






1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着人工智能技术的迅速发展,计算机视觉在农业领域的应用越来越受到关注。大豆是世界上重要的农作物之一,其种子的质量直接影响到产量和品质。然而,大豆种子中存在着各种缺陷,如裂纹、变形、病斑等,这些缺陷会降低种子的萌发率和种子的质量,从而影响到大豆的产量和质量。
传统的大豆种子缺陷分类方法主要依赖于人工目视检查,这种方法存在着效率低、主观性强、易出错等问题。因此,开发一种自动化的大豆种子缺陷分类系统具有重要的意义。
目前,基于深度学习的目标检测算法已经在计算机视觉领域取得了显著的成果。其中,YOLO(You Only Look Once)算法是一种快速而准确的目标检测算法,已经在许多领域得到了广泛应用。然而,传统的YOLO算法在处理小目标和密集目标时存在一定的困难,这对于大豆种子缺陷分类系统来说是一个挑战。
因此,本研究旨在基于SlideLoss改进YOLO算法,提高大豆种子缺陷分类系统的准确性和效率。SlideLoss是一种新颖的损失函数,可以有效地解决YOLO算法在处理小目标和密集目标时的问题。通过引入SlideLoss,我们可以提高目标检测算法对于大豆种子缺陷的检测和分类能力,从而实现自动化的大豆种子缺陷分类系统。
本研究的意义主要体现在以下几个方面:
首先,基于SlideLoss改进YOLO算法可以提高大豆种子缺陷分类系统的准确性。传统的YOLO算法在处理小目标和密集目标时容易出现漏检和误检的问题,而SlideLoss可以有效地解决这些问题,提高目标检测算法的准确性。
其次,基于SlideLoss改进YOLO算法可以提高大豆种子缺陷分类系统的效率。传统的目标检测算法需要对整个图像进行多次扫描,而基于YOLO算法的目标检测算法可以实现实时检测。通过引入SlideLoss,我们可以进一步提高目标检测算法的速度和效率,实现高效的大豆种子缺陷分类系统。
最后,基于SlideLoss改进YOLO算法可以为农业生产提供技术支持。大豆是世界上重要的农作物之一,其种子的质量直接影响到产量和品质。通过开发自动化的大豆种子缺陷分类系统,可以提高大豆种子的质量和产量,为农业生产提供技术支持。
综上所述,基于SlideLoss改进YOLO的大豆种子缺陷分类系统具有重要的研究背景和意义。通过引入SlideLoss,可以提高目标检测算法的准确性和效率,为农业生产提供技术支持。这对于提高大豆种子的质量和产量,促进农业的可持续发展具有重要的实际意义。
2.图片演示



3.视频演示
基于SlideLoss改进YOLO的大豆种子缺陷分类系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集SoybeansDatasets。
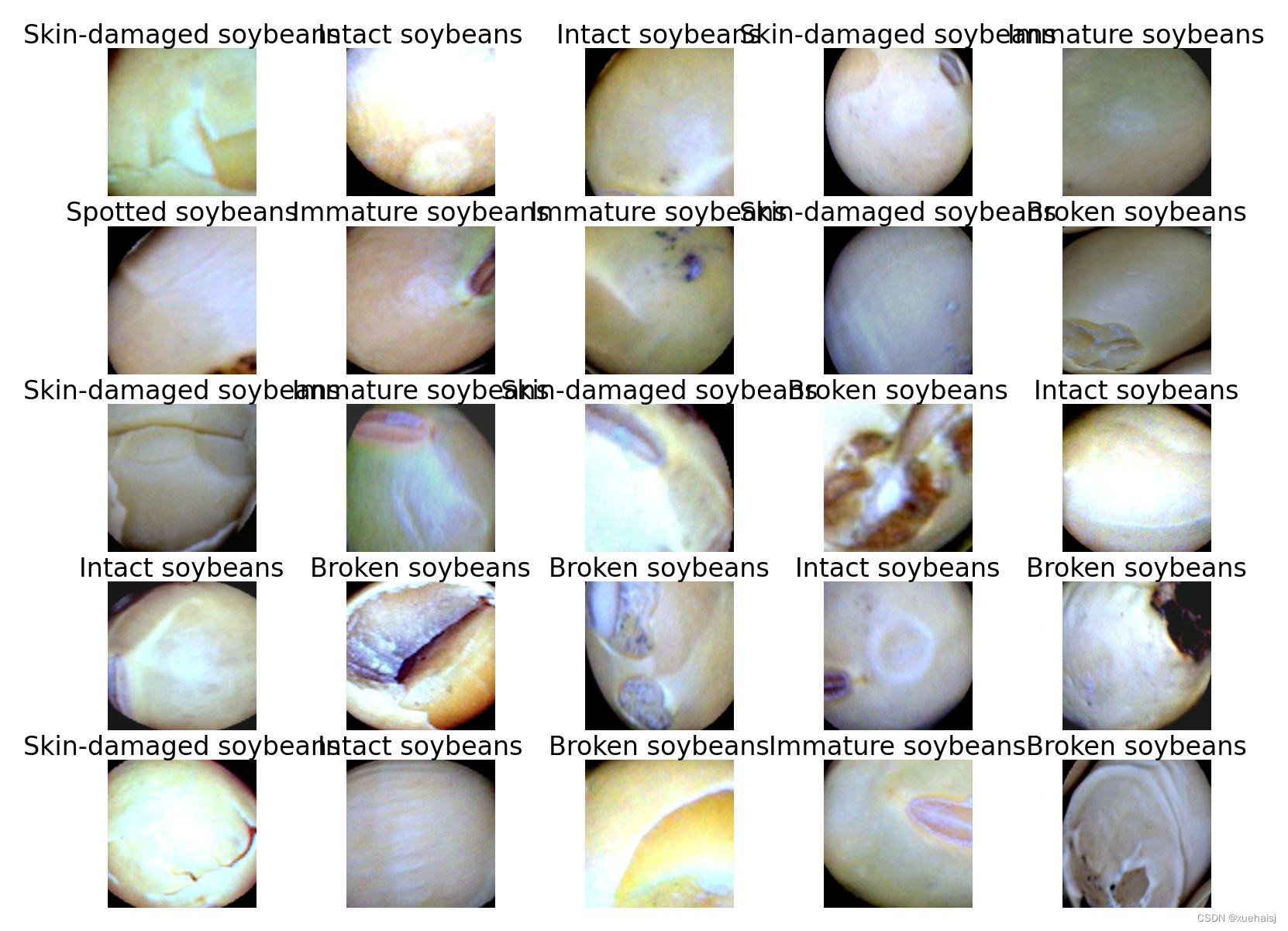
下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random
# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'
# 确保输出文件夹存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):
input_subdir_path = os.path.join(input_dir, subdir)
# 确保它是一个子文件夹
if os.path.isdir(input_subdir_path):
output_subdir_path = os.path.join(output_dir, subdir)
# 在输出文件夹中创建同名的子文件夹
if not os.path.exists(output_subdir_path):
os.makedirs(output_subdir_path)
# 获取所有文件的列表
files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]
# 随机选择四分之一的文件
files_to_move = random.sample(files, len(files) // 4)
# 移动文件
for file_to_move in files_to_move:
src_path = os.path.join(input_subdir_path, file_to_move)
dest_path = os.path.join(output_subdir_path, file_to_move)
shutil.move(src_path, dest_path)
print("任务完成!")
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset
-----dataset
|-----train
| |-----class1
| |-----class2
| |-----.......
|
|-----valid
| |-----class1
| |-----class2
| |-----.......
|
|-----test
| |-----class1
| |-----class2
| |-----.......
