







Fine-grained Detection —— LIO(2022.02.18)
文章:Look-into-Object: Self-supervised Structure Modeling for Object Recognition
原文IEEE
原文arxiv
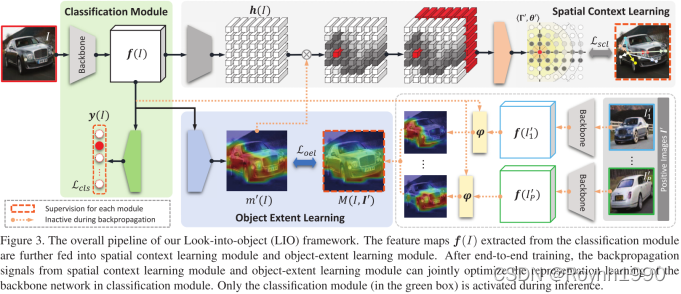
简称LIO,包含2个部分内容,OEL和SCL模块可以完全去掉,几乎没有额外的推理开销:
- 目标范围学习OEL(Object-Extent Learning Module)
- 空间上下文学习SCL(Spatial Context Learning Module)
LIO:看体态,检测骨架或罗阔特征,实现细粒度目标检测。
1. Object-Extent Learning Module
OEL目的是定位目标关注范围,实现自监督。
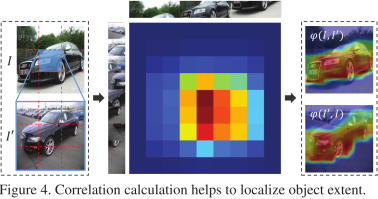
OEL输入为backbone的输出,即特征向量。OEL输出为样本的核心关键区域的Mask。训练阶段,为了学习目标A的范围,它通过采样一定数目与 A同类别的图像,与目标A做区域相似性计算,会得到多个masks,将这些masks进行点乘,最后计算得出一个语义Mask,该Mask矩阵反映了目标A的大致范围。
2. Spatial Context Learning Module
SCL目的是学习目标的不同部分的位置关系。
对目标区域的非中心部分与目标区域的中心部分(极坐标原点)的极坐标进行预测,距离计算采用MSE。中心部分(极坐标原点)是OEL给出的Mask的“核心”。
3. My Thinking
3.1. OEL部分
-
这部分应该与Faster R-CNN中ROI目的一样,就是得出感兴趣区域。不同的是,OEL用对比的方式学习各类别的Mask,而不是闷头学样本集。这意味着,针对各类目标都需要各自有单独的对比样本集合,并且这个对比样本集合质量很有可能左右OEL的输出质量。换句话说,我认为数据上的前期工作可能相比OEL训练更重要。
-
感觉跟DCL有同样问题。原图拆分成子区域后,负样本(背景)区域变得更集中,而目标变得更稀疏。所以我认为,这篇文章的做法不适用于目标可拆分的场景和背景特点有明显规则的场景。假设对比样本集和训练样本来自于同样场景,那OEL更容易侧重学习背景特点,因为背景比目标更具有共性。
3.2. SCL部分
-
这部分的输入来源于OEL,可想而知OEL左右了训练质量。我认为这有点像在不确定结果上乘另外一个不确定结果。
-
原文上看,感觉SCL更注重关注骨架或轮廓的特征。
4. My Summary
OEL迫使backbone关注目标大致范围。
RAN迫使backbone侧重关注目标骨架或轮廓特征。














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









