







本文将会继续介绍——如何为STM32H7S78-DK开发板准备CMake项目、如何将TFLM集成到基于CMake的STM32项目中、如何在STM32H7S78-DK开发板上运行TFLM基准测试,具体包括如何支持计时和printf输出、如何集成TFLM到基于CMake的STM32项目,以及解决过程中遇到的一些问题。
本系列博文目录:
- 【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】 (背景介绍、初步体验、框架移植)
- 【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】 (平台适配、编译集成、基准测试)
- 【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【DSP指令加速篇】 (CMSIS-NN简介、TFLM+CMSIS-NN集成、TFLM+CMSIS-NN测试)
一、上篇回顾
书接上回,上篇文章主要分为TFLM是什么、TFLM初步体验、TFLM源码浅析、TFLM主体移植几个部分。其中,TFLM初步体验部分将会介绍如何在PC上运行TFLM基准测试,TFLM源码浅析部分主要介绍TFLM源码是如何进行构建的,TFLM主体移植主要介绍如何在基于CMake的STM32项目中构建TFLM库和基准测试。
上篇链接: https://blog.csdn.net/xusiwei1236/article/details/142467410
二、项目准备
2.1 准备模板项目
项目模板采用基于CMake的STM32H7S78-DK项目,代码仓为:
https://gitcode.com/xusiwei1236/STM32H7S78-DK-XIP
该项的ioc文件来自官方STM32CubeH7RS软件包Template_XIP项目,修改了部分配置,项目类型改为了CMake;然后使用CubeMX生成的项目代码即为本项目的主要代码。
2.2 支持计时功能
STM32上,使用HAL库记录耗时非常简单,只需要用:
HAL_GetTick()获取Tick数即可,默认的Tick频率是1000Hz;- 需要注意的是:
HAL_GetTickFreq()返回的枚举值,并不是实际的频率(例如默认的HAL_TICK_FREQ_1KHZ,其值为1,而不是1000)。
因此,记录使用HAL_GetTick记录耗时,代码类似:
uint32_t start = HAL_GetTick();
// 需要记录耗时的代码
uint32_t end = HAL_GetTick();
