







0.前言
我要搭建的集群是一台Master和3台Worker。先按照前面博客内容配置好。
Spark分布式搭建(1)——ubuntu14.04 设置root自动登入
http://blog.csdn.net/xummgg/article/details/50630583
Spark分布式搭建(2)——ubuntu14.04下修改hostname和hosts
http://blog.csdn.net/xummgg/article/details/50634327
Spark分布式搭建(3)——ubuntu下ssh无密码登入(设置ssh公钥认证)
http://blog.csdn.net/xummgg/article/details/50634730
Spark分布式搭建(4)——ubuntu下Hadoop伪分布式搭建
http://blog.csdn.net/xummgg/article/details/50641096
1.安装scala
1.1下载scala
下载地址:
http://www.scala-lang.org/download/
我在All downloads里面选择了2.10.4版本:

1.2 解压
下载保存在Downloads目录下,所以进行该目录,用tar命令直接解压到当前目录,这里的操作现在Master下进行。

拷贝到/usr/local/scala目录下

1.3配置scala环境变量
用vim命令打开系统的bashrc文件:

添加如下内容,包括bin目录加到path
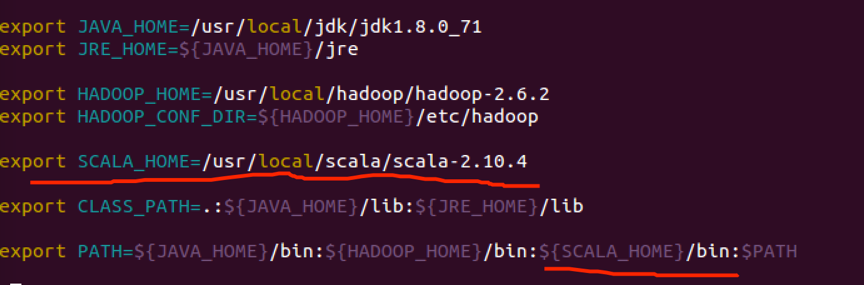
用source使其生效

1.4 验证
输入scala version可以显示如下就对了:

还可以直接用scala,进行scala编程:

2.安装Spark
2.1下载Spark
下载地址:
http://spark.apache.org/downloads.html
出于学习目的,我下载的是预先编译好了的1.6版本。
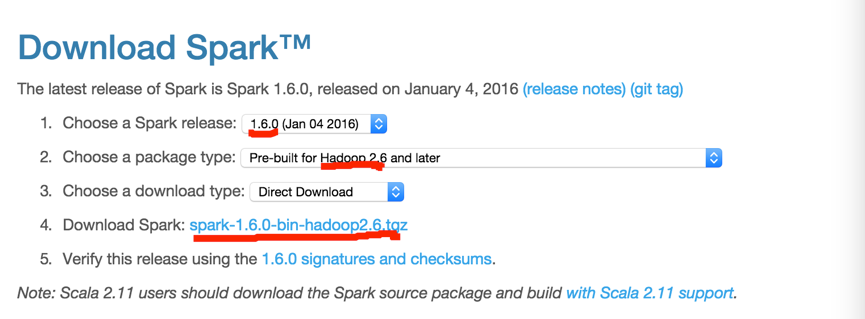
2.2 解压
下载也是在Downloads目录下,用tar解压到当前:

拷贝到/usr/local/spark目录下:

2.3 配置Spark环境变量
配置也是先对Master进行,用vim命令进入bashrc:

