






Meta 最近发布了Llama 3,这是其开源大型语言模型(LLM)的最新和最强大的版本。Llama3包括两个版本:Llama 3 8B(含80亿个参数)和 Llama 3 70B(含700亿个参数),这两个版本都有基础和指令调整变体。
与Llama 2相比,Llama 3模型降低了错误拒绝率,提供了双倍的上下文长度,具有 8K 标记上下文窗口。Llama 3 模型的训练数据比 Llama 2 多出约 8 倍,在24000个GPU卡上,使用了超过 15 万亿个token的新的公开在线数据组合。HumanEval的大模型代码能力评测对比结果中,作为开源模型的Llama3得分为81.7分,高于闭源商业模型Gemini Pro 1.5(71.9分)和Claude 3 Sonnet(73分),低于Claude 3 Opus (84.9分) 和GPT4 Turbo (85.7分)。

本文介绍5种安装和运行Llama3的方法,供参考。
- 使用Web浏览器部署和运行模型
该方法使用WebGPU技术在Web浏览器运行模型,不需要网络和服务器端支持。
- WebLLM
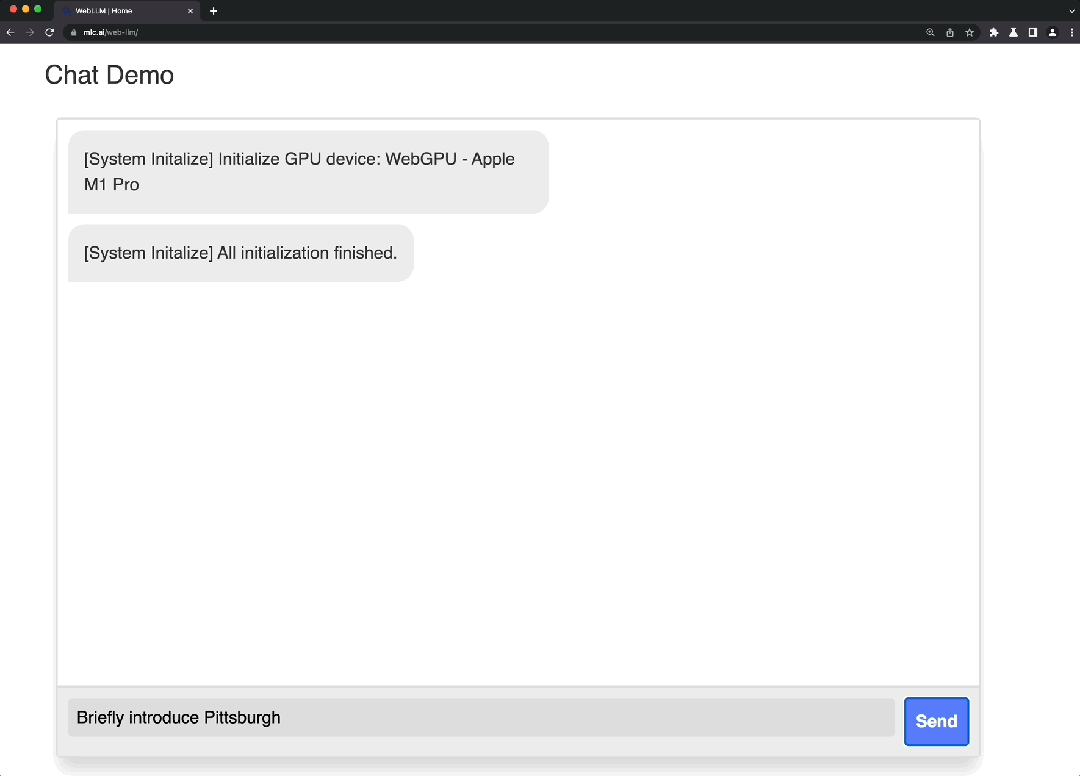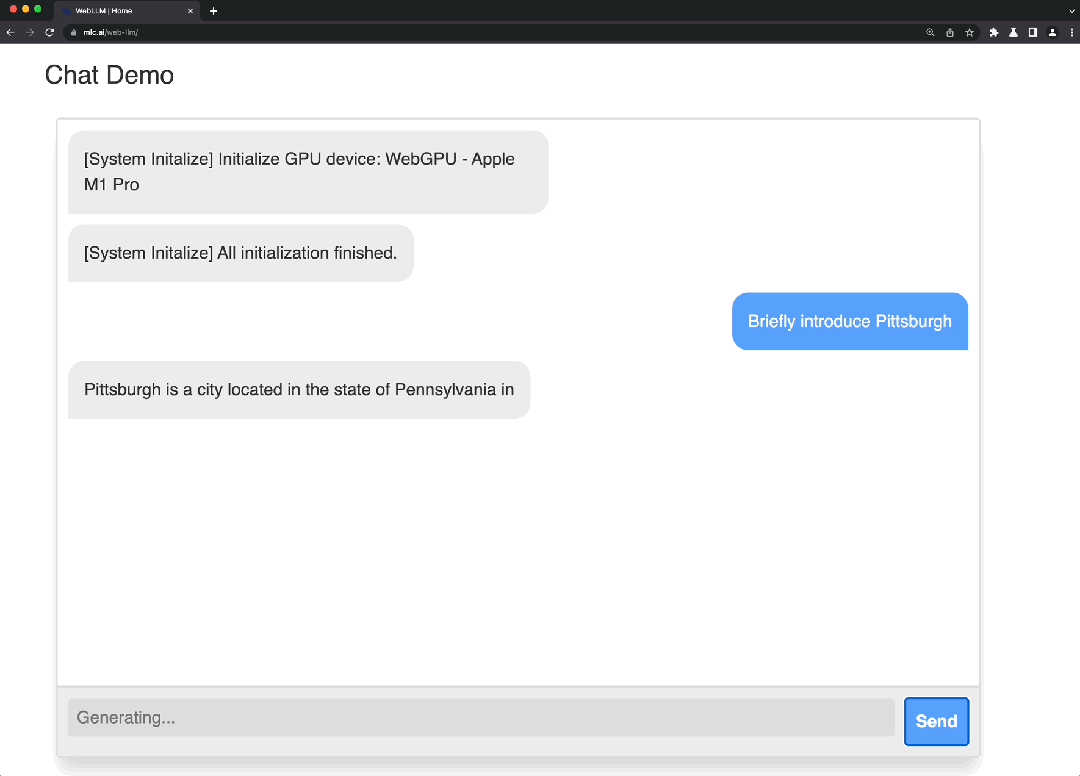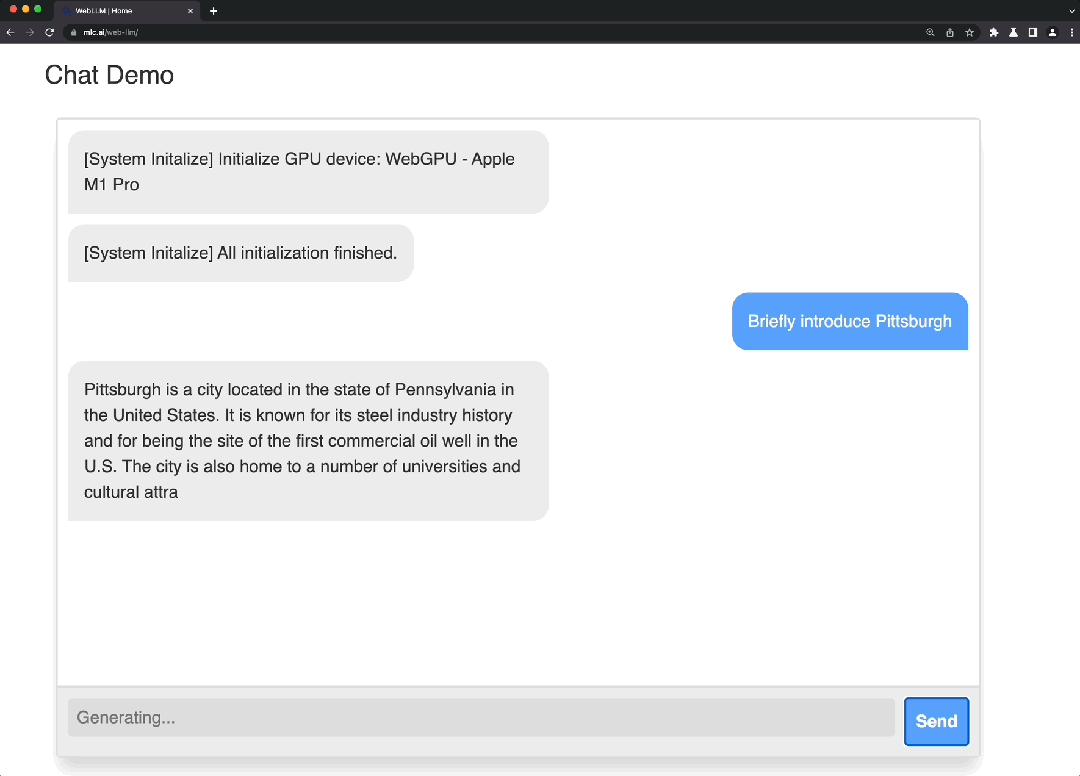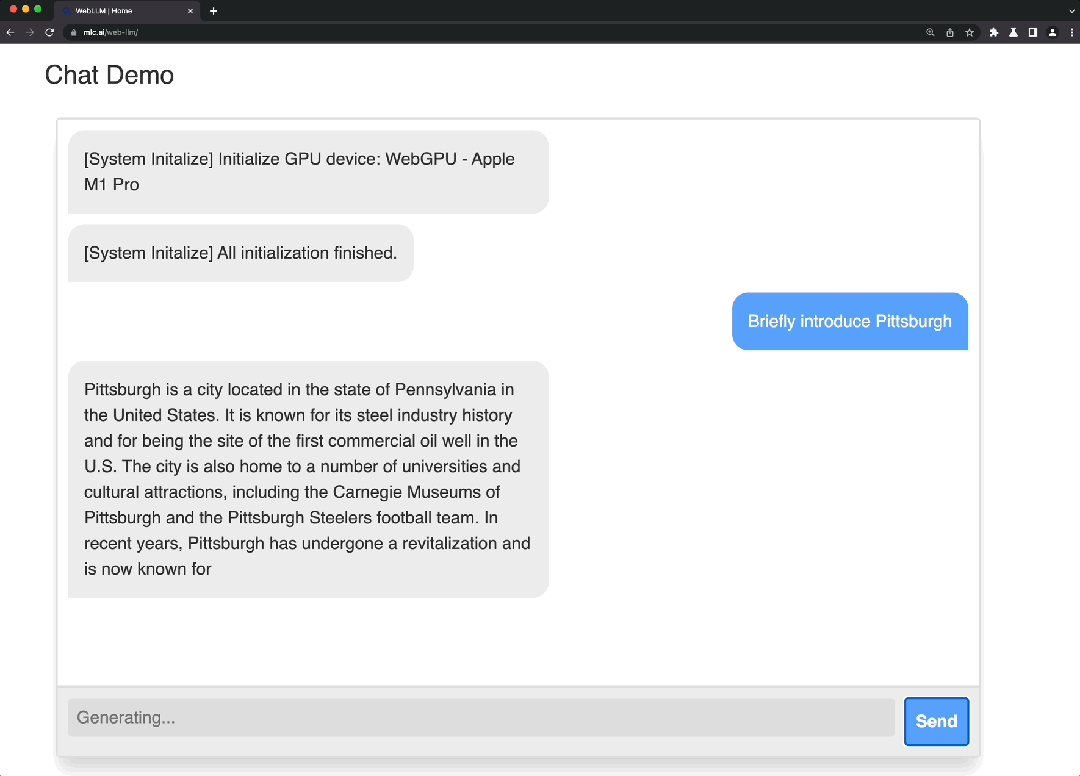
这是一个使用WebGPU和WebAssembly等技术的项目,能够完全在浏览器中运行大语言模型和大语言模型应用程序。WebLLM 是一个模块化和可定制的 javascript 软件包,可直接将语言模型聊天直接带入Web浏览器,并进行硬件加速。一切都在浏览器内运行,无需服务器支持,并通过 WebGPU 加速。同时还支持在手机上运行模型。
Demo: https://mlc.ai/mlc-llm/
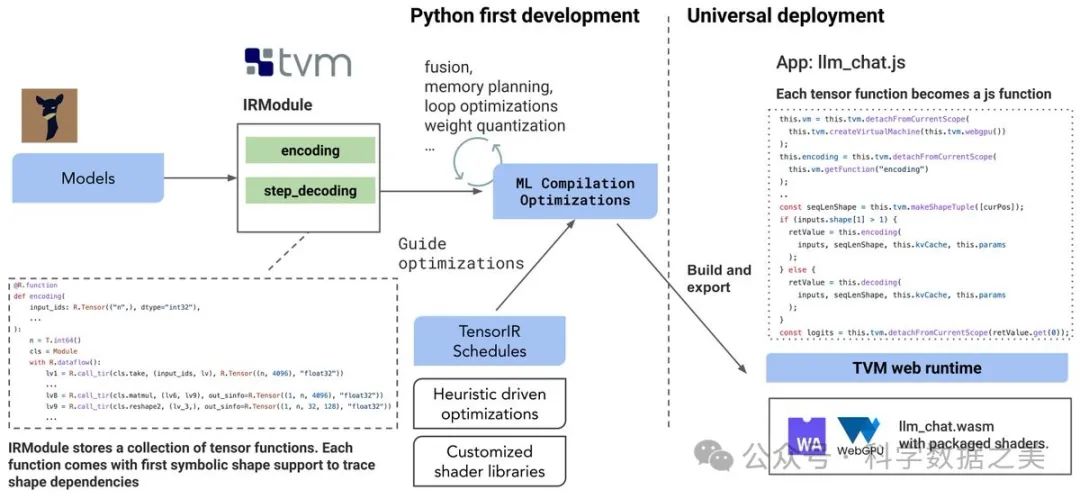
WebLLM技术架构
🔗 https://github.com/mlc-ai/web-llm
- Secret Llama
完全私有的大语言模型聊天机器人,完全通过浏览器运行,支持离线运行,无需服务器。目前支持 Mistral 和 LLama 3。
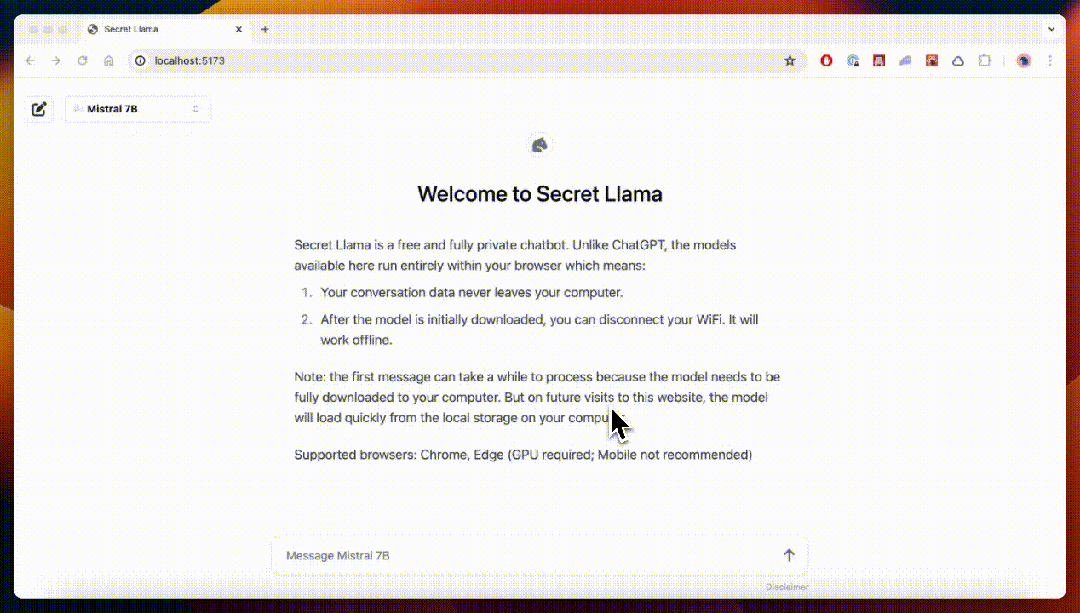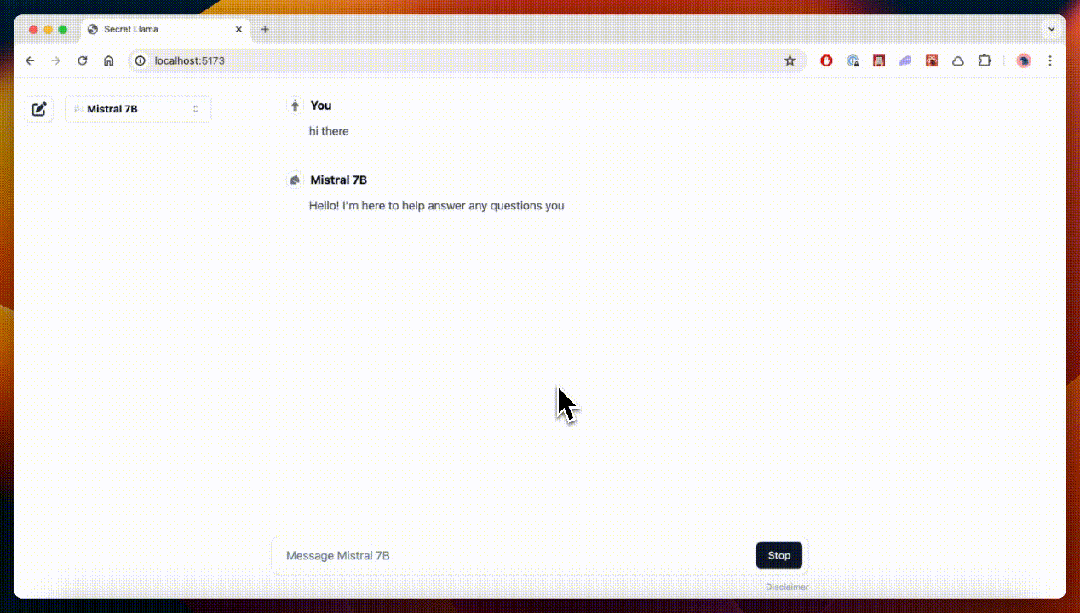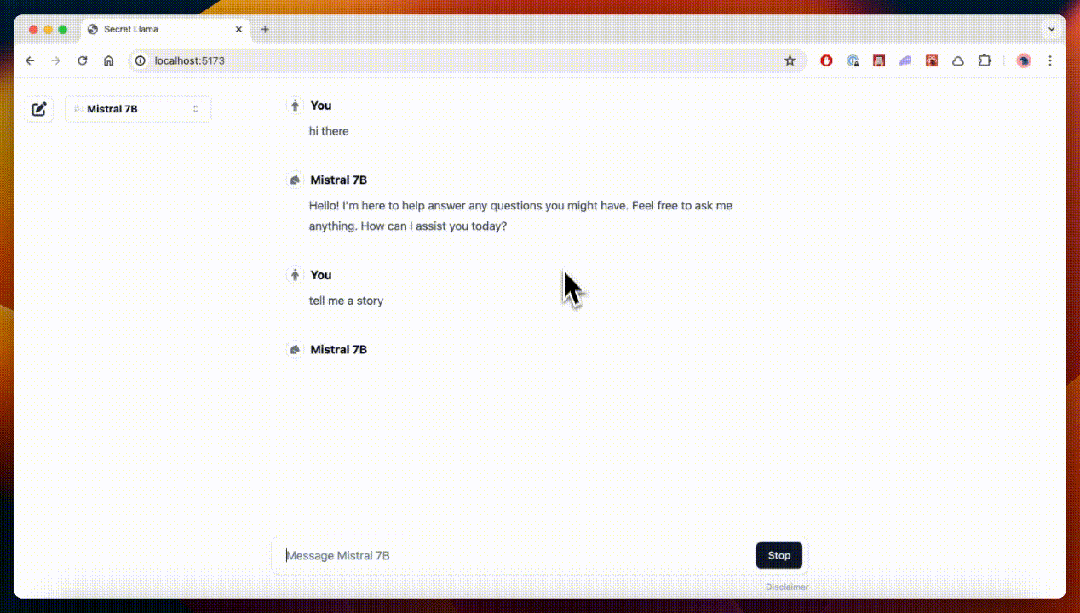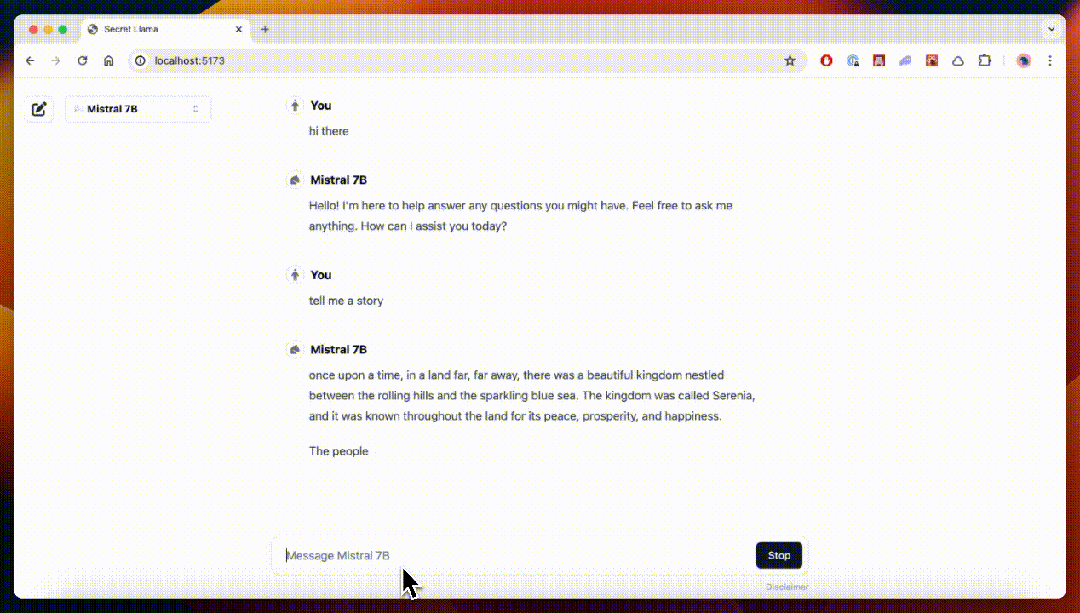