float cost_s = (end - start) / 1000.0f; // 实际耗时(单位:秒)
这部模板本身已经支持了,不需要额外的工作。
2.3 配置UART4引脚
开发板上自带了ST-Link V3调试器,该调试器带有虚拟串口功能。通过查阅原理图,我们知道主控MCU和ST-Link之间的连接关系如下图:
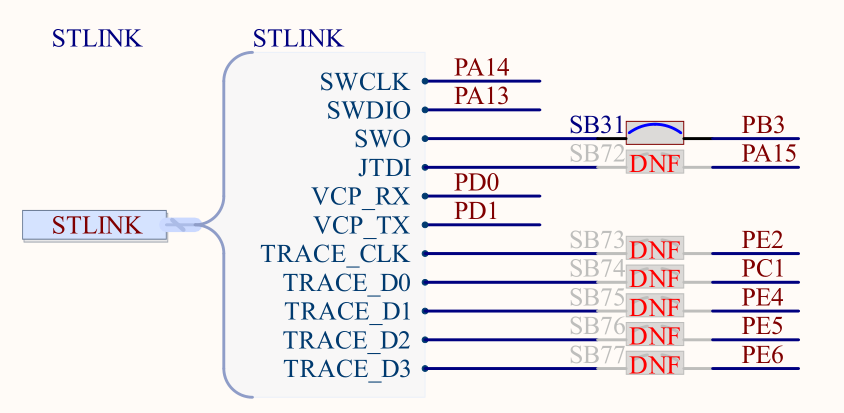
可以看到,ST-Link的虚拟串口和主控芯片的连接关系为:
- VCP_RX连接到主控芯片的 PD0上;
- VCP_TX连接到主控芯片的 PD1上;
接下来,需要修改这两个引脚的功能:

启用UART4功能:
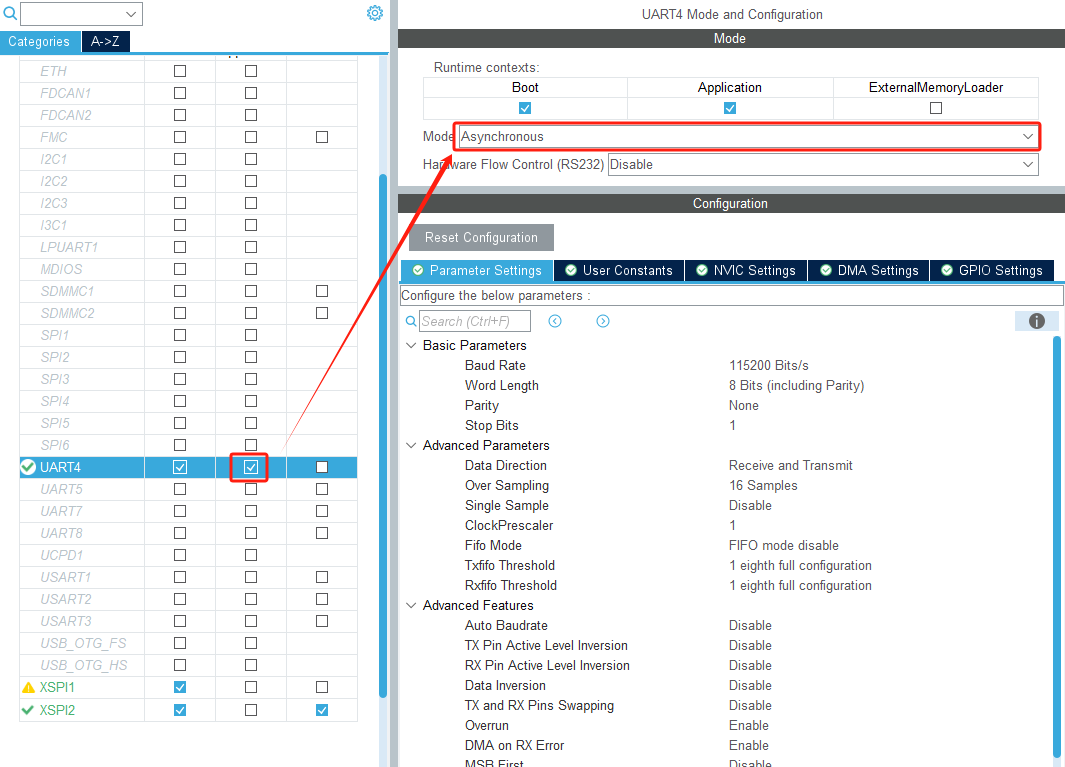
完成上述修改后,Ctrl+S保存,然后重新生成项目代码。
2.4 支持printf重定向到UART4
CubeMX选择CMake项目后,默认已经生成了 syscalls.c文件,已经实现了支持gcc工具链的printf输出的一半功能:
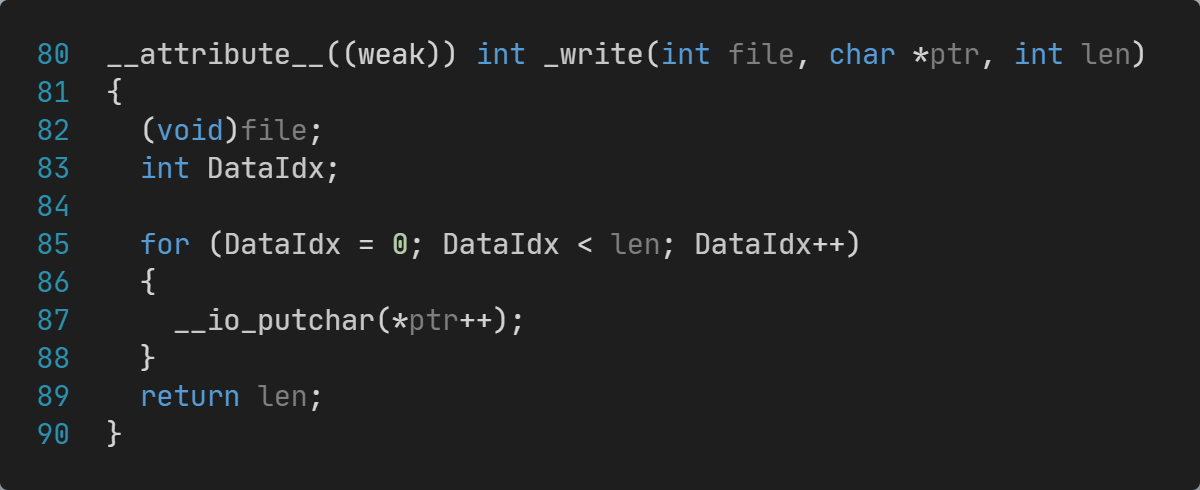
这个_write支持printf和fprintf调用__io_puchar进行输出。
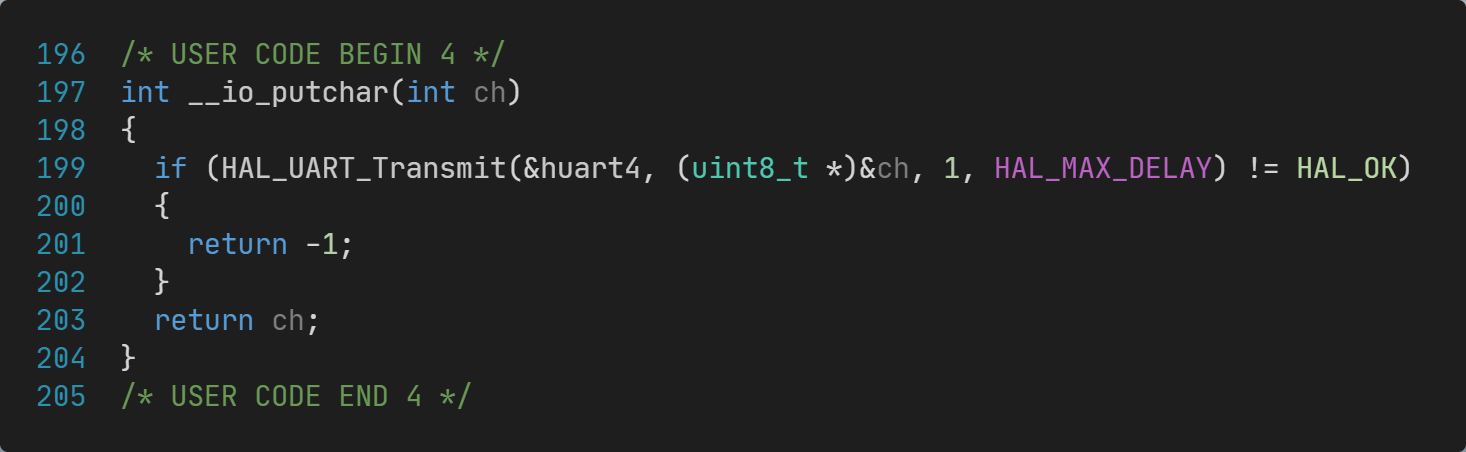
另外一半功能——实现__io_puchar输出到UART即可实现printf输出到UART。
需要手动修改main.c文件,实现__io_puchar函数:
2.5 支持printf输出浮点数
默认生成的CMake项目不支持浮点数打印,需要修改链接选项,修改文件Appli\CMakeLists.txt:
在末尾添加如下代码片段:
target_link_options(${CMAKE_PROJECT_NAME} PRIVATE
-u _printf_float
)
之后,再次编译,就可以输出浮点数了。
2.6 支持printf不带\r的换行
大部分串口终端工具,例如MobaXterm,换行需要收到\r\n两个字符才能正常换行。通过修改代码,可以让测试代码输出\n结尾也能和\r\n一样自动换行,具体实现方式为:
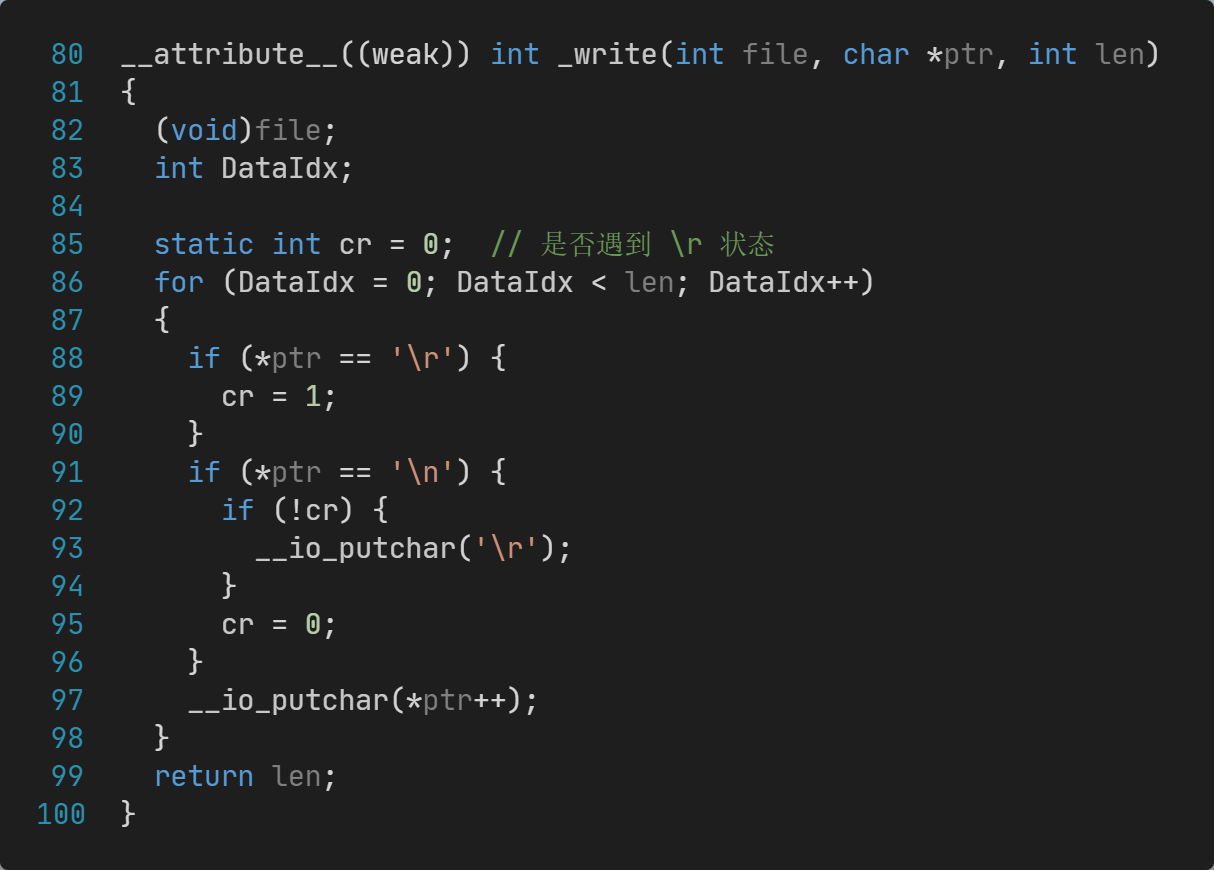
这样修改之后,printf就同时支持了\r\n和\n两种换行符。
2.7 支持ccache编译缓存
修改CMake有时候需要清理build目录才能正常出发重新配置和构建,但清理了build目录后重新构建的过程非常耗时。为了解决这个问题,我们可以使用ccache进行加速。
