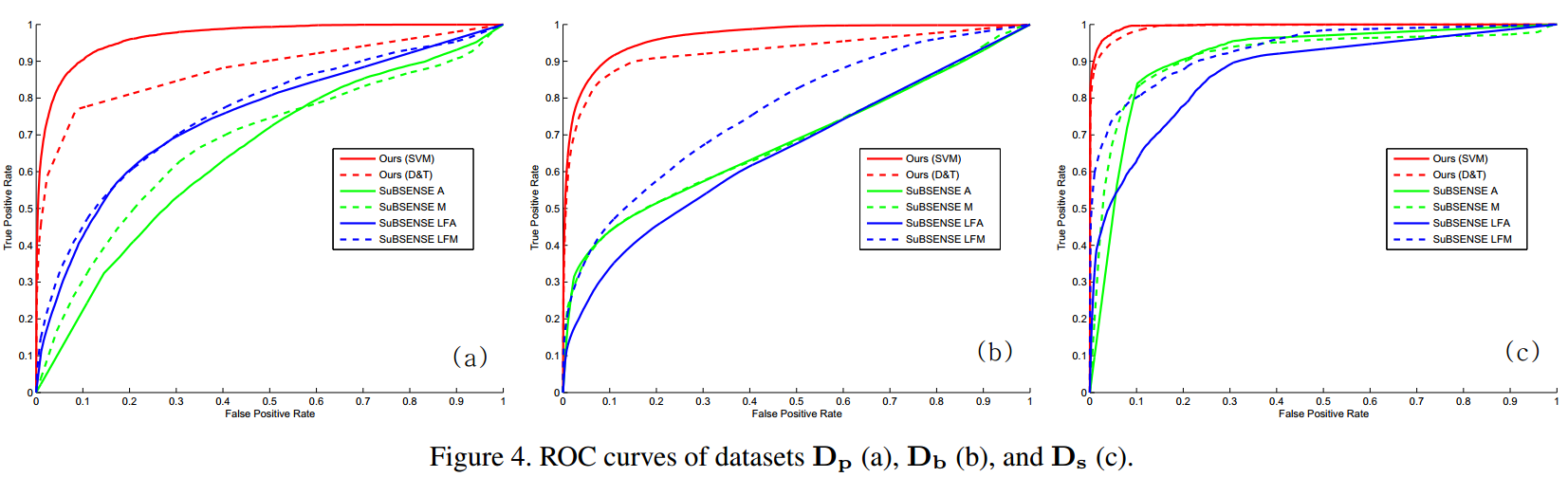
稍微解释一下, Y1,Y2 是拉格朗日算子, Φ(Y,Z)=μ2||Y||2F+⟨Y+Z⟩ ,使用ALM算法求解 5[^cite3]。 最后把 E 取平均值得到差异概率矩阵 C 。 6. Coarse-to-fine优化以及最终结果图2很直观,差不多3到5个循环3-5小节的步骤就能结果收敛,这时候简单的对 C 一个阈值分割就可以得到结果,本文却没这样做。而用了金字塔模型构造了所有层的平局值 Call ,然后用线性SVM分类,像素特征是周围 7×7 网格的线性排列。这样就有了最终结果。 实验结果颐和园数据集 Dp
实验室内壁画试块数据集 Db
雕像数据集 Ds
金字塔模型不同层数的 F-1 measure
02-20
 1145
1145
02-23
755
02-20
685
02-23
2439
01-03
2284
评论 4
  被折叠的 条评论
为什么被折叠? 被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言 到【灌水乐园】发言
查看更多评论

添加红包



|