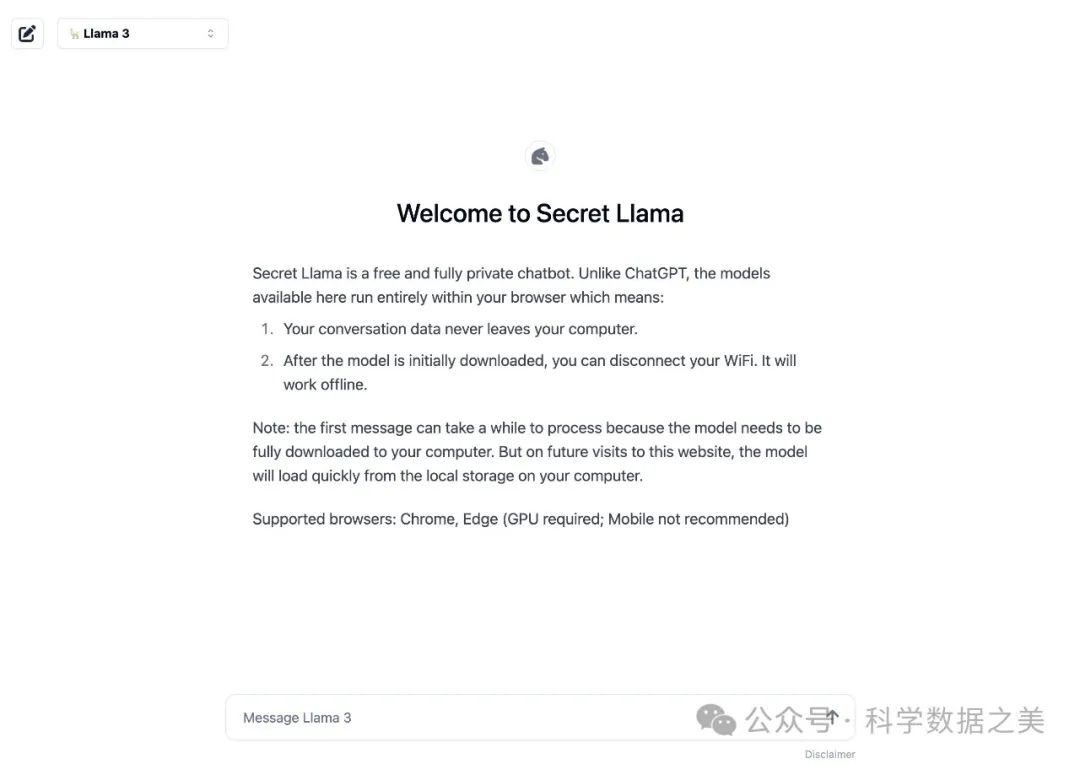
🔗 https://github.com/abi/secret-llama
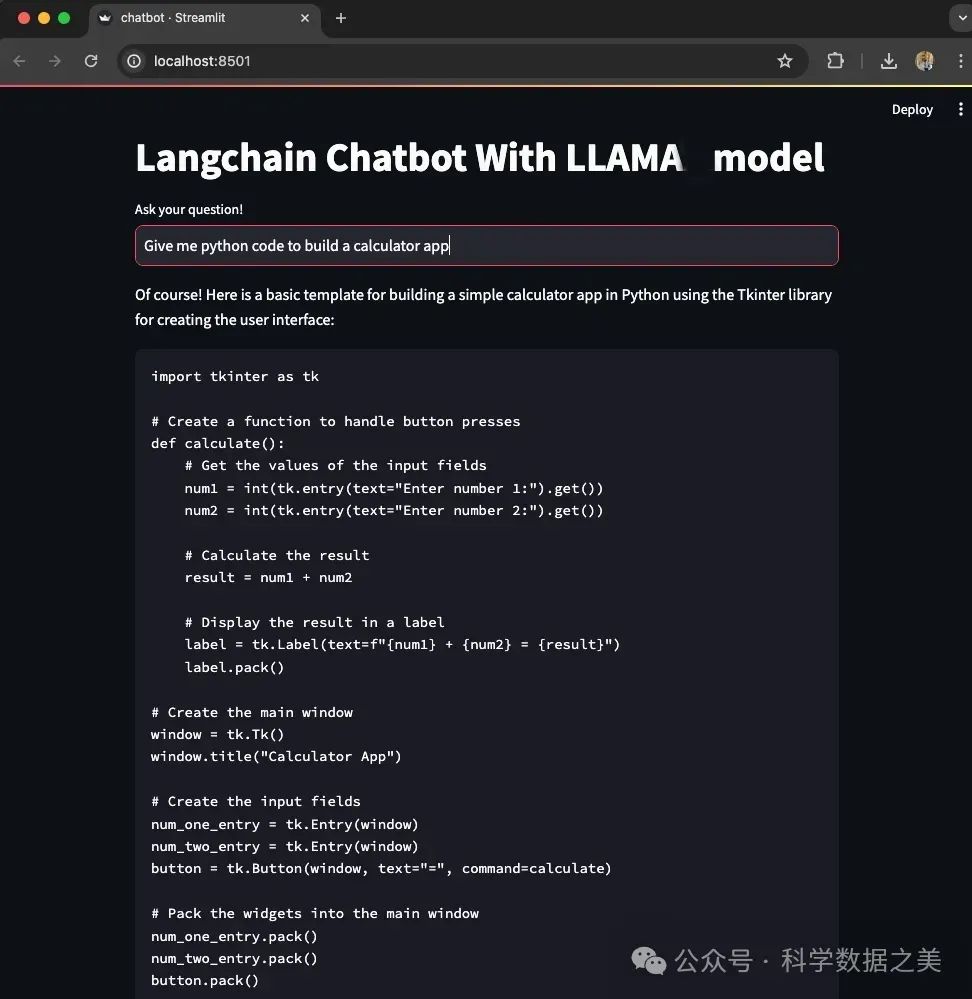
2. 使用Ollama+LangChain+streamlit构建模型聊天机器人
Ollama 是一个基于 Go 语言开发的简单易用的本地大语言模型部署和运行开源框架。可以将其类比docker包实现命令行交互中的 list,pull,push,run 等命令)。它将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括 GPU 使用情况,从而简化了在本地运行大型模型的过程。Ollama 支持多种模型,如Llama 2/3、Code Llama、Mistral、Gemma 等,并允许用户根据特定需求定制和创建自己的模型。

🔗 https://ollama.com/
LangChain是一个开源框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以让AI开发人员把大型语言模型和外部自定义数据结合起来。它提供了Python或**JavaScript(TypeScript)**的包。
