






LangChain 就像是个多媒体翻译官,能帮你把各种图片、文字完美融合起来处理。
基本功能
模型接入
# 导入必要的模块
from langchain.llms import OpenAI
from langchain_community.chat_models import ChatOpenAI
# 设置API密钥
import os
os.environ["OPENAI_API_KEY"] = "你的OpenAI密钥"
# 创建语言模型实例
llm = OpenAI(temperature=0.7)
chat_model = ChatOpenAI(model_name="gpt-4-vision-preview")
# 简单测试
回复 = llm.invoke("解释下什么是多模态AI")
print(回复)
图像处理
# 导入图像处理相关模块
from langchain_core.messages import HumanMessage
from langchain_community.document_loaders import ImageLoader
# 创建图像消息
图片消息 = HumanMessage(
content=[
{"type": "text", "text": "这张图片里有什么?"},
{
"type": "image_url",
"image_url": "https://example.com/image.jpg"
}
]
)
# 获取图片描述
图片描述 = chat_model.invoke([图片消息])
print(图片描述.content)
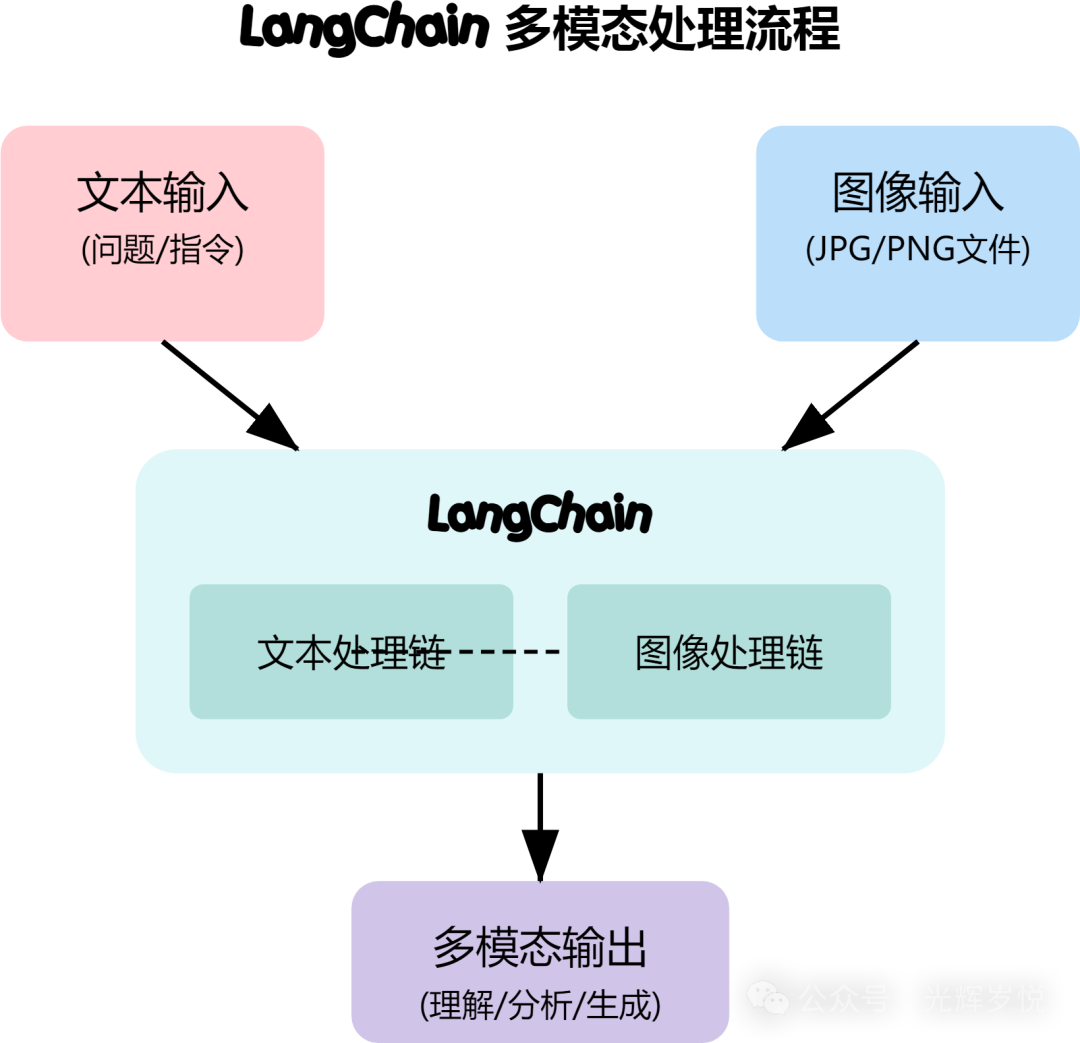
实用功能
文档图像分析
# 导入文档和图像处理工具
from langchain_community.document_loaders import PyPDFLoader
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 加载包含图片的PDF
pdf加载器 = PyPDFLoader("报告.pdf")
页面列表 = pdf加载器.load()
# 创建提示模板
提示模板 = PromptTemplate(
input_variables=["page_content"],
template="分析这个PDF页面内容,包括文字和图表:{page_content}"
)
# 创建分析链
分析链 = LLMChain(llm=chat_model, prompt=提示模板)
# 分析每个页面
for 页面 in 页面列表:
分析结果 = 分析链.run(页面.page_content)
print(f"页面 {页面.metadata['page']}: {分析结果}")
图片批量处理
# 图片批处理功能
import os
from pathlib import Path
from langchain.chains import SimpleSequentialChain
