







TAPAS: Weakly Supervised Table Parsing via Pre-training
原论文理解解读
这里只进行原论文解读,若有不正确的地方希望指正,不明白的地方我也会写上,如果后续有时间继续进行TAPAS的改进方法和论文阅读。
总体流程
对于bert模型先进行大规模tableqa数据的pre-training,然后进行三个数据集(WIKITQ、SQA、WIKISQL)的微调。
下面就分两部分进行解释。
先说下embedding吧
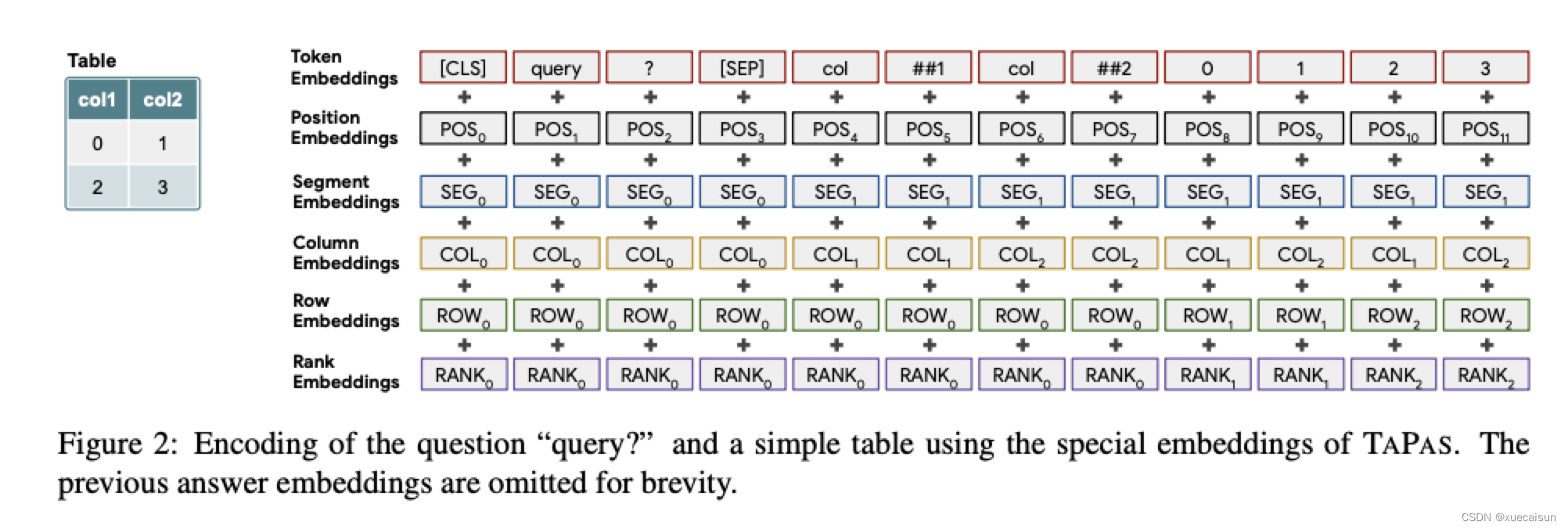
这个表就很清晰了,query就是question了(pre-training过程是与表相关的文本),query和表格信息用[SEP]分隔,表格是平摊(flatten)后输进去的,##1和##2估计是列名。
- token embedding:standard BERT tokenizer,数字和日期类似Neural Programmer(没看了,有兴趣自己去看看:Learning a natural language interface with neural programmer.)
- Position Embedding:位置index了,和BERT一样
- Segment Embedding:query用0,table用1,和BERT 一样
- Column Embedding:query用0,table用1,2,3等等,表示表格中的第几列
- Row Embedding:query用0,table用1,2,3等等,表示表格中的第几行
- Rank Embedding:如果表格中某些列是可排序的,如数字、日期,则用自然数1-n,1表示最小,依次排序。其余不可排序的如string之类的都用0
实际还有一个Previous Answer,对于某个表格的连续问答,其中当前的问题可能指向前一个问题或它的答案,我们添加一个特殊嵌入,标记一个单元格是否是前一个问题的答案(1表示是前一个问题的答案,0表示其他)。这个1的表示只会在连续问答数据集中出现,这篇文章的连续问答数据集是SQA
大规模数据pre-training
数据集
- Infobox 3.3M 表格
- WikiTable 2.9M 表格
在这里表明只使用横向表格(应该是为了表格编码的简单,纵向表也还好吧,做个简单的转置就能转成横向表了)。对于Infobox数据,只用了表头和一行表数据信息,而且论文说这个数据集并不是非常典型的数据集,但是也还是提升最后的效果。
表格信息有了,那文本信息呢?当然这里没有对于表格的question了,每个表格对应的文本信息是爬取当前表格所在文章的标题,文章的描述,表的标题,以及表格所在段落的段落小标题和文本。
训练过程
- 仿照Bert的MLM,文章说也尝试了用bert的第二个任务(NSP)但是对最终任务没有提升,MLM和bert有一丢丢小区别,就是mask的token如果是某个单词的一部分(如:单词:philammon,经过tokenizer变成三个token:phil ##am ##mon),那就把整个单词全部mask掉。
- input长度,文章用的输入长度是128,那么对于长的文本信息,只随机从原相关文本中选取8-16个 word pieces,对于表格,这个也很长,那就先只使用表格头和内容的头一个单词(原文:
To fit the table, we start by only adding the first word of each column name and cell. We then keep adding words turn-wise until we reach the word piece budget),对于一个表格,取10个8-16个word pieces,这样就是一个表格就有10条训练数据。
Finetune过程
这个过程还是很重要的,私以为是这篇文章的精华所在,因为这篇文章通篇都在讲我们是Weakly Supervised,这里就讲述了为什么是Weakly,和其他的tableqa有什么区别,如何实现。
首先Weakly是指不需要tableqa的逻辑形式,正常tableqa任务是使用seq2seq或者其他形式生成类似sql的格式,如select count(name) from TABLE where value>3,然后通过这种逻辑形式去表格中查询答案,得到结果。这篇文章就说我们不需要这种逻辑结构,那如何实现呢?
