






利用轻量级SSD神经网络进行快速神经元细胞检测
敬如意 计算机科学系 美国新泽西州罗格斯大学 jy486@cs.rutgers.edu
吴鹏翔 计算机科学系 美国新泽西州罗格斯大学 pw241@cs.rutgers.edu
丹尼尔J.Hoeppner 利伯大脑发展研究所 霍普金斯医学校园,MD,美国daniel.hoeppner@libd.org
DimitrisMetaxas 计算机科学系 美国新泽西州罗格斯大学 dnm@cs.rutgers.edu
摘要
识别神经细胞的谱系路径对于理解大脑的发育是至关重要的。 准确的神经细胞检测是获得可靠的细胞谱系描述的关键步骤。为了解决这个问题,本文提出了一种基于SSD(单发多盒探测器)神经网络模型的高效神经元细胞检测方法。我们的方法适应原有的SSD架构,并去除不必要的块,导致轻量级的模型。此外,我们将细胞检测制定为二元回归问题,这使得我们的模型更简单。实验结果表明,只需要一个小的训练集,我们的方法就能够快速准确地捕捉严重形变的神经细胞。
1. 引言
建立从单个神经干/祖细胞到神经元,星形胶质细胞和少突胶质细胞产生的谱系路径对于正常脑发育的研究是至关重要的[8]。 在谱系史中,神经细胞通过有丝分裂自我分裂,通过丝状伪足和片状伪足彼此物理相互作用,旨在建立分化的局部生态位(生态龛),促进成熟并最终产生神经元突触。
研究神经细胞的谱系路径的一种方法是通过记录时间推移视频中的细胞命运转变。 然后检测视频中不同类型的神经细胞后代,这是分类细胞,捕获它们之间的相互作用并鉴定细胞谱系的关键的前提步骤。传统上,这是由逐帧检查延时视频的专家手动执行的。 然而,手工注释遇到诸如相当耗时和重复性有限的问题。因此,对自动细胞检测方法的要求非常高,以提高效率并减少研究人员的工作量。
尽管如此,由于细胞的严重聚集和形状畸变以及细胞数量急剧增加(图1),这项任务非常具有挑战性。另外,不明显的背景变化(例如照明条件)以及背景中存在死细胞和杂质,对检测构成另一个挑战。这些因素使得传统的基于特征的手工检测方法(如基于HOG特征的检测器[2])无法应对这个问题。
近年来,深度神经网络(DNNs)在物体检测领域取得了巨大的成功[5,4,11,9,10,7]。与手工提取特征不同,DNN的特征是通过学习构建的,因此更加通用和可扩展,从而在实践中获得更好的性能。Girshick等[5]提出了一个开创性的工作,他们提出了一种将经典区域提议和卷积神经网络(CNN)相结合的R-CNN方法,用于鲁棒的目标检测和分类。R-CNN取得了巨大的成功,并在[4,11]中得到进一步完善。然而,虽然准确,R-CNN方法家族在计算上仍然太昂贵,太慢而不适合实时应用。为了克服这个问题,Redmon等[9]提出用一种新颖的YOLO检测系统直接预测目标包围盒,比R-CNN更简单,更快速,同时达到更高的精度。在[7]中,刘等人。更进一步,提出了一种消除提案生成和后续重采样阶段的单发多盒检测器(SSD)方法,并且能够获得比YOLO系统更高的精度和速度。在本文中,我们采用修改后的轻量级SSD模型进行神经细胞检测。自适应模型将单元检测制定为二元回归问题,并且比原始版本小得多。
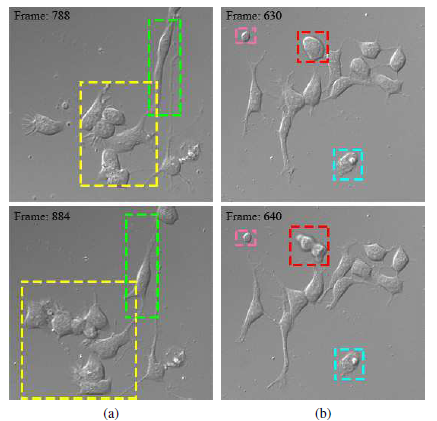
图1:神经细胞检测挑战的例证。(a)在成熟的过程中,神经细胞倾向于伸展它们的丝状伪足和片状伪足,扭曲自身(绿色框)和聚集体(黄色框),对鲁棒的细胞检测构成挑战。(b)为了形成一个神经网络,他们需要执行有丝分裂(红框),这导致了外观的大变化。此外,死细胞(青框)和杂质(粉盒)的存在也增加了从背景提取细胞的挑战。
DNN的一个问题是对训练数据的强烈需求。在小数据集(如我们的神经细胞(仅有1595帧))的情况下,模型性能可能急剧下降。为了解决这个问题,我们将学习权重从预先训练好的模型(例如,VGG-16[13])转移到我们的改进版本,并在神经细胞图像上进行微调(以SSD训练好的模型微调改进版本训练细胞图像)。这种转移学习过程使得我们的细胞检测模型能够从训练的SSD模型中继承学习的“对象性”(一种算法“Objectness”)概念[6],从而帮助我们的模型只用一个小的训练集来捕捉神经细胞的特征。 实验结果表明,我们的方法能够以相对较高的准确度快速检测细胞。