ccache下载链接: Ccache — Download
Windows平台的ccache是压缩包,解压到合适的目录后,将其配置到PATH环境变量,即可在任意位置使用ccache命令。
完成ccache配置之后,可以咋CMake代码中加入如下片段,实现CMake支持ccache加速:
find_program(CCACHE_PROGRAM ccache)
if (CCACHE_PROGRAM)
set(CMAKE_C_COMPILER_LAUNCHER "${CCACHE_PROGRAM}")
set(CMAKE_CXX_COMPILER_LAUNCHER "${CCACHE_PROGRAM}")
message(STATUS "Ccache found: ${CCACHE_PROGRAM}!")
else ()
message(STATUS "Ccache not found!")
endif ()
三、TFLM集成
3.1 添加tflite-micro源码
首先,将PC上运行过基准测试的TFLM代码拷贝到CubeMX生成的基于CMake的STM32H7S78-DK项目中,并放在如下目录:
Middlewares/tensorflow
然后,将前“TFLM移植”章节编写完成的CMakeLists.txt文件、micro_time.cc文件,也放到这个目录中。另外,将后下一步需要修改的generate_cc_arrays.py文件也拷贝一份放到该目录中。
完成上述操作后,项目文件布局如下:
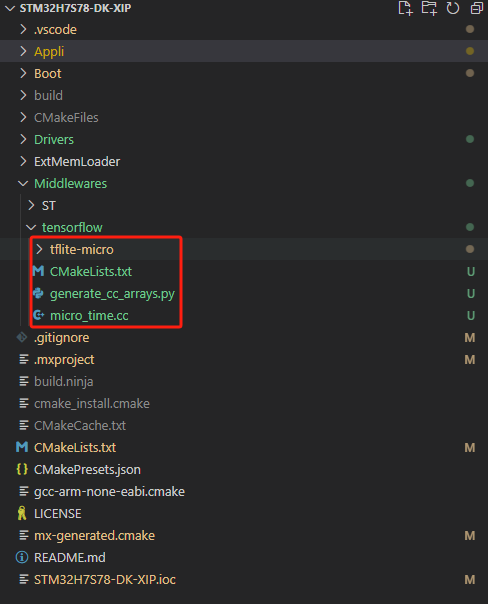
3.2 修正micro_time.cc代码
TFLM默认的micro_time.cc文件在STM32上不能正常工作,上篇文章已经给出了一个版本的实现,经过测试上篇文章的代码不能实现预期。
实际需要修改为使用调用HAL库的代码:
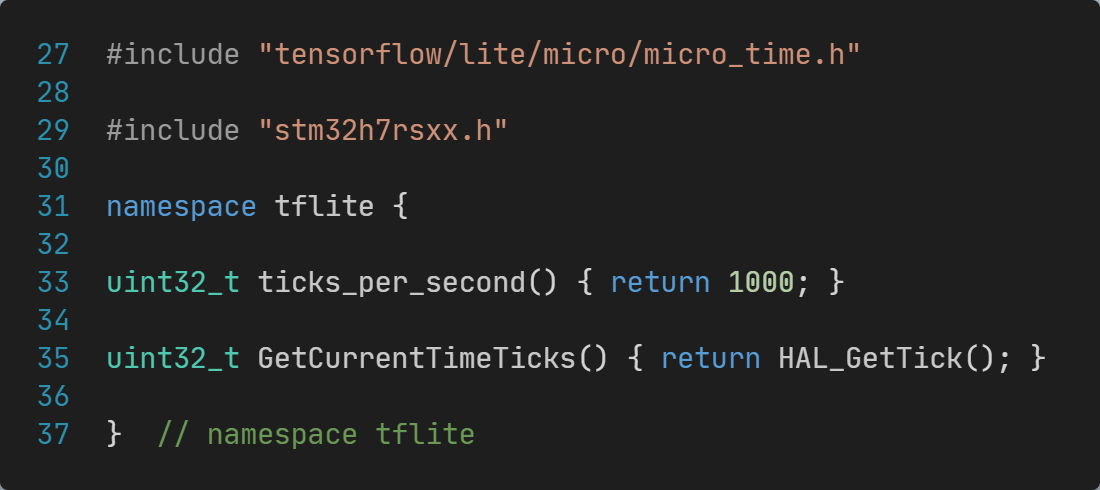
这里的ticks_per_second函数用于返回ticks频率,GetCurrentTimeTicks函数用于返回当前的ticks数;
3.3 构建micro_time.cc的规则
为了正确的构建micro_time.cc,需要将TFLM默认的micro_time.cc文件过滤掉,因此需要修改上一篇文章中我们实现的CMakeLists.txt代码,具体修改为:
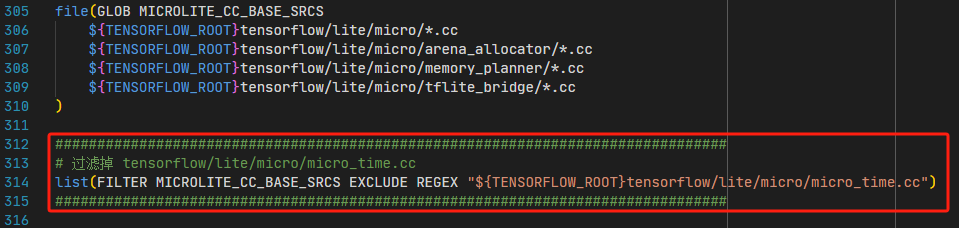