首先就是模型架构
原文有个图:
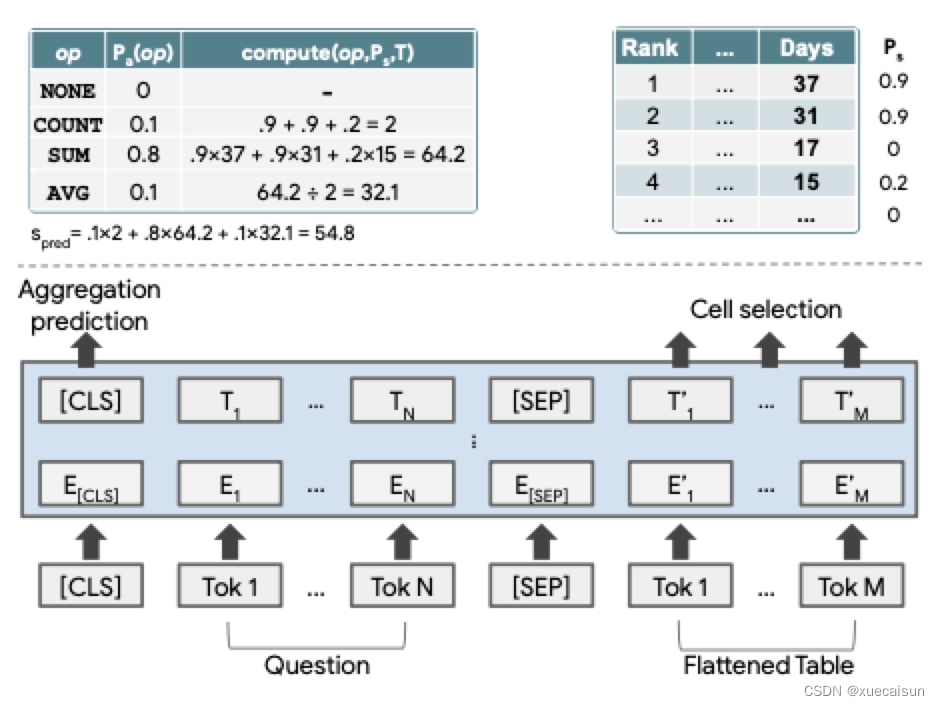
基础架构还是Bert了(这里再啰嗦一下,文章是号称使用了简单的模型结构实现了更好或者有竞争力的结果,那这里的简单是相对于别人使用encoder-decoder模型的,这里只是使用了bert,只有encoder)。
输出分为两部分:
- 一个是agg输出(None、Count、Sum、Average等),用的就是cls的的隐藏层输出
- 另一个是table的每一个cell的隐藏层输出,这里实际是两个任务:
- 一个是使用每个cell的token隐藏层的平均embedding进行softmax,二值判断是否选取该cell。
- 另一个是使用列的所有token隐藏层的平均embedding进行softmax,二值判断是否选取该列。
最后的结果是该列该行都要满足,如果所选cell的所在列不被选取,那么该cell也不被选取。
三种情况
上文说到这是weakly supervised,也就是说只有答案,没有逻辑结构,那么对于这个答案,如何进行训练呢?分三种情况
- Cell Selection:table中存在答案原文的,且只出现一次(出现多次的sample过滤掉),如下图question1
- Scalar Answer:table中没有,通过agg计算得到的,如下图question2
- Ambigous Answer:table中有,但是agg计算也可以得到答案的,如下图question4

Cell Selection
这个简单,主要分为三部分损失:
列选择binary交叉熵损失J-columns,cell选择binary交叉熵损失J-cells,以及agg判别为非None的l对数损失J-aggr: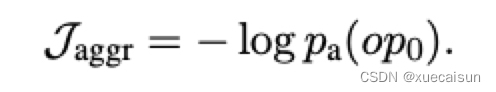
最终的结果就是三部分损失的加和。
Scalar Answer
这里是指结果是一个数字标量,而且在原表格中找不到该标量,拿这肯定是通过agg(count,sum,avg)操作得到的,但是我们并没有agg label以及column select label,label只有一个最终标量结果。这样的话如何进行反向传播学习?
