







1024 我要水一篇 立个flag 更爱IT吗?
感觉兜兜转转又回到了光流,研一 一入学看的第一篇论文就是光流,当时肯定看不懂呀,然后就搁置了,然后又回到了这里,哑巴吃黄连。。。。。
Definition:
最近查阅了一些光流的资料。首先什么是光流,光流可以做啥,最后光流怎么用呢?看了维基百科,链接如下:optical flow is the pattern of apparent of objects,surface,and edges in a visual scene caused by the relative motion between an observer and a scene
光流概念最早是由美国心理学家提出的,哈哈想不到吧(最近还学习了跨界思维,有点意思)互通原理,有个经典的句子:We see because we move;we move because we see
首先这个名字很形象了,流,想象一下:你有一双大大的亮亮的眼睛(当然得有光),你可以看到世界万物,如走过的人,路过的风景,飞过的车等等,没有绝对静止的物体,正因为有了运动,才让世界变得很美好(change???),总之,就是嗖的一下或者龟速一般从你的眼前穿过(大白话理解)。官方理解如下:它是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
Traditional methods:
光流老远之前的传统方法,例如HS算法,LK算法,TV-L1算法等,
有亮度恒定约束,移动的范围小约束,最后推导出一个公式,得到了Vx 和Vy就是那个像素的光流(是一个矢量,代表方向和大小),如下(4):

u=dx/dt v=dy/dt
但是一个方程两个未知数是解不了的(这被称为光流算法的孔径问题aperture problem)那怎么办呢?加一些其他的约束呗。
一、1981年的HS算法,引入全局平滑约束,计算稠密光流,利用变分方法(泛函的极值问题),正则化方法(Dirichlet泛函,就是第一项)进行求解:
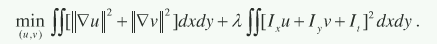
第一项是一个先验:Arguably the simplest prior is to favor small first-order derivatives (gradients) of the flow field.
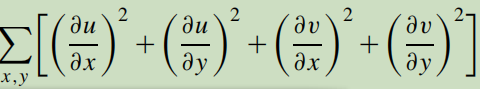
第二项就是光流的约束条件。
还可以写成如下:

Equation (3) is suitable if the image data is continuous in time. Typically, this equation is replaced by the non-linear formulation:

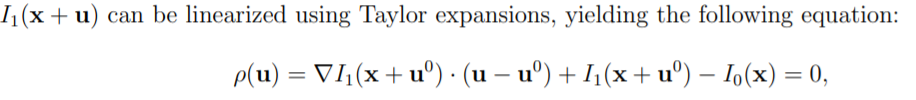

然后用欧拉-拉格朗日方程求解:
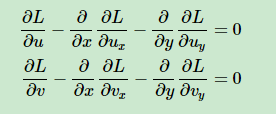
这里涉及到拉普拉斯算子,定义为:
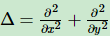
用到邻域的均值,然后进行迭代更新。
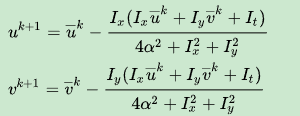
至于代码嘛,OpenCv的API是 CalcOpticalFlowHS,相关论文是《Determining Optical Flow》
具体参考 维基百科HS-method或者一个中文的博士学位论文 特别特别长,不过写的真是详细,专业
二、LK算法引入的约束为空间一致性(即相邻像素点运动相似),计算稀疏光流,使用3*3的一块区域,它假定这9个点有相同的运动,所以现在的问题变为有9个等式,2个未知量,这个问题当然能够解决。一个好的解决方式是使用最小二乘法。参考维基百科。
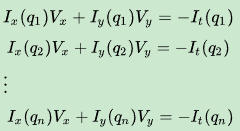
然后写成向量形式,求解。
代码如下:OpenCV写的
三、1992年的提出基于TV的《Nonlinear Total Variation Based Noise Removal Algorithms》,进行图像的去噪。
2013年的TV-L1(Total variation norm—L1 norm)《TV-L1 Optical Flow Estimation》计算稠密光流
高大上的话用起来:正则化TV泛函是全变差、而不是常见的二次型,取变分后导致的偏微分方程是非线性的。用绝对值变差代替惯用的Dirichlet泛函,很像统计学中用绝对误差代替平方误差所起到的鲁棒化作用。(This method is based on the minimization of a functional containning a data term using the L1 norm and a regularization term using the total variation of the flow.) more robust to noise than HS
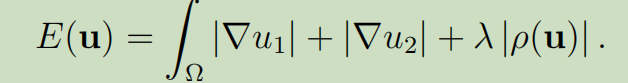
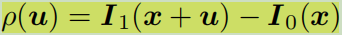
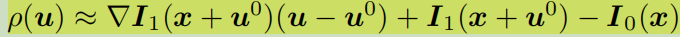
看到这个式子就是差分思想了吧,两帧之间的变化
我觉得与HS算法相比只是把正则化二范改为一范。
参考泛函与变分初步
参考全变分(TV))
全变分模型(TV)图像去噪[学习笔记]
啥是TV-L1 OpticalFlow
以上都是针对于小位移假设,那对于大位移问题呢,使用了金字塔算法 OpenCv的API是: (LK算法的) calcOpticalFlowPyrLK 金字塔LK论文
都是纯数学公式,泰勒公式,欧拉-拉格朗日(Euler-Lagrange),吉洪诺夫正则化(Tikhonov regularization),解耦理论(即经过某个状态和输入的变换之后,每个输出只依赖一个相应的输入,而不依赖于其他输入),狄里克莱函数(Dirichlet function),泛函,雅克比方法,矩阵分裂,一范式和二范式,,,,,,头疼了吧
小结:
传统的计算光流的方法先读取视频(一般用cv2.VideoCapture() or skvideo.io.vread() ),得到许多帧,长度一样的RGB图片,( 如果不是视频,是连续的帧的话,直接读取图片,使用cv2.imread())然后把它转为灰度图(用cv2.cvColor(image,cv2.COLOR_RGB2GRAY)),最后用(TV-L1或其他方法都可以,大部分都在OpenCV集成了,不得不说现在什么都想好了,你只要会用就可以),以下是参考代码(python):
import os
import numpy as np
import cv2
from glob import glob
from PIL import Image
import imageio
def cal_for_frames(video_path): #读取图片并计算光流,染后保存下来
frames = glob(os.path.join(video_path, '*.jpg'))
frames.sort()
flow = []
prev = imageio.imread(frames[0]) #是uint型的Array
prev = cv2.cvtColor(prev, cv2.COLOR_BGR2GRAY)
for i, frame_curr in enumerate(frames[1:]):
curr = imageio.imread(frame_curr)
curr = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
tmp_flow = compute_TVL1(prev, curr)
flow.append(tmp_flow)
prev = curr
print('complete:' + str(i))
return flow
def compute_TVL1(prev, curr, bound=15):
"""Compute the TV-L1 optical flow."""
TVL1 = cv2.createOptFlow_DualTVL1() ## 得到 <DualTVL1OpticalFlow 0x7fe8247ce130>
flow = TVL1.calc(prev, curr, None) ##得到两通道的流
print(flow.dtype)
return flow
def ToImg(raw_flow,bound):
'''
this function scale the input pixels to 0-255 with bi-bound
:param raw_flow: input raw pixel value (not in 0-255)
:param bound: upper and lower bound (-bound, bound)
:return: pixel value scale from 0 to 255
'''
flow=raw_flow
flow[flow>bound]=bound
flow[flow<-bound]=-bound
flow-=-bound
flow*=(255/float(2*bound))
flow=flow.astype(np.uint8)
return flow
def save_flow(video_flows, flow_path):
for i, flow in enumerate(video_flows):
flow_x = ToImg(flow[..., 0], 15)
flow_y = ToImg(flow[..., 1], 15)
flow_x_img = Image.fromarray(flow_x)
flow_y_img = Image.fromarray(flow_y)
imageio.imwrite(os.path.join(flow_path,'flow_x_{:05d}.jpg'.format(i)),
flow_x_img)
imageio.imwrite(os.path.join(flow_path,'flow_y_{:05d}.jpg'.format(i)),
flow_y_img)
def extract_flow(video_path, flow_path):
flow = cal_for_frames(video_path)
save_flow(flow, flow_path)
print('complete:' + flow_path)
return
if __name__ == '__main__':
video_paths = "/home/hongyuan/data/test_data/OTB50/Deer/img" #要提取视频帧的路径,最简单的
flow_paths = "/home/hongyuan/projects/wenmei/flow/" #保存流的路径
extract_flow(video_paths, flow_paths)
把得到的光流保存下来,一般为flow_x,flow_y,正好是两个通道,当然在保存之前会将光流 rescale to 0~255 with the bound setting
最最最要的一点是:在计算光流之前转为灰度图,要不 然报错,还有弄清楚cv2中的RGB2GRAY/BGR2GRAY,被折腾死,报错内容如下:
OpenCV(3.4.2) /io/opencv/modules/video/src/tvl1flow.cpp:416: error: (-215:Assertion failed) I0.type() == (((0) & ((1 << 3) - 1)) + (((1)-1) << 3)) || I0.type() == (((5) & ((1 << 3) - 1)) + (((1)-1) << 3))