这里,默认的micro_time.cc由306行代码匹配上,314行实现了将其从MICROLITE_CC_BASE_SRCS中过滤掉。
3.4 添加TFLM构建规则
接下来修改顶层的CMakeLists.txt文件,在最后追加两行:
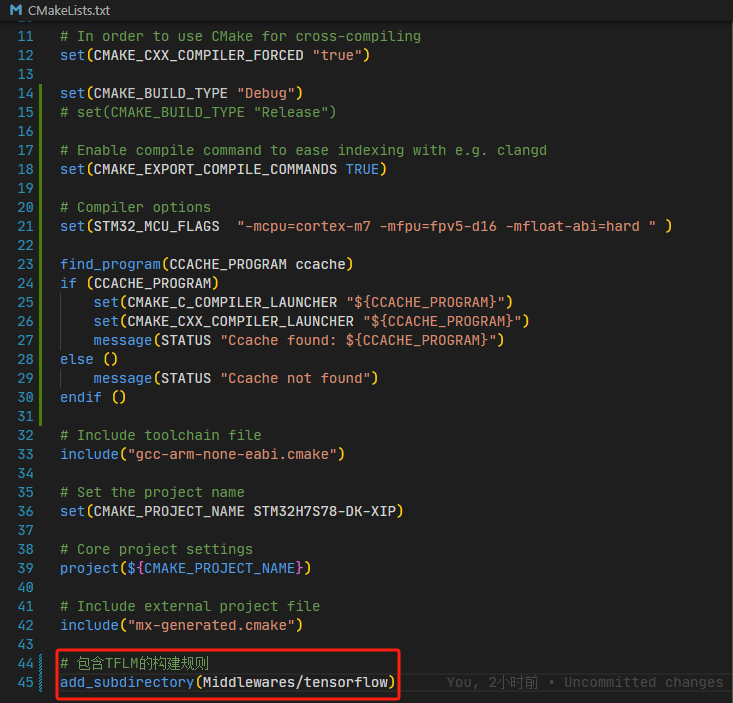
这样,就将TFLM的构建规则添加到了CubeMX生成的CMake项目中了。
3.5 添加TFLM函数调用
上篇文章中,我们实现的TFLM的CMakeLists.txt以及完成了对TFLM库和基准测试库的构建,并且最终会生成三个静态库:
- TFLM库,包含TFLM所有类和函数实现代码;
- keyword_benchmark 库,包含
keyword_benchmark函数实现代码; - person_detection_benchmark 库,包含
person_detection_benchmark函数实现代码;
接着,在我们的Appli子项目的代码中,添加对TFLM的调用。
由于C++函数支持参数重载,编译器生成C++函数会经过名称修饰。同样的函数声明代码,放在C++代码文件中和C代码文件中经过编译生成的二进制符号不同。这导致,在C代码中,我们无法通过声明函数或包含头文件的方式,直接调用C++函数;否则,链接时报告符号找不到。
因此,我们无法通过在Appli子项目的main.c中直接调用keyword_benchmark函数或者person_detection_benchmark函数的方式实现基准测试的集成。
为了解决C代码中不能直接调用C++函数的问题,我们需要引入一个中间层。这里需要用到几个C++相关的知识:
- 使用
extern "C"修饰C++函数,可以让编译器将该C++函数按照C函数的方式生成符号,不进行名称修饰; - C代码中可以调用由名称修饰的C++函数,就像调用其他C函数一样;
- C++有默认的内置宏,
__cplusplus用于只是当前C++编译器支持的语言标准版本,例如201103L表示C++11;
在Appli\Src目录中,创建tflm_benchmark.h文件,内容如下:

与之对应的tflm_benchmark.cc文件,内容为:
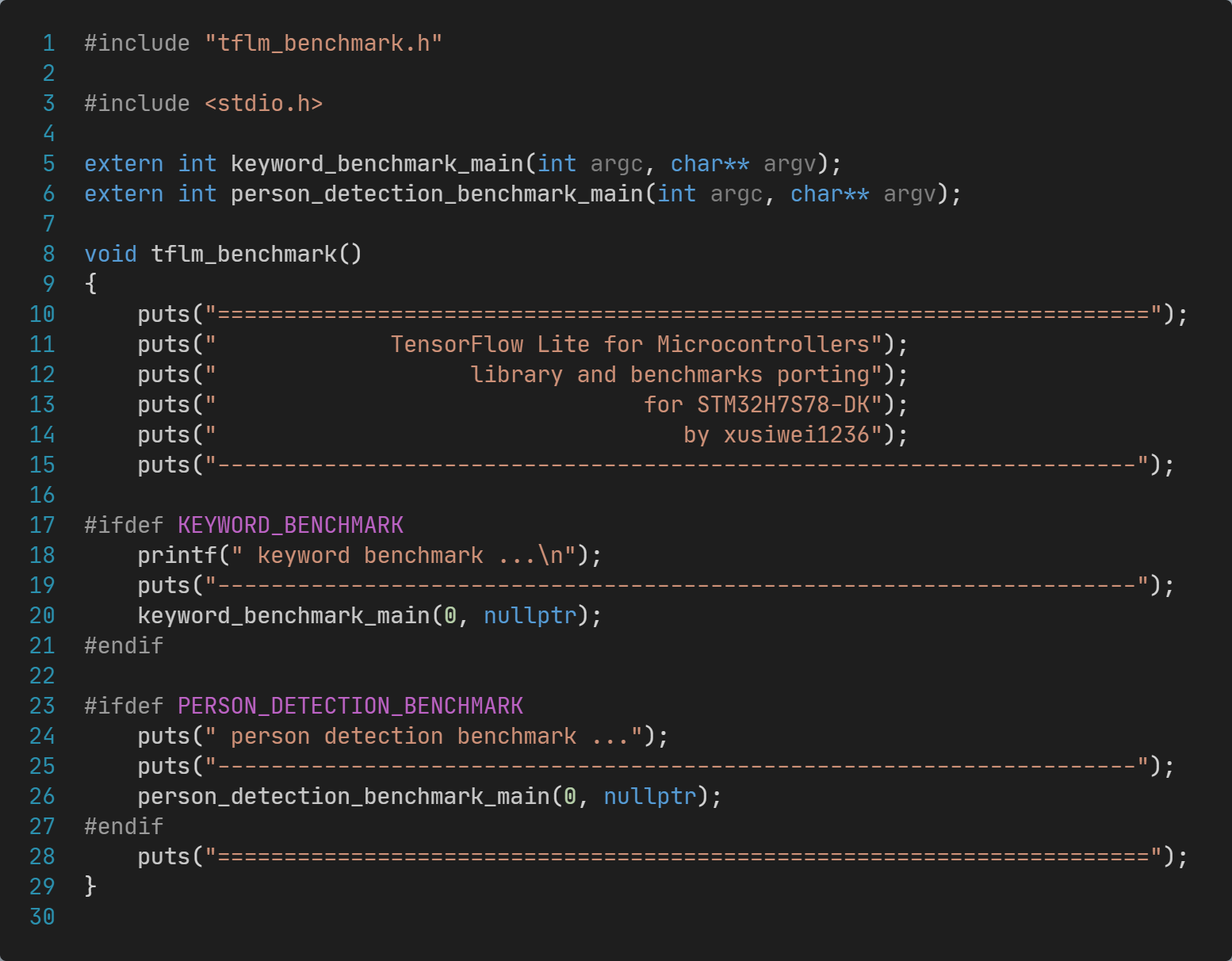
这里,通过KEYWORD_BENCHMARK和PERSON_DETECTION_BENCHMARK两个宏,实现两个基准测试的开关。
接下来就可以修改Appli子项目的main.c,调用这个tflm_benchmark函数了:
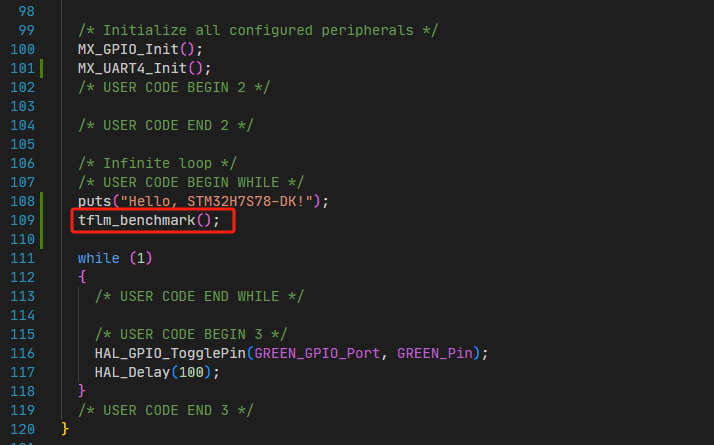