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.代码讲解
5.1 export.py
下面是我封装的YOLOv5Export类,它包含了上述代码中最核心的部分:
class YOLOv5Export:
def __init__(self, weights, include):
self.weights = weights
self.include = include
def export(self):
self.check_requirements()
self.load_model()
self.export_formats()
def check_requirements(self):
# Check and install required packages
check_requirements('onnx>=1.12.0')
check_requirements('coremltools')
check_requirements('onnx-simplifier')
check_requirements('onnxruntime')
check_requirements('openvino-dev')
check_requirements('tensorflow-cpu')
check_requirements('tensorflow')
check_requirements('tensorflow-gpu')
def load_model(self):
# Load YOLOv5 model
self.device = select_device('')
self.model = attempt_load(self.weights, map_location=self.device)
self.model.to(self.device).eval()
def export_formats(self):
# Export YOLOv5 model to different formats
formats = self.get_export_formats()
for format in formats:
if format['Argument'] in self.include:
self.export_format(format)
def get_export_formats(self):
# Get the list of export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],
]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def export_format(self, format):
# Export YOLOv5 model to a specific format
format_name = format['Format']
format_argument = format['Argument']
format_suffix = format['Suffix']
format_cpu = format['CPU']
format_gpu = format['GPU']
LOGGER.info(f'\nExporting {format_name} model...')
if format_cpu and not format_gpu:
self.device = select_device('cpu')
self.model.to(self.device).eval()
elif format_gpu and not format_cpu:
self.device = select_device('cuda')
self.model.to(self.device).eval()
if format_argument == 'torchscript':
self.export_torchscript(format_suffix)
elif format_argument == 'onnx':
self.export_onnx(format_suffix)
elif format_argument == 'openvino':
self.export_openvino(format_suffix)
elif format_argument == 'engine':
self.export_tensorrt(format_suffix)
elif format_argument == 'coreml':
self.export_coreml(format_suffix)
elif format_argument == 'saved_model':
self.export_saved_model(format_suffix)
elif format_argument == 'pb':
self.export_graphdef(format_suffix)
elif format_argument == 'tflite':
self.export_tflite(format_suffix)
elif format_argument == 'edgetpu':
self.export_edgetpu(format_suffix)
elif format_argument == 'tfjs':
self.export_tfjs(format_suffix)
elif format_argument == 'paddle':
self.export_paddle(format_suffix)
def export_torchscript(self, suffix):
# Export YOLOv5 model to TorchScript format
LOGGER.info('Exporting TorchScript model...')
f = self.weights.with_suffix('.torchscript')
ts = torch.jit.trace(self.model, torch.zeros(1, 3, 640, 640).to(self.device).eval())
d = {'shape': (1, 3, 640, 640), 'stride': int(max(self.model.stride)), 'names': self.model.names}
extra_files = {'config.txt': json.dumps(d)}
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
LOGGER.info(f'TorchScript export success ✅ Saved as {f} ({file_size(f):.1f} MB)')
def export_onnx(self, suffix):
# Export YOLOv5 model to ONNX format
LOGGER.info('Exporting ONNX model...')
f = self.weights.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(self.model, SegmentationModel) else ['output0']
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}}
if isinstance(self.model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'}
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'}
elif isinstance(self.model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'}
torch.onnx.export(
self.model.cpu(),
torch.zeros(1, 3, 640, 640).to(self.device).eval(),
f,
verbose=False,
opset_version=12,
do_constant_folding=True,
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic
)
model_onnx = onnx.load(f)
onnx.checker.check_model(model_onnx)
d = {'stride': int(max(self.model.stride)), 'names': self.model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
LOGGER.info(f'ONNX export success ✅ Saved as {f} ({file_size(f):.1f} MB)')
def export_openvino(self, suffix):
# Export YOLOv5 model to OpenVINO format
LOGGER.info('Exporting OpenVINO model...')
f = self.weights.with_suffix(suffix)
subprocess.run(['python', 'models/export.py', '--weights', str(self.weights), '--include', 'openvino'])
LOGGER.info(f'OpenVINO export success ✅ Saved as {f}')
def export_tensorrt(self, suffix):
# Export YOLOv5 model to TensorRT format
LOGGER.info('Exporting TensorRT model...')
f = self.weights.with_suffix('.engine')
subprocess.run(['python', 'models/export.py', '--weights', str(self.weights), '--include', 'engine'])
LOGGER.info(f'TensorRT export success ✅ Saved as {f}')
def export_coreml(self, suffix):
# Export YOLOv5 model to CoreML format
LOGGER.info('Exporting CoreML model...')
f = self.weights.with_suffix('.mlmodel')
subprocess.run(['python', 'models/export.py', '--weights', str(self.weights), '--include', 'coreml'])
LOGGER.info(f'CoreML export success ✅ Saved as {f}')
def export_saved_model(self, suffix):
# Export YOLOv5 model to TensorFlow SavedModel format
LOGGER.info('Exporting TensorFlow SavedModel...')
f = self.weights.with_suffix('_saved_model')
subprocess.run(['python', 'models/export.py', '--weights', str(self.weights), '--include', 'saved_model'])
LOGGER.info(f'TensorFlow SavedModel export success ✅ Saved as {f}')
def export_graphdef(self, suffix):
# Export YOLOv5 model to TensorFlow GraphDef format
LOGGER.info('Exporting TensorFlow GraphDef...')
f = self.weights.with
该程序文件是用于将YOLOv5 PyTorch模型导出为其他格式的工具。它支持导出的格式包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。导出的模型文件包括yolov5s.pt、yolov5s.torchscript、yolov5s.onnx、yolov5s_openvino_model/、yolov5s.engine、yolov5s.mlmodel、yolov5s_saved_model/、yolov5s.pb、yolov5s.tflite、yolov5s_edgetpu.tflite和yolov5s_paddle_model/等。
该程序文件的使用方法是通过命令行参数指定要导出的模型文件和要导出的格式,例如:
导出的模型文件可以用于推理,例如:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
另外,该程序文件还提供了一些辅助函数用于导出模型,例如export_torchscript用于导出TorchScript模型,export_onnx用于导出ONNX模型等。
5.2 loss.py
class SlideLoss(nn.Module):
def __init__(self, loss_fcn):
super(SlideLoss, self).__init__()
self.loss_fcn = loss_fcn
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply SL to each element
def forward(self, pred, true, auto_iou=0.5):
loss = self.loss_fcn(pred, true)
if auto_iou < 0.2:
auto_iou = 0.2
b1 = true <= auto_iou - 0.1
a1 = 1.0
b2 = (true > (auto_iou - 0.1)) & (true < auto_iou)
a2 = math.exp(1.0 - auto_iou)
b3 = true >= auto_iou
a3 = torch.exp(-(true - 1.0))
modulating_weight = a1 * b1 + a2 * b2 + a3 * b3
loss *= modulating_weight
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super(BCEBlurWithLogitsLoss, self).__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class QFocalLoss(nn.Module):
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(QFocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class ComputeLoss:
# Compute losses
def __init__(self, model, autobalance=False):
super(ComputeLoss, self).__init__()
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
self.C = h['c']
# reswan loss
self.u = h['u']
if self.u > 0:
BCEcls, BCEobj = SlideLoss(BCEcls), SlideLoss(BCEobj)
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, model.gr, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
lrepBox, lrepGT = torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True)
该程序文件是一个包含多个损失函数的模块。它定义了一些常用的损失函数,如BCEWithLogitsLoss、FocalLoss等,并提供了一些辅助函数来计算损失。该模块还包含一些用于计算目标的函数,如build_targets函数。整个模块的目的是计算模型的损失,以便进行训练和优化。
5.3 SlideLoss.py
class SlideLoss(nn.Module):
def __init__(self, loss_fcn):
super(SlideLoss, self).__init__()
self.loss_fcn = loss_fcn
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply SL to each element
def forward(self, pred, true, auto_iou=0.5):
loss = self.loss_fcn(pred, true)
if auto_iou < 0.2:
auto_iou = 0.2
b1 = true <= auto_iou - 0.1
a1 = 1.0
b2 = (true > (auto_iou - 0.1)) & (true < auto_iou)
a2 = math.exp(1.0 - auto_iou)
b3 = true >= auto_iou
a3 = torch.exp(-(true - 1.0))
modulating_weight = a1 * b1 + a2 * b2 + a3 * b3
loss *= modulating_weight
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
这个程序文件是一个名为SlideLoss的PyTorch模块,用于计算损失函数。它接受两个输入pred和true,然后使用loss_fcn计算损失值。在计算损失之前,它会根据auto_iou的值对true进行分段处理,并根据不同的分段计算相应的调制权重modulating_weight。最后,根据self.reduction的设置,返回损失的平均值、总和或不进行任何降维操作。
