







这是旷视(Megvii)2020年发表AAAI的一篇论文
论文地址: SiamFC++
代码地址: code
从题目看出此论文提出来鲁棒且精确跟踪的目标估计Guidelines,题眼就是Guidelines
视觉跟踪问题需要在给定目标下,同时有效的执行分类和精确的目标状态估计(也就是得到bbox),基于仔细的分析视觉跟踪问题的特性(one unique characteristic of generic object tracking is that no prior knowkedge(object class) about the object,as well as its surrounding environment),提出的Guidelines 如下:
| G1:decompositon of classification and state estimation(needing classification and target state estimation branch) G2:non-ambiguous scoring(classification score without ambiguity)也就是说分类的分数是目标存在的置信score,而不是预定义的设置,像anchor box 解释:In other words,our SiamFC++ directly views locations as training samples,while the anchor-based counterparts,which consider the location on the input image as the center of multiple anchor boxes,output multiple classification score at the same location and regress bounding box with respect to these anchor boxes,leading to ambiguous matching between anchor and object.we empirically show that the ambiguous matching could result in serious issues. In our per-pixel prediction fashion, only one prediction is made at each pixel on the final feature map. Hence it is clear that each classification score directly gives the confidence that the target is in the sub-window of the corresponding pixel and our design is free of ambiguity to this extent. G3:prior knowledge-free(tracking without prior knowledge)依赖数据分布的先验信息(scale/ratio distribution)会降低泛化能力 G4:estimate quality score直接使用分类的置信度进行bbox选择会降低跟踪性能,因此需要一个独立于分离的估计质量分数,ATOM 、Dimp 的第二branch就是使用这个guideline |
因此在siamfc的基础上加了一个用于精确目标估计的回归head,与分类head并列(G1),因为预先定义的achor设置被移除,所以matching ambiguity(G2)和目标scale/ratio分布(G3)被移除。最后增加了估计质量评估分支(G4)------这个开始不理解,你知道是什么吗?其实就是得到score , 也是目标位置,得到bbox,然后就是refine bbox,因为pss输入的是回归的值,从而refine目标位置。提高了跟踪和泛化能力,并且速度可以达到90FPS,是第一个在数据集TrackingNet中达到75.4,ATOM是70.3
Introduction
跟踪问题可以看出分类任务和估计任务的联合,分类任务提供一个鲁棒的粗略的目标位置,估计任务估计一个精确的目标状态(bbox)。尽管现在的跟踪器获得了显著的进步,但是他们的方法的第二个任务有很大的不同。
基于这个方面,以前的方法可以大体分为三个方面:
1.DCF、SiamFC使用粗暴的multi-scale test,它是不准确,效率也不高,先验假设是相邻帧以固定速率进行目标scale/ratio changes
2.ATOM,通过梯度下降迭代refine多个初始化的bbox来估计目标的bbox( 缺点:heavy computation burden 、additional hyperparameters)
3.SiamRPN 通过引入RPN进行准确和有效的目标状态估计,然而预定义的anchor设置不仅引入了模糊的相似性分数而且需要获得数据分布的先验信息(这违反了目标跟踪的spirit)。RPN回归预定义的anchor box和target location之间位置的偏移和大小(dx dy dw dh)

Related Works
Tracking Framework
Detection Framework(anchor-base,anchor-free
SiamFC++
框架图如下:

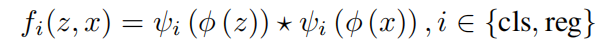
先用Siamese backbone进行特征提取
然后:

ψ
c
l
s
\psi_{cls}
ψcls and
ψ
r
e
g
\psi_{reg}
ψreg after common feature extraction to adjust the common features into task-specific feature space.
那没有RPN怎么进行分类和回归呢?
classification:
feature map
ψ
c
l
s
\psi_{cls}
ψcls location (x,y)
input image corresponding location(
⌊
s
2
⌋
\lfloor \frac{s}{2} \rfloor
⌊2s⌋ +xs,
⌊
s
2
⌋
\lfloor \frac{s}{2} \rfloor
⌊2s⌋ +ys) s:stride
regression:(只考虑正样本)
feature map
ψ
r
e
g
\psi_{reg}
ψreg location (x,y)
最后一层预测从对应位置(
⌊
s
2
⌋
\lfloor \frac{s}{2} \rfloor
⌊2s⌋ +xs,
⌊
s
2
⌋
\lfloor \frac{s}{2} \rfloor
⌊2s⌋ +ys)到真值bbox四个点的距离,表示为:
t
∗
\pmb{t}^\ast
ttt∗=(
l
∗
l^\ast
l∗,
t
∗
t^\ast
t∗,
r
∗
r^\ast
r∗,
b
∗
b^\ast
b∗)
因此对于location(x,y)回归目标计算如下:
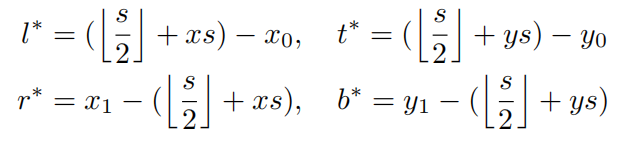
(
x
0
x_0
x0,
y
0
y_0
y0) and (
x
1
x_1
x1,
y
1
y_1
y1) 是真值的左上和右下的坐标。