3.6 添加TFLM依赖关系
接下来,需要为我们的Appli添加对TFLM的依赖关系,包括对TFLM库和基准测试的依赖,具体修改的代码为:
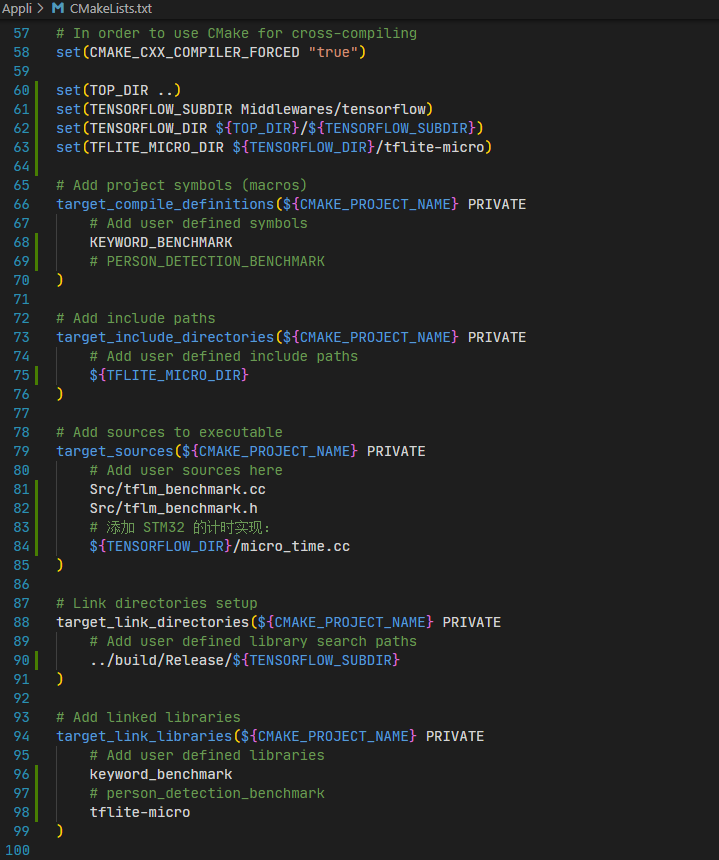
左侧行号标记绿色的即为新增代码行,一共六处,作用分别为:
- 60~64行,定义了几个CMake变量,后面会用到;
- 68~69行,为当前Appli子项目的构建目标,添加
KEYWORD_BENCHMARK(或PERSON_DETECTION_BENCHMARK)宏; - 75行,为当前Appli子项目的构建目标,添加头文件搜索目录;
- 81~84行,为当前Appli子项目的构建目标,添加三个源代码文件;
- 90行,为当前Appli子项目的构建目标,添加库文件搜索目录;
- 96~98行,为当前Appli子项目的构建目标,添加链接
keyword_benchmark(或person_detection_benchmark)库、tflite-micro库;
完成以上全部修改后,就完成了对TFLM库和基准测试的集成工作。
四、TFLM测试
好了,万事俱备,只欠东风!
完成前面的所有工作后,就可以准备在我们的STM32H7S78-DK上进行TFLM基准测试了。
4.1 编译TFLM和Appli项目
编译构建,主要使用VSCode的CMake插件工具栏,具体方法不再赘述,感兴趣的可以参考我之前发的帖子: 【STM32H7S78-DK评测】搭建基于ST官方VSCode扩展的STM32开发环境 - STM32团队 ST意法半导体中文论坛 (stmicroelectronics.cn)
编译之前,先清理一下项目:
接着,构建TFLM核心库:
继续,生成基准测试库keyword_benchmark:
以及基准测试库person_detection_benchmark:
紧接着,构建Appli项目:

构建完成后,可以看到RAM、Flash占用信息:
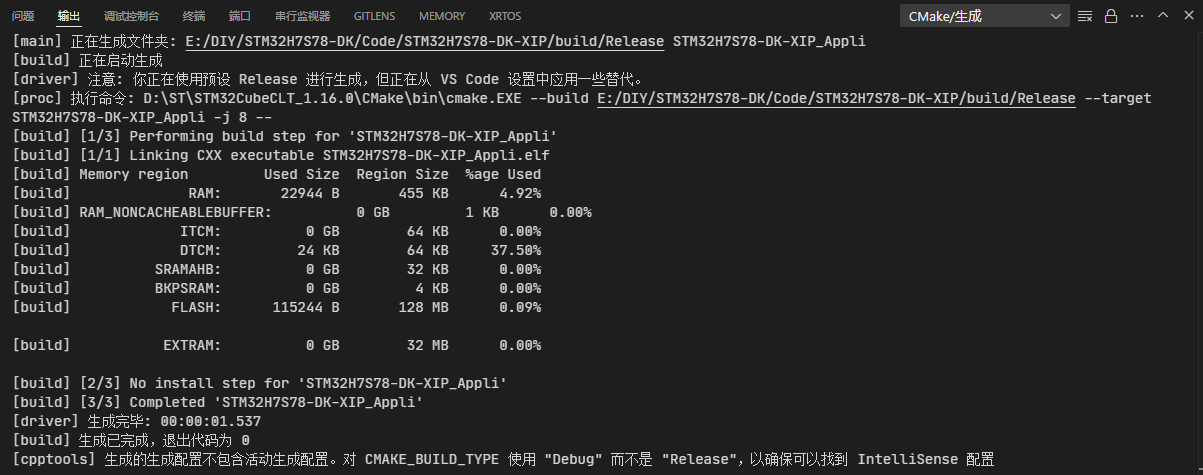
例如,图中的Flash占用为115244 B。
和Appli类似的方式,进行Boot子项目的构建,不再赘述。
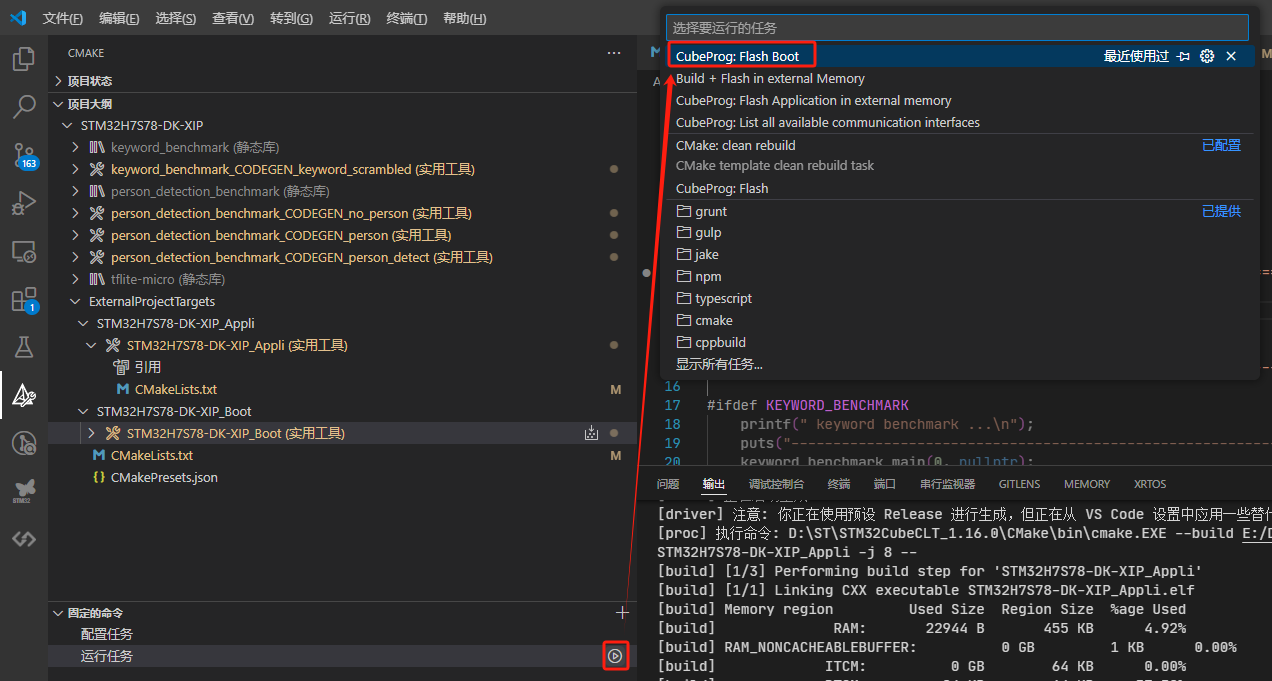
4.2 下载Boot代码
由于Appli代码需要使用Boot代码进行跳转,因此,下载Appli代码之前,需要线下载Boot代码到开发板上。
下载之前,先将STM32H7S78-DK开发板和PC通过USB线连接好,板子由三个USB口,注意连接到标有STLK的。