5.4 train.py
class YOLOv5Trainer:
def __init__(self, hyp, opt, device, callbacks):
self.hyp = hyp
self.opt = opt
self.device = device
self.callbacks = callbacks
self.save_dir = Path(opt.save_dir)
self.epochs = opt.epochs
self.batch_size = opt.batch_size
self.weights = opt.weights
self.single_cls = opt.single_cls
self.evolve = opt.evolve
self.data = opt.data
self.cfg = opt.cfg
self.resume = opt.resume
self.noval = opt.noval
self.nosave = opt.nosave
self.workers = opt.workers
self.freeze = opt.freeze
self.w = self.save_dir / 'weights'
self.last = self.w / 'last.pt'
self.best = self.w / 'best.pt'
self.cuda = self.device.type != 'cpu'
self.plots = not self.evolve and not self.opt.noplots
self.init_seeds(opt.seed + 1 + RANK, deterministic=True)
self.data_dict = None
self.train_path, self.val_path = None, None
self.nc = None
self.names = None
self.is_coco = None
self.model = None
self.optimizer = None
self.scheduler = None
self.ema = None
self.best_fitness = 0.0
self.start_epoch = 0
def init_seeds(self, seed, deterministic=True):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
if deterministic:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def train(self):
self.callbacks.run('on_pretrain_routine_start')
self.create_directories()
self.load_hyperparameters()
self.create_loggers()
self.process_custom_dataset_artifact_link()
self.create_model()
self.freeze_layers()
self.check_image_size()
self.check_batch_size()
self.create_optimizer()
self.create_scheduler()
self.create_ema()
self.resume_training()
self.train_model()
def create_directories(self):
(self.w.parent if self.evolve else self.w).mkdir(parents=True, exist_ok=True)
def load_hyperparameters(self):
if isinstance(self.hyp, str):
with open(self.hyp, errors='ignore') as f:
self.hyp = yaml.safe_load(f)
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in self.hyp.items()))
self.opt.hyp = self.hyp.copy()
def create_loggers(self):
if RANK in {-1, 0}:
self.loggers = Loggers(self.save_dir, self.weights, self.opt, self.hyp, LOGGER)
for k in methods(self.loggers):
self.callbacks.register_action(k, callback=getattr(self.loggers, k))
self.data_dict = self.loggers.remote_dataset
if self.resume:
self.weights, self.epochs, self.hyp, self.batch_size = self.opt.weights, self.opt.epochs, self.opt.hyp, self.opt.batch_size
def process_custom_dataset_artifact_link(self):
if RANK in {-1, 0}:
self.data_dict = self.data_dict or check_dataset(self.data)
self.train_path, self.val_path = self.data_dict['train'], self.data_dict['val']
self.nc = 1 if self.single_cls else int(self.data_dict['nc'])
self.names = {0: 'item'} if self.single_cls and len(self.data_dict['names']) != 1 else self.data_dict['names']
self.is_coco = isinstance(self.val_path, str) and self.val_path.endswith('coco/val2017.txt')
def create_model(self):
check_suffix(self.weights, '.pt')
pretrained = self.weights.endswith('.pt')
if pretrained:
self.weights = attempt_download(self.weights)
ckpt = torch.load(self.weights, map_location='cpu')
self.model = Model(self.cfg or ckpt['model'].yaml, ch=3, nc=self.nc, anchors=self.hyp.get('anchors')).to(self.device)
exclude = ['anchor'] if (self.cfg or self.hyp.get('anchors')) and not self.resume else []
csd = ckpt['model'].float().state_dict()
csd = intersect_dicts(csd, self.model.state_dict(), exclude=exclude)
self.model.load_state_dict(csd, strict=False)
LOGGER.info(f'Transferred {len(csd)}/{len(self.model.state_dict())} items from {self.weights}')
else:
self.model = Model(self.cfg, ch=3, nc=self.nc, anchors=self.hyp.get('anchors')).to(self.device)
def freeze_layers(self):
freeze = [f'model.{x}.' for x in (self.freeze if len(self.freeze) > 1 else range(self.freeze[0]))]
for k, v in self.model.named_parameters():
v.requires_grad = True
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
def check_image_size(self):
gs = max(int(self.model.stride.max()), 32)
self.imgsz = check_img_size(self.opt.imgsz, gs, floor=gs * 2)
def check_batch_size(self):
if RANK == -1 and self.batch_size == -1:
self.batch_size = check_train_batch_size(self.model, self.imgsz, amp)
self.loggers.on_params_update({'batch_size': self.batch_size})
def create_optimizer(self):
nbs = 64
accumulate = max(round(nbs / self.batch_size), 1)
self.hyp['weight_decay'] *= self.batch_size * accumulate / nbs
self.optimizer = smart_optimizer(self.model, self.opt.optimizer, self.hyp['lr0'], self.hyp['momentum'], self.hyp['weight_decay'])
def create_scheduler(self):
if self.opt.cos_lr:
lf = one_cycle(1, self.hyp['lrf'], self.epochs)
else:
lf = lambda x: (1 - x / self.epochs) * (1.0 - self.hyp['lrf']) + self.hyp['lrf']
self.scheduler = lr_scheduler.LambdaLR(self.optimizer, lr_lambda=lf)
def create_ema(self):
self.ema = ModelEMA(self.model) if RANK in {-1, 0} else None
def resume_training(self):
if pretrained:
if self.resume:
self.best_fitness, self.start_epoch, self.epochs = smart_resume(ckpt, self.optimizer, self.ema, self.weights, self.epochs, self.resume)
del ckpt, csd
def train_model(self):
for epoch in range(self.start_epoch, self.epochs):
self.callbacks.run('on_epoch_start', epoch)
self.model.train()
self.callbacks.run('on_train_epoch_start', epoch)
for i, (imgs, targets, paths, _) in enumerate(self.train_dataloader):
self.callbacks.run('on_train_batch_start', i, len(self.train_dataloader))
imgs = imgs.to(self.device).float() / 255.0
targets = targets.to(self.device)
loss, _ = self.model(imgs, targets)
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
self.callbacks.run('on_train_batch_end', i, len(self.train_dataloader))
self.callbacks.run('on_train_epoch_end', epoch)
self.callbacks.run('on_epoch_end', epoch)
self.callbacks.run('on_pretrain_routine_end')
该程序文件是用于训练一个YOLOv5模型的自定义数据集的。文件中包含了训练模型所需的各种参数和功能。
程序文件的主要功能包括:
- 解析命令行参数,包括数据集配置文件、模型权重、图像大小等参数。
- 加载模型和数据集,并进行必要的预处理。
- 定义训练过程中的损失函数、优化器和学习率调度器。
- 进行模型训练,并在每个epoch结束时计算验证集上的mAP。
- 保存训练过程中的模型权重和日志信息。
程序文件还包含了一些辅助函数和工具类,用于处理模型和数据集的相关操作,如模型加载、权重保存、数据加载、日志记录等。
该程序文件可以通过命令行参数来指定训练所需的各种配置,如数据集配置文件、模型权重、图像大小等。可以通过命令行参数来选择使用单GPU训练还是多GPU训练。还可以选择从预训练模型开始训练,或者从头开始训练。
该程序文件还支持使用comet_ml库进行实时的训练日志记录和可视化。
在训练过程中,程序文件会根据配置的参数和模型结构,自动调整学习率、优化器和损失函数等参数,以优化模型的训练效果。
训练过程中会使用到的数据集和模型可以从指定的链接中自动下载。
训练过程中会生成一些日志文件和图像文件,用于记录训练过程和评估模型性能。
训练结束后,程序文件会保存训练得到的模型权重和训练日志信息,以供后续使用和分析。
5.5 ui.py
class YOLOv5:
def __init__(self, weights, source, data, imgsz, device, view_img, save_txt, nosave, augment, visualize, update, project, name, exist_ok, half, dnn, vid_stride):
self.weights = weights
self.source = source
self.data = data
self.imgsz = imgsz
self.device = device
self.view_img = view_img
self.save_txt = save_txt
self.nosave = nosave
self.augment = augment
self.visualize = visualize
self.update = update
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.vid_stride = vid_stride
def run(self):
source = str(self.source)
save_img = not self.nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(self.imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=self.vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=self.vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.Tensor(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
results = model(im)
# Post-process
with dt[2]:
pred = F.softmax(results, dim=1) # probabilities
# Process predictions
for i, prob in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
annotator = Annotator(im0, example=str(names), pil=True)
# Print results
top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices
s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
# Write results
text = '\n'.join(f'{prob[j]:.2f} {names[j]}' for j in top5i)
classname = names[top5i[0]]
ui.printf('大豆缺陷检测为:' + str(classname))
if save_img or view_img: # Add bbox to image
annotator.text((32, 32), text, txt_color=(255, 255, 255))
if self.save_txt: # Write to file
with open(f'{txt_path}.txt', 'a') as f:
f.write(text + '\n')
# Stream results
im0 = annotator.result()
ui.showimg(im0)
QApplication.processEvents()
if view_img:
if platform.system() == 'Linux' and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
......