这是其中的一张图,放大后可以看到几个亮点,一张图片看不出流的变化,多张图就可以看到喽。如果有人想要试试传统的光流算法,可以直接在git上搜dense_flow,第一个就是我师兄推荐的(用C++和matlab语言写的,自己太菜了,也没有看),也有python写的,我就是看的python ,或者谷歌百度一下dense_flow有很多讲解
得到的是两个通道的光流,那如果我们想要三个通道的呢?
只需把以上函数 save_flow()修改一下,如下:

保存后的图片为:(是不是闪瞎了你的眼,这么绚丽多姿)

一般我们看到的都是可视化出来的彩色光流场:不同颜色表示不同的运动方向,深浅表示运动的速度。
你会发现,疯狂动物城中的树懒不是最慢的,而是此时提取光流的速度,一眼望不到头的慢!!!
那怎么办呢?当然使用GPU加速了呢,可是可是,安装一个能gpu加速的opencv需要管理员权限,另外代码都是matlab和c++,这又难住了我,如果那个大神实现了用gpu加速的代码,请联系我,我向你学习一下!
以下是gpu加速的参考资料:opencv3.0 gpu加速光流法
dense_flow
但是接下来讲的这篇是用深度学习来计算光流的。那怎么计算呢?
This paper:
首先这篇文章是ICCV2015年的论文, 论文地址Flownet,来自于德国弗莱堡大学和慕尼黑工业大学
In this paper we construct CNNs which are capable of solving the optical flow estimation problem as a supervised learning task.(per-pixel prediction)
提出了 两个架构,一个普通的Encoder Decoder , 另一个加了一个相关层(提供匹配的功能)。最后证明了普通的网络也可以学到哦,加入相关层是没有必要的。(但是在FlowNet2.0证明了FlowNetC outperforms FlowNetS,这里是因为FlowNet没有在完全相同的条件下去训练FlowNetS and FlowNetC, 参考lowNet2.0)另外由于现有的ground truth数据集不够大,这里生成了大量的合成数据集。然后用这些数据集,输入a pair of images去end-to -end训练CNN网络来预测光流场。
那光流估计需要什么呢?precise per-pixel localization,it also requires finding correspondences between two input images.This involves not only learning image feature representations,but also learning to match them at different locations in the two images.
Related Work
上面已经讲了传统的几种经典的方法了,现在用英文描述一下。
Variational approaches have dominated optical flow estimation since the work of Horn and Schunck.Many improvements have been introduced.The recent focus was on **large displacements,**and combinatoral matching has been integrated into the variational approach.
DeepFlow EpicFlow …
创新点:While there has been no work on estimating optical flow with CNNs,there has been reseach on matching with neural networks(如用欧几里得距离来匹配,用Siamese框架来计算相似度,)
Network Architectures
网络包含了 contracting(收缩) and expanding (放大)两部分

