







Deep Representation Learning with Part Loss for Person ReID
本论文为了更好的提升reid模型在未见过的行人图像判别能力,正对现有大部分只有全局特征表达(转化为分类,一般minimize the empirical classification risk即loss)且容易过拟合而不考虑parts 局部特征表达(the representation learning risk)的的方法做了改进,设计了Part Loss Networks (PL-Net),该网络通过引入part loss 影响全局特征的表达,使其更注意重点parts,同时对应的part network被无监督训练可用于自动检测人体部件(parts),进行parts的软分类来产生具有更好的soft parts(而不是产生grid parts),最后,part loss增加了模型在unseen persons上的判别性。
作者在Market1501, CUHK03, VIPeR验证了模型的优秀性能。
这篇论文和1711.Beyond Part Models- Person Retrieval with Refined Part Pooling联系较大,一块学习比较好!
论文信息:


传统的只考虑全局特征表达分类网络和考虑part loss的网络显著性区域的可视化:

文中的Zero-shot learning :
Zero-shot learning 指的是我们之前没有这个类别的训练样本。但是我们可以学习到一个映射X->Y。如果这个映射足够好的话,我们就可以处理没有看到的类了。 比如,我们在训练时没有看见过狮子的图像,但是我们可以用这个映射得到狮子的特征。一个好的狮子特征,可能就和猫,老虎等等比较接近,和汽车,飞机比较远离。感性认识的话,虽然我们不知道这东西叫狮子,但是我们可以说出他和谁谁谁像。(生物学家第一次看到鸭嘴兽的感觉。)
Person ReID can be regarded as a challenging zero-shot learning problem, 即测试的probe ID不包括在训练集中,because the training and test sets do not share any person in common. Therefore, person ReID requires discriminative representations to depict unseen person images.
当仅用全局表达时,为了减少分类损失,网络趋向于聚焦主要身体,然而the other
body parts like head, lower-body, and foot are potential to be meaningful for depicting other unseen persons。所以忽视part 注意机制会增加特征表达的风险对于未见数据的应用。
作者提出的part loss会自动生成K个parts对于一张图像,计算各自的行人分类loss,最小化各自的part loss来指导网络学习面向不同body parts的判别性特征表达。
PL-Net 结构:
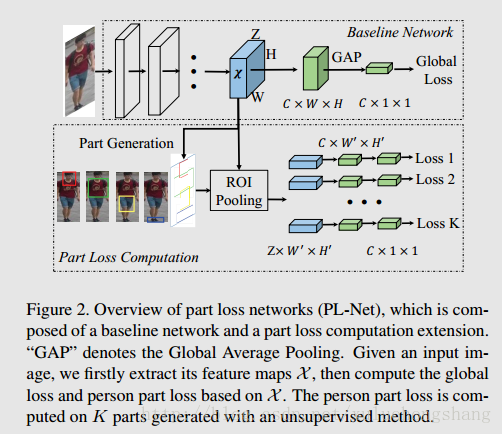
part loss networks is composed of a baseline network and an extension to compute the person part loss.同时须训练两个loss,PL-Net只比baseline多了一个参数,因为是无监督训练,即(分K个parts的K值)
part loss networks (PL-Net) automatically detects human parts and does not need extra annotation or detectors, thus is more efficient and easier to implement.
Part Loss Networks和Person Part Loss Computation
作者采用的baseline network is modified from second version of GoogLeNet,并应用了Faster R-CNN的ROI pooling来统一转化响应图的bbox到同一size的空间特征图
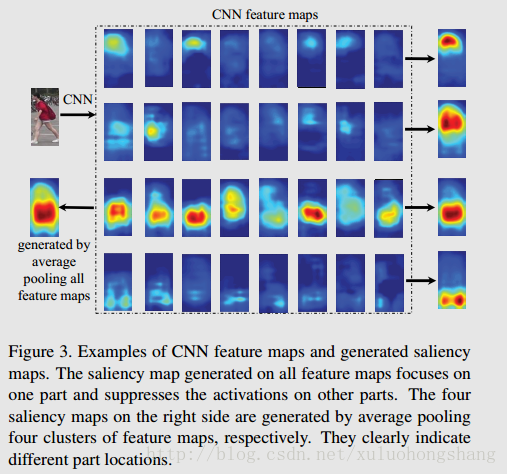
基框架average pooling all feature maps产生的CNN 不同part响应:
Although the responses on different parts are seriously imbalanced, they still provide cues of different part locations.
无监督训练过程:
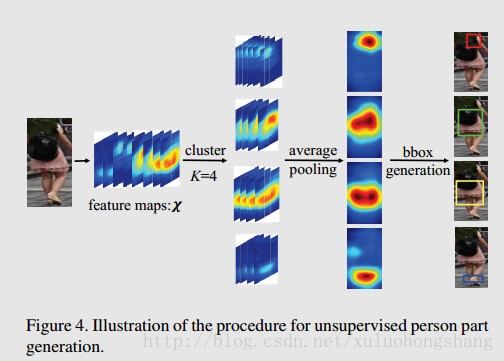
During this procedure, the part generation and representation learning can be jointly optimized.