这是一个使用YOLOv5模型进行目标检测的程序。程序文件名为ui.py,主要包含以下功能:
- 导入所需的库和模块。
- 定义了一个名为run的函数,用于运行目标检测模型。
- 定义了一个名为parse_opt的函数,用于解析命令行参数。
- 定义了一个名为main的函数,用于检查所需的依赖项并运行目标检测。
- 定义了一个名为det的函数,用于解析命令行参数并调用main函数运行目标检测。
该程序使用了YOLOv5模型进行目标检测,可以通过命令行参数指定模型路径、输入源、数据集路径等。运行时会加载模型、进行推理、后处理,并将结果保存到指定的目录中。
5.6 val.py
class YOLOv5Validator:
def __init__(self, weights, data, batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300,
device='', workers=8, single_cls=False, augment=False, verbose=False, save_txt=False,
save_hybrid=False, save_conf=False, save_json=False, project=None, name='exp', exist_ok=False,
half=True, dnn=False, model=None, dataloader=None, save_dir=Path(''), plots=True, callbacks=Callbacks(),
compute_loss=None):
self.weights = weights
self.data = data
self.batch_size = batch_size
self.imgsz = imgsz
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.max_det = max_det
self.device = device
self.workers = workers
self.single_cls = single_cls
self.augment = augment
self.verbose = verbose
self.save_txt = save_txt
self.save_hybrid = save_hybrid
self.save_conf = save_conf
self.save_json = save_json
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.model = model
self.dataloader = dataloader
self.save_dir = save_dir
self.plots = plots
self.callbacks = callbacks
self.compute_loss = compute_loss
def save_one_txt(self, predn, save_conf, shape, file):
# Save one txt result
gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
for *xyxy, conf, cls in predn.tolist():
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(file, 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
def save_one_json(self, predn, jdict, path, class_map):
# Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
box = xyxy2xywh(predn[:, :4]) # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
for p, b in zip(predn.tolist(), box.tolist()):
jdict.append({
'image_id': image_id,
'category_id': class_map[int(p[5])],
'bbox': [round(x, 3) for x in b],
'score': round(p[4], 5)})
def process_batch(self, detections, labels, iouv):
"""
Return correct prediction matrix
Arguments:
detections (array[N, 6]), x1, y1, x2, y2, conf, class
labels (array[M, 5]), class, x1, y1, x2, y2
Returns:
correct (array[N, 10]), for 10 IoU levels
"""
correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
iou = box_iou(labels[:, 1:], detections[:, :4])
correct_class = labels[:, 0:1] == detections[:, 5]
for i in range(len(iouv)):
x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
correct[matches[:, 1].astype(int), i] = True
return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
def run(self):
# Initialize/load model and set device
training = self.model is not None
if training: # called by train.py
device, pt, jit, engine = next(self.model.parameters()).device, True, False, False # get model device, PyTorch model
