







 本文介绍了论文ANOMALY TRANSFORMER,该论文提出利用Transformer结构进行时序异常检测。创新点包括计算Association Discrepancy评估异常和采用Minimax Strategy放大差异。通过Anomaly-Attention、Prior-Association和Series-Association,论文提出了一种适应不同时间序列模式的方法,增强了正常与异常序列的区分度。
本文介绍了论文ANOMALY TRANSFORMER,该论文提出利用Transformer结构进行时序异常检测。创新点包括计算Association Discrepancy评估异常和采用Minimax Strategy放大差异。通过Anomaly-Attention、Prior-Association和Series-Association,论文提出了一种适应不同时间序列模式的方法,增强了正常与异常序列的区分度。
最近又在做异常检测方面,所以这里记录一下比较经典的基于transformer的时序异常检测文章。
这篇文章是2022年的,算是比较新的,目前时序检测的新文章并不多,一方面这个时序异常检测在模型和计算上都不算难,再怎么创新也没什么太大水花,另一方面异常检测中的时序检测已经比较成熟了,大家更关注异常检测中的图像和音频之类的。
这篇论文的创新点有两个:
- 借鉴了transformer结构,提出了Prior-Association和Series- Association,计算Association Discrepancy,用以评估异常
- Minimax Strategy,用来放大Association Discrepancy
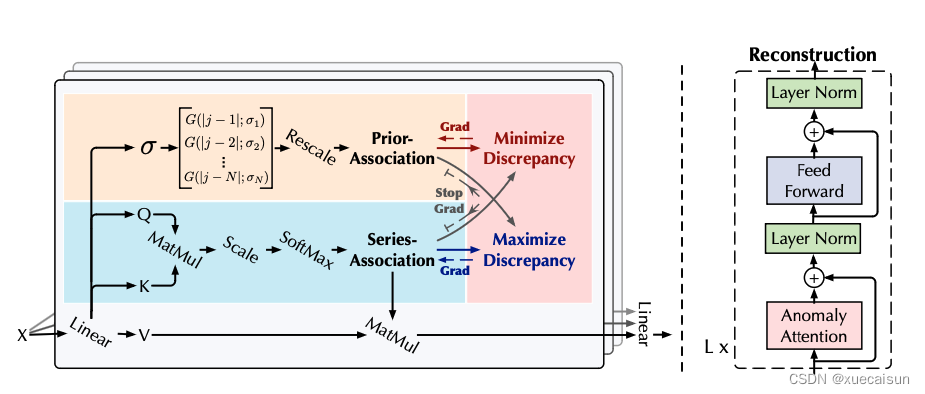
关于第一个创新点在上图
右边的框架就是仿transformer的,输入序列,
表明框架的层数,N为序列长度,d表示输入维度,总体计算:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6175
6175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