For the case with K=4, the generated four parts coarsely cover the head, upper body, lower body, and legs, respectively. For the case that K=8, most of generated parts
distribute on the human and cover more detailed parts.无特殊说明,作者一般设置K=8.
实验:
Accuracy of Part Generation Generated parts是part loss监督和无监督训练得到的part(基于注意力机制),而Grid Parts则是严格的手工条纹等间隔parts分割,如图所示:
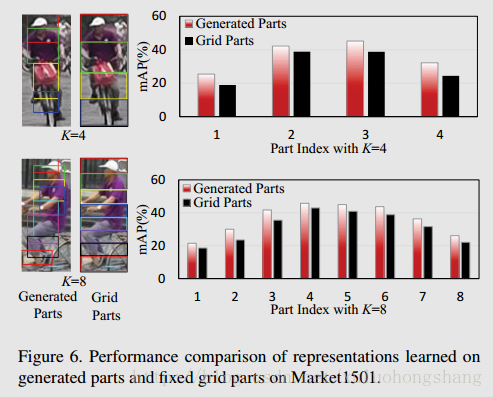

Validity of Part Loss
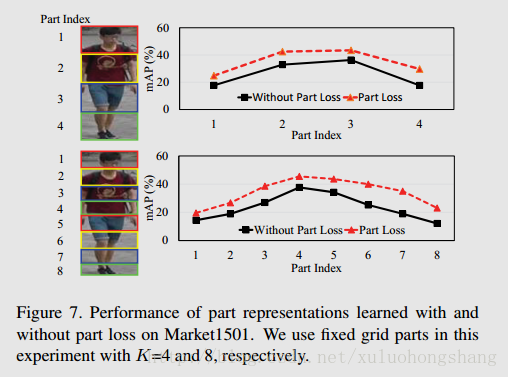
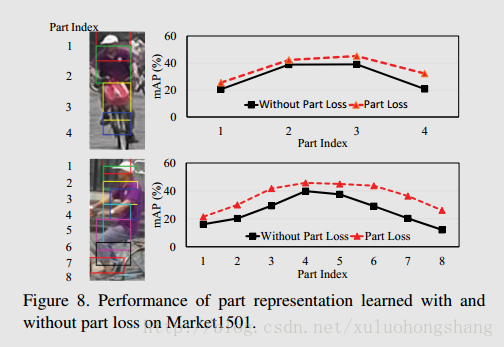
Performance of Global Representation

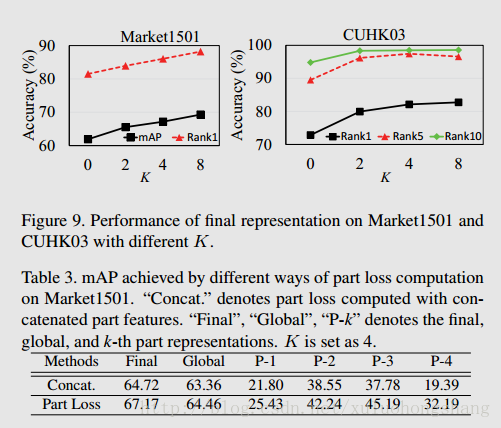
Performance of Final Representation
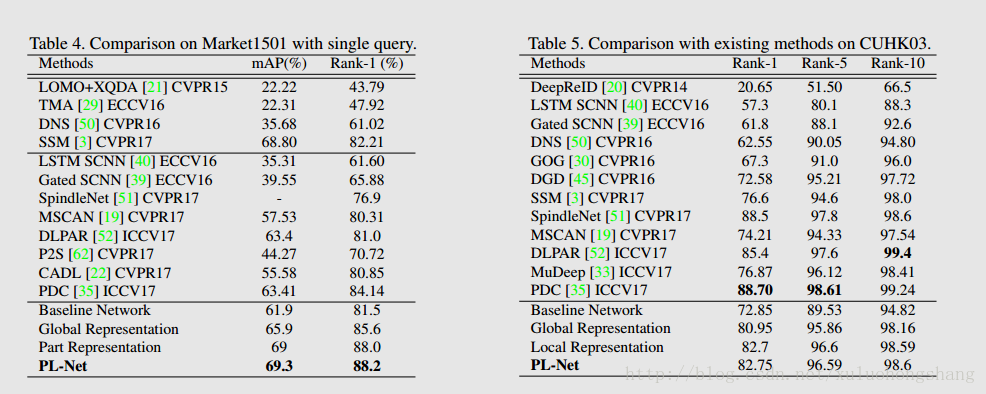
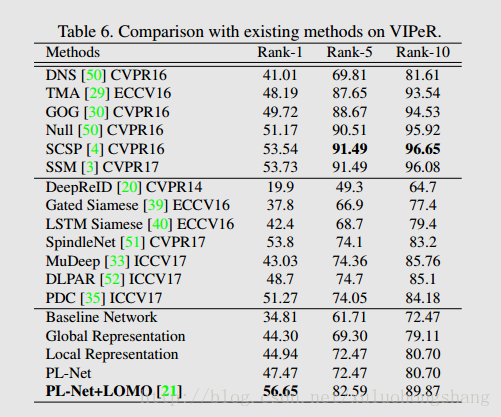
Comparison with State-of-the-art
总结:
From the above comparisons, we summarize : 1) part loss improves the baseline network and results in more discriminative global and part representations, and 2) the combined final representation is learned only with person ID annotations but outperforms most of existing works on the three datasets.
Conclusions
















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