half &= device.type != 'cpu' # half precision only supported on CUDA
self.model.half() if half else self.model.float()
else: # called directly
device = select_device(self.device, batch_size=self.batch_size)
# Directories
self.save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(self.save_dir / 'labels' if self.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
self.model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, pt, jit, engine = self.model.stride, self.model.pt, self.model.jit, self.model.engine
self.imgsz = check_img_size(self.imgsz, s=stride) # check image size
self.half = self.model.fp16 # FP16 supported on limited backends with
这是一个用于在检测数据集上验证训练好的YOLOv5检测模型的程序文件。它可以通过命令行参数来指定模型权重文件、数据集配置文件和图像尺寸等参数。程序会加载模型并在数据集上进行推理,计算模型的性能指标,并可选择保存结果到文本文件或JSON文件中。程序还支持在训练过程中调用,用于计算训练集上的损失。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于SlideLoss改进的YOLOv5大豆种子缺陷分类系统。它包含了目标检测和图像分割两个主要任务。整体构架采用了YOLOv5模型作为基础,并通过SlideLoss损失函数进行改进。该项目还提供了训练、验证和推理等功能,以及一些辅助工具和功能模块。
下表整理了每个文件的功能:
| 文件路径 | 功能概述 |
|---|---|
| export.py | 将YOLOv5模型导出为其他格式的工具 |
| loss.py | 定义了多个损失函数和辅助函数,用于计算模型的损失 |
| SlideLoss.py | 实现了SlideLoss损失函数的计算 |
| train.py | 训练YOLOv5模型的程序,包括模型加载、数据加载、损失函数、优化器等 |
| ui.py | 使用YOLOv5模型进行目标检测的程序 |
| val.py | 在检测数据集上验证训练好的YOLOv5模型的程序 |
| classify/predict.py | 使用YOLOv5模型进行大豆种子缺陷分类的推理程序 |
| classify/train.py | 训练大豆种子缺陷分类模型的程序 |
| classify/val.py | 在验证集上验证大豆种子缺陷分类模型的程序 |
| models/common.py | 包含一些通用的模型操作函数 |
| models/experimental.py | 包含一些实验性的模型定义和函数 |
| models/tf.py | 包含一些与TensorFlow相关的模型操作函数 |
| models/yolo.py | 包含YOLOv5模型的定义和相关函数 |
| models/init.py | 模型模块的初始化文件 |
| segment/predict.py | 使用图像分割模型进行图像分割的推理程序 |
| segment/train.py | 训练图像分割模型的程序 |
| segment/val.py | 在验证集上验证图像分割模型的程序 |
| utils/activations.py | 包含一些激活函数的定义 |
| utils/augmentations.py | 包含一些数据增强函数的定义 |
| utils/autoanchor.py | 包含自动锚框生成的函数 |
| utils/autobatch.py | 包含自动批处理大小调整的函数 |
| utils/callbacks.py | 包含一些回调函数的定义 |
| utils/dataloaders.py | 包含数据加载器的定义 |
| utils/downloads.py | 包含一些下载数据集和模型的函数 |
| utils/general.py | 包含一些通用的辅助函数 |
| utils/loss.py | 包含一些损失函数的定义 |
| utils/metrics.py | 包含一些评估指标的定义 |
| utils/plots.py | 包含一些绘图函数的定义 |
| utils/torch_utils.py | 包含一些与PyTorch相关的辅助函数 |
| utils/triton.py | 包含与Triton Inference Server相关的函数 |
| utils/init.py | 工具模块的初始化文件 |
| utils/aws/resume.py | 包含AWS训练恢复相关的函数 |
| utils/aws/init.py | AWS模块的初始化文件 |
| utils/flask_rest_api/example_request.py | 包含示例请求的函数 |
| utils/flask_rest_api/restapi.py | 包含Flask REST API的定义 |
| utils/loggers/init.py | 日志记录模块的初始化文件 |
| utils/loggers/clearml/clearml_utils.py | 包含ClearML日志记录工具的函数 |
| utils/loggers/clearml/hpo.py | 包含ClearML超参数优化的函数 |
| utils/loggers/clearml/init.py | ClearML日志记录模块的初始化文件 |
| utils/loggers/comet/comet_utils.py | 包含Comet日志记录工具的函数 |
| utils/loggers/comet/hpo.py | 包含Comet超参数优化的函数 |
| utils/loggers/comet/init.py | Comet日志记录模块的初始化文件 |
