







背景
论文地址:R-FCN: Object Detection via Region-based Fully Convolutional Networks
代码地址:GitHub
贡献
文章发表于 NIPS 2016,何凯明组新品。训练和测试速度比上一篇 Faster R-CNN 都有提高,单张图片测试用时 170ms,比 Faster R-CNN 快 2.5-20 倍,并且准确度略有提升(0.2%?)。
之前做法
R-CNN 系列对物体检测主要步骤是先提 proposals,然后对每个 proposal 单独做分类,同时微调 proposal 位置,最终使用非极大值抑制方法去除重叠的 proposal 得到最终结果。
Fast R-CNN 将提取 proposal 纳入神经网络范围,将神经网络最后一个 Pooling 层修改为 RoI 层,自此神经网络基于这个 RoI 层被分为前后两部分,Fast/Faster R-CNN 在 RoI 层之后的神经网络对每个 proposal 进行运算时,都有一个神经子网络,产生大量计算。
方法
本文通过 pooling + voting 方法去除了 RoI 后面子网络引出的大量计算,提高了训练和测试速度。下表可以看到,RoI 层后面子网络层数越来越少,在 R-FCN 中彻底干掉了。

那没有了子网络产生了一个问题,RoI 层后面接什么,怎么训练?
物体检测模型
作者这里提出了一个理论,图片分类要求网络具有平移不变性(这也是为什么在 RoI 之前加入全连接层表现不好的原因),而物体检测恰恰需要平移可变性。为了使 RoI 层后面具有平移可变性,作者提出在提出 RoI 层之后加入
k2
个 position-sensitive score map。Map 中一点的值为点到某一 Region 的距离,如到物体左上角/中心距离(此处留疑如何通过卷积获取)。
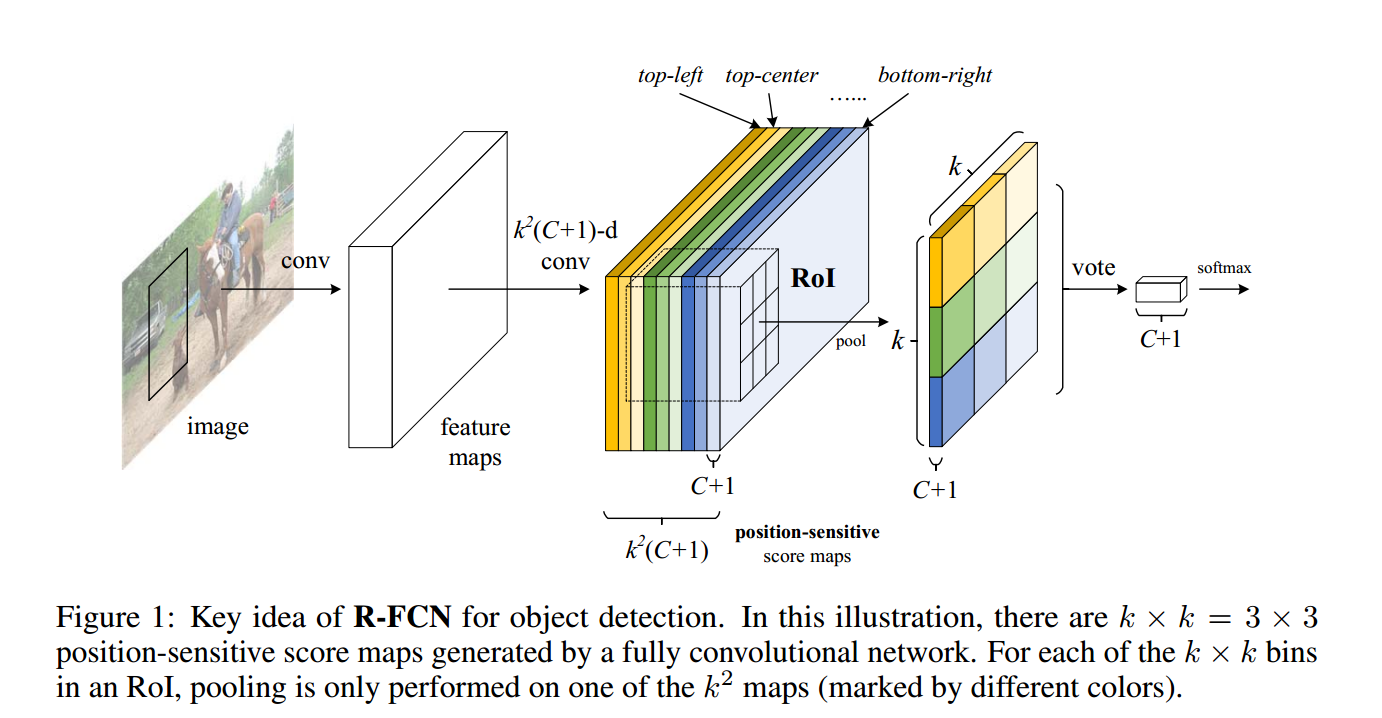
到这里我们可以看到每个 RoI 都对应了
k2(C+1)
个 map,假设有一个 RoI 宽高为
w, h
,做 selective pooling。具体为将 RoI 也划为
k2
个相同面积网格,每个网格 pooling 一个值,但注意一点是前面的
k2(C+1)
个 map 中,每个种类只 pooling 其中一个 position-sensitive score map。
