






之前我写过一篇《你没有大数据》那一篇被阅读的也很多。我这里说的是大部分企业,少数公司有这个场景的可以使用。不过即使大数据为未必使用Hadoop。
Oracle和PG都有组件或者衍生途径去实现列式存储,那么对数据分析是有利的。MySQL当然也有只是目前在企业版中,在云上有。所以他相比较其他不太适合做分析。但是今天我就用这个不太适合做分析的数据来说一下为什么一般企业不用大数据。
构造两个表,表big表示企业的业务主要数据。写了个脚本写入了几千万数据。
mysql> use big;
Database changed
mysql> create table big (id int auto_increment,name varchar(30),money int,age int,time datetime,primary key(id));
Query OK, 0 rows affected (0.03 sec)
mysql> create table conf (name varchar(30),tel varchar(11),address varchar(100));
Query OK, 0 rows affected (0.07 sec)
该表大约1.2亿条数据,模拟业务以每秒一条的数据写入的。那么一天86400条数据。

这个虽然和滴滴一天3000万的订单不能比。但是比起大部分企业来说这个一条主营业务这么多数据,其实也算不少了。况且我用的是个4C 4G的虚拟机MySQL,也不是什么好机器。
虽然这次模拟的表字段相对于真实场景来说少了很多,但是本次的出发点是利用索引进行查询,所以和这个表的大小和宽窄关系不大。也正是我要表达的,只要好好写SQL,利用好索引。是可以很好的完成数据分析和报表的。当然如果有列数存储的数据库就更好了。
说明1:本次模拟一天8万多数据的查询。如果某企业一天是1万笔的交易量。那么我这个一天等于某企业8天,这个应该没有异议。
说明2:有时候分析会关联多个表,如果关联关系是1对1的,那么他的读取数据量就N倍。2表关联是2倍,8表关联就是8倍。当然如果是1对n的话,那么2表关联就直接是n倍。m表关联就是mXn倍。这些是大约的关系。
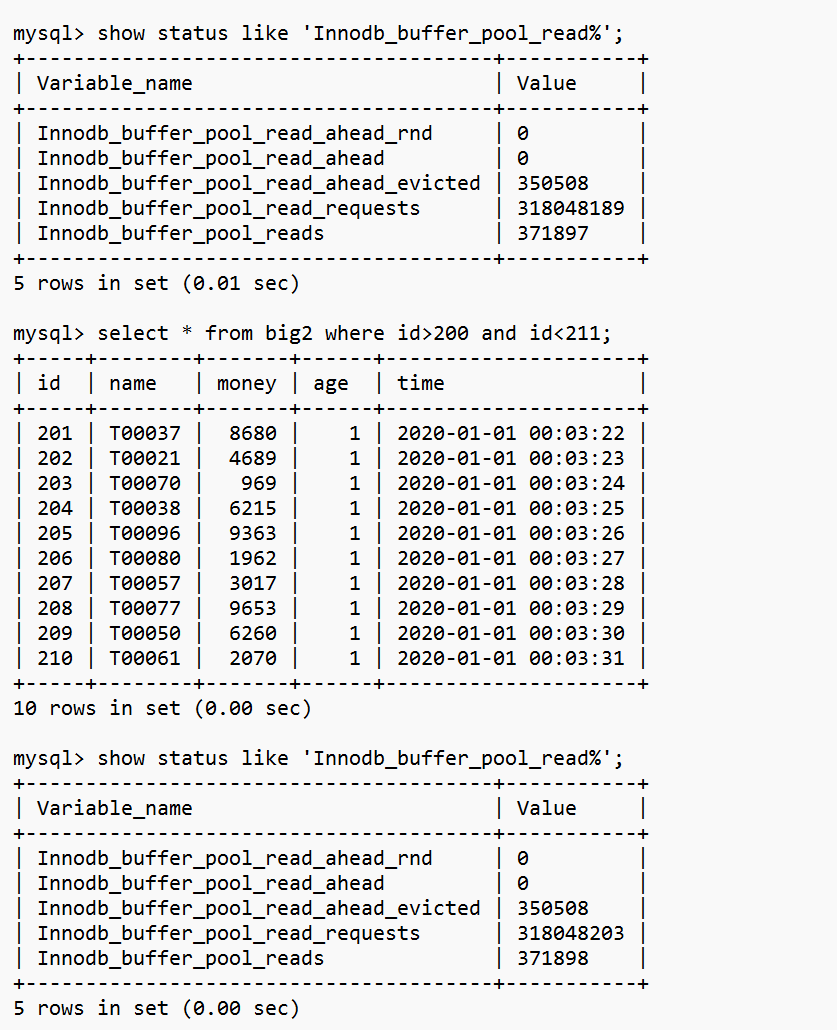
Innodb_buffer_pool_reads这个值增加了1,说明读取了一次IO,大约16K。

Innodb_buffer_pool_reads这个值增加了2,说明读取了2次IO,大约32K。
下面是所谓的报表分析。Innodb_buffer_pool_reads这个值增加了156,说明读取了156次IO,大约2M。 这是从磁盘读到内存用了1.45秒。

由于一秒一笔交易,所以一小时的3600行数据。 查询了86000行数据。即如果一个企业每天1万订单的业务量,那么一周的统计分析也大约是1秒左右。而且第二次计算count全部在内存中计算。尽管这个MySQL只有4G的物理内存。但是由于读取的数据通过索引,实际只大约读取2M。什么数据库处理不了2M的数据呢?在内存中处理只要0.5秒。

一周的将近10万笔业务的系统单表分析也只有0.5秒。假设10表关联也就5秒嘛。或者是MXN这种1对多乘积达到20倍,也就10秒。对于一周的报表统计5-10秒还是可以接受的。以上都是基于4c 4G的MySQL。如果多CPU,大内存,或者是列存数据库,那就更加不用说了。比如Oracle In-memory不用索引,单表聚合一亿条也就一秒。
当然如果说乱写SQL,没有索引,每次全量查询或者笛卡尔积,那么这个另当别论。其实Hadoop诞生之初就是给乱写SQL的分析去用的。用几百台机器去乱来。这不禁让我想到了这张图。















 2333
2333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