| utils/loggers/wandb/wandb_utils.py | 包含WandB日志记录工具的函数 |
| utils/loggers/wandb/init.py | WandB日志记录模块的初始化文件 |
| utils/segment/augmentations.py | 包含图像分割数据增强函数的定义 |
| utils/segment/dataloaders.py | 包含图像分割数据加载器的定义 |
| utils/segment/general.py | 包含图像分割的通用辅助函数 |
| utils/segment/loss.py | 包含图像分割的损失函数的定义 |
| utils/segment/metrics.py | 包含图像分割的评估指标的定义 |
| utils/segment/plots.py | 包含图像分割的绘图函数的定义 |
| utils/segment/init.py | 图像分割模块的初始化文件 |
请注意,由于文件较多,上述表格仅提供了每个文件的功能概述,并未详细列出每个文件中的所有函数和功能。
7.现有的难点
通过仔细分析分类检测器遇到的困难和YOLOv5检测器的不足,提出了以下解决方案:
多尺度融合:
在很多场景下,图像中通常存在不同尺度的人脸,人脸检测器很难将它们全部检测出来。因此,解决不同尺度的人脸是人脸算法非常重要的任务。
目前,解决多尺度问题的主要方法是构建金字塔来融合人脸的多尺度特征。例如,在 YOLOv5 中,FPN 融合了 P3、P4 和 P5 层的特征。但是对于小尺度的目标,经过多层卷积后信息很容易丢失,保留的像素信息很少,即使在较浅的P3层也是如此。因此,提高特征图的分辨率无疑有利于小目标的检测。
注意力机制:
在很多复杂的场景中,经常会出现人脸遮挡,这是导致人脸检测器准确率下降的主要原因之一。
为了解决这个问题,一些研究人员尝试使用注意力机制来提取面部特征。FAN 提出了Anchor-Level Attention。他们提出解决方案是保持无遮挡区域的响应值,并通过注意力机制来补偿遮挡区域降低的响应值。但是,它并没有充分利用通道之间的信息。
困难样本:
在单阶段检测器中,许多边界框没有被迭代过滤掉。所以单阶段检测器中的简单样本数量非常大。在训练过程中,它们的累积贡献支配了模型的更新,导致模型的过拟合。这被称为不平衡样本问题。
为了解决这个问题,Lin 等人提出 Focal Loss 为困难的样本示例动态分配更多权重。与focal loss类似,Gradient Harmonizing Mechanism (GHM) 抑制正负简单样本的梯度,以更多地关注困难样本。Cao等人提出的Prime Sample Attention (PISA)。根据不同的标准为正负样本分配权重。然而,目前的硬样本挖掘方法需要设置的超参数过多,在实践中非常不方便。
Anchor design:
CNN特征图中的一个区域有两种感受野,理论感受野和实际感受野。实验表明,并非感受野中的所有像素都响应相同,而是服从高斯分布。这使得基于理论感受野的anchor尺寸大于其实际尺寸,使得bounding box的回归更加困难。Zhang等人根据S3FD中的有效感受野设计了anchors的大小。FaceBoxes设计了多尺度anchor来丰富感受野,并在不同层上离散anchors来处理各种尺度的人脸。因此,anchor box的尺度和比例的设计非常重要,这对模型的准确性和收敛过程有很大的好处。
回归损失:
回归损失用于衡量预测边界框和地面实况边界框之间的差异。目标检测器中常用的回归损失函数有 L1/L2 损失、平滑 L1 损失、IoU 损失及其变体。YOLOv5 将 IoU 损失作为其目标回归函数。然而,对于不同尺度的物体,IoU 的敏感性差异很大。不难理解,对于小目标,轻微的位置偏差会导致 IoU 显著下降。Wang等人提出了一种基于Wasserstein距离的小目标评价方法,有效减轻小目标的影响。然而,他们的方法对大型目标的执行并不那么重要。
8.网络架构
SlideLoss改进YOLO5 是一个优秀的通用目标检测器。
SlideLoss改进YOLO5 以 CSPDarknet53 为Backbone,并在 P5 层用 RFE 模块替换Neck,以融合多尺度特征。在Neck,保持了 SPP 和 PAN 的结构。此外,为了提高目标位置感知能力,还将P2层集成到PAN中。Head用于对类别进行分类并回归目标的位置。作者还在Head添加了一个特殊的分支,以增强模型的遮挡检测能力。
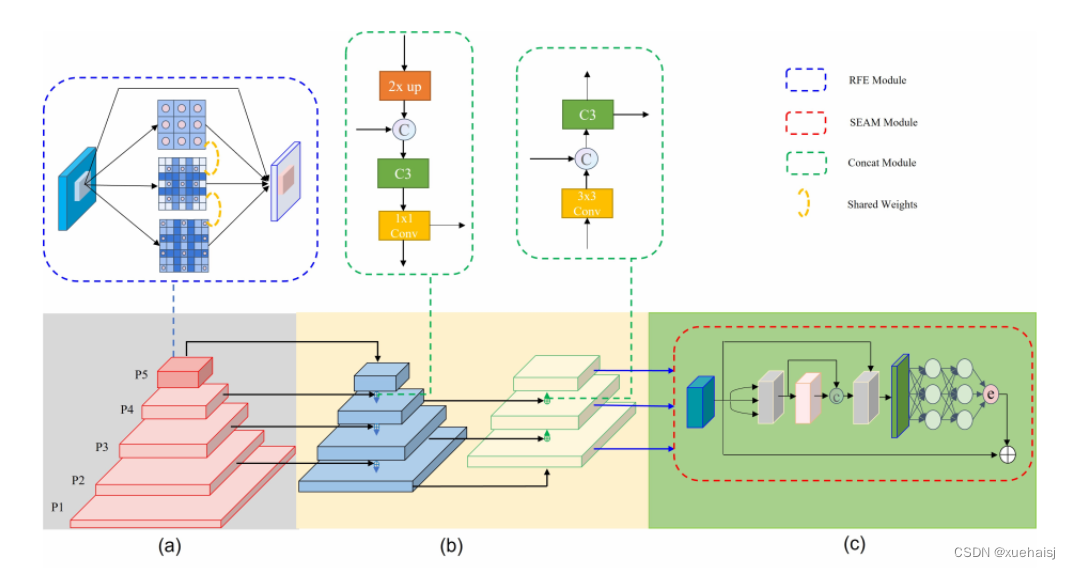
在图1(a)中,左边的红色部分是检测器的Backbone,由CSP块和CBS块组成。主要用于提取输入图像的特征。并且在P5层增加RFE模块,扩大有效感受野,增强多尺度融合能力。
在图 1(b)中,右边的蓝色和黄色部分称为Neck层,由 SPP 和 PAN 组成。还融合了 P2 层的特征,以提高更准确的目标定位能力。
在图 1(c)中,引入了分离和增强注意力模块(SEAM)来增强Neck层输出部分后被遮挡人脸的响应能力。
Scale-Aware RFE Model
由于不同大小的感受野意味着不同的捕获远程依赖的能力,作者设计RFE模块以充分利用特征图中感受野的优势,通过使用扩张卷积。受 TridentNet 的启发使用4个不同速率的扩张卷积分支来捕获多尺度信息和不同范围的依赖关系。所有的分支都有共享权重,唯一的区别是它们独特的感受野。
一方面,它减少了参数的数量,从而降低了潜在过拟合的风险。另一方面,它可以充分利用每个样本。
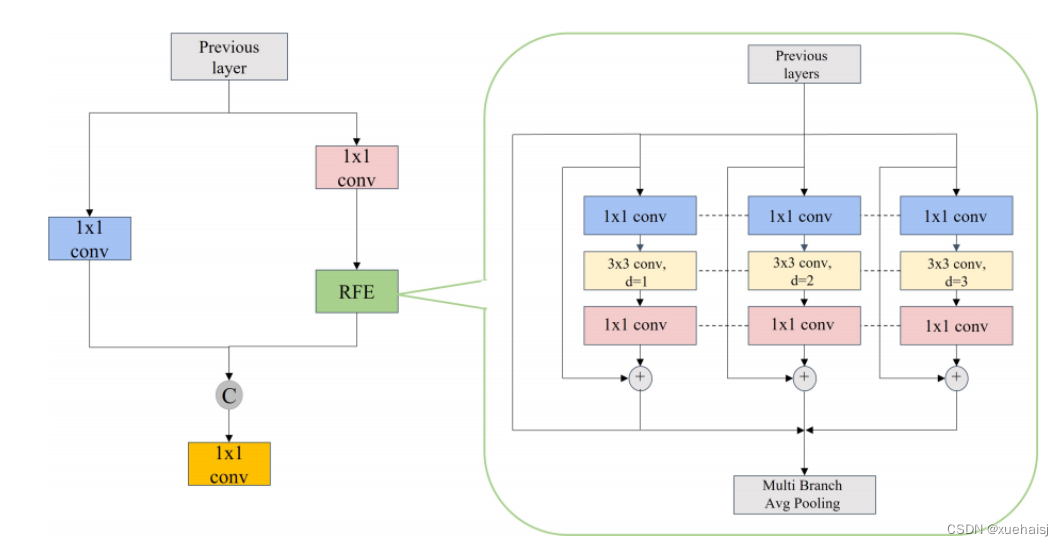
提出的RFE模块可以分为2部分:基于扩张卷积的多分支和聚集加权层,如图2所示。多分支部分分别以1,2和3作为不同扩张速率,它们都使用固定的卷积核大小 3×3。此外,作者添加了一个残差连接来防止训练过程中梯度爆炸和消失的问题。gathering and weighting层用于收集来自不同分支的信息并对特征的每个分支进行加权。加权操作用于平衡不同分支的表示。
为了说清楚,将YOLOv5中C3模块的瓶颈替换为RFE模块,以增加特征图的感受野,从而提高多尺度目标检测识别的准确率,如图2所示。
遮挡感知排斥损失
类内遮挡可能导致A面包含B面的特征,从而导致较高的误检率。排斥损失的引入可以通过排斥有效缓解这一问题。排斥损失分为两部分:RepGT 和 RepBox。
