







背景
之前听说过DenseNet,再次被提起是因为七月初上交大主办的SSIST 2017,Yann Lecun的一页PPT,将其地位放置到如此之高,查了一下是CVPR 2017的一篇Oral,于是下定决心好好拜读一下。1

文章地址:https://arxiv.org/abs/1608.06993
代码地址:Torch版本,TensorFlow版本,MxNet版本,Caffe版本,
方法
我们回顾一下ResNet,大意就是本层的激活值与本层的输入,作为本层的输出。换一种方式理解,第
l
层的激活值不仅仅影响
- 与传统的卷积网络相比,需要更少的参数就能得到相同的效果。这里指出一点,参数少并不意味计算量降低,实验前向速度并未比ResNet降低。作者给出的原因是每层的输入包括之前的所有层,所以可以避免传统网络中冗余的层;
- Densenet改变了传统网络反向传递时,梯度(信息)传播方式,由线性变成树状反向,这样的好处就在于减少了梯度消失的可能,并且加速训练,有利于更深层网络的训练;
- 作者发现稠密的网络结构有类似正则功能,在小数据集合上更好的避免过拟合。
实现
对于输入图像
x0
定义一个
L
层的网络,他的第
xl=Hl(xl−1)
,在ResNet中我们有
xl=Hl(xl−1)+xl−1
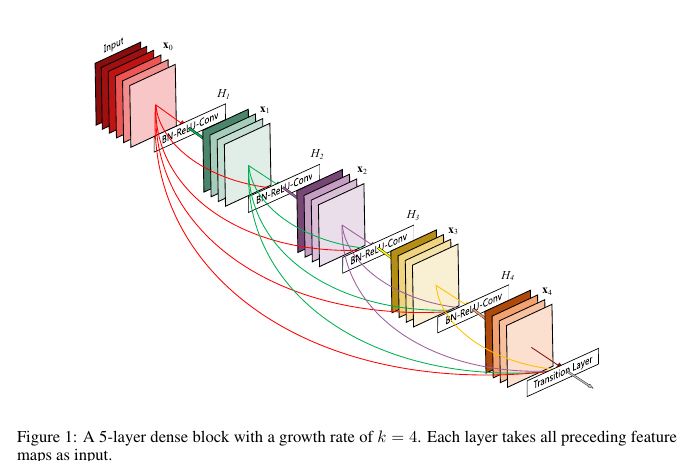
。作者指出由于单纯使用求和操作可能会干扰网络信号的传递。于是提出不是简单求和,而是将前面的结果放入新的channel通道,然后进行非线性操作,于是我们有
xl=Hl([x0,x1,...,xl−1])
。同ResNet一样,这里的
Hl(·)
是BN+ReLU+Conv的组合。但是我们可以看到在上面的
[x0,x1,...,xl−1]
如果维度的尺寸不同的话,无法进行操作的,于是作者使用了模块的方式,模块内部没有Pooling操作,这样避免了形状不同。模块之间有Pooling操作。如下图

作者又尝试了 Hl(·) 输出channels个数(记为 k )对消耗和结果的影响,channels个数越多网络参数越多,计算量更大。
Hl(·) 是BN+ReLU+Conv(1x1)+BN+ReLU+Conv(3x3)的组合,这种网络记为Densenet-B- 假设Dense模块之间的卷积输出channels个数是模块输出层数的 θ 倍,如果 θ<1 网络记为Densenet-C,一般我们设 θ=0.5
- 同时上面两种情况记为网络Densenet-BC
网络参数不放了,直接结果:
- From Weibo: http://weibo.com/2805770701/Fb6gC2TTv ↩


















 4253
4253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