本文的其余部分安排如下。 我们在第2节中详细介绍了我们的细胞检测模型。第3节提供了实验结果和相应的讨论。我们的工作总结在第4节。
2. 方法
2.1 网络架构
我们的方法的神经网络结构如图2所示。对于每个输入图像,它形成一个平均裁剪为300×300×3的张量。然后将一系列前馈卷积层应用于输入图像。网络的底部(块1到块5)基于VGG-16[13],对此ImageNet[12]上的预训练权重是可用的。我们将这些学习权重转移到底部,并在我们的神经细胞图像上进行微调。与原来的SSD型号相比,我们的改装版本去除了多个中间层,因此体积更小。特别是,我们的网络模型是10亿FLOP(在乘法方面)小于原来的版本。
为了在多个尺度上进行检测,从块4(38×38)和块7(19×19)的层提取我们的特征图。对于每个特征图,它包含特定数量的默认边界框,这些边界框具有一定的比例和纵横比(见第2.2节)。将两种不同类型的滤波器(即位置和对象)应用于两个特征图以预测边界框偏移以及对象分数。最后,将一个Sigmoid层添加到对象预测层的末尾,以将对象分数限制为[0,1]。
2.2 默认框提名
生成可能的目标位置的两种常用策略是滑动窗口和区域提名。然而,滑动窗口方法在训练和预测中具有极高的计算成本。当窗口纵横比和尺度有很多选择时,计算就变得不可行。相比之下,区域提名更好地工作,但在计算上仍然昂贵[11,14]。为了解决这个问题,SSD模型采用了默认的盒子[7],这在很大程度上提高了速度与精度之间的平衡。
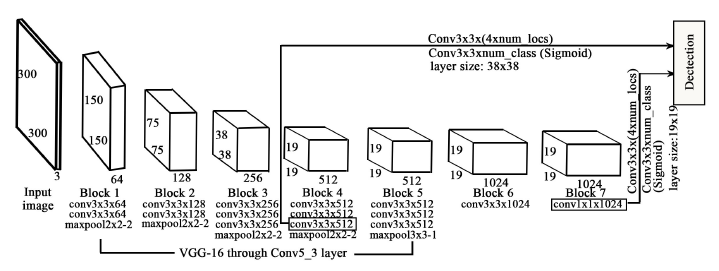
图2:检测网络架构概述。两个特征图(38×38和19×19)被用来预测每个细胞的位置偏移和目标得分。这里,numlocs表示边界框的数量,这取决于为特定图层指定的边界框比例和高宽比; num类是单元类的数量(本文中为1)。
在默认框策略中,将特征映射(38×38和19×19)划分为具有1×1大小的块的网格,并且在这些块中确定默认框的中心。特别的是,默认框的中心被设置为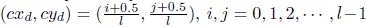
在成熟的过程中,神经细胞往往变得细长(图1中的绿色框),以便它们可以与周围的其他细胞进行主动通信,并最终形成神经网络。根据这个属性,我们选择对38x38的特征图的宽高比为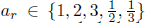
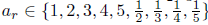
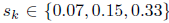

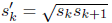
在对默认框设置好尺度和长宽比之后,我们可以接着以公式
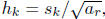
2.3 编码ground truth框
在从第2.2节获得默认框之后,我们需要将groundtruth边框作为默认框进行编码,以便我们可以获得它们相对于网格框中心的偏移,相应的默认框标签及其对象分数。通过这种方式,我们将groundtruth边框转换成可以输入到我们的SSD模型进行训练的形式。
转换步骤如下。首先,我们通过计算他们的jaccard(jaccard相似度可以看成两个集合A,B的交集占并集的比例:Jaccard Sim = (A∩B) / (A∪B),其实就是计算A与B产生重叠的程度。)索引来比较groundtruth框和每个默认框。如果jaccard值大于忽略阈值(0.45),那么默认框就是相应的编码结果。在这种情况下,默认框的对象标签将被设置为1,并将jaccard值保留为默认框的对象分数,并且groundtruth框和编码默认框之间的位置偏移也将被记录下来。但是,有可能两个groundtruth框将匹配相同的默认框。在这种情况下,我们只保留一个更高的jaccard值。因此,总的来说,编码的地面真实向量由位置偏移(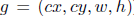
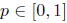
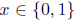
