






想想学习CUDA的时间也应该有十来天了,也该是做一个小总结了,说说我理解的CUDA,它到底是什么东西?
其实说到CUDA,还真的没几个人知道,说实话,我也听说不久,主要因为它2007年才刚发布,也是这几年才刚兴起,国内那就更慢了。
CUDA它中文的名字是统一计算设备架构,CUDA是一种将GPU作为数据并行计算设备,听到并行这个名称,我相信很多热爱计算机的朋友就特别兴奋,因为这意味着速度会很快,确实,CUDA就是为了提高计算速度的一个计算机架构。
要理解CUDA,就先理解一个基本概念:GPU是图形处理单元 (Graphic Processing Unit) 的简称,最初主要用于图形渲染。 由于GPU 拥有比CPU 更强的计算能力,很早就有人想到将GPU 应用到通用计算上,这就是GPGPU,所谓GPGPU 是指直接使用了图形学的API,将任务映射成纹理的渲染过程,使用汇编或者高级着色器语言Cg,HLSL 等编写程序,然后通过图形学API 执行(Direct3D和OpenGL),这样的开发不仅难度较大,而且难以优化,对开发人员的要求非常高,因此,传统的GPGPU 计算并没有广泛应用。 2007 年6 月,NVIDIA 公司推出了CUDA (Compute Unified Device Architecture) , CUDA 不需要借助图形学API,而是采用了类C 语言(CUDA C)进行开发。
由于CUDA使用的是类C语言(CUDA C)语言开发,因此对于对C语言有所理解的程序员都可以开发,因此它得到很大的广泛应用。
其实CUDA有很多用途,因为它有并行计算的能力,因此只要有并行计算的地方就可以用它,就像在OpenGL或者是D3D中都可以用CUDA来进行计算的加速,众所周知,在图形学中很多操作都是用矩阵来进行运算,所以在OpenGL中就可以加入CUDA的架构,其实CUDA两个是独立的架构,用CUDA只是用来并行运算,当把数据处理完了之后就要返回到OpenGL中进行渲染,当然CUDA的用途不仅如此,它还有更高级的用途。
 今天我就来讲讲有关于CUDA的编程模型:
今天我就来讲讲有关于CUDA的编程模型:
1.主机和设备
CUDA 编程模型将CPU作为主机(Host),GPU作为协处理器或者设备(Device),在一个系统中可以存在一个主机和若干个设备。
在这个模型中,CPU与CPU协同工作,各司其职。CPU负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
一旦确定了程序的并行部分,就可以考虑把这部分计算工作交给GPU。
能够使用GPU计算的程序必须具有以下特点:需要处理的数据量比较大,数据以数组或矩阵形式有序存储,并且对这些数据要进行的处理方式基本相同,各个数据之间的依赖性或者说耦合很小,需要复杂数据结构的计算如树,图等,则不适用于使用GPU进行计算。找到程序中满足这些要求的部分后,就能将该部分程序移植GPU上。运行在GPU上的程序被称为内核(Kernel)。内核并不是完整的程序,只是整个程序中的一个可以使用数据并行处理的步骤。一个完整的程序由若干个内核函数以及CPU上的串行处理共同组成。一个完整的程序的计算流程如下所示:

