







最近在帮朋友医疗器械行业的本地知识库,然后就想找个医疗领域的数据集对llama3做个简单微调,在专业性上更加符合医疗行业知识库的内容。
上了抱脸搜索相关信息,发现居然有个现成的
基于Llama 3微调的开源医疗AI大模型——OpenBioLLM-Llama3-70B和OpenBioLLM-Llama3-8B——不仅刷新了抱脸上的医疗大模型榜单,还成功占据了榜首位置。在生物医学领域的测试性能上超越了包括GPT-4、Gemini、Meditron-70B和Med-PaLM-2在内的行业巨头,成为了医疗AI领域开源大模型的后起之秀。
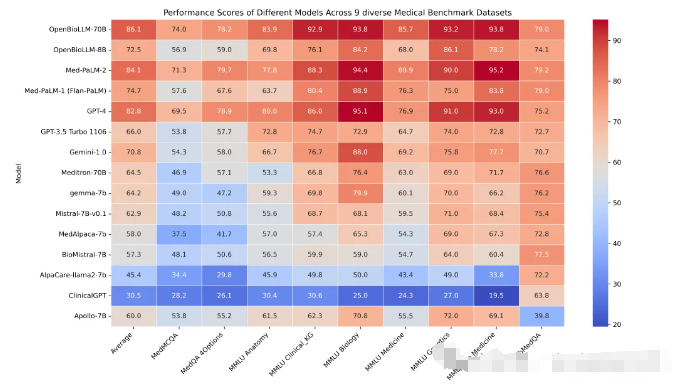
在 9 个不同的生物医学数据集上的表现,竟然超过了那些比它参数多的 GPT-4、Gemini、Meditron-70B 和 Med-PaLM-2。别看它参数少,成绩却好得让人眼前一亮,平均得分 86.06%,真是让人刮目相看!
作为医疗知识库的底座模型是非常合适的,8B的量化版本可以在基层医疗单位轻松本地部署,例如部署在社区诊所再跟社区居民健康档案的知识库一挂钩,配合数据采集设备将社区老年人在家中自行测量的心跳血压血糖等数据做自动化的数据分析,提前发现老年人健康问题,自动标注信息推送给家庭医生,真是科技改变生活
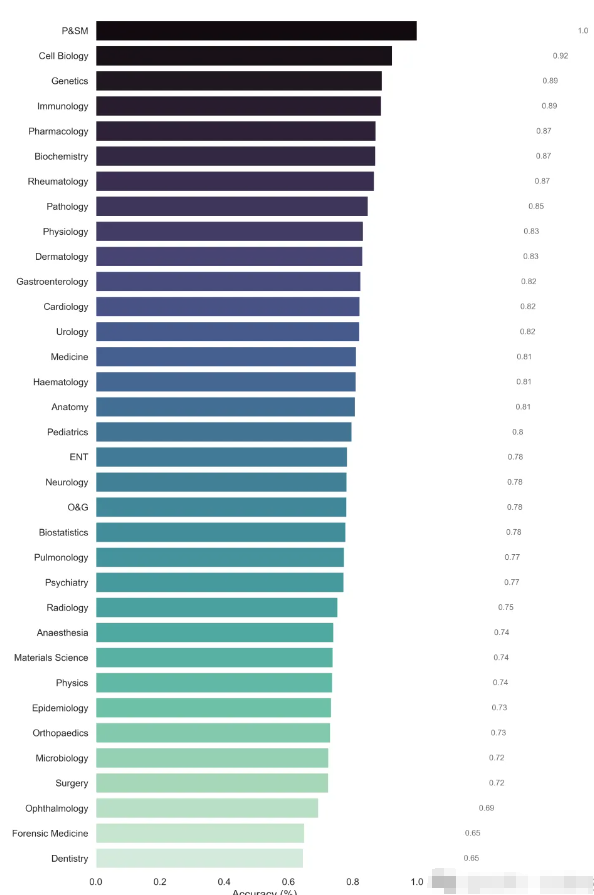
下面是准确性评测结果:
OpenBioLLM-70B 能快速翻阅一大堆临床记录、电子病历(EHR)和出院小结,从中找出要点,然后整理出一份简洁明了、条理清晰的摘要。
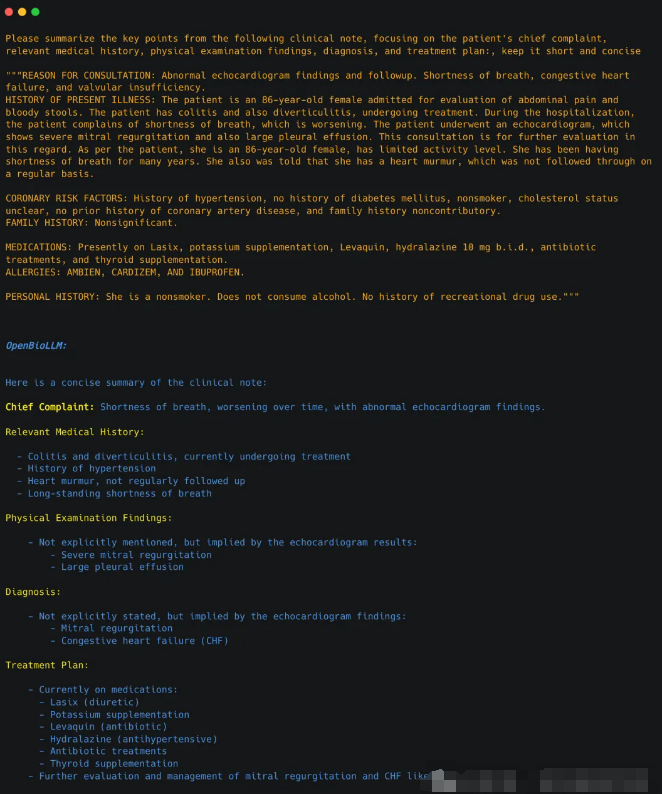
咨询原因:异常的超声心动图结果和随访。呼吸急促,充血性心力衰竭和瓣膜关闭不全。
现病史:患者为86岁女性,因评估腹痛和血便入院。患者有结肠炎和憩室炎,正在接受治疗。住院期间,患者诉说呼吸急促,且症状在恶化。患者接受了超声心动图检查,显示严重二尖瓣反流和大量胸腔积液。此次咨询是为了进一步评估这一情况。据患者所述,她是一位86岁的女性,活动能力有限。多年来一直有呼吸急促的症状。她还曾被告知有心脏杂音,但并未定期跟进。