接着,VSCode上上操作:
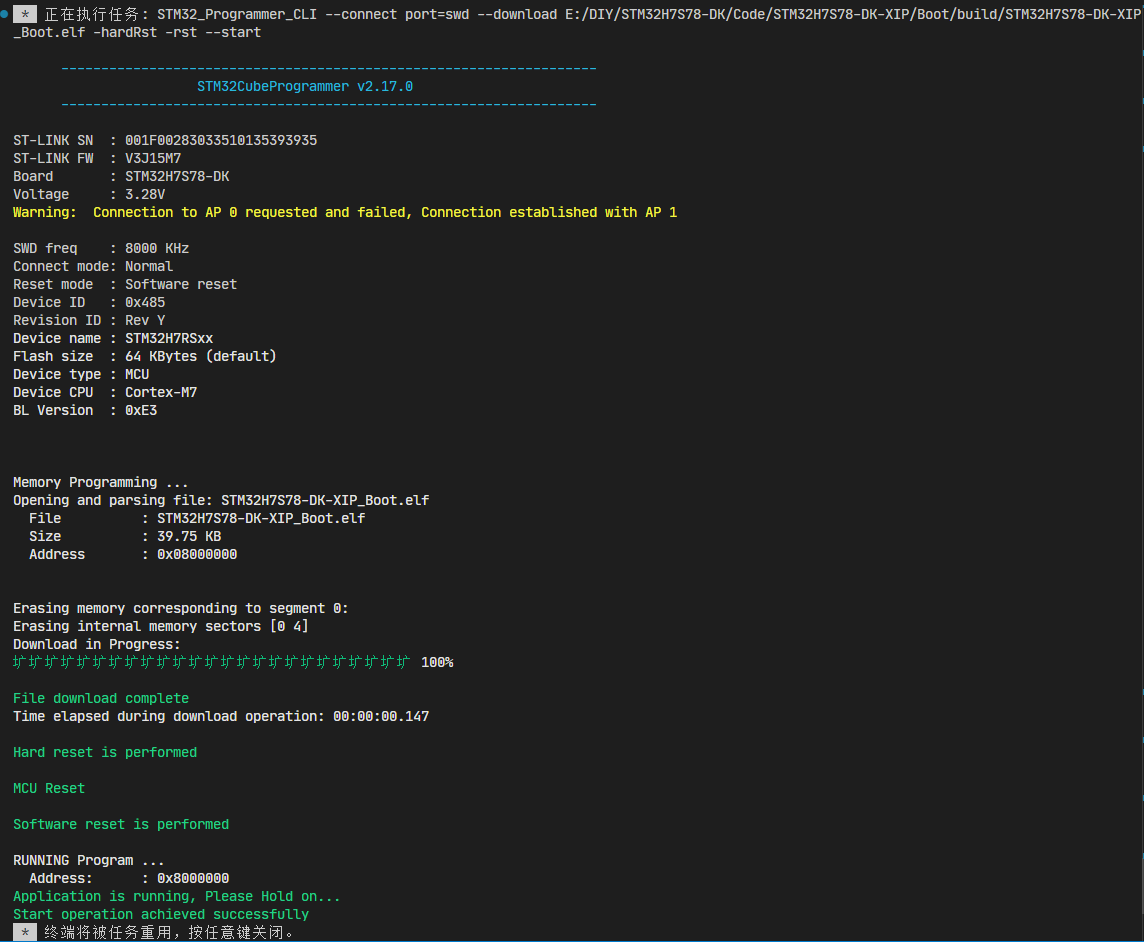
终端子窗口可以看到输出:
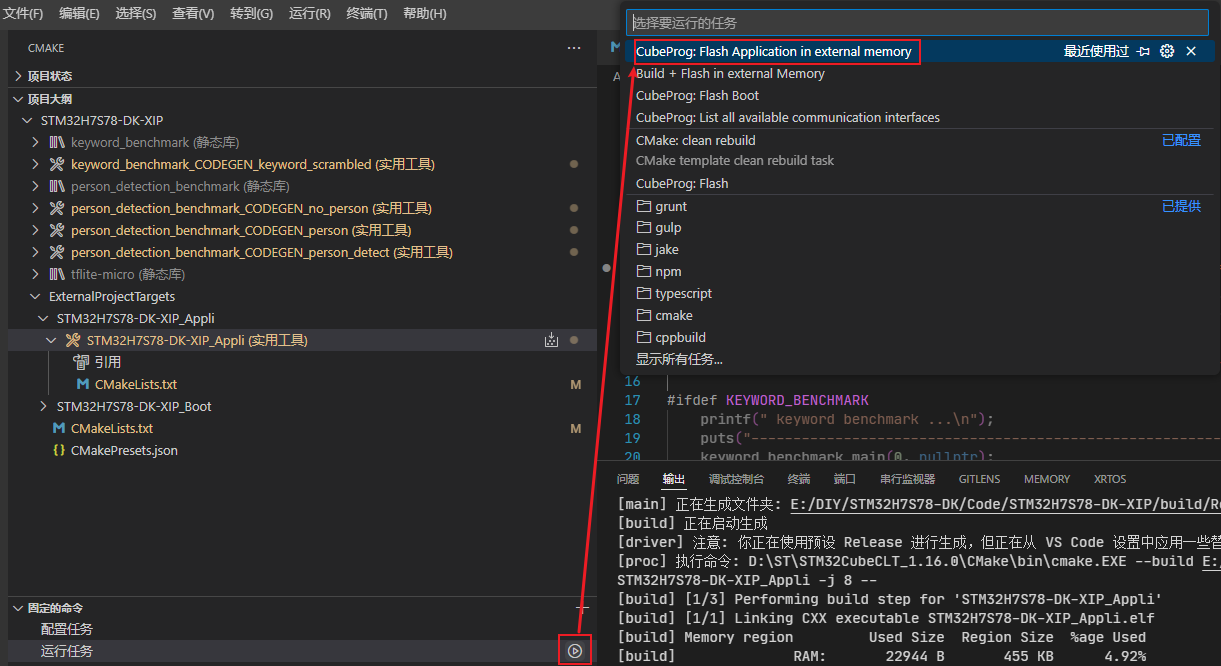
4.3 下载Appli代码
接下来,将我们的STM32H7S78-DK开发板和PC通过USB线连接好,板子由三个USB口,注意连接到标有STLK的。
然后,在VSCode上操作:
终端子窗口可以看到输出:
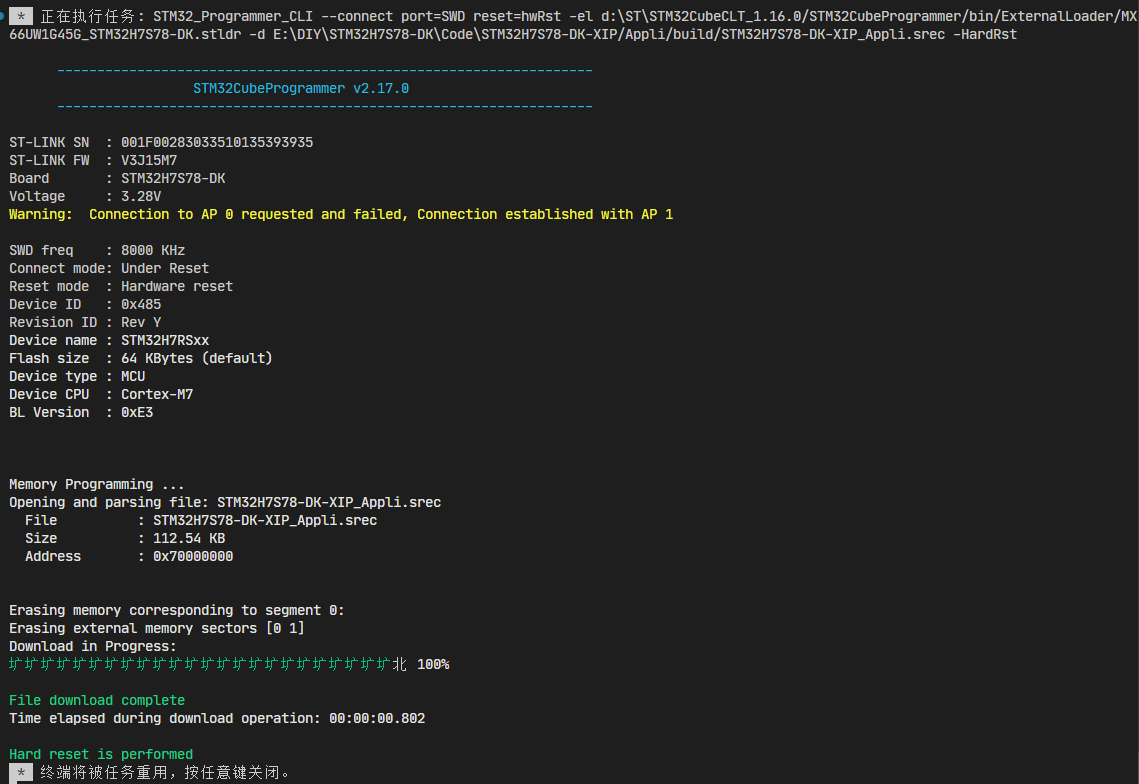
4.3 运行TFLM基准测试
打开MobaXterm,添加会话,选择STLink的虚拟串口设备,参数如下:
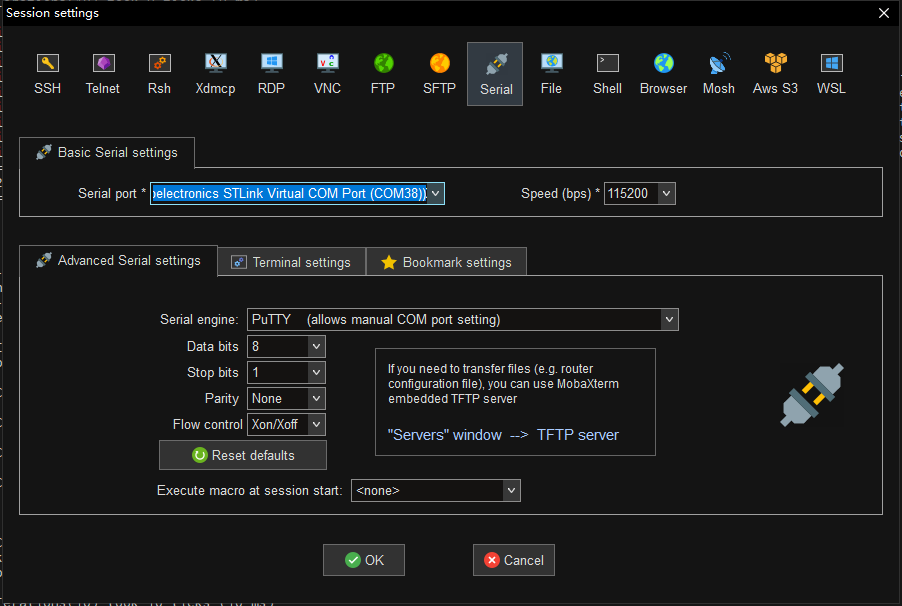
连接设备之后,按下开发板上的NRST按钮,重启设备,可以看到串口输出如下:
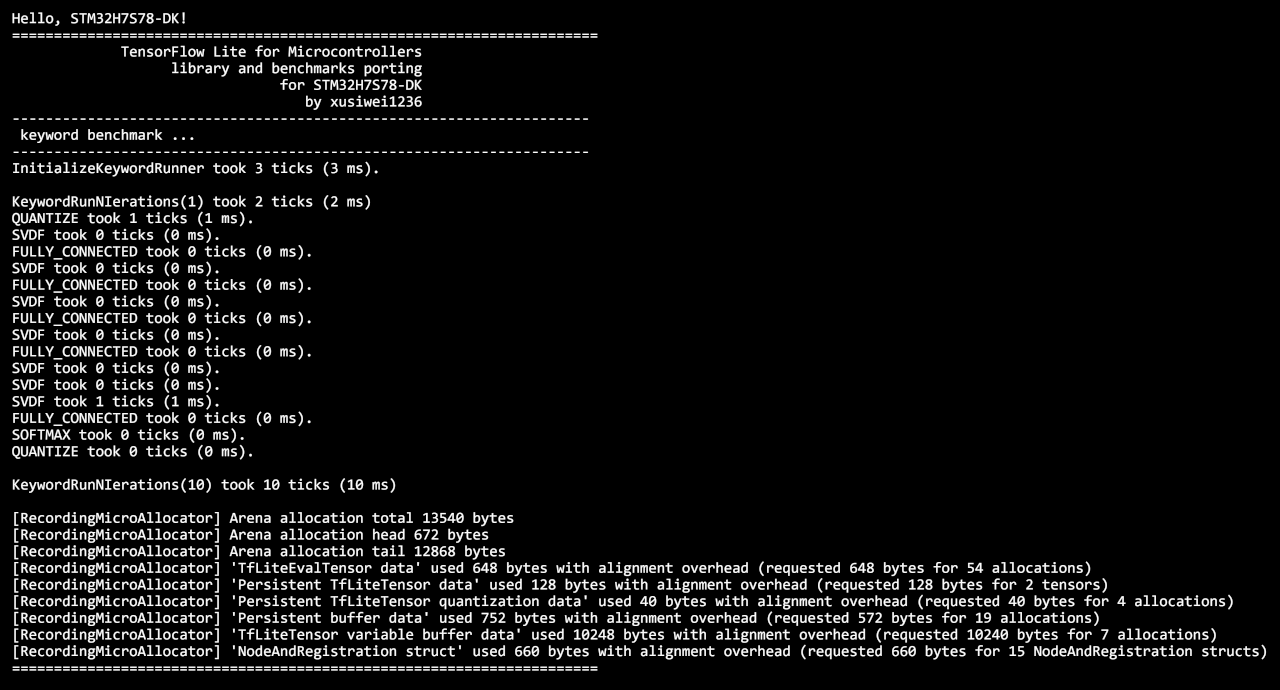
可以看到,keyword模型初始化耗时3毫秒,单独运行一次耗时2毫秒,连续运行10次耗时10毫秒,速度还是可以的。
与之对比的,在PC上运行keyword_benchmark的结果数据:
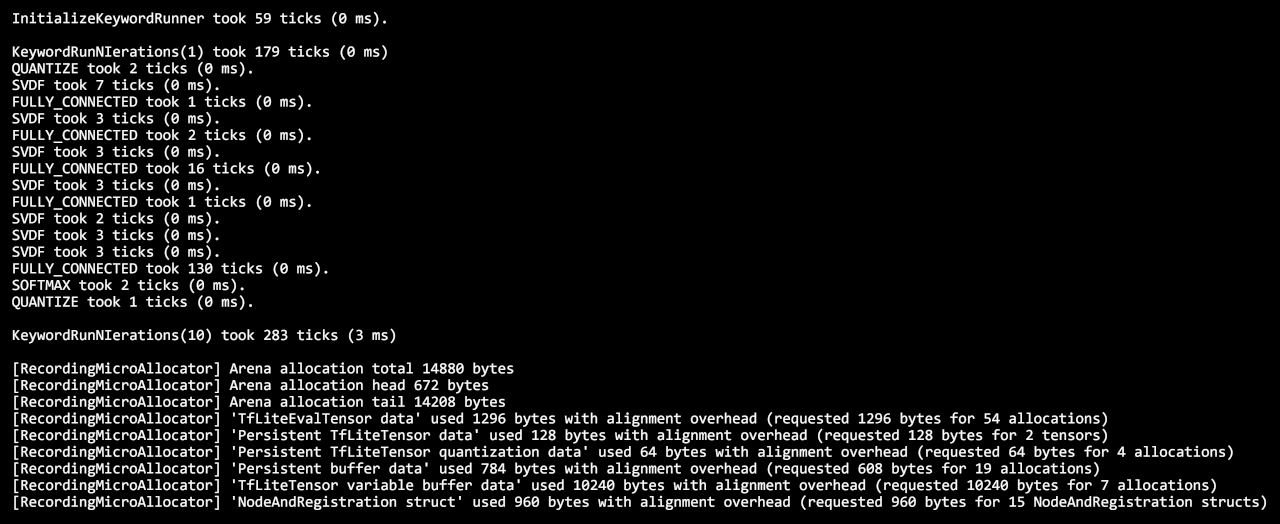
可以看到,PC上模型初始化和单独运行一次耗时都不到1毫秒,连续运行10次耗时3毫秒。
同样,稍加修改Appli\CMakeLists.txt,我们可以编译person_detection_benchmark,并得到在开发板上运行结果数据:
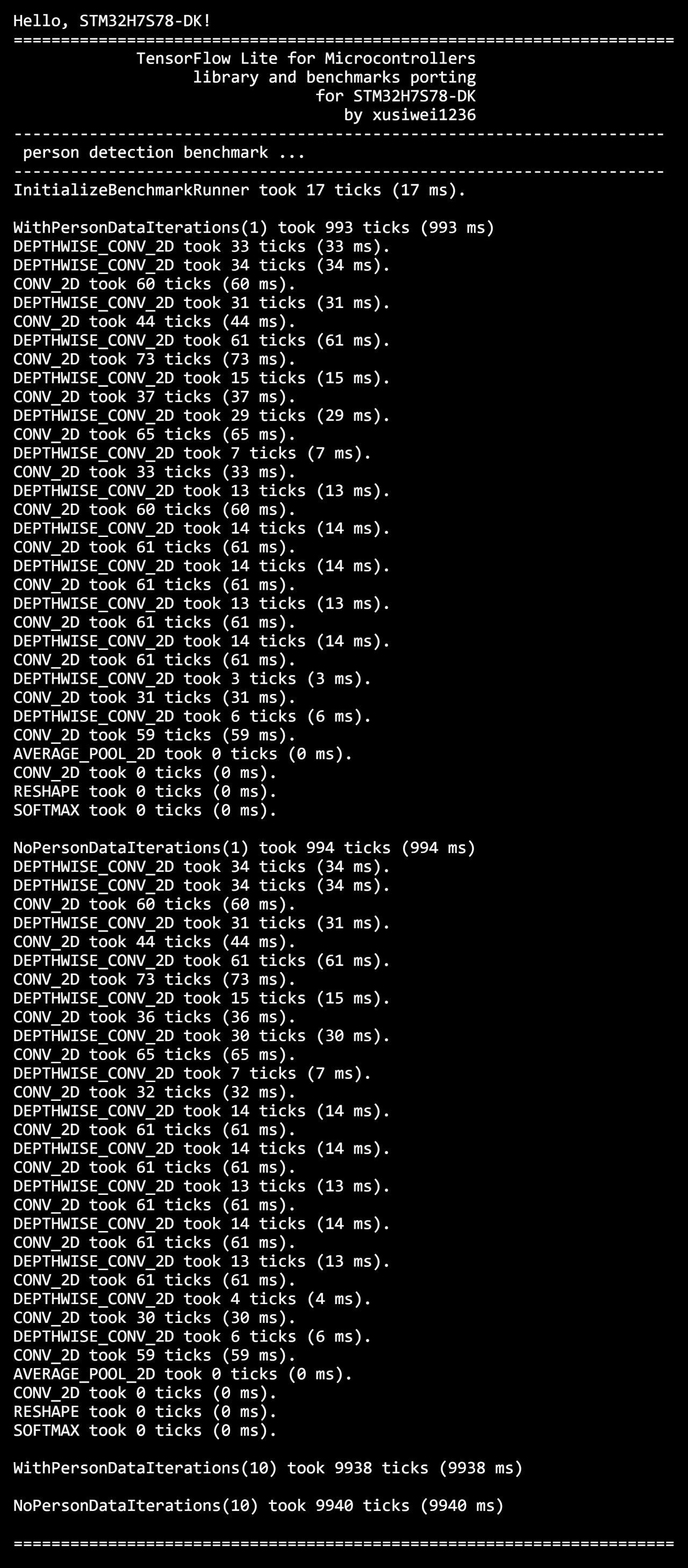
可以看到,开发板上,运行有人图像的人体检测耗时为993毫秒,没有人的耗时为994毫秒;连续运行10次的耗时分别为9938毫秒和9940毫秒,速度有点慢。
与之对应的,PC上运行person_detection_benchmark的结果数据为:
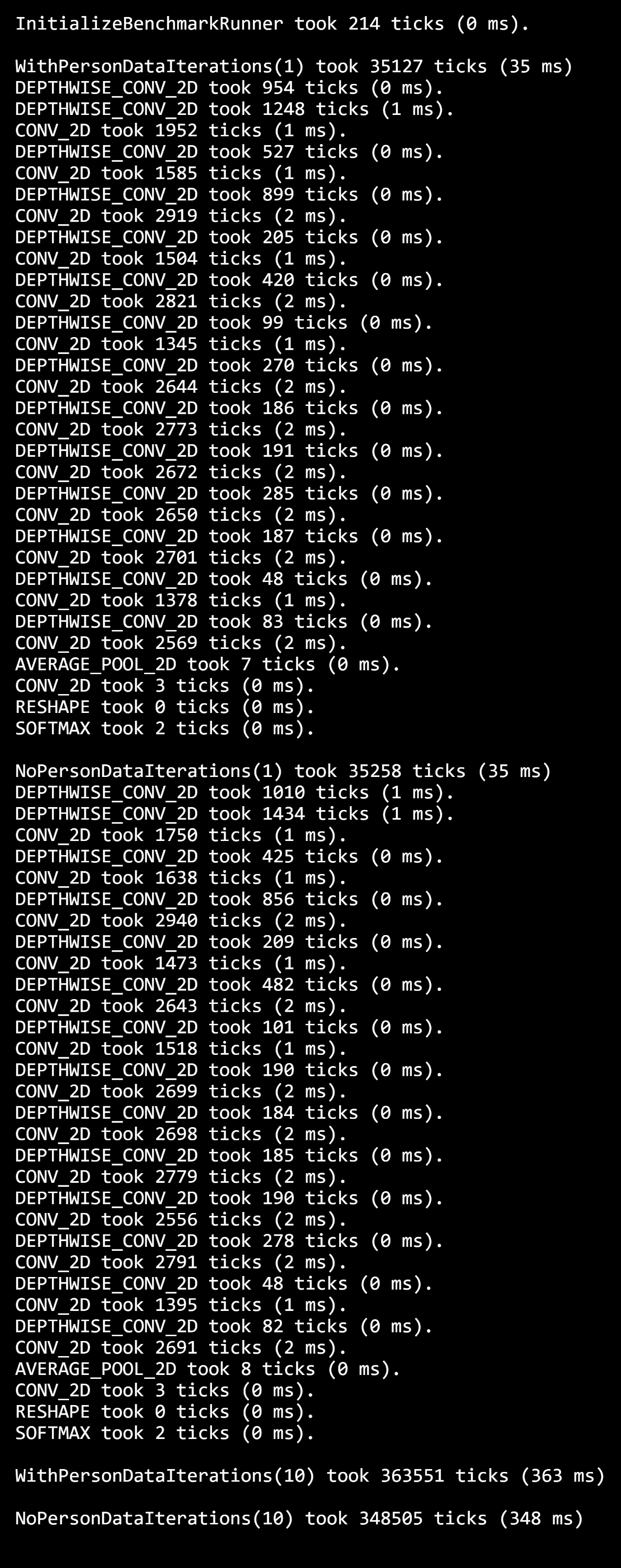
可以看到,PC上运行有人图像的人体检测耗时为36毫秒,没有人的耗时为35毫秒;连续运行10次的耗时分别为9938毫秒和9940毫秒,
五、问题解决
在前面的第三章、第四章的实践过程中,我遇到了一些问题,为了保持主体部分的简洁清晰,没有将问题描述和解决方法写在第三章、第四章内容中。本章将介绍预提遇到的问题,以及问题的解决方法,如果你在实践过程中遇到类似的问题,可以参考本章的方法进行解决。
5.1 benchmark编译失败
【问题现象】 编译失败,报错信息:

【问题原因】 直接原因是脚本生成代码中,数组和变量定义有问题(把路径带入进去了):

【解决方法】 修改代码生成脚本:
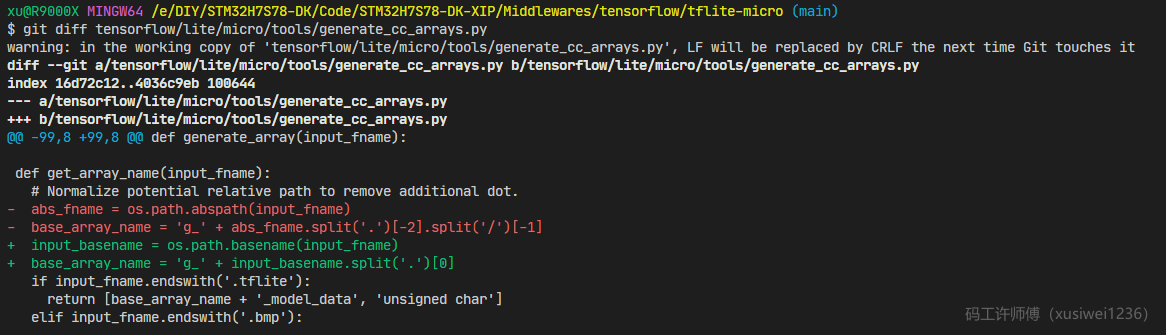
通过排查脚本生成代码,可以知道**【问题根因】**是Windows系统的路径分隔符不是/,.split('/')失败。
根据走读代码,可以知道代码中的base_array_name是文件名的基础部分,也就是去掉路径和扩展名;重新实现一下就好了。
5.2 Appli链接报错
【问题现象】 Appli链接失败,报错信息:
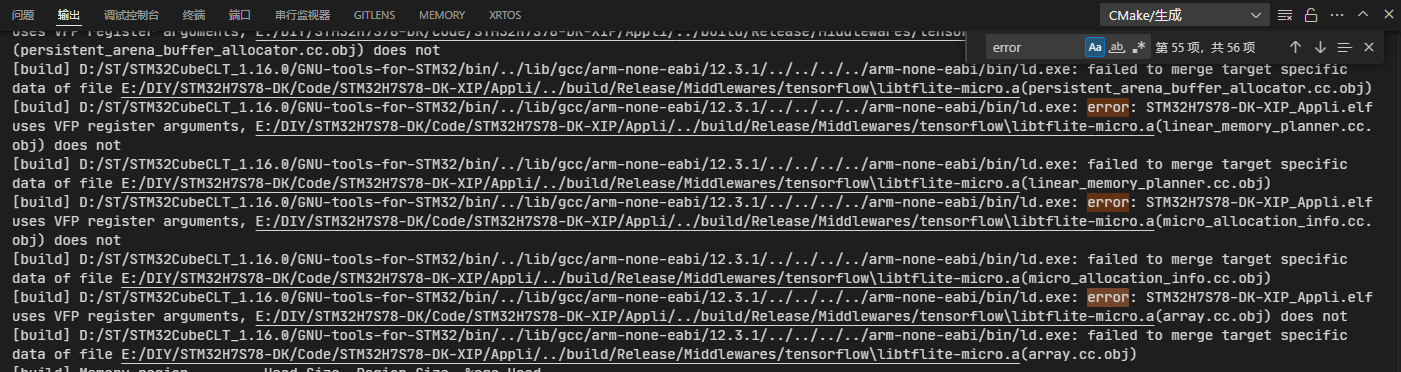
【问题原因】 Appli子项目使用了VFP寄存器参数(VFP register arguments),而libtflite-micro.a没有使用;
【解决方法】 顶层修改CMakeLists.txt,添加一行:

5.3 benchmark无法正常开始
【问题现象】 无法正常运行benchmark;
【初步调试】 运行到benchmark入口函数之后,无法进入tflite::InitializeTarget函数;
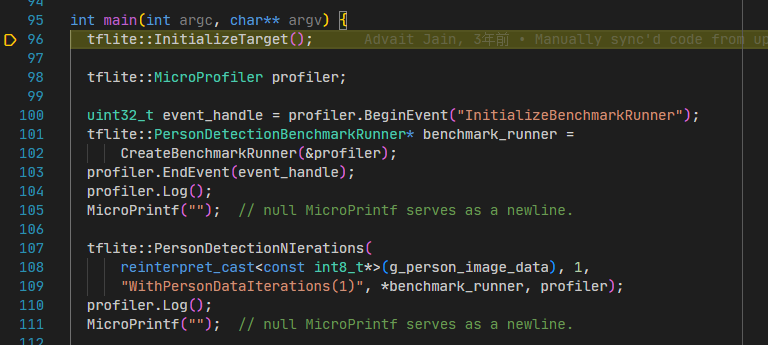
下一步直接进入HardFault_Handler;
【问题分析】 查看寄存器,发现栈指针位置异常:
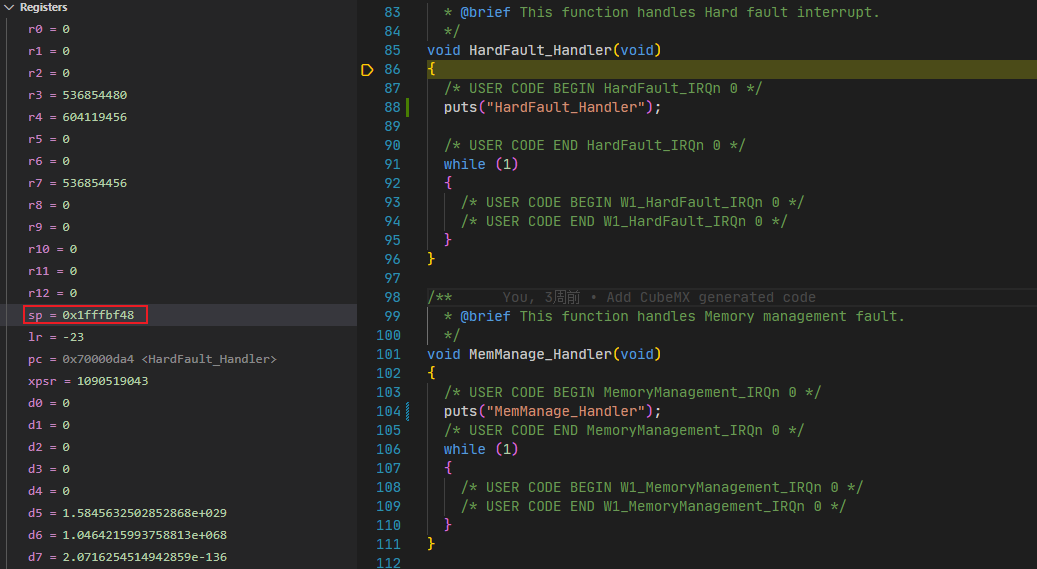
已经超出了链接脚本设置的栈范围:
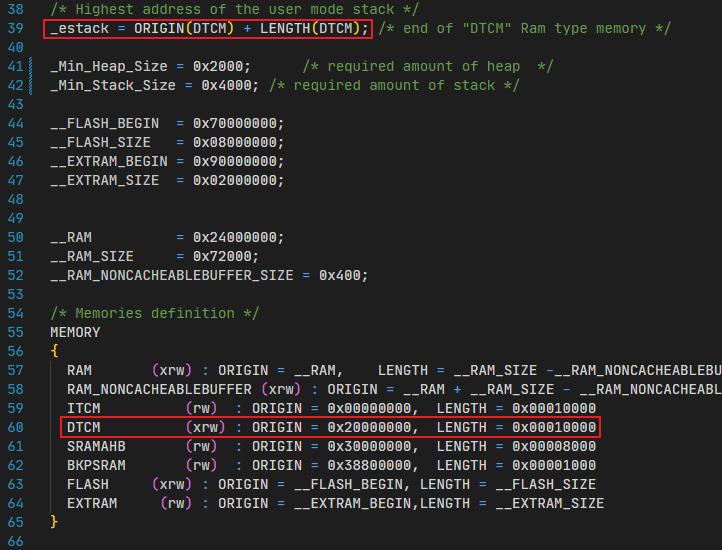
根据这段代码,可以知道正常的栈指针范围应该在[0x20000000, 0x20010000)的64K范围内。
【代码排查】 反汇编查看benchmark入口代码:
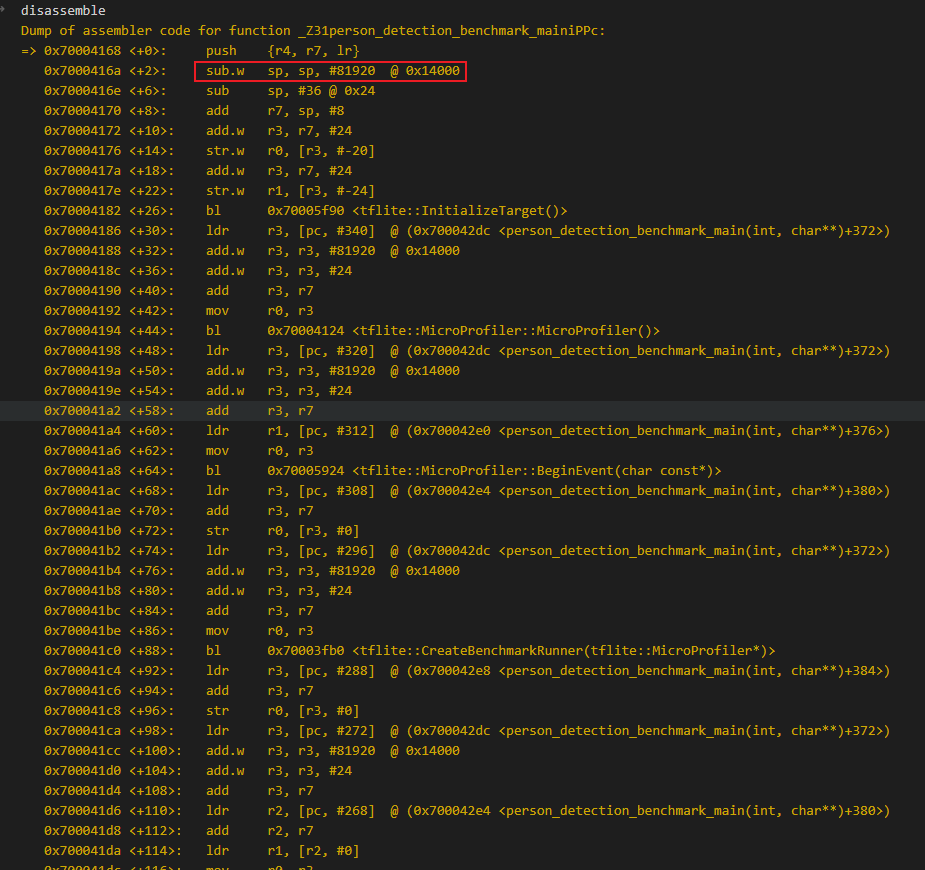
可以看到入口处申请的栈内存空间为81920(80K),超过链接脚本设置的64K栈空间,结合代码内容,可以知道是MicroProfiler对象占用的空间。
【解决方法】 修改MicroProfiler代码,具体修改如下:
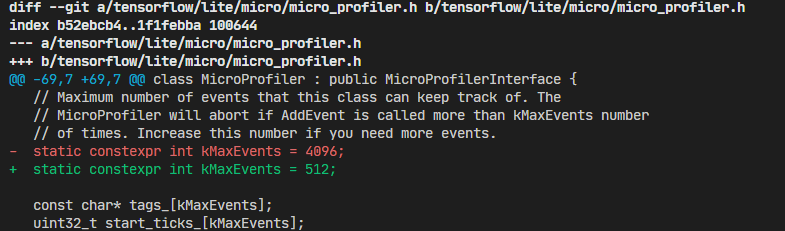
因为,这个常量是几个数组的大小:
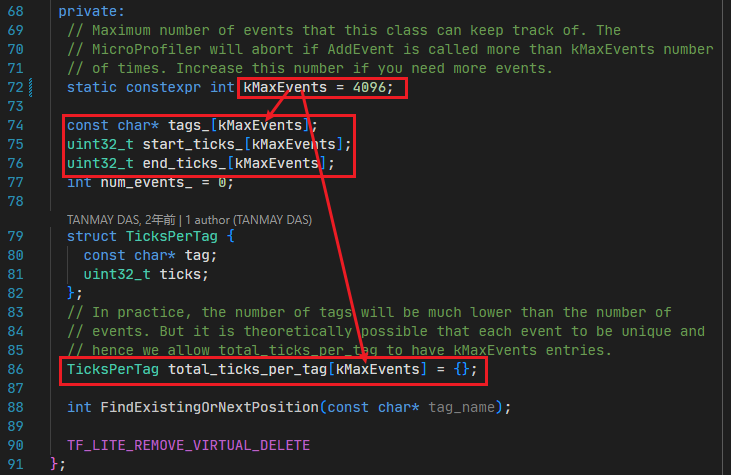
初步估算:5*4*4K正好是80K;
因此,把这个常量的值改小即可解决该问题。
5.4 Release版无法正常返回
【问题现象】 Debug版本可以正常运行,Release版benchmark函数无法正常返回到main函数;