Contracting part:
这里有两种方案,这也是我们经常看到的方案,我们会在想,到底在哪一层融合特征呢?
第一种FlowNetS就是简单的把输入的图片对concat在一起,(通道由3变成6,这部分在数据集处理的部分实现,一般读取一张,现在读取两张list形式)送入网络,然后用真值让网络学得如何提取光流信息;
第二种FlowNetC就是各提取各的,two stream,然后到了一定的high level阶段把他们combine起来(就像Siamese网络),但是这样combine 网络怎么找到对应的位置呢?文章引入了一个"correlation layer",也就是在两个feature map中进行conv,和一般的区别是参数不需要学习。这里需要c x k x k multiplications,这样就导致了intractable,so limit the maximum displacement and introduce striding

Expanding part:
使用了," upconvolutional ",输入的还有来自 contracting 对应的feature map 和 unsampled coarser flow prediction(这个是怎么来的呢?当然是输入后的预测值了,例如知道t+1帧图像,知道t->t+1间的光流,那么可以从t+1wrap到t帧图像)
这样就有high-level information也有fine local information ,重复了4次,但是还是比原图小4倍,作者试验了直接用双线性差值到原来图片大小比继续upconvolution 有效,并与variational approach(变分方法)做了比较。

Existing Datasets

由于现存在的ground truth too small,所以作者自己合成了一个数据集训练并使用了数据增强,然后会用Sintel数据集fine-tuning。如下图所示:(左边生成和右边数据增强)

Loss

Result
作者总结如下:The figure show how the nets often produce visually appealing results,but are still worse in terms of endpoint error.你怎么认为呢?

原代码是caffe的咱也看不懂,,,但是有pytorch版本的代码,Flownetpytorch 模型很简单
贴一个前向传播的代码(FlowNetS)
def forward(self, x):
out_conv2 = self.conv2(self.conv1(x))
out_conv3 = self.conv3_1(self.conv3(out_conv2))
out_conv4 = self.conv4_1(self.conv4(out_conv3))
out_conv5 = self.conv5_1(self.conv5(out_conv4))
out_conv6 = self.conv6_1(self.conv6(out_conv5))
flow6 = self.predict_flow6(out_conv6)
flow6_up = crop_like(self.upsampled_flow6_to_5(flow6), out_conv5)
out_deconv5 = crop_like(self.deconv5(out_conv6), out_conv5)
concat5 = torch.cat((out_conv5,out_deconv5,flow6_up),1)
flow5 = self.predict_flow5(concat5)
flow5_up = crop_like(self.upsampled_flow5_to_4(flow5), out_conv4)
out_deconv4 = crop_like(self.deconv4(concat5), out_conv4)
concat4 = torch.cat((out_conv4,out_deconv4,flow5_up),1)
flow4 = self.predict_flow4(concat4)
flow4_up = crop_like(self.upsampled_flow4_to_3(flow4), out_conv3)
out_deconv3 = crop_like(self.deconv3(concat4), out_conv3)
concat3 = torch.cat((out_conv3,out_deconv3,flow4_up),1)
flow3 = self.predict_flow3(concat3)
flow3_up = crop_like(self.upsampled_flow3_to_2(flow3), out_conv2)
out_deconv2 = crop_like(self.deconv2(concat3), out_conv2)
concat2 = torch.cat((out_conv2,out_deconv2,flow3_up),1)
flow2 = self.predict_flow2(concat2)
if self.training:
return flow2,flow3,flow4,flow5,flow6
else:
return flow2
最后放一个youtube上的一个可视化视频















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









