







一、OCR简介
什么是 OCR
OCR,即 Optical Character Recognition,是光学字符识别
的简称。它是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。简言之,OCR 技术可以将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工。
OCR 技术基于图像处理和模型识别技术,其应用场景非常广泛,包括文档数字化、数据提取、自动翻译、安全监控、智能客服等,还可以应用于医疗、金融、教育等领域。衡量一个 OCR 系统性能好坏的主要指标包括拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
技术路线:

Tesseract OCR
官网:Tesseract OCR - industry-fastest .Net OCR library
Tesseract OCR 是一款开源的文本识别(OCR)引擎。它主要用于识别图片中的文字,并将其转换为可编辑的文本。Tesseract OCR 是目前公认最优秀、最精确的开源 OCR 系统之一。
Tesseract OCR 支持多种语言,包括英文、中文、德文、法文等,并可以通过训练来扩展识别其他语言。它能够处理各种图像文件格式,如JPEG、PNG、TIFF 等。此外,Tesseract OCR 的准确性在同类产品中处于领先地位,对于印刷体文本的识别率高达 95% 以上。
Tesseract OCR 采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。它的主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
值得一提的是,Tesseract OCR 提供了灵活的 API 接口,可以轻松集成到各种应用中。这款软件已经有 30 年的历史,最初是惠普实验室的一款专利软件,然后在2005年开源,自 2006 年后由 Google 赞助进行后续的开发和维护。
GitHub:GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)
二、Python图片文本识别代码
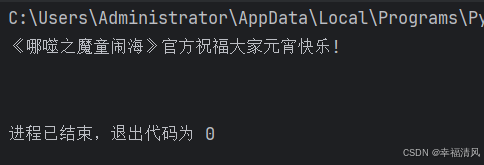
这里我准备了一张图片,用 tesseract-ocr 识别该图片中的文字

python代码:
import os
import pytesseract
from PIL import Image
output_path = r'C:\Users\Administrator\Desktop\test.png'
image = Image.open(output_path)
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)结果:
三、Tesseract OCR的下载与安装