添加如下内容,包括bin目录:
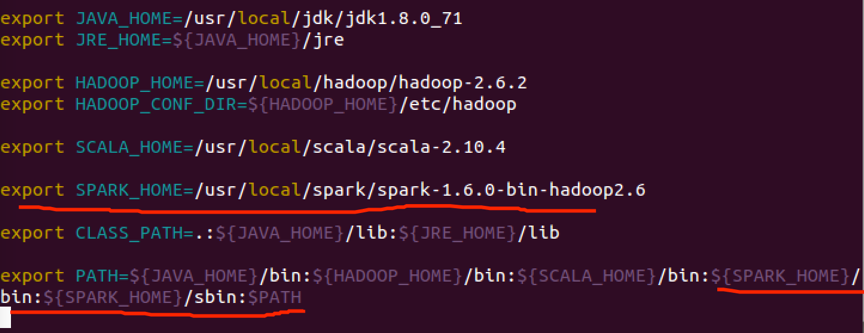
2.4 单台设置Spark文件配置
我们这里配置3个文件,
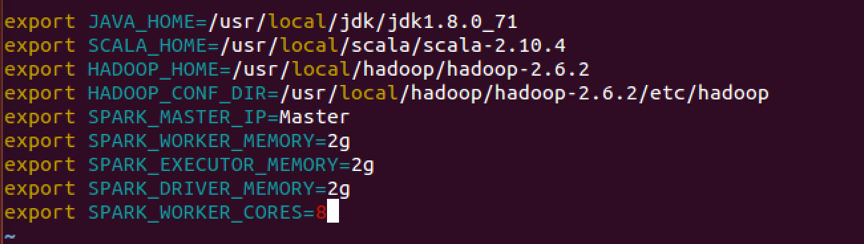
- 配置spark-env.sh
因为只有临时文件spark-env.sh.template,先拷贝出spark-env.sh
添加如下内容:
- 配置slaves
因为只有临时文件slaves.template,先拷贝出slaves
修改内容如下:
- 配置spark-defaults.conf
因为只有临时文件spark-defaults.conf.template,先拷贝出spark-defaults.conf
添加如下内容:
到这里单机spark已经完成。




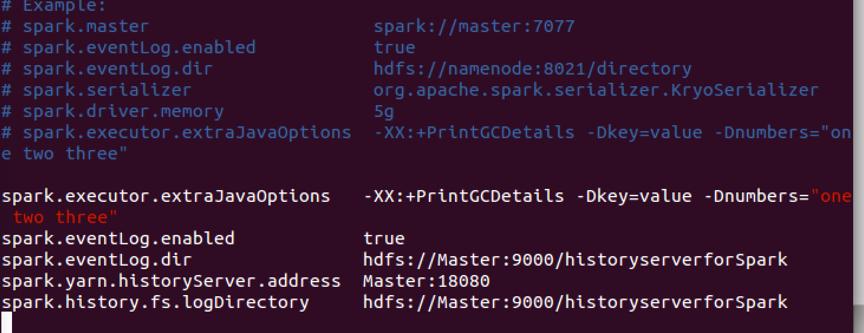
3.运行Spakr集群
把scala,spark,bashrc传到其他Worker上。
传scala文件夹(截图就取Worker1,Worker2,Worker3请自行传输过去):

传spark文件夹(截图就取Worker1,Worker2,Worker3请自行传输过去):