RepGT Loss 的作用是使当前边界框尽可能远离周围的ground truth box。这里的周围ground truth box是指除了bounding box本身要返回的对象之外,与人脸IoU最大的人脸标签。RepGT损失函数的公式如下:
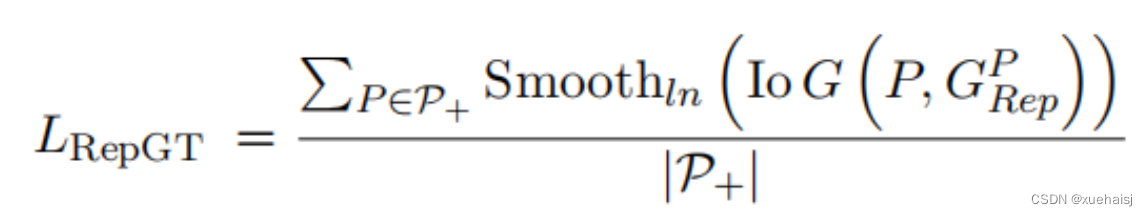
其中:
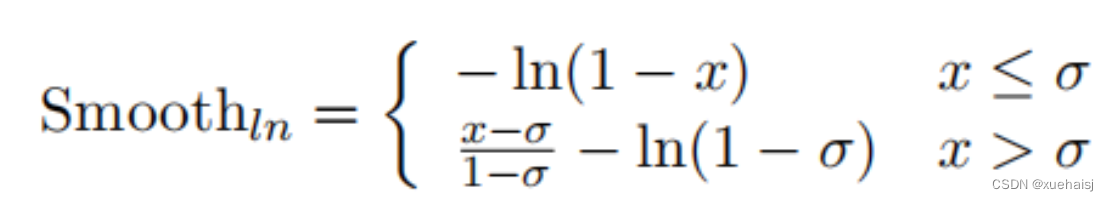
公式中的P是人脸预测框,是人脸周围IoU最大的ground truth。P 和之间的重叠被定义为与 ground truth (IoG) 的交集: 和。是 (0, 1) 一个连续可微的。ln 函数,σ ∈ [0, 1) 是一个平滑参数,用于调整排斥损失对异常值的敏感性。
RepBox loss的目的是让预测框尽可能远离周围的预测框,减少它们之间的IOU,从而避免属于两个人脸的预测框之一被NMS抑制。这里将预测帧分成多个组。假设有g个个体人脸,划分形式如下式所示。相同组之间的预测帧返回相同的人脸标签,不同组之间的预测帧对应不同的人脸标签。
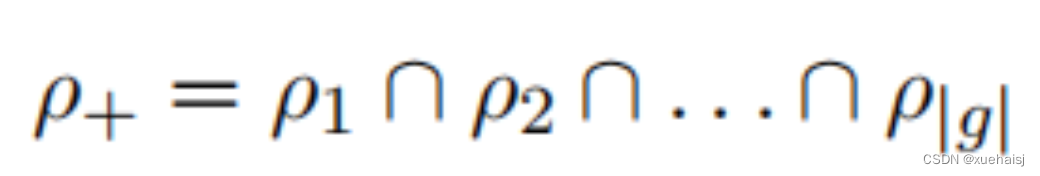
然后,对于不同组和之间的预测框,希望得到和之间的重叠区域越小。RepBox 还使用作为优化函数。整体损失函数如下:
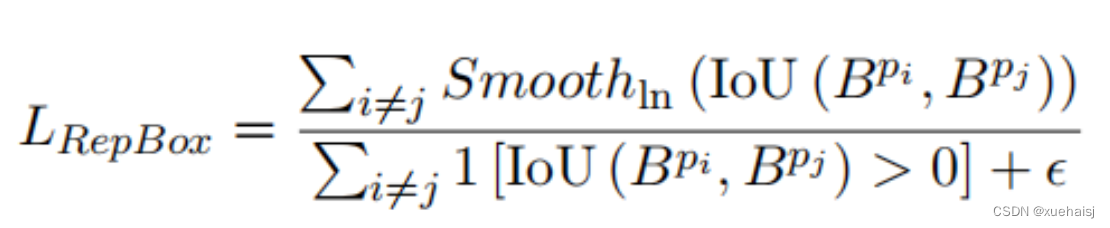
遮挡感知注意力网络
类间遮挡会导致对齐错误、局部混叠和特征缺失。该博客作者添加了多头注意力网络,即SEAM模块(见图3),其中我们有三个目的:实现多尺度人脸检测,强调图像中的人脸区域,反之弱化背景区域。
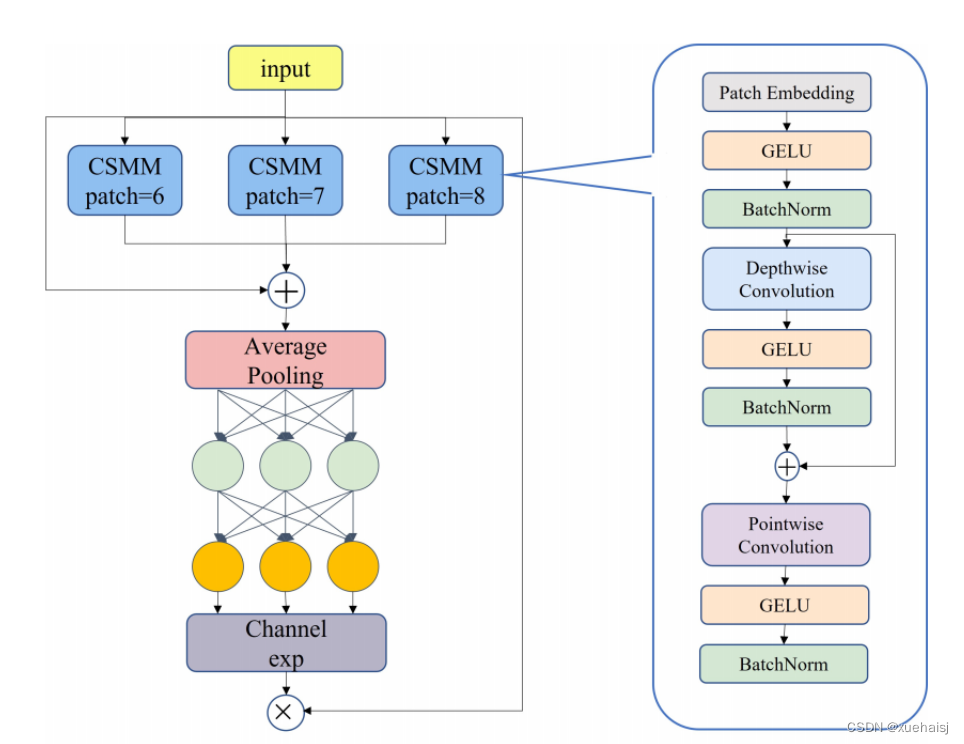
SEAM的第一部分是带有残差连接的深度可分离卷积。深度可分离卷积是逐个深度操作的,即逐个通道分离卷积。深度可分离卷积虽然可以学习不同通道的重要性并减少参数量,但它忽略了通道之间的信息关系。
为了弥补这种损失,不同深度卷积的输出随后通过逐点卷积进行组合。然后用一个两层的全连接网络来融合每个通道的信息,这样网络就可以加强所有通道之间的连接。
希望该模型能够通过上一步学习到的被遮挡人脸与无遮挡人脸的关系来弥补前面提到的遮挡场景下的损失。全连接层学习到的输出logits再经过指数函数处理,将取值范围从[0, 1]扩大到[1, e]。这种指数归一化提供了一种单调映射关系,使结果更能容忍位置误差。
最后将SEAM模块的输出作为attention乘以原始特征,使模型能够更有效地处理人脸遮挡。
样本加权函数
样本不平衡问题,即在大多数情况下,容易样本的数量很大,而困难样本相对稀疏,引起了很多关注。在本文的工作中,设计了一个看起来像“slide”的 Slide Loss 函数来解决这个问题。
简单样本和困难样本之间的区别是基于预测框和ground truth 框的IoU 大小。为了减少超参数,将所有边界框的 IoU 值的平均值作为阈值 µ,小于 µ 的取负样本,大于 µ 的取正样本。
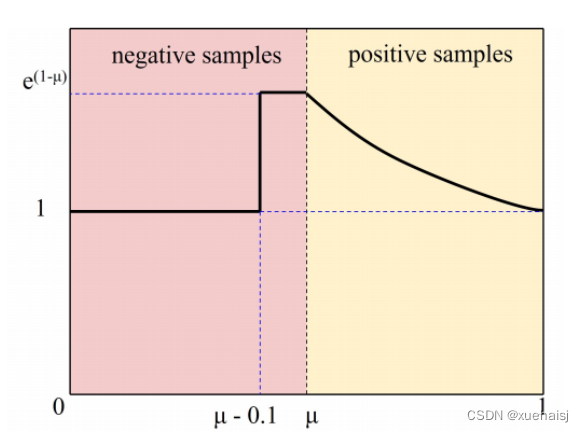
然而,由于分类不明确,边界附近的样本往往会遭受较大的损失。希望模型能够学习优化这些样本,并更充分地使用这些样本来训练网络。然而,此类样本的数量相对较少。因此,尝试为困难样本分配更高的权重。首先通过参数μ将样本分为正样本和负样本。然后,通过加权函数 Slide 对边界处的样本进行强调,如图所示。Slide 加权函数可以表示为 Eqn 5。
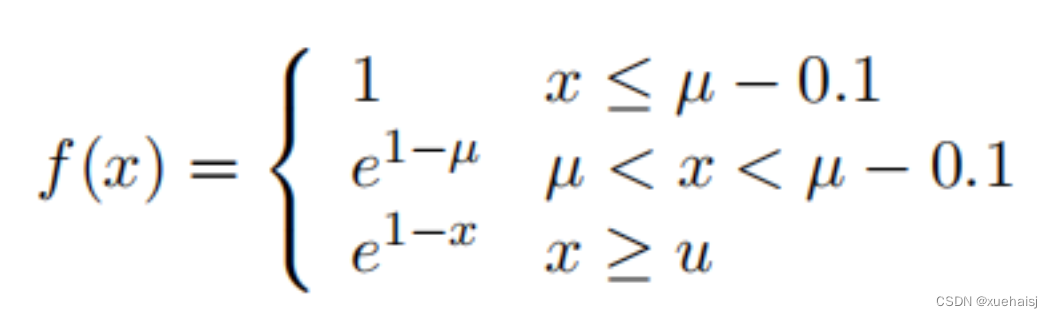
Anchor设计策略
Anchor设计策略在人脸检测中至关重要。在模型中,3个检测头中的每一个都与特定的Anchor尺度相关联。Anchor的设计包括宽高比和Anchor的尺寸,根据P2、P3和P4的步幅设计(见表1)。对于宽高比,根据真实人脸比从 WiderFace 训练集计算统计数据。

在人脸检测中,根据统计数据将纵横比设置为 1:1.2。对于Anchor的大小,根据每一层的感受野来设计,可以通过卷积层和池化层的数量来计算。然而,并非理论感受野中的每个像素对最终输出的贡献都相同。一般来说,中心像素比外围像素的影响更大,如图5(a)所示。也就是说,只有一小部分区域是有效的影响。实际效果可以相当于一个有效的感受野。根据这个假设,为了匹配有效感受野,Anchor应该明显小于理论感受野(具体例子见图5(b))。因此,重新设计了初始Anchor大小,如表 1 所示。
归一化高斯 Wasserstein 距离
归一化 Wasserstein 距离称为 NWD 是一种新的小目标检测评估方法。首先将bounding box建模为二维高斯分布,通过其对应的高斯分布计算预测目标与真实目标的相似度,即根据Eqn 6计算它们之间的归一化wasserstein距离。对于检测到的目标,无论它们是否重叠,都可以通过分布相似度来衡量。
NWD对目标的尺度不敏感,更适合测量小目标之间的相似度。在回归损失函数中,添加了一个 NWD 损失来弥补 IoU 损失对于小目标检测的缺点。但仍然保留 IoU 损失,因为它适用于大物体检测。
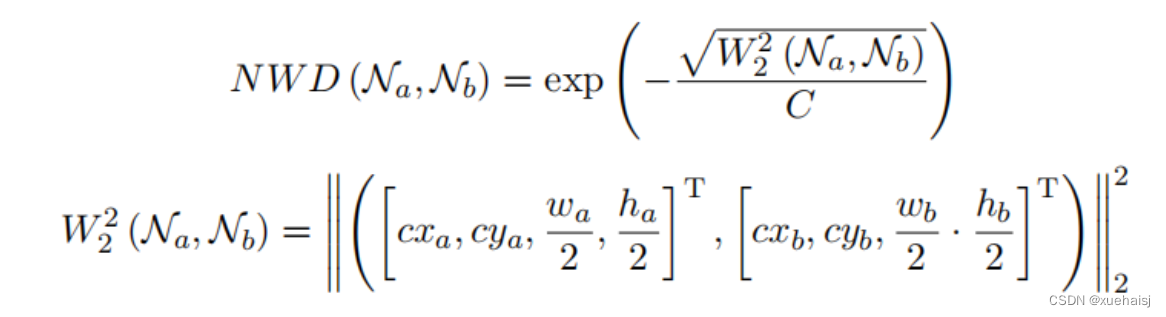
其中C是一个与数据集密切相关的常数,是一个距离度量,和是由和建模的高斯分布。
9.SlideLoss改进YOLO
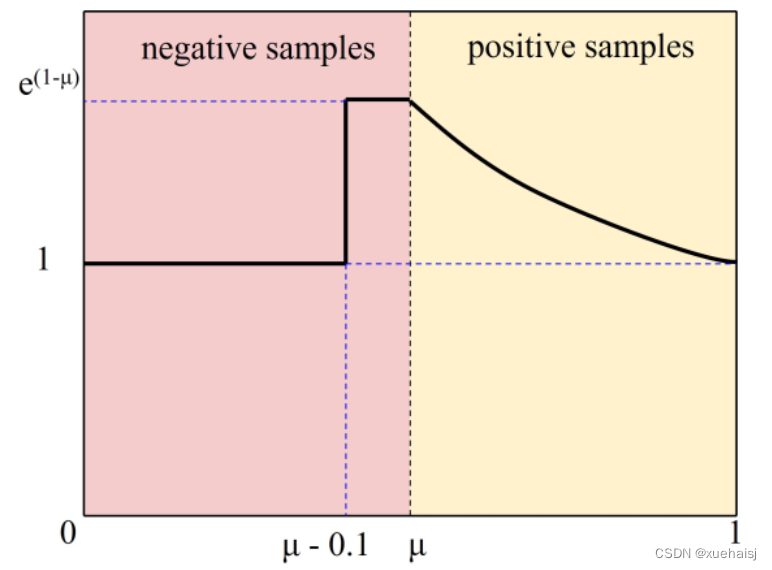
样本不平衡问题,即在大多数情况下,容易样本的数量很大,而困难样本相对稀疏,引起了很多关注。在本文的工作中,设计了一个看起来像“slide”的Slide Loss函数来解决这个问题。简单样本和困难样本之间的区别是基于预测框和ground truth 框的IoU大小。为了减少超参数,将所有边界框的 IoU 值的平均值作为阈值 µ,小于µ的取负样本,大于µ的取正样本。
然而,由于分类不明确,边界附近的样本往往会遭受较大的损失。希望模型能够学习优化这些样本,并更充分地使用这些样本来训练网络。然而,此类样本的数量相对较少。因此,尝试为困难样本分配更高的权重。首先通过参数μ将样本分为正样本和负样本。然后,通过加权函数Slide对边界处的样本进行强调,如图所示。
10.训练结果可视化分析
评价指标
Epoch:这可能代表训练过程中的迭代次数。
Train/Loss:训练期间的损失分数,表明模型对训练数据的拟合程度。值越低表明性能越好。
测试/损失:测试期间的损失分数,显示模型在未见过的数据上的性能。与训练损失一样,值越低越好。