这里的做法是将当前结果进行回归预测,通过概率进行连续值计算:
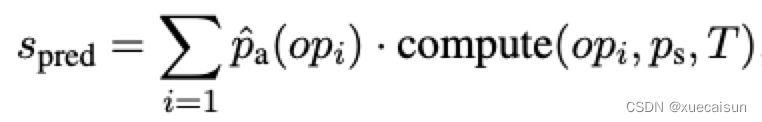
这个公式就是开篇那张图的计算解释了:
question:Total number of days for the top two
columns select and cell select:选中的是Days列,cell选择的是1,2,4行,概率值分别为0.9,0.9,0.2,其余概率为0(这里只是为了举例,实际概率值并不会有很多零值概率,文章后来为了从连续概率去预测离散值,加了一个temparature进行二值化,原文:In addition, as computation done during training is continuous, while that being done during inference is discrete, we further add a temperature that scales token logits such that ps would output values closer to binary ones)
agg select:count:0.1,sum:0.8,avg:0.1
所以在这里就计算每个agg结果:
count:(0.9 + 0.9 +0.1)* 0.1 = 0.2
sum:(0.9* 37+0.9* 31+0.215)0.8 =51.36
avg: (0.9 37+0.9 31+0.2*15)/3 * 0.1 = 2.14 (图中这里除错了,应该是除3)
所以最终结果pred就是全加起来:53.7
损失函数这里并没有用回归常用的平方损失,而是使用了一个叫Huber loss的:
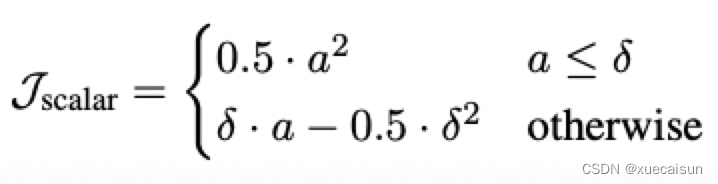
解释说的是这个损失更稳定一点,图中a = pred - scalar label
另外,这里还对agg结果判为None进行了惩罚,用的还是对数损失,是将判为除None以外的其他所有概率加和,说明这个概率值越小,那么判别为None的概率就越大,损失值就越大,惩罚越高:
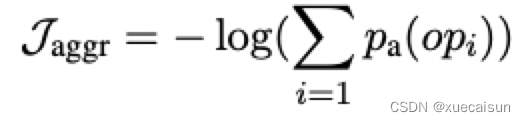
最终的损失结果是:
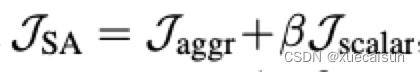
如果有异常值,比如预测结果和label差别太大,那么这个损失公式的beta=0,这样就可以避免异常值(异常判断是J-scalar大于某个数值)。
这里就有一个疑问了,对于结果预测值的计算,也就是S-pred那个公式,可以进行反向传播吗,反向传播的充分必要条件是该公式处处可微,文章其实给出了推导和解释,最终的结果是软可微(soft differentiable),这部分推导我没看了,感兴趣的可以自己去原文中看一看。
Ambiguous Answer
这里就是混淆部分了,既可以在table中找到一模一样的,又可以通过agg计算得到,那这部分如何计算?
这里的解决方案是通过模型自己去判断,如果agg结果是sum、count、avg(概率值超过某个设定的阈值),那就是agg操作,如果agg结果是None,那就直接在table中select。
实验结果
finetune数据集
前面也提过,这里进行微调的数据集有三个:
- WikiTQ:没有逻辑形式,不是连续问答,有agg操作,22033 example,2108 tables
- SQA:没有logical Form,这个是连续问答(平均每轮2.9个问题),但没有agg操作,17553 examples, 982 tables
- WikiSQL: 有logical Form,后续实验也试过完全监督,效果的确要比软监督稍好,非连续问答,有agg操作,80654 examples,24241 tables
结果
最终结果图懒得贴了,大致是:
WikiSQL:test 83.6 / test 86.4(fully-supervised),这篇文章比较早,2020年的好像,当时的确效果很好了,现在test上最高能到93了(SeaD改进版,这个我后面应该还会写一篇解读),而为什么现在都2022年了我还在看2020年的文章,因为这个是google出的,hugging face有非常成熟的源码和各种model,既可以直接拿来用,又可以继续改进继续训练。Docs ,models
WikiTQ:test 42.6/ test 48.7 based wikiSQL / test 48.8 based SQA
SQA:test 67.2 avg/ 40.4 all seq/ 78.2 question1/ 66.0 question2/ 59.7 question3
后续还对embedding做了测试实验,就是去掉rank embedding或者其他各种embedding对结果的影响,果然大佬就是大佬,这么多实验看得我头皮发麻,要我的话是真的懒得做这么多实验的。
转载请注明出处!















 4473
4473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