🔗 https://github.com/langchain-ai/langchain
Streamlit是一个开源的 Python 库,允许开发人员快速创建交互式 Web 应用程序。它提供了一种简单直观的方法来构建数据可视化工具、机器学习应用程序和交互式仪表板。Streamlit 的主要功能之一是它能够创建响应式用户界面,这些界面会随着用户与应用程序的交互而实时更新。这使其成为构建聊天机器人和其他对话界面的理想选择。🔗 https://github.com/streamlit/streamlit

具体步骤如下:
-
安装Ollama,拉取Llama3 8B模型,运行模型
-
使用LangChain链接模型、提示词和数据
-
使用streamlit创建聊天机器人交互式应用程序
3. 使用LM Studio在本地运行Llama3
LM Studio 是一个可以在本地运行大语言模型的免费桌面端软件,支持MacOS、Windows和Linux操作系统。它支持在本地发现、下载和执行大语言模型,具有内置聊天界面以及与类似 OpenAI 的本地服务器的兼容性。通常被认为比 Ollama的界面更友好,LM Studio 还提供了更多来自 Hugging Face 等地方的模型选项,支持Llama 3、Phi 3、Falcon、Mistral、StarCoder、Gemma等模型。
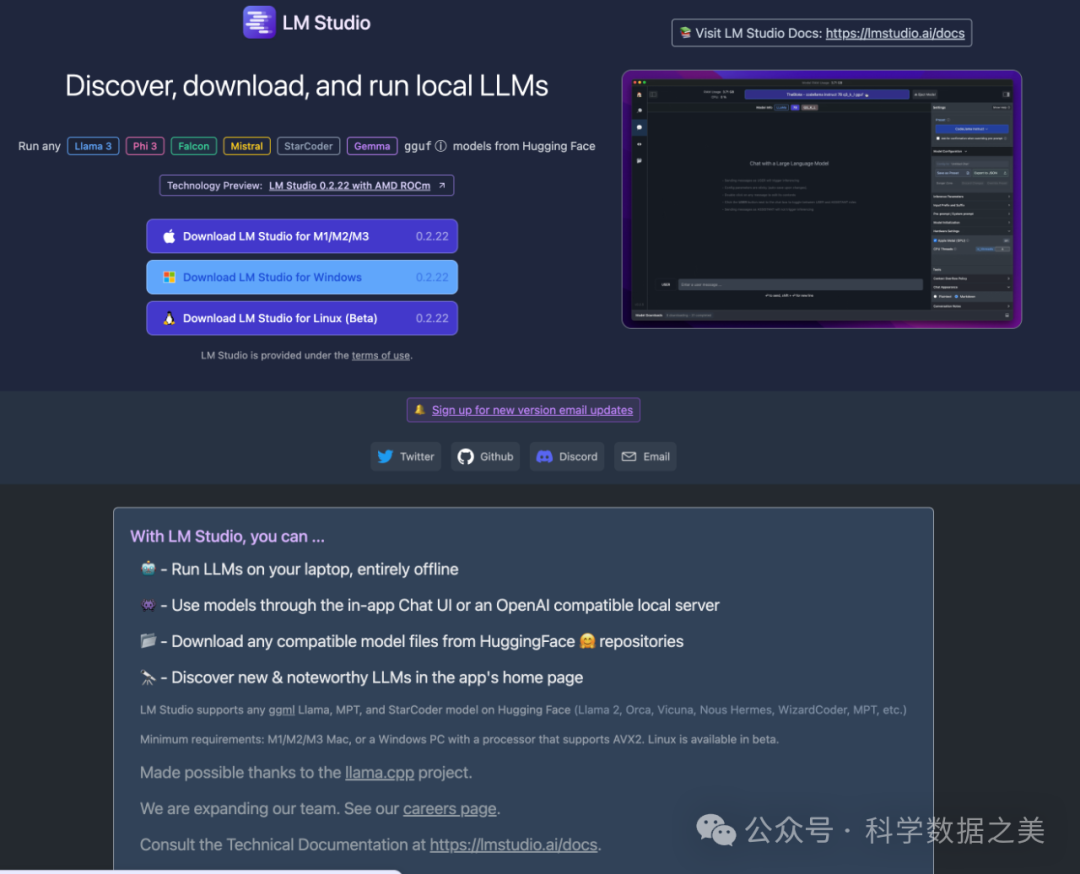
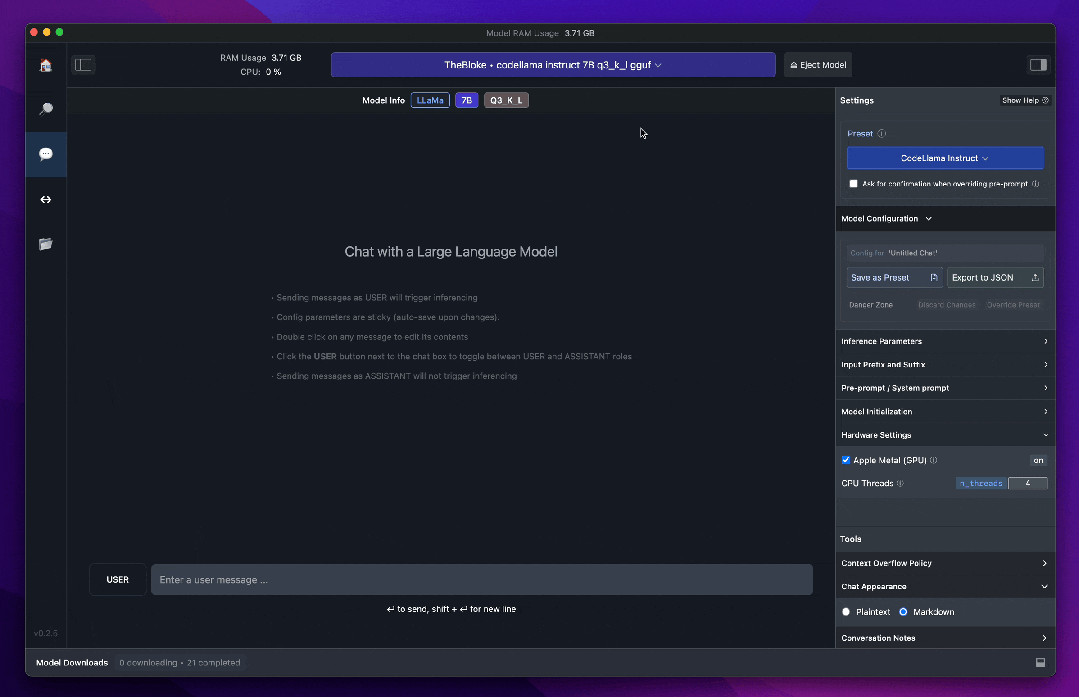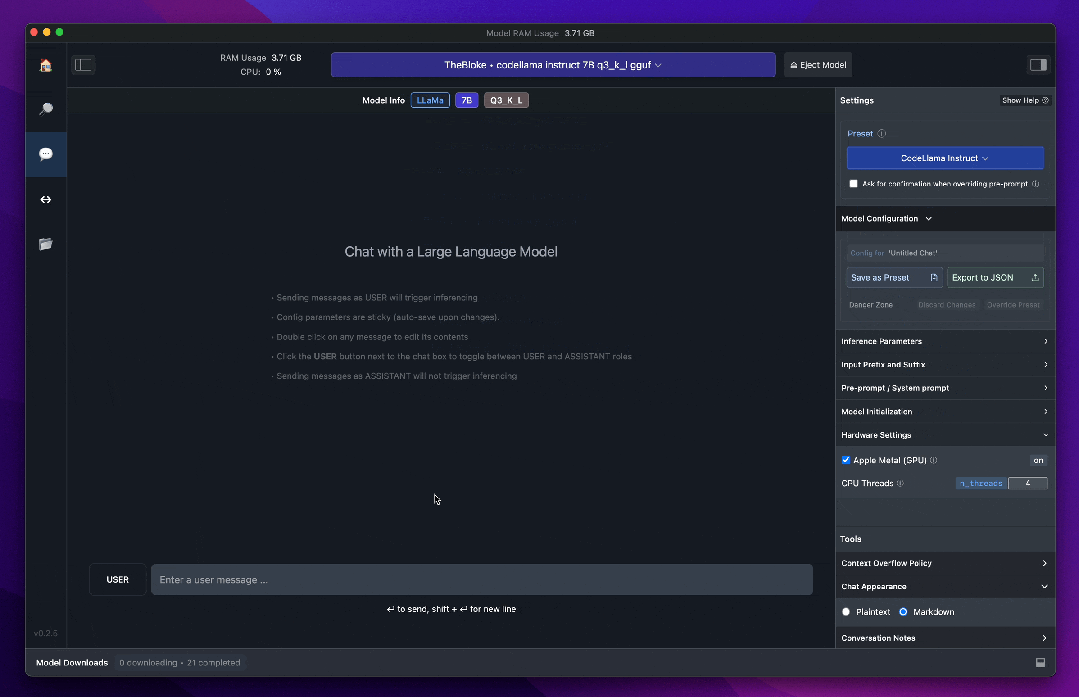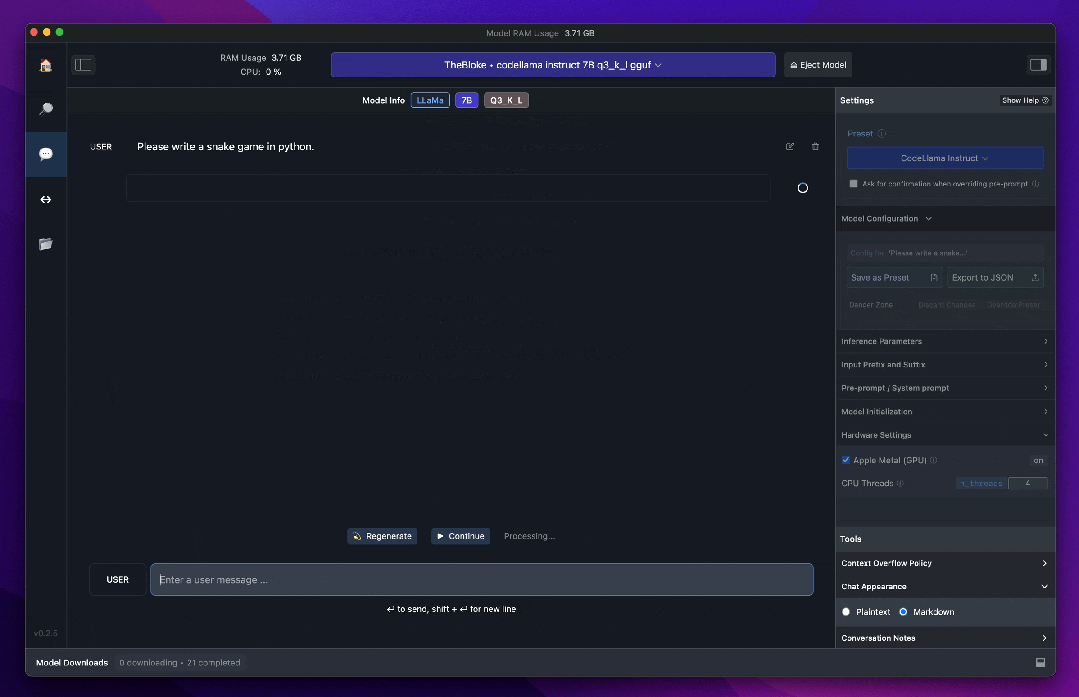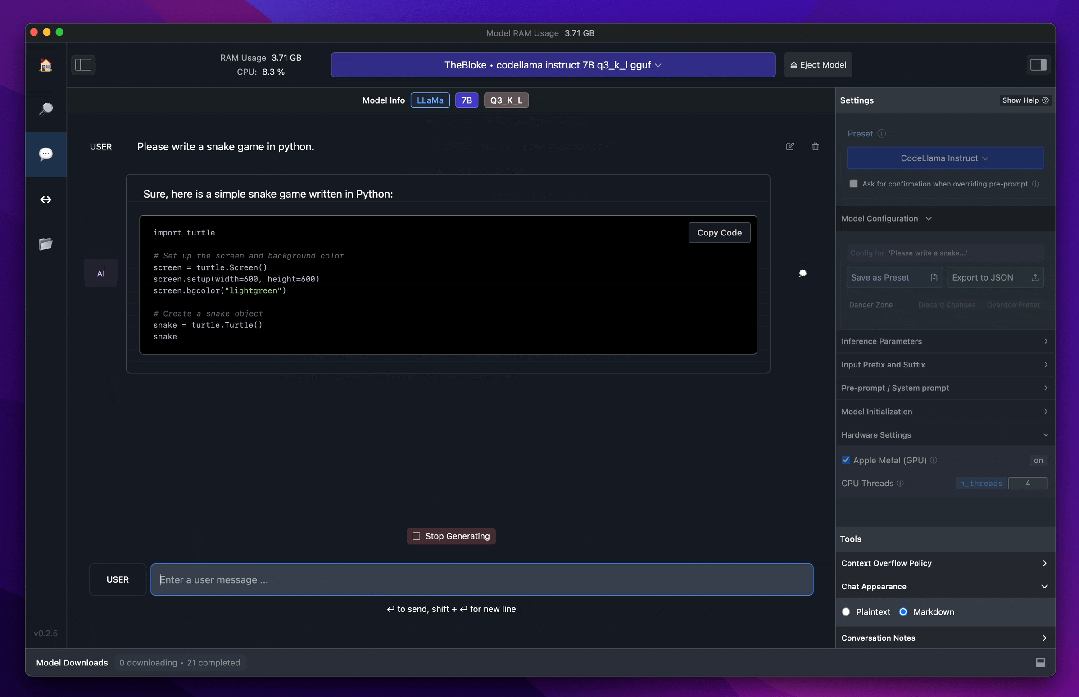
🔗 https://lmstudio.ai/
4. 使用4GB单卡GPU运行Llama3 70B模型
Llama3 70B 大型语言模型的参数大小为130GB。仅将模型加载到 GPU 中就需要 2 个 A100 GPU,每个 100GB 内存。
在推理过程中,还需要将整个输入序列加载到内存中,以进行复杂的 "注意力 "计算。这种注意力机制的内存需求与输入长度成四次方关系。除了 130GB 的模型大小外,还需要更多的内存。
开源项目AirLLM优化了模型推理内存的使用,允许 70B 大型语言模型在一块 4GB GPU 显卡上运行推理。无需量化、蒸馏、剪枝或其他会导致模型性能下降的模型压缩技术。