【问题原因】 经过排查, 发现原因是benchmark函数写了返回值类型int,但没有写return语句;
【解决方法】 修改代码,benchmark函数最后添加一行return 0;语句即可;
六、源码分享
本项目的所有代码已经开源到GitCode平台,感兴趣的小伙伴可以免费下载体验: https://gitcode.com/xusiwei1236/STM32H7S78-DK-TFLM.git
本代码仓使用了git submodule特性,需要用--recursive选项进行克隆:
git clone --recursive https://gitcode.com/xusiwei1236/STM32H7S78-DK-TFLM.git
另外,tflite-micro依赖的一些三方软件已经打包到了如下仓库:
https://gitcode.com/tflm/downloads.git
下载方法:
# 跳转到 tflite-micro 子目录
cd Middlewares/tensorflow/tflite-micro
# 下载 downloads 下的三方软件源码
git clone https://gitcode.com/tflm/downloads.git tensorflow/lite/micro/tools/make/downloads/
七、参考链接
- CCache下载页面: Ccache — Download
- CMake中使用CCache: Use Ccache with CMake | Lindevs
- 官方STM32CubeH7RS软件包的XIP项目模板: Template_XIP
- TensorFlow Lite for Microcontrollers介绍: TensorFlow Lite for Microcontrollers (google.cn)
- TensorFlow Lite for Microcontrollers入门: 微控制器入门 | TensorFlow (google.cn)
- tflite-micro 源码GitHub仓: https://github.com/tensorflow/tflite-micro
- CMake最新文档: CMake Reference Documentation — CMake 3.30.3 Documentation



















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