说了这么多大家可能有点懵,看上面那张图,第三步中的颜色表示到不同位置距离产生的 map,而每种颜色中 map 只取网格中一块进行 pooling,输出结果到第四步图。简单求和(voting)产生第五步图,使用 softmax 标准 loss function。
边界回归模型
使用和物体检测相似方法,对 t=(tx,ty,tw,th) 产生 4k2 个 position-sensitive map,使用 selective pooling 得到 4 维向量,同 Faster R-CNN 相同的方法更新。
训练
- Loss Function 和 Fast R-CNN 相同
- weight decay = 0.0005
- momentum = 0.9
- single scale, shorter size of image = 600 pixel
- 交叉训练 RPN & F-RCN,同 Faster R-CNN
- -
实验
- 非极大值抑制的 IoU 阈值为0.3
- 洞洞算法1
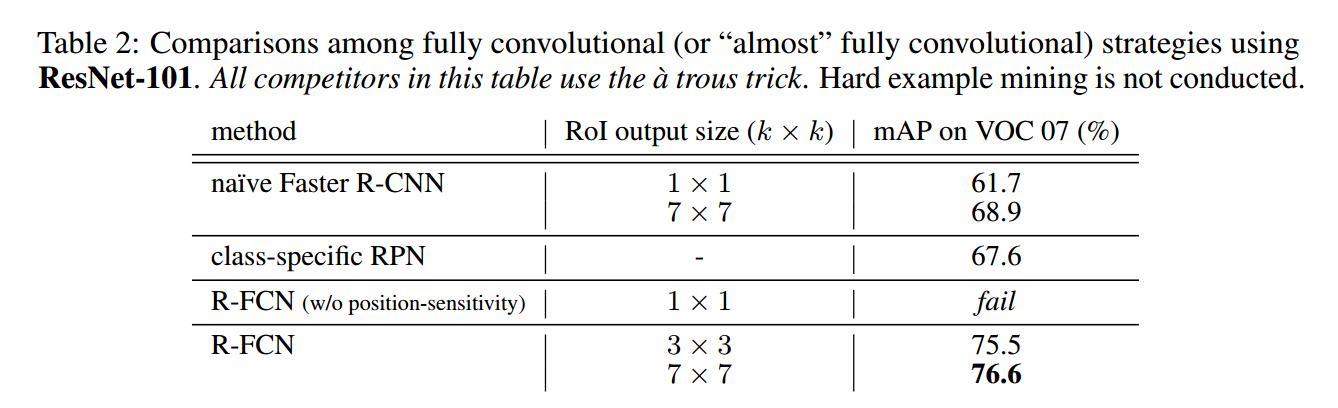
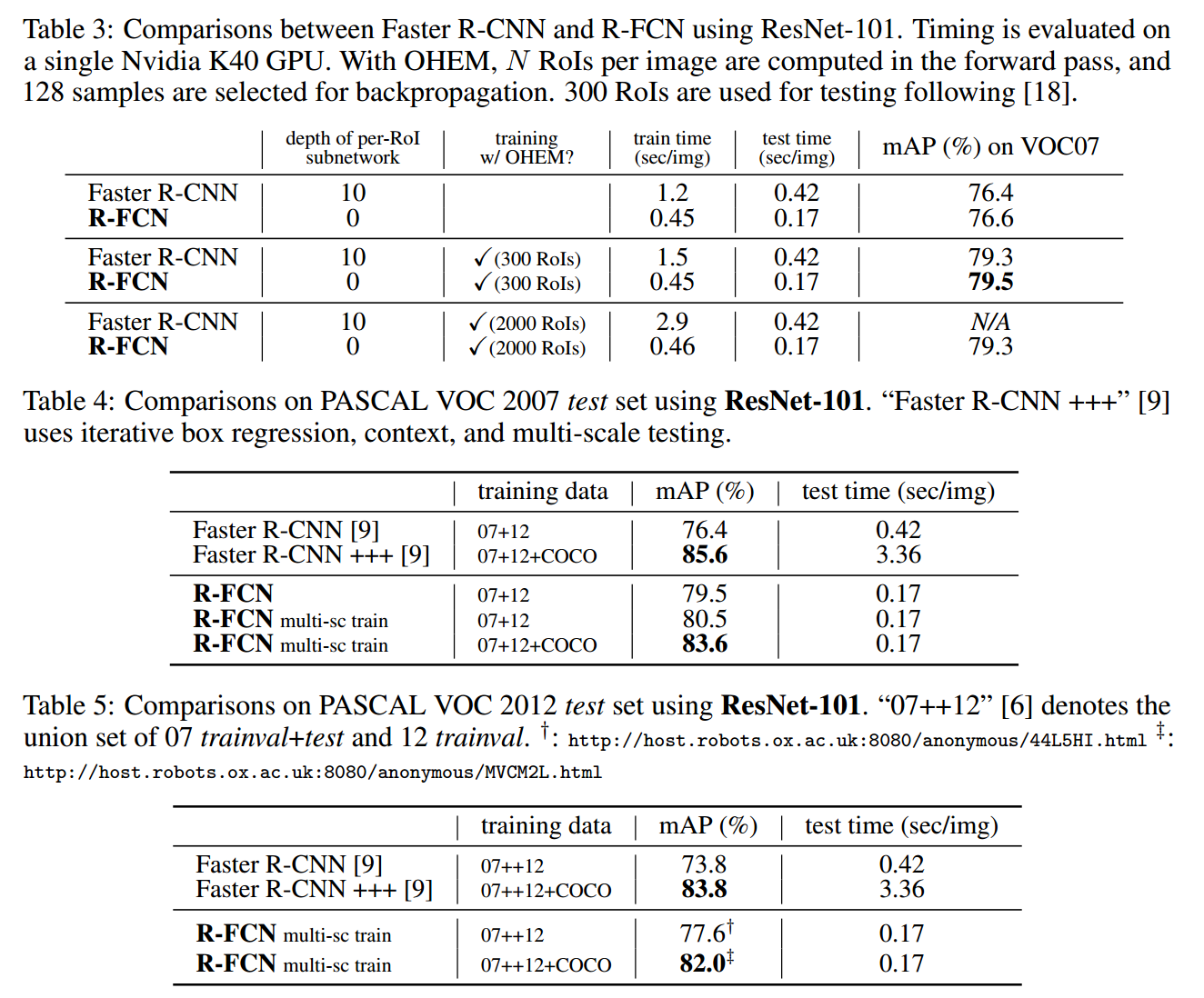















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