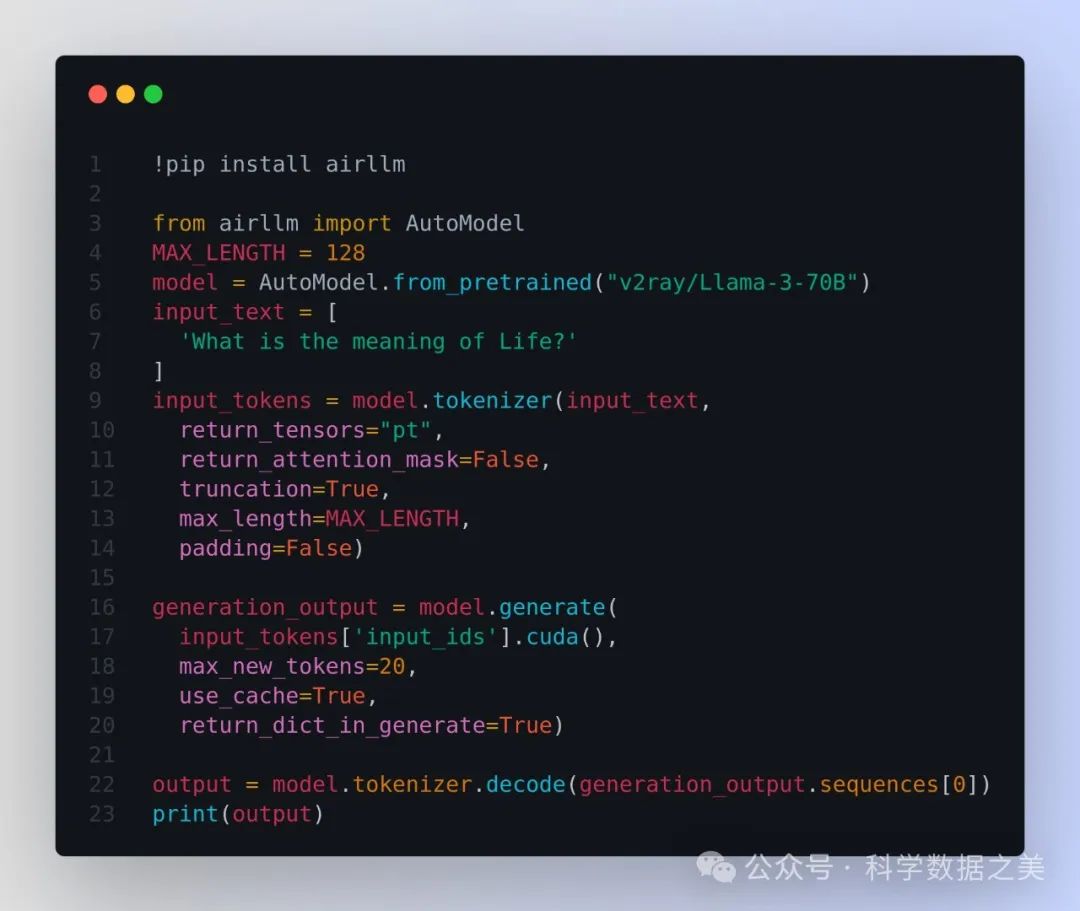
🔗 https://github.com/lyogavin/Anima/tree/main/air_llm
5. 使用免费在线AI平台运行Llama3模型
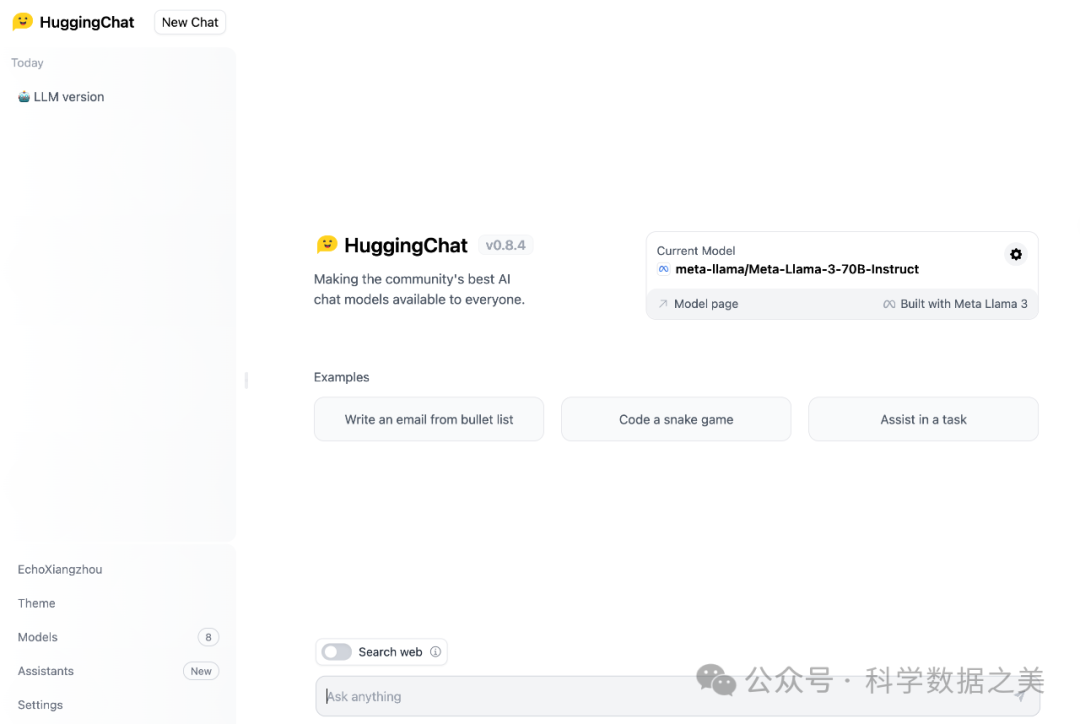
- Hugging Chat
HuggingChat 是 HuggingFace 开发的开源聊天机器人界面,用于与大型语言模型互动。要测试运行Llama,可以使用HuggingChat,登录或创建一个免费账户,然后在 "当前模型 "下选择 "Meta-Llama-3-70B-Instruct "模型。
🔗 https://huggingface.co/chat/
- Perplexity Labs
Perplexity Labs 是 Perplexity AI 的一个部门,它为开发人员提供了一个测试各种大型语言模型的实验场。
它提供了一个用户友好的界面,你可以选择 llama-3-70b-instruct 或 llama-3-8b-instruct 模型,并立即开始互动。