3.1 下载
下载页面:Downloads | tessdoc
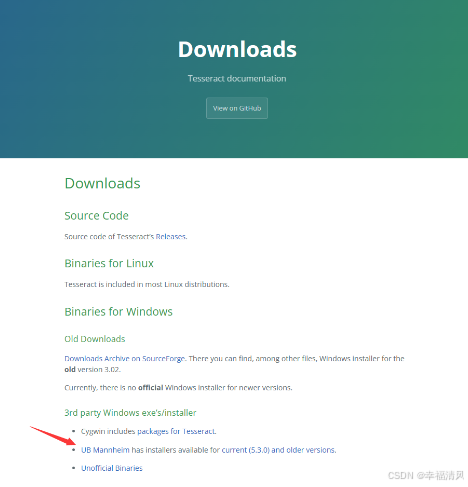
在这里可以下载最新的二进制安装包
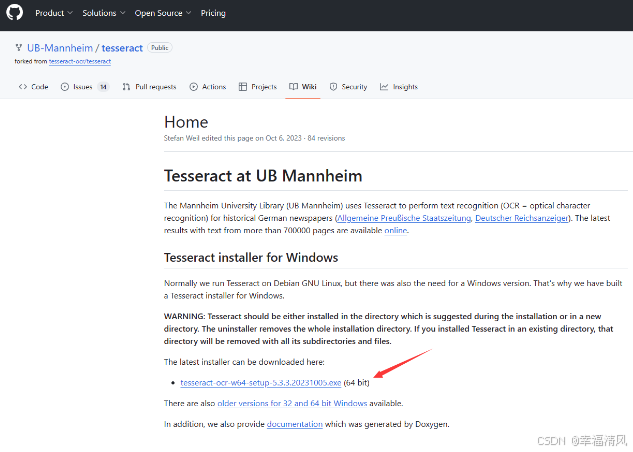
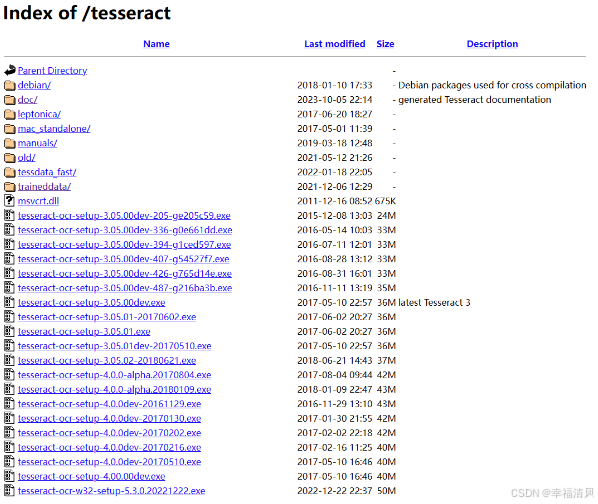
如果想要下载旧版本可在该地址中下载:Index of /tesseract
3.2 安装
下载完成之后,双击进行安装
选择语言,点击 OK
点击 Next
点击 I Agree
点击 Next
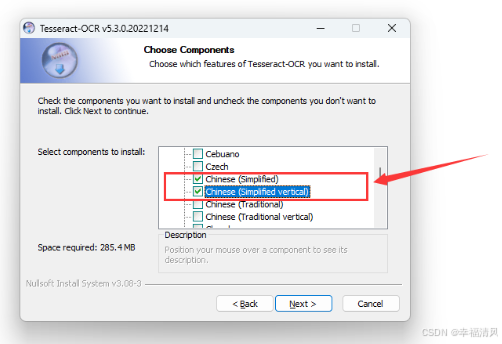
这里有一个 Additional language data (download)添加语言库的选项,可以添加所需要识别的语言
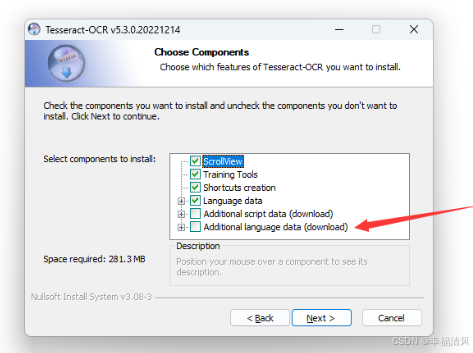
比如你需要它识别中文和英文,则可以选择
- Chinese (Simplified):简体中文
- Chinese (Simplified Vertical):简体中文(竖排)
- English:英文
再点击,Next
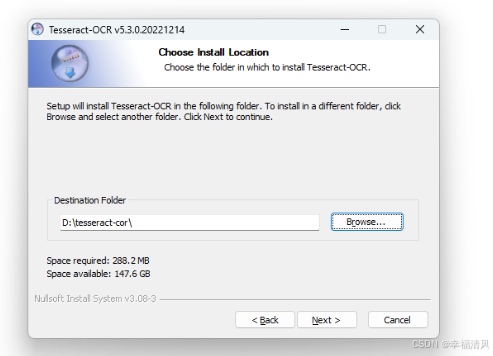
选择安装路径,再点击 Next
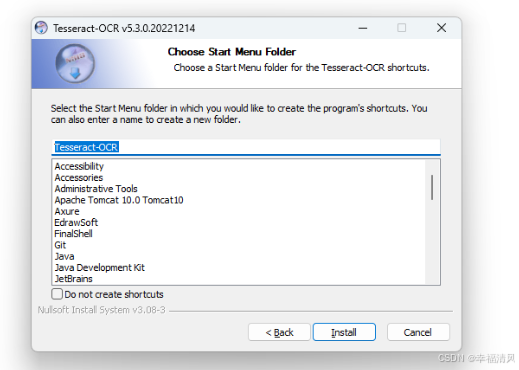
点击 Install 开始安装
点击 Next
点击 Finish 安装结束