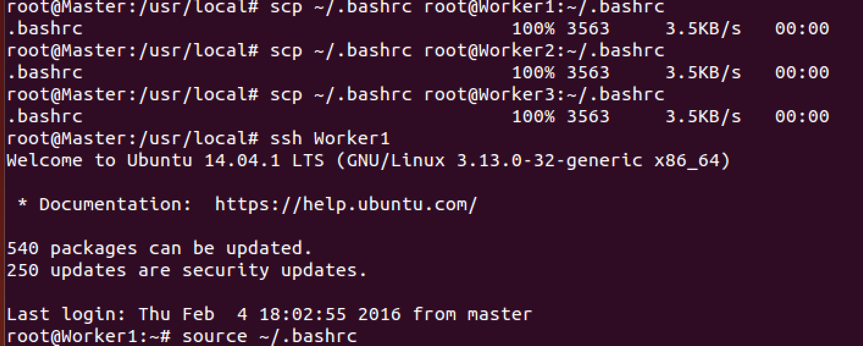
传bashrc文件,并使其有效(截图就取Worker1,Worker2,Worker3请自行传输过去):
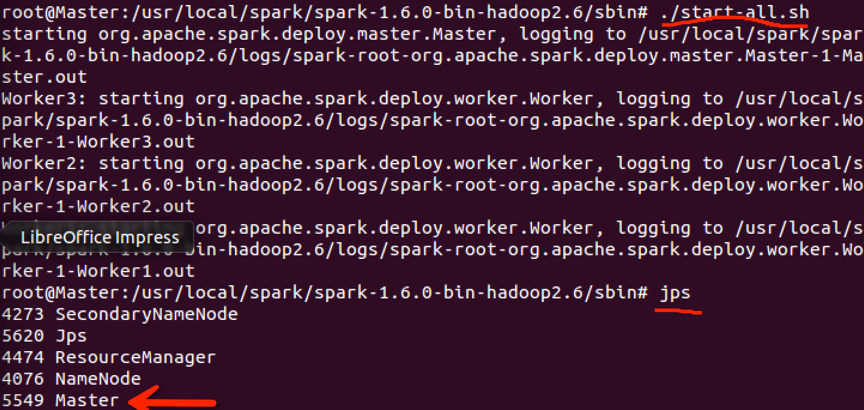
直接在sbin下运行start-all.sh,再用jps命令查看,如下所示就是启动成功了:
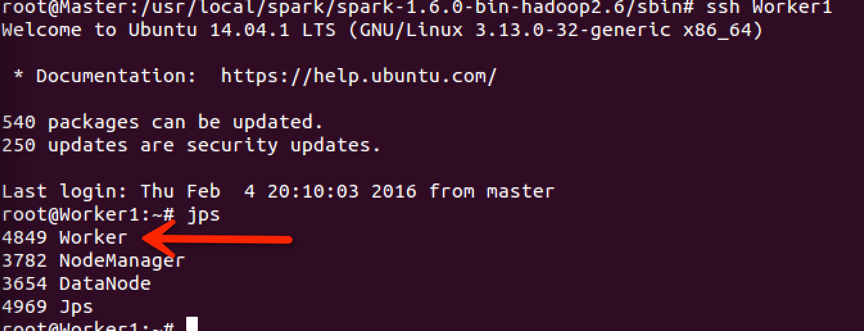
登入到Worker节点,用jps查看:
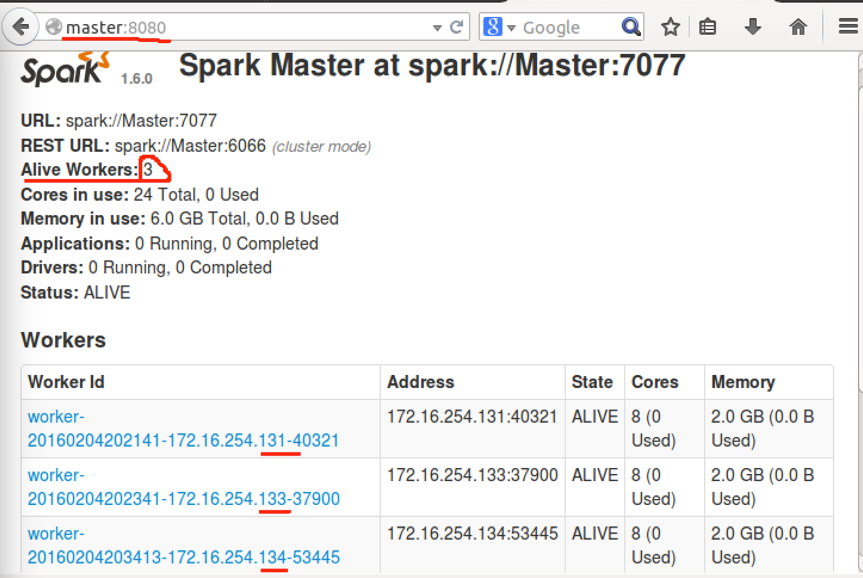
登入master:80080 在页面查看:
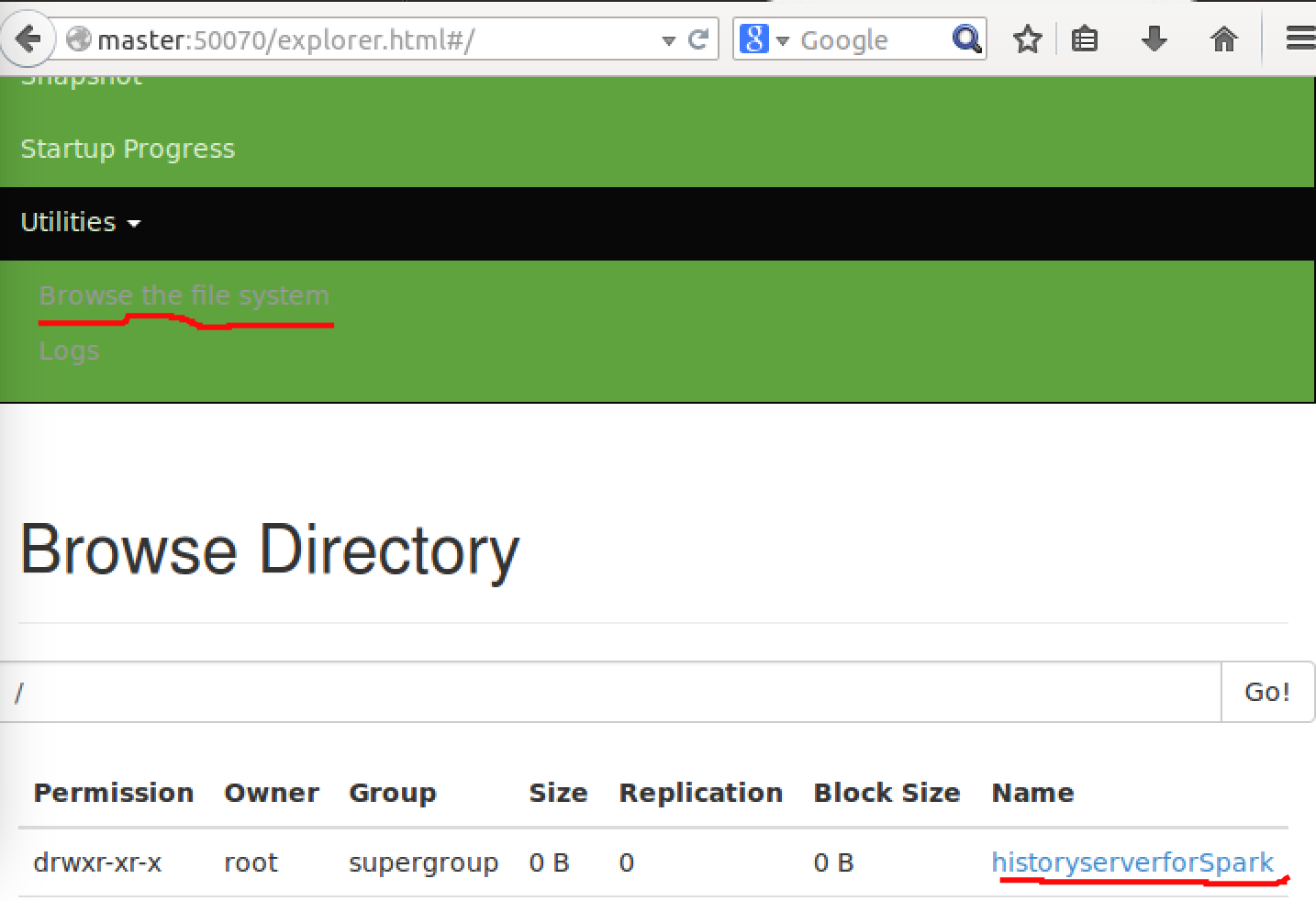
创建一个historyserverforSpark文件夹,用来放历史日志。