Perplexity Labs 的一大亮点是其慷慨的token限制。对于 llama-3-70b-instruct 模型,请求率限制为每 5 秒 20 个请求、每分钟 60 个请求和每小时 600 个请求。该模型的令牌率限制为每分钟 40,000 个令牌和每 10 分钟 160,000 个令牌。llama-3-8b-instruct 模型的请求速率限制为每 5 秒 20 个请求、每分钟 100 个请求和每小时 1000 个请求。令牌速率限制为每 10 秒 16,000 个令牌、每分钟 160,000 个令牌和每 10 分钟 512,000 个令牌。这对于广泛测试 Llama 3 的能力绰绰有余。
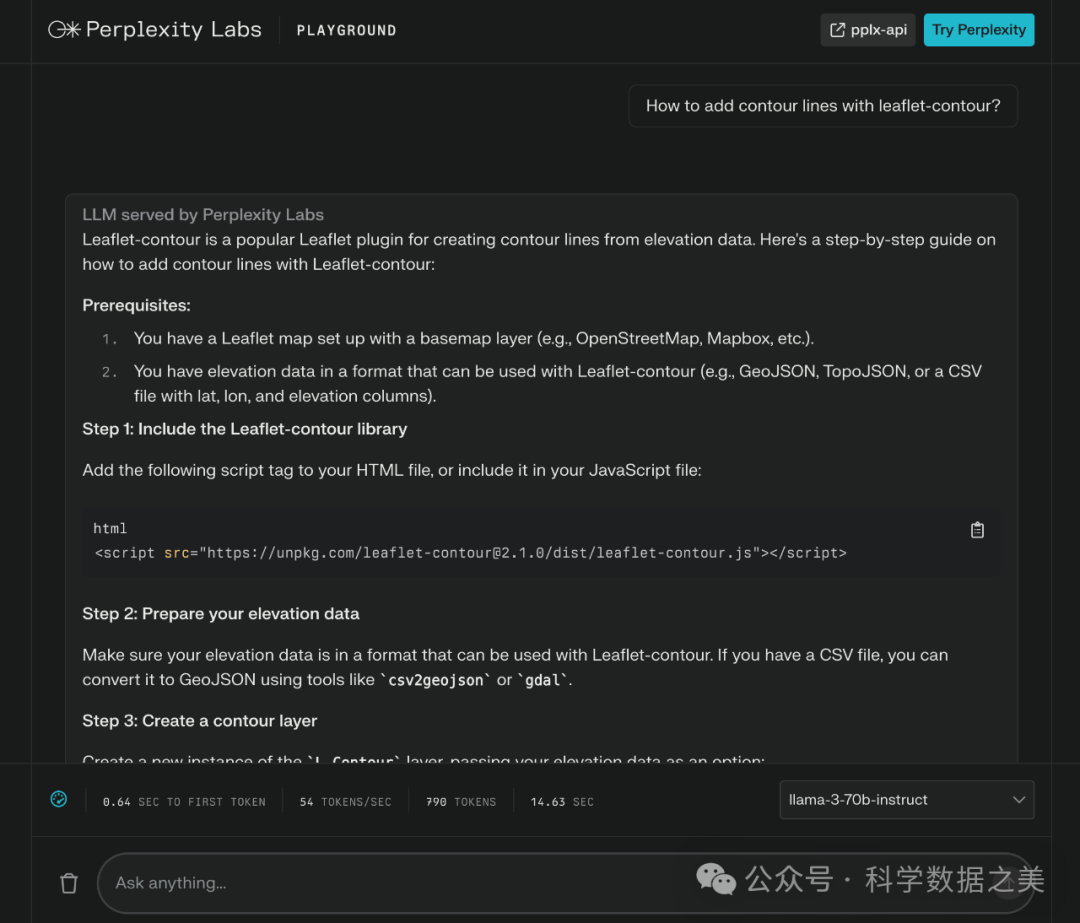
🔗 https://labs.perplexity.ai/
- Vercel Chat
Vercel Chat 可免费运行两个Llama 3版本。用户可以与两个或多个模型并排聊天,比较响应质量和令牌使用情况。这样就可以非常方便地将 Llama 3 与其他领先的人工智能模型进行直接比较。
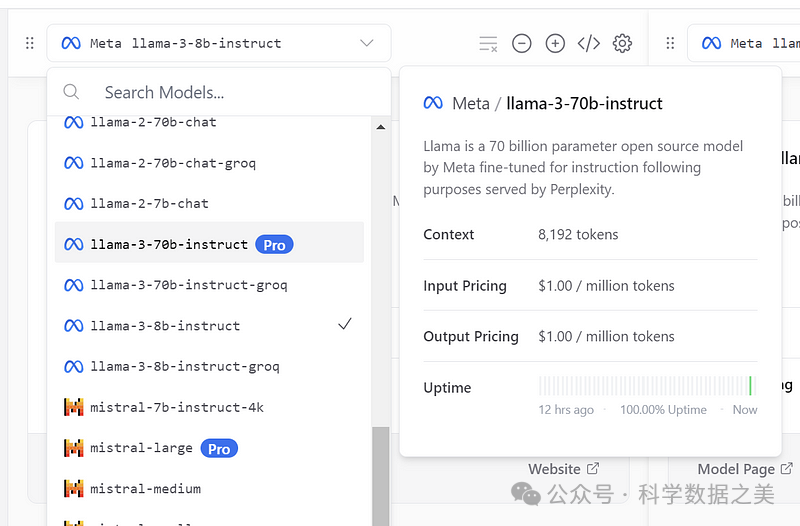
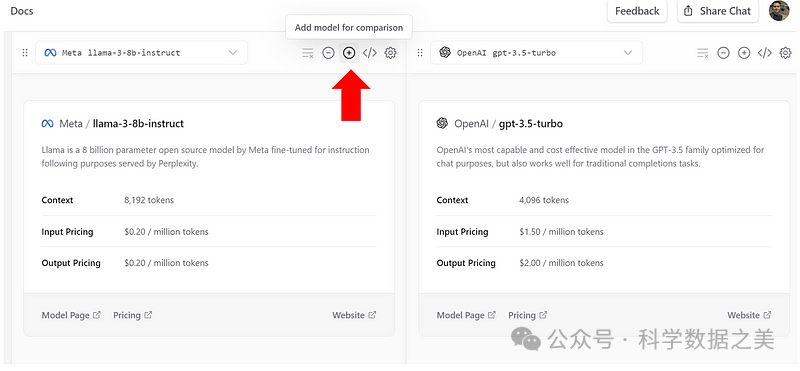
🔗 https://sdk.vercel.ai/
- Replicate
Replicate 为人工智能实验提供了一个简单实用的界面。您也无需创建账户,就可以立即与这些模型对话。