冠状动脉疾病风险因素:高血压病史,无糖尿病史,非吸烟者,胆固醇状况不明,无冠状动脉疾病史,家族史无贡献。
家族史:无显著。
用药:目前服用的药物包括Lasix(利尿剂)、钾补充剂、Levaquin(抗生素)、肼苯哒嗪10毫克每日两次、抗生素治疗和甲状腺补充剂。
过敏史:安必恩(AMBIEN)、地尔硫卓(CARDIZEM)、布洛芬(IBUPROFEN)。
个人史:非吸烟者。不饮酒。无娱乐性药物使用史。
OpenBioLLM的总结如下:
主要症状:呼吸急促,随时间加重,伴有异常超声心动图结果。
相关医疗史:
- 结肠炎和憩室炎,目前正在治疗
- 高血压病史
- 心脏杂音,未定期跟进
- 长期呼吸急促
体格检查结果:未明确提及,但根据超声心动图结果暗示:
- 严重二尖瓣反流
- 大量胸腔积液
诊断:
- 未明确说明,但根据超声心动图结果暗示:
- 二尖瓣反流
- 充血性心力衰竭(CHF)
治疗计划:
-
目前正在使用的药物:
-
- Lasix(利尿剂)
- 钾补充剂
- Levaquin(抗生素)
- 肼苯哒嗪(降压药)
- 抗生素治疗
- 甲状腺补充剂
-
可能需要进一步评估和管理二尖瓣反流和CHF。
OpenBioLLM-70B 可以为广泛的医学问题提供答案,可以通过从非结构化临床文本中识别和提取关键医学概念(例如疾病、症状、药物、手术和解剖结构)来执行高级临床实体识别。
通过利用对医学术语和上下文的深刻理解,这个模型能准确地对临床实体进行注释和分类,从而从电子健康记录、研究文章和其他生物医学文本源中实现更高效的信息检索、数据分析和知识发现。此功能可以支持各种下游应用,例如临床决策支持、药物警戒和医学研究。
OpenBioLLM-70B 虽然用了大量的临床数据集做训练,但是它给出的信息有时候也可能不太准确,不能代替医生的治疗方案。
如何学习AI大模型?
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