Metrics/Accuracy_Top1:top-1 准确度指标,可能表示模型最高预测(最置信度分类)正确的次数比例。
Metrics/Accuracy_Top5:前 5 个准确度指标,可能表示正确答案出现在模型前 5 个预测中的频率。
LR/0:训练期间模型的学习率,影响训练期间模型权重的调整程度。
训练结果可视化
为了可视化和分析这些数据,我将创建几个图:
损失图:显示历元内的训练和测试损失,以了解模型的性能在训练期间如何演变。
准确率图:绘制历元内的 top-1 准确率,以查看模型预测能力的改进。
学习率图:可视化学习率在历元内的变化情况,这可以提供对训练动态的洞察。
创建这些可视化后,我将从各个角度进行深入分析。让我们从可视化开始。
import matplotlib.pyplot as plt
import seaborn as sns
# Setting the style for the plots
sns.set(style="whitegrid")
# Creating subplots
fig, axes = plt.subplots(3, 1, figsize=(12, 18))
# Plot for Training and Test Loss
axes[0].plot(data['epoch'], data['train/loss'], label='Train Loss', color='blue', marker='o')
axes[0].plot(data['epoch'], data['test/loss'], label='Test Loss', color='red', marker='x')
axes[0].set_title('Training and Test Loss per Epoch')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss')
axes[0].legend()
# Plot for Top-1 Accuracy
axes[1].plot(data['epoch'], data['metrics/accuracy_top1'], label='Top-1 Accuracy', color='green', marker='o')
axes[1].set_title('Top-1 Accuracy per Epoch')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('Accuracy')
axes[1].legend()
# Plot for Learning Rate
axes[2].plot(data['epoch'], data['lr/0'], label='Learning Rate', color='purple', marker='o')
axes[2].set_title('Learning Rate per Epoch')
axes[2].set_xlabel('Epoch')
axes[2].set_ylabel('Learning Rate')
axes[2].legend()
# Adjust layout
plt.tight_layout()
# Show the plots
plt.show()
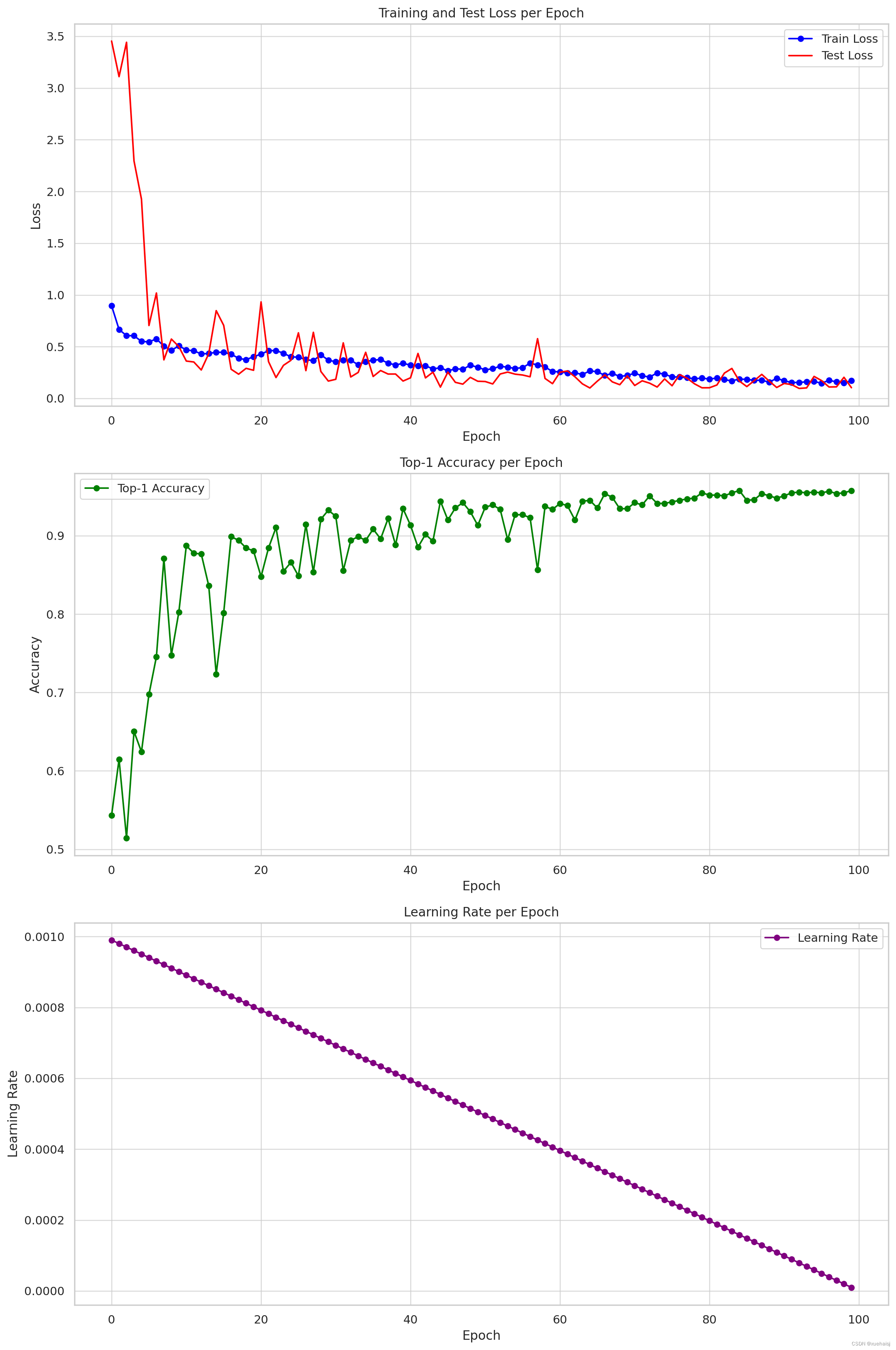
以下是基于数据集的可视化:
每个时期的训练和测试损失:该图显示了训练和测试的损失值在时期内如何变化。损失是衡量模型性能的指标,值越低表示性能越好。
每个时期的 Top-1 准确率:该图描述了各个时期内 top-1 准确率的变化。Top-1 准确度衡量模型最有信心的预测正确的频率。
每个时期的学习率:此图表说明了学习率在各个时期的进展。学习率在训练神经网络时至关重要,因为它决定了优化过程中采取的步骤的大小。
分析:
损失分析:训练损失通常会随着时间的推移而减少,这是模型从训练数据中学习时所期望的。理想情况下,测试损失应遵循类似的趋势,但任何偏差都可能表明存在过度拟合或欠拟合等问题。比较训练和测试损失之间的差距很重要。较大的差距可能表明过度拟合,即模型对训练数据的学习太好,但无法推广到新数据。
准确性分析:top-1 准确性可让您深入了解模型正确分类数据的能力。准确性的增加趋势是可取的。然而,重要的是要确保准确性的提高不会以过度拟合为代价。这可以与损失图交叉验证。
学习率动态:学习率图对于理解训练动态至关重要。学习率过高可能会导致模型超出最佳解决方案,而学习率过低可能会导致训练缓慢或陷入局部最小值。学习率的趋势和调整还可以揭示所采用的学习率策略(如步进衰减、指数衰减等)。
进一步的步骤:
详细的统计分析:除了目视检查之外,对数据进行详细的统计分析可以提供更多见解。这可以包括分析方差、标准差和其他统计度量,以更好地了解模型的性能。
比较分析:如果使用不同的模型或配置,比较它们的性能可以深入了解什么最适合给定问题。
上下文解释:在特定问题领域(在本例中为大豆种子缺陷分类)的上下文中解释这些结果至关重要。根据应用程序的实际要求和限制,某些级别的准确性或损失可能更可接受或更重要。
11.系统整合

参考博客《基于SlideLoss改进YOLO的大豆种子缺陷分类系统》
12.参考文献
[1]卢青.基于高光谱图像技术的黄瓜种子品质无损检测技术研究[D].2019.
[2]朱少龙.基于遥感成像技术的大豆病虫害与品种识别[D].2020.
[3]丘广俊.甜玉米种子个体质量近红外无损检测方法研究[D].2019.
[4]王茂瑶.甘蔗品质性状高通量表型评价体系的建立及初步应用[D].2021.
[5]周碧云.基于近红外光谱法对红酸汤中氨基酸类滋味物质快速测定的研究[D].2022.
[6]郑田甜.花生种子品质可见-近红外光谱的特片提取与分类识别[J].烟台大学.2014.
[7]梁剑.基于近红外光谱技术的水稻种子真伪性和新陈度鉴别方法研究[J].中国科学院大学.2013.
[8]张朝洁.基于高光谱成像技术的不同加工程度下稻谷品种和虫害鉴别研究[J].江苏大学.2014.
[9]毛晓东.基于多层SVM的面筋强度分类模型优化研究[J].黑龙江大学.2014.
[10]毕文佳.基于高光谱图像技术的大豆品种鉴别方法研究[J].东北农业大学.2016.















 1752
1752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