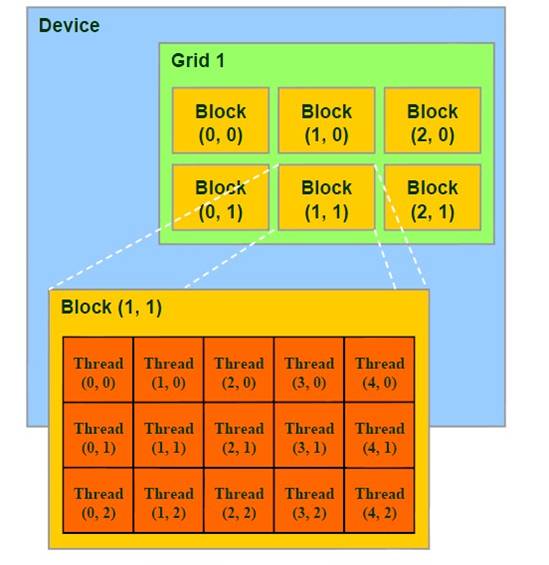
2. 线程结构
内核以线程网格(Grid)的形式组织,每个线程网格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。实质上,内核(kernel)是以block为单位执行的,CUDA引入grid只是用来表示一系列可以被并行执行的block的集合,各block的集合。各block是并行执行的,block间无法通信,也没有执行顺序。
目前一个内核(kernel)函数中只有一个grid,而未来的支持DX11的硬件采用MIMD(多指令多数据)结构,允许一个kernel中存在多个不同的grid。(目前是使用SIMT(单指令多线程)。
为简便起见,threadIdx是一个有3个组件的向量,所以线程可以使用一维,二维,三维索引标识,形成一维,二维,三维的线程块。这提供了一种自然的方式来调用作用在域内元素上的计算,如向量,矩阵,体元(volume)(译者注:目前还没见过使用三维的,原因可能在于网格不支持三维)。
线程索引和线程ID直接相关:对于一维的块,它们相同;对于二维长度为(Dx,Dy)的块,线程索引为(x,y)的线程ID是(x+yDx);对于三维长度为(Dx,Dy,Dz)的块,索引为(x,y,z)的线程ID为(x+yDx+zDxDy)
实例代码:
- // Kernel definition
- __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){
- int i = threadIdx.x;
- int j = threadIdx.y;
- C[i][j] = A[i][j] + B[i][j];
- }
- //host code
- int main() {
- ...
- // Kernel invocation with one block of N * N * 1 threads
- int numBlocks = 1;
- dim3 threadsPerBlock(N, N);
- MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
- }
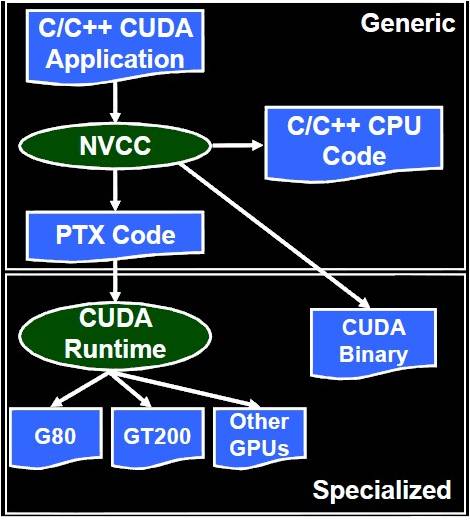
今天我讲讲CUDA所用到的编译器nvcc:
—nvcc编译器根据配置编译CUDA C代码,可以生成三种不同的输出:PTX、CUDA二进制序列和标准C。
一.纹理存储器介绍
纹理存储器(texture memory)是一种只读存储器,由GPU用于纹理渲染的的图形专用单元发展而来,因此也提供了一些特殊功能。纹理存储器中的数据位于显存,但可以通过纹理缓存加速读取。在纹理存储器中可以绑定的数据比在常量存储器可以声明的64K大很多,并且支持一维、二维或者三维纹理。在通用计算中,纹理存储器十分适合用于实现图像处理或查找表,并且对数据量较大时的随机数据访问或者非对齐访问也有良好的加速效果
纹理缓存有两个作用。首先,纹理缓存中的数据可以被重复利用,当一次访问需要的数据已经存在于纹理缓存中时,就可以避免对显存进行读取。数据重用过滤了一部分对显存的访问,节约了带宽,也不必按照显存对齐的要求读取。第二,纹理缓存可以缓存拾取坐标附近几个像元的数据,可以实现滤波模式,也能提高具有一定局部性的访问的效率。
纹理存储器是只读的,不需要关心缓存数据一致性问题。这意味着如果更改了绑定到纹理存储器的数据,纹理缓存中的数据可能并没有被更新,此时通过纹理拾取得到的数据可能是错误的。因此,在每次修改了绑定到纹理的数据以后,都需要对纹理进行重新绑定。由于不能从设备端修改CUDA数组,因此只有在对绑定到纹理的线性内存进行修改时才需要注意这一点。
二.纹理存储器的使用步骤:
1. 声明CUDA数组,分配空间
声明CUDA数组之前,必须先以结构体channelDesc描述CUDA数组中的数据类型。
struct cudaChannelFormatDesc {
int x, y, z, w;
enum cudaChannelFormatKind f;
};
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat);
cudaArray* cu_array;
cutilSafeCall( cudaMallocArray( &cu_array, &channelDesc, width, height )); //为cu_array开辟空间
cutilSafeCall( cudaMemcpyToArray( cu_array, 0, 0, h_data, size, cudaMemcpyHostToDevice)); //复制到设备端的数组
2. 声明纹理参照系
// declare texture reference for 2D float texture 声明纹理参照系
texture<float, 2, cudaReadModeElementType> tex;
3. 设置运行时纹理参照系属性
tex.addressMode[0] = cudaAddressModeWrap; //采用循环模式
tex.addressMode[1] = cudaAddressModeWrap; //说明寻址模式
tex.filterMode = cudaFilterModeLinear; //设置纹理的滤泼模式
tex.normalized = true; // access with normalized texture coordinates设置是否对纹理坐标进行归一化
4. 纹理绑定
// Bind the array to the texture //纹理绑定
cutilSafeCall( cudaBindTextureToArray( tex, cu_array, channelDesc));
5. 纹理拾取
g_odata[y*width + x] = tex2D(tex, tu, tv); //纹理拾取
http://blog.csdn.net/augusdi/article/details/12439805















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