fully-convolutional siamese trackers,where each pixel of the feature map directly corresponds to each translated sub-window on the search image due to its fully convolutional nature。

以上方法就避免了G2,G3(没有使用anchor)
那最后一个呢?
我们并没有考虑目标状态估计质量,而是直接使用分类的score来挑选最后的box,这会导致定位精确度下降, classification confidence is not well correlated with the localization accuracy。
根据分析,一个sub-window中心的输入pixel对 对应的输出特征比其他位置重要,因此我们假设目标中心的特征pixel比其他有一个更好的估计质量。所以在1x1卷积分类head添加了1x1卷积,输出被支持估计PSS(Prior Spatial Score):
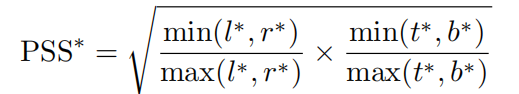
当然我们也可以用IOU来计算质量评估:


Training objective:

L
c
l
s
L_{cls}
Lcls表示focal loss用于分类的结果
L
q
u
a
l
i
t
y
L_{quality}
Lquality表示BCE(二进制交叉熵用于质量的评估
L
r
e
g
L_{reg}
Lreg表示IOU loss用于bbox result
assign
c
x
,
y
∗
c^\ast_{x,y}
cx,y∗ 1 to if (x, y) is considered as a positive sample, and 0 if as a negative sample.
如果这里的损失函数和标签不清楚,可以结合SiamCAR一起看
Experiments
实现了两个版本(不同的backbone architecture):
1.modified version of AlexNet
2.GoogleNet(和ResNet-50相当甚至更好)
Trainning data:
ILSVRC-VID/DET
COCO
Youtube-BB
LaSOT
GOT-10k( there is no class intersection between train and test subsets.)
对于视频数据集,我们从VID,LaSOT,GOT-10k,提取图像对,通过挑选间隔小于100的帧,5 for Youtube-BB。
training phase
for the AlexNet version:
600k image pairs for each epoch
冻结前三层卷积,fine-tune 后两层卷积,使用zero-centered 的高斯分布进行初始化。首先训练我们的模型5 warm up epochs ,学习率从
1
0
−
7
10^{-7}
10−7 to 2 x
1
0
−
3
10^{-3}
10−3 ,剩下的45个epochs使用余弦退火学习率。在vot2018上达到160FPS
for the GoogLeNet version:
20 epochs(5 for warming-up,and 15 for training),在vot2018上达到90FPS
300k images pairs per epoch

逐渐增加数据集,应用head structure,应用质量评估。
the regression branch(0.094),
data source diversity (0.063/0.010),
stronger backbone (0.026)
better head structure (0.020)
与其他方法在不同数据集上的比较:

SiamCAR
CVPR2020

与SiamFC++相比只是backbone的结构和计算score map 不一样,后面的两个分支都一样
这里贴一下回归分支,center-ness分支和分类分支的loss计算:
回归定义了一个网格

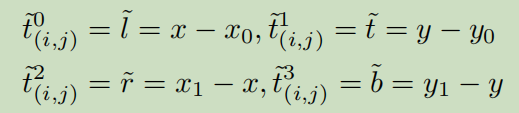
center-ness

分类
也是交叉熵损失函数(和siamrpn++ 一样)

SiamBAN
CVPR2020


这里也是用的是achor-free的思想,只不过使用了FCN 使用了multi-level的信息,计算不同层的一个分类和回归,分类的时候设置正负样本也是不一样的,它使用了椭圆的方法,并比较了与矩形、圆的区别。
分类和回归的操作如下:
















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