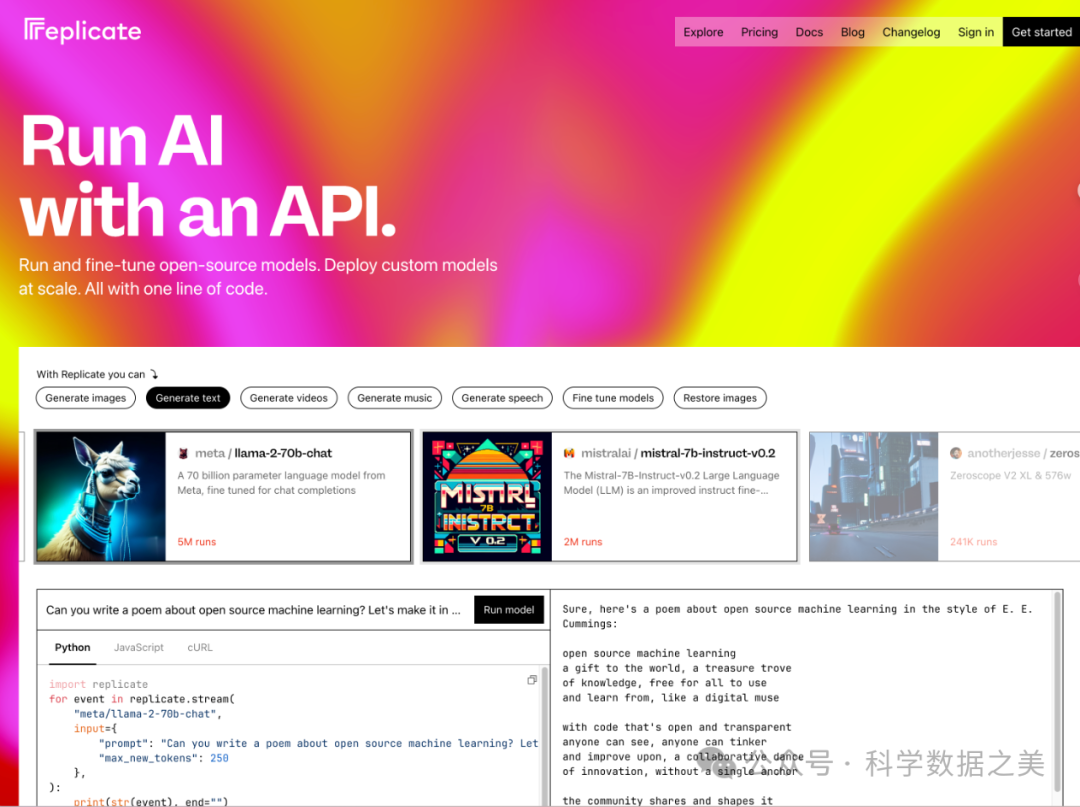
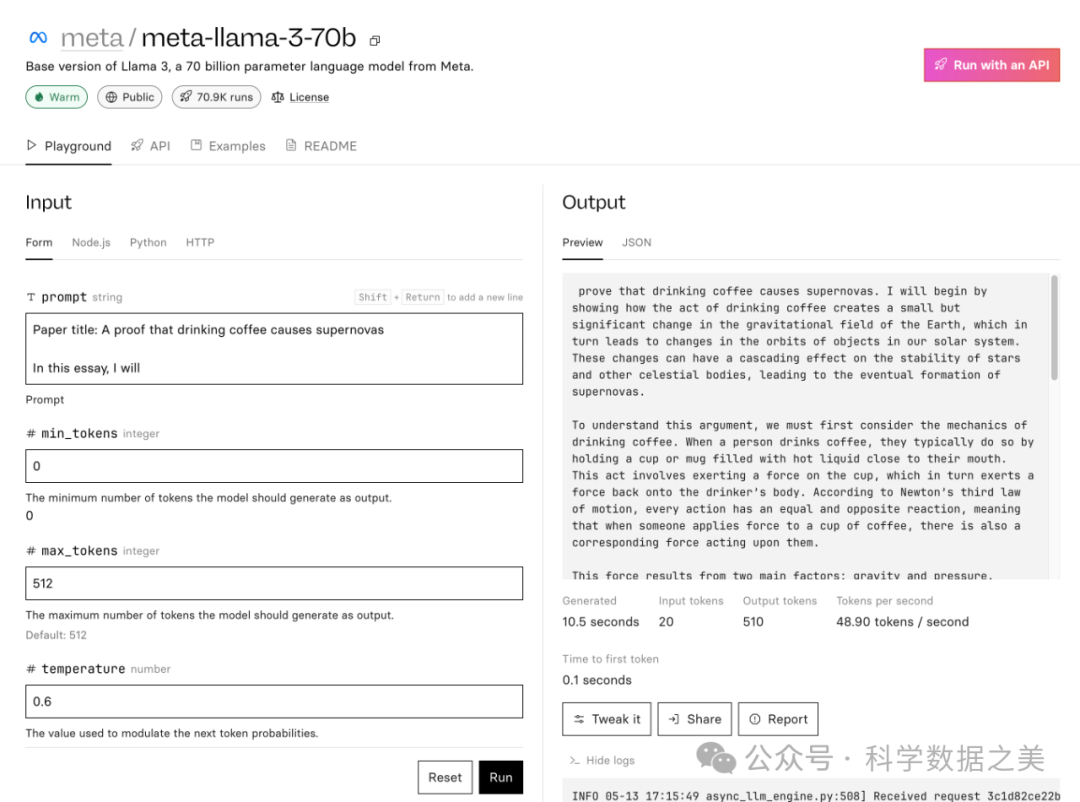
Llama 3 8B: https://replicate.com/meta/meta-llama-3-8b
Llama 3 70B: https://replicate.com/meta/meta-llama-3-70b
- Meta AI Web
在Meta AI官网运行Llama3,另外还可以通过Facebook、Instagram、WhatsApp、Messenger等软件使用该模型。
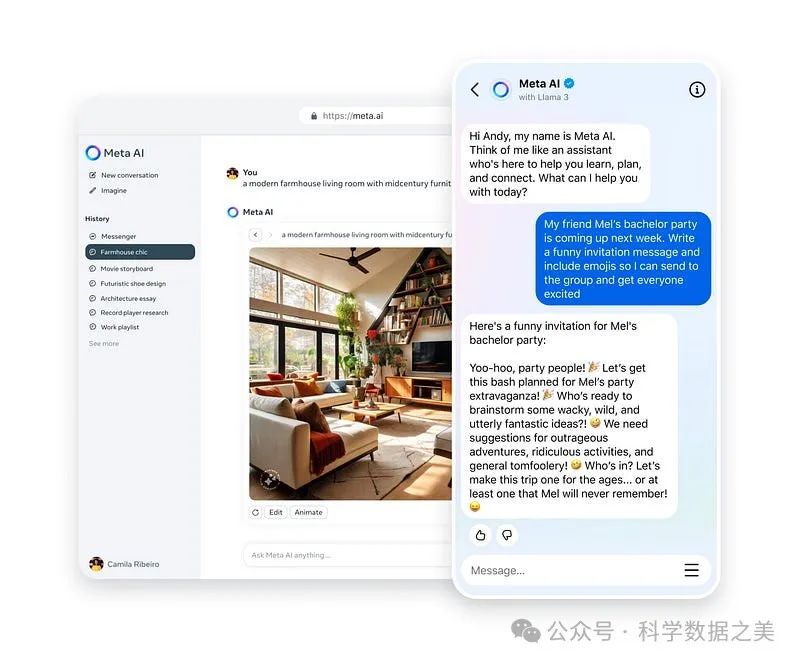
🔗 https://www.meta.ai/
- Cloudflare
Cloudflare官方出品,可以免费在线运行开源大模型的平台 ,亮点是不用注册,连注册按钮都没有,直接用。
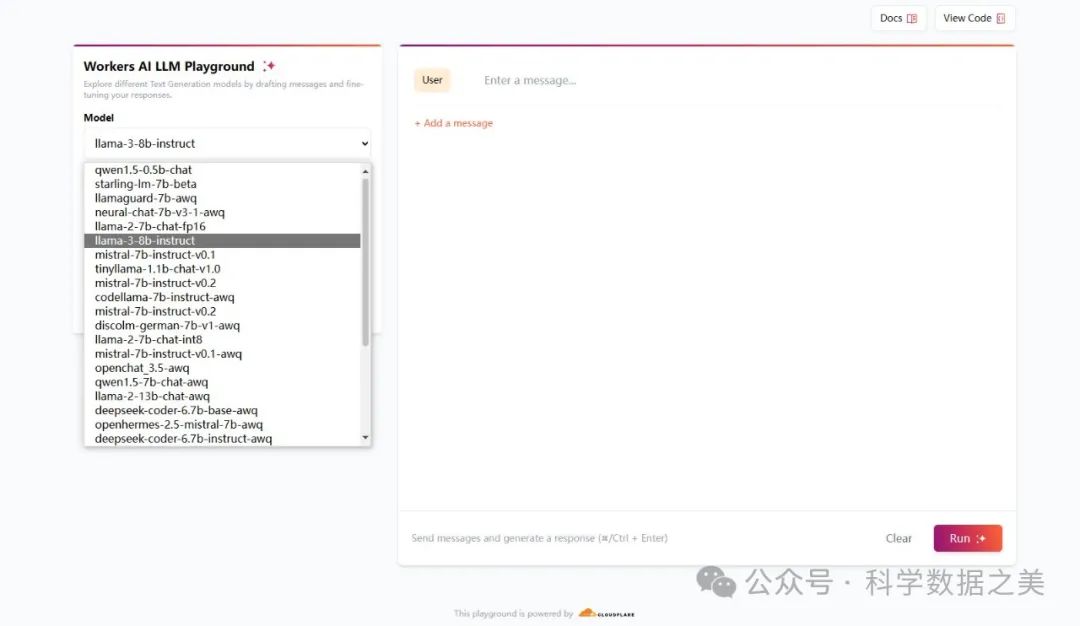
🔗 https://playground.ai.cloudflare.com
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