可以在master:50070中查到这个文件夹:
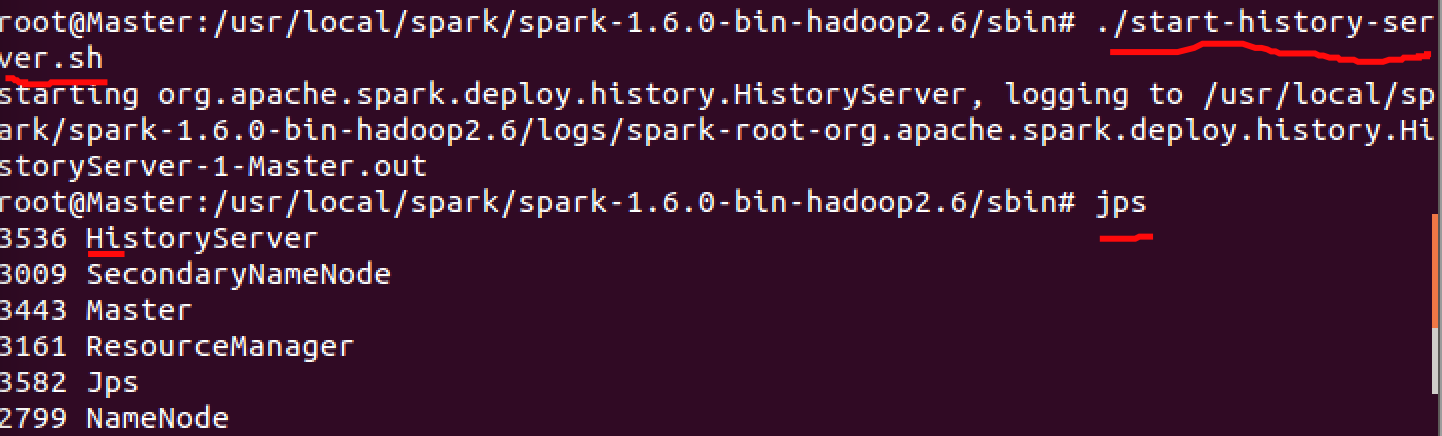
再开启historyserver,并用jps来查看是否开启成功。
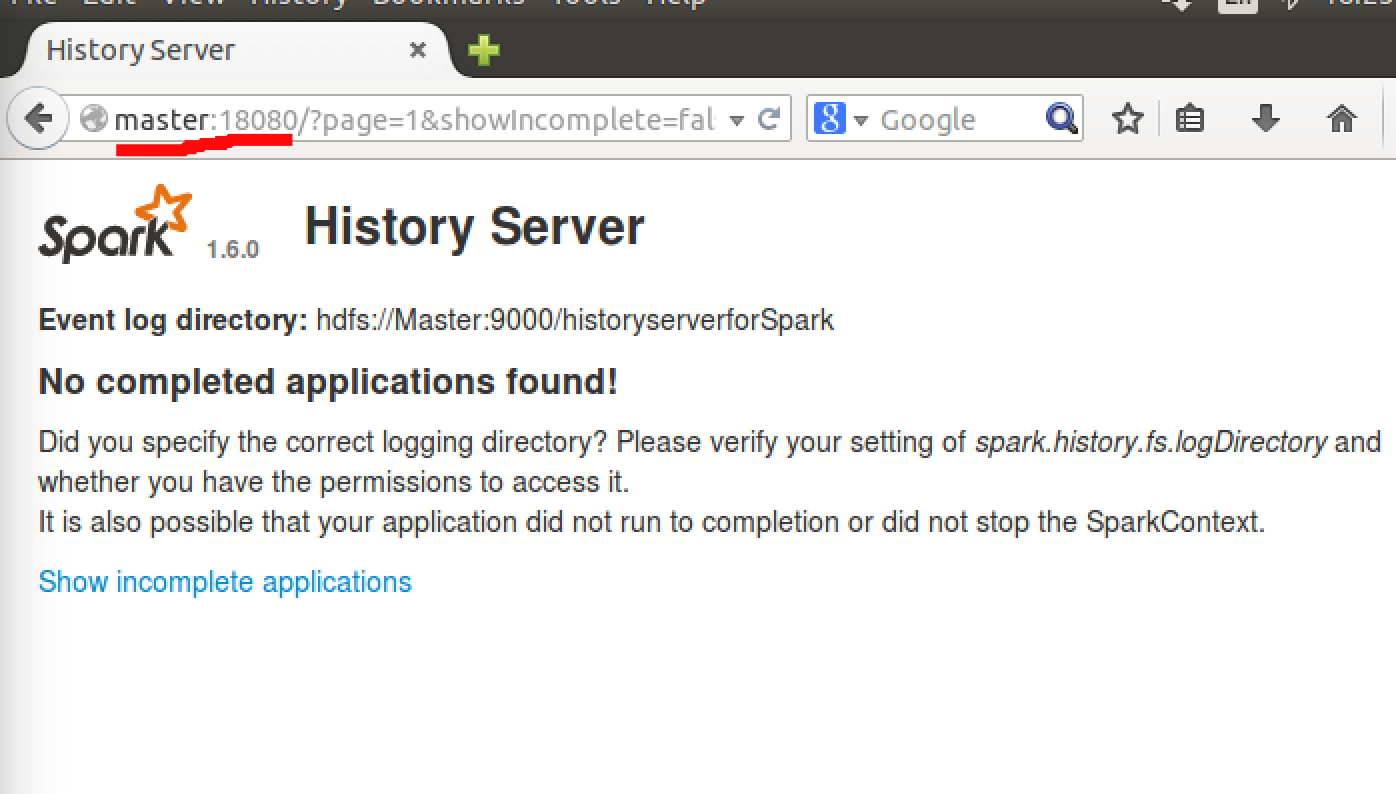
这个时候可以在页面登入到Master:18080 来查看historyserver
还可以在并里面运行,spark-shell。看到版本好了。成功啦。
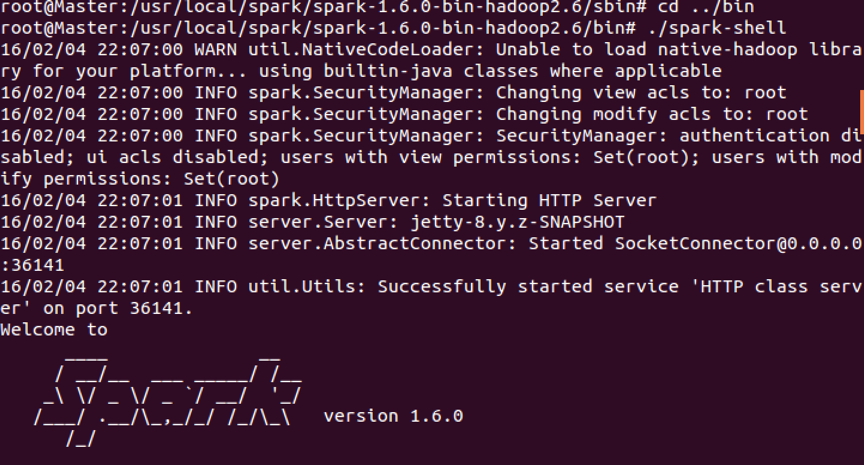
到此整个搭建过程就完成来。请读者仔细跟着这5个博客操作就可以了。
下面是用shell做个简单的测试(这个是后加的内容,所以图片颜色不一样),在spark-shell里写下如下代码:

可以在master:4040/jobs 里面查看到spark-shell里运行的任务:

也可以在master:18080 里查看到历史任务:

XianMing















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