def 批量处理图片(图片文件夹):
结果集 = {}
# 创建图片描述链
描述提示 = PromptTemplate(
input_variables=["image_path"],
template="详细描述这张图片内容: {image_path}"
)
描述链 = LLMChain(llm=chat_model, prompt=描述提示)
# 创建分类链
分类提示 = PromptTemplate(
input_variables=["description"],
template="根据这个描述,将图片分类: {description}"
)
分类链 = LLMChain(llm=llm, prompt=分类提示)
# 组合链
完整处理链 = SimpleSequentialChain(
chains=[描述链, 分类链],
verbose=True
)
# 处理文件夹中所有图片
for 文件路径 in Path(图片文件夹).glob("*.jpg"):
try:
结果 = 完整处理链.run(str(文件路径))
结果集[文件路径.name] = 结果
except Exception as e:
print(f"处理 {文件路径} 时出错: {e}")
return 结果集
多模态QA构建
# 构建多模态问答系统
from langchain.retrievers import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.document import Document
def 创建多模态知识库(文本列表, 图片列表):
# 初始化嵌入模型
嵌入模型 = OpenAIEmbeddings()
# 创建向量存储
向量数据库 = Chroma(embedding_function=嵌入模型)
# 处理文本文档
文本文档 = [Document(page_content=文本) for 文本 in 文本列表]
向量数据库.add_documents(文本文档)
# 处理图片 - 先获取描述再存储
for 图片路径 in 图片列表:
图片消息 = HumanMessage(
content=[
{"type": "text", "text": "详细描述这张图片"},
{"type": "image_url", "image_url": f"file://{图片路径}"}
]
)
描述 = chat_model.invoke([图片消息])
图片文档 = Document(
page_content=描述.content,
metadata={"source": 图片路径, "type": "image"}
)
向量数据库.add_documents([图片文档])
# 创建检索器
检索器 = 向量数据库.as_retriever()
return 检索器
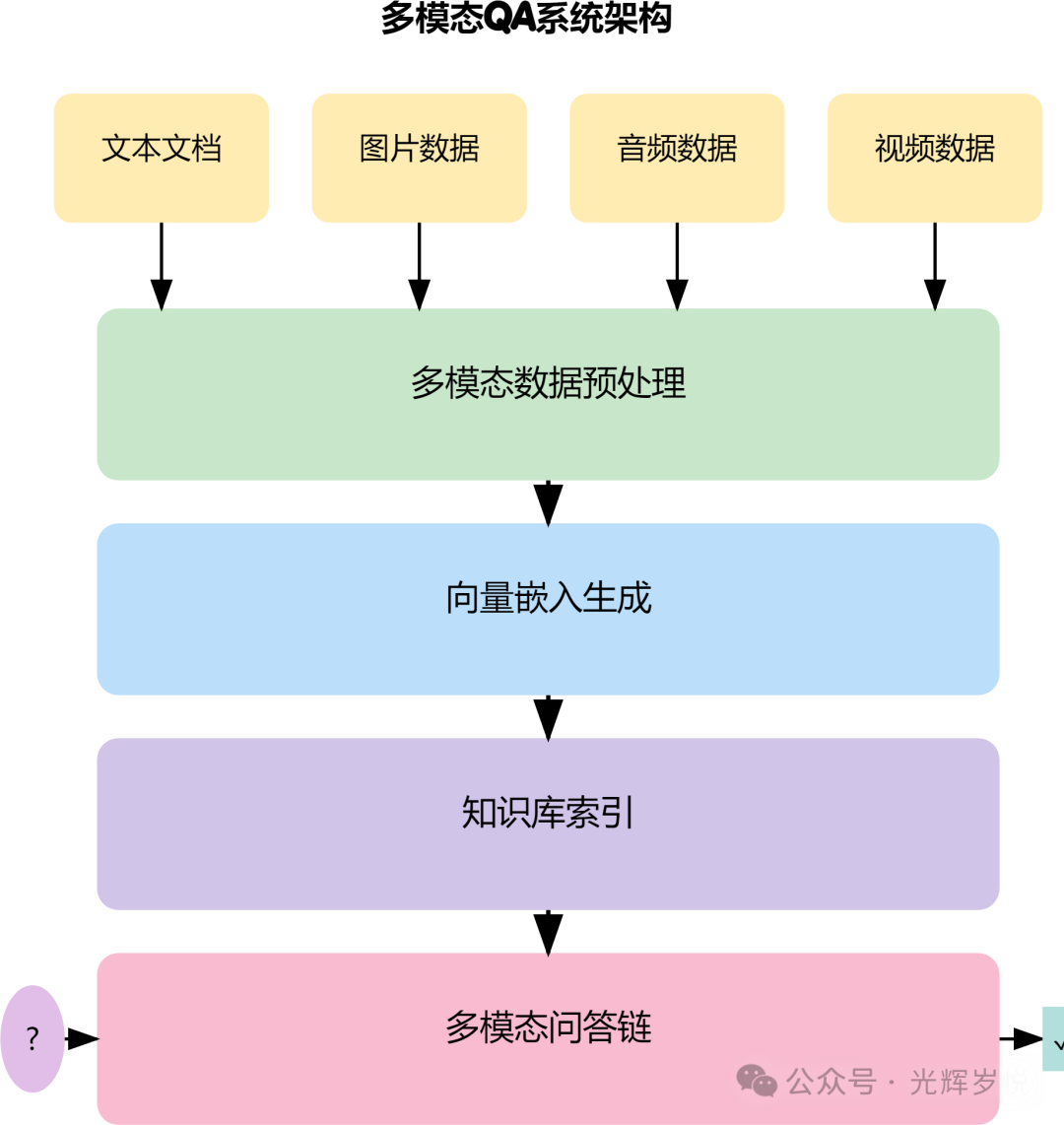
常见任务示例
图片内容搜索
# 构建图片内容搜索系统
from langchain.vectorstores import FAISS