3.3 配置环境变量
安装完成之后需要修改一个环境变量
鼠标右键 我的电脑(此电脑) - 属性 - 高级系统设置 再选择 环境变量
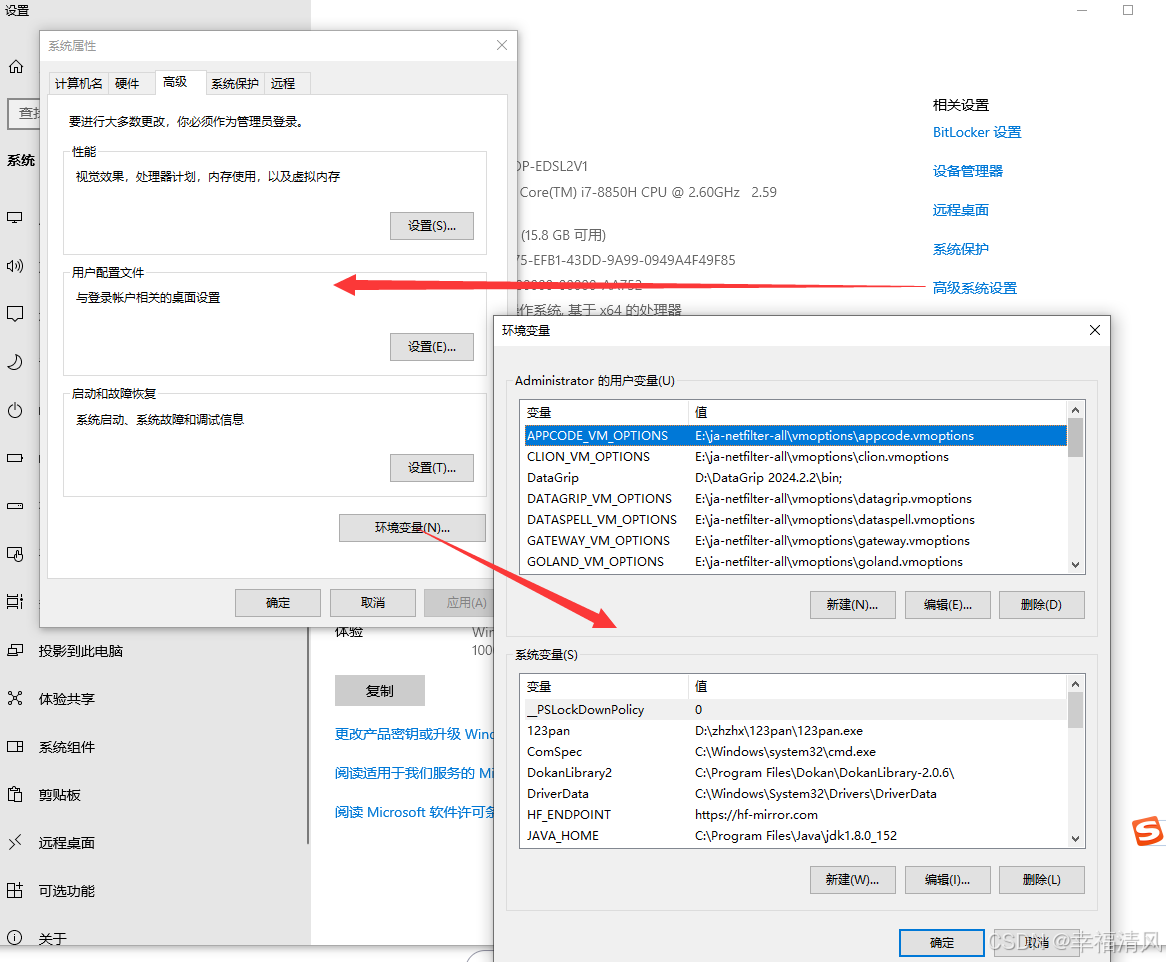
找到 Path
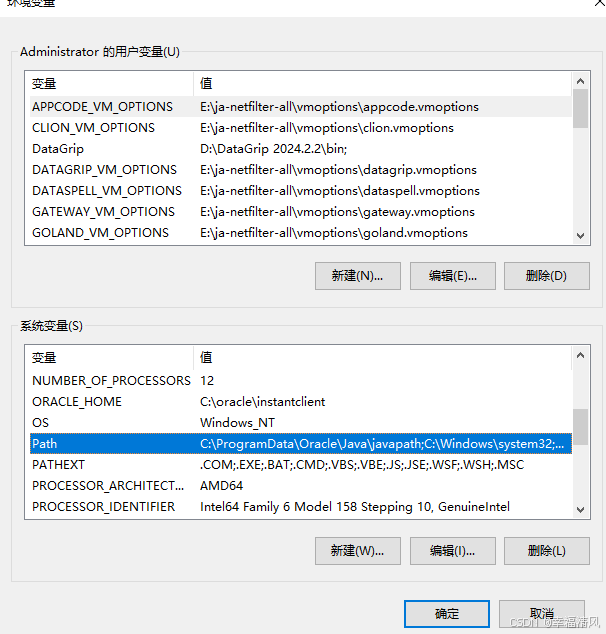
将安装地址配置在末端,例如:;D:\tesseract-cor,记得加上 ;
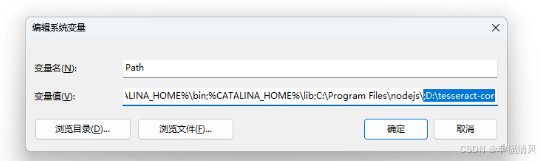
再添加一个系统变量:
- 变量名:
TESSDATA_PREFIX - 变量值:
安装地址\tessdata
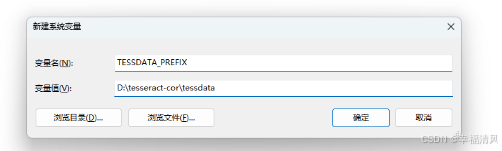
然后 确认 保存即可
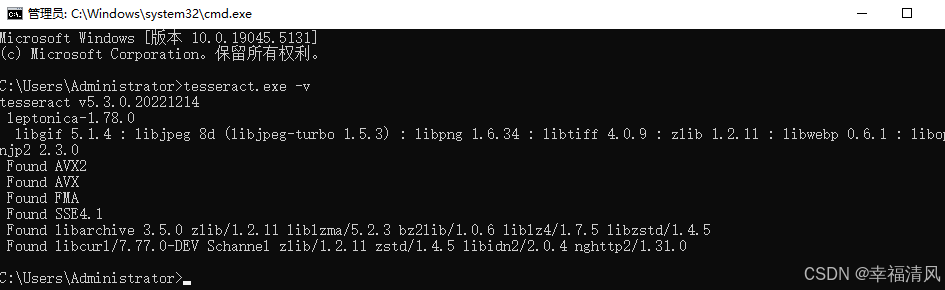
配置好之后就可以 win + R,输入 cmd 调出命令命令窗口
输入:tesseract.exe -v,能看到对应的版本信息就表明环境变量配置成功了
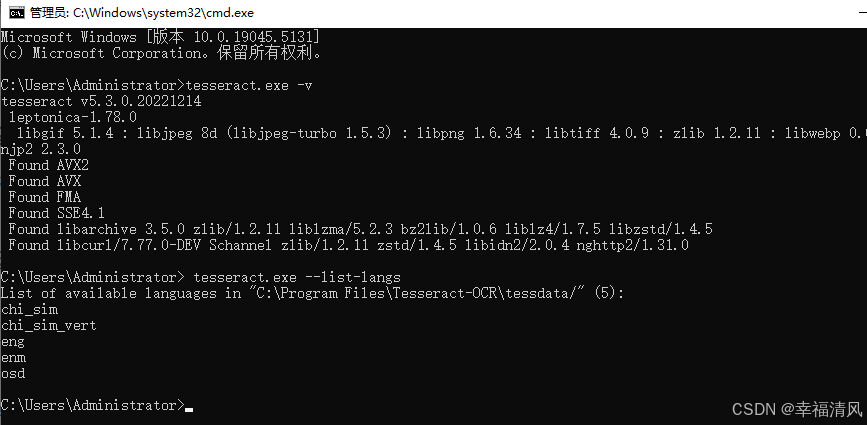
通过 tesseract.exe --list-langs 命令可以查看 tesseract 所支持的语言包

















 4000
4000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