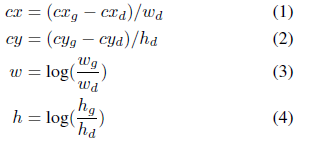
这里(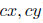
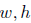
2.4 损失函数
总的损失是位置偏移损失与目标得分损失的加权总和:
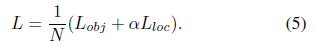
其中N是匹配的默认框的数量。位置偏移损失在[4,7]中被定义:
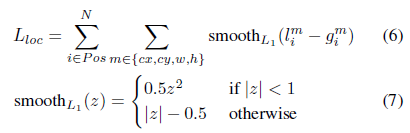
其中i 为标签为1的默认框的索引,而l 和g 分别为被预测的框的偏移和编码框的偏移。目标分数损失通过二元交叉熵计算:
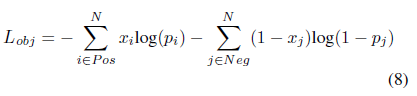
这里,p是被预测框的目标分数,并且x∈{0,1}是编码标签,这表达了默认框的目标。当计算负默认框的目标得分损失时,使用Hardnegtive mining(硬负挖掘)[7]。这样我们在正负训练样本之间保持平衡。
3. 实验
我们实验中使用的神经细胞数据来自一系列时间推移的显微镜视频,我们从中总共采集2658个图像。在这些图像中,60%用于培训,20%用于验证,20%用于测试。考虑到我们的训练集相对较小(仅有1595个图像),我们还通过随机裁剪和翻转来进行数据增强。在预测部分,对象分数大于0.4的框被接受为细胞边框。使用0.5阈值的非最大抑制来消除相似的边界框。我们的模型是用Keras库[1]在Python中实现的,并且在单个NvidiaK40 GPU上进行了训练和测试。
根据文章[3]计算检测精度。如果预测边框和groundtruth框之间的jaccard重叠超过0.5,则预测框将被认为是正确的。测试图像的精度(共531帧)为83%,平均检测速度为10 FPS。 我们相信用更强大的硬件(例如,原始SSD模型[7]使用的Nvidia Titan X),检测速度会进一步提高。

图3:检测结果。顶行:成功的例子,其中神经细胞的预测包围盒由绿色框表示。底部行:用黑色箭头指向的失败案例。特别是,(d)和(e)分别说明了太长而难以捕获的细胞,而(f)提供了两个新生成的有丝分裂细胞太小而不能识别的失败情况。
图3显示了我们检测结果的几个例子。可以观察到,我们的方法能够优质地处理细胞聚集和形状变形。我们还在图3中显示几个失败案例(箭头指向),这可能是由于少量的特征映射或默认框缺少比例和纵横比选项造成的。解决这个问题的一个方法是丰富可用的尺度和纵横比规格,但这也意味着对训练数据的需求增加。

图4:(a)基于HOG的SVM检测器和(b)我们的轻量级SSD模型的检测结果比较。 与HOG检测器相比,我们的模型更好地处理杂质和死细胞的干扰,并以更精确的方式捕获目标细胞。
为了说明我们的轻量级SSD模型相对于基于手工特征检测方法的优势,在图4中,我们将模型与经典的基于HOG的SVM检测器进行比较[2]。可以看出,HOG检测器对杂质非常敏感,无法区分死细胞和正常细胞,而我们的方法相对更为鲁棒,并且能很好地处理背景干扰。HOG检测器的精度和召回率分别为60%和44%,而我们的轻量级SSD模型分别为83%和96%,大幅度超越HOG检测器。而且,我们的方法(每帧0.1s)比HOG检测器(每帧6.72s)快67倍。
4. 结论
在本文中,我们将改进的轻量级SSD模型应用于神经细胞检测问题。 与原来的SSD架构相比,我们的改装版本体积更小。 此外,我们的模型将细胞检测制定为二元回归问题,使其更易于部署。 实验结果表明,我们的方法能够准确,快速地检测神经细胞,为未来的细胞分类和谱系建立奠定基础。
参考文献
[1] F. Chollet. Keras. https://github.com/fchollet/ keras,2015.
[2] N. Dalal and B. Triggs. Histogramsof oriented gradients for human detection. In CVPR, pages 886–893 vol. 1, June2005.
[3] M. Everingham, L. Van Gool, C. K.I.Williams, J.Winn, and A. Zisserman. The pascal visual object classes (voc)challenge. International Journal of Computer Vision, 88(2):303–338, 2010.
[4] R. B. Girshick. Fast R-CNN. CoRR,abs/1504.08083, 2015.
[5] R. B. Girshick, J. Donahue, T.Darrell, and J. Malik. Rich feature hierarchies for accurate object detectionand semantic segmentation. CoRR, abs/1311.2524, 2013.
[6] S. D. Jain, B. Xiong, and K.Grauman. Pixel objectness. CoRR, abs/1701.05349, 2017.
[7] W. Liu, D. Anguelov, D. Erhan, C.Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD: single shot multibox detector.CoRR, abs/1512.02325, 2015.
[8] R. Ravin, D. J. Hoeppner, D. M.Munno, L. Carmel, J. Sullivan, D. L. Levitt, J. L. Miller, C. Athaide, D. M.Panchision, and R. D. McKay. Potency and fate specification in cns stem cellpopulations in vitro. Cell Stem Cell, 3(6):670–680, 2004.
[9] J. Redmon, S. K. Divvala, R. B.Girshick, and A. Farhadi. You only look once: Unified, real-time objectdetection. CoRR, abs/1506.02640, 2015.
[10] J. Redmon and A. Farhadi. YOLO9000:better, faster, stronger. CoRR, abs/1612.08242, 2016.
[11] S. Ren, K. He, R. B. Girshick, andJ. Sun. Faster R-CNN: towards real-time object detection with region proposalnetworks. CoRR, abs/1506.01497, 2015.
[12] O. Russakovsky, J. Deng, H. Su, J.Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein,A. C. Berg, and F. Li. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015.
[13] K. Simonyan and A. Zisserman. Verydeep convolutional networks for large-scale image recognition. CoRR,abs/1409.1556, 2014.
[14] J. R. R. Uijlings, K. E. A. van deSande, T. Gevers, and A.W. M. Smeulders. Selective search for objectrecognition. International Journal of Computer Vision, 104(2):154–171, 2013.















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