from langchain.retrievers import MultiQueryRetriever
def 创建图片搜索(图片文件夹):
# 初始化图片库
图片数据 = []
嵌入模型 = OpenAIEmbeddings()
# 处理每张图片获取描述和特征
for 图片路径 in Path(图片文件夹).glob("*.jpg"):
图片消息 = HumanMessage(
content=[
{"type": "text", "text": "用100字描述这张图片的内容、风格和主题"},
{"type": "image_url", "image_url": f"file://{图片路径}"}
]
)
# 获取图片描述
图片描述 = chat_model.invoke([图片消息])
# 创建文档
图片文档 = Document(
page_content=图片描述.content,
metadata={"source": str(图片路径), "type": "image"}
)
图片数据.append(图片文档)
# 创建向量存储
向量库 = FAISS.from_documents(图片数据, 嵌入模型)
# 创建多查询检索器以提高召回率
检索器 = MultiQueryRetriever.from_llm(
retriever=向量库.as_retriever(),
llm=llm
)
return 检索器
# 使用方法
def 搜索图片(检索器, 查询):
相关文档 = 检索器.get_relevant_documents(查询)
结果 = []
for 文档 in 相关文档:
结果.append({
"图片路径": 文档.metadata["source"],
"匹配原因": 文档.page_content,
"类型": 文档.metadata["type"]
})
return 结果
图文报告生成
# 图文报告生成系统
from langchain.chains import SequentialChain
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 定义报告结构
class 报告结构(BaseModel):
标题: str = Field(description="报告的主标题")
摘要: str = Field(description="内容摘要,100字以内")
章节: List[str] = Field(description="报告的章节标题列表")
结论: str = Field(description="报告的结论和建议")
def 生成图文报告(文本内容, 图片列表, 报告主题):
# 处理图片获取内容描述
图片描述列表 = []
for 图片路径 in 图片列表:
图片消息 = HumanMessage(
content=[
{"type": "text", "text": "分析这张图片的内容并提取关键信息"},
{"type": "image_url", "image_url": f"file://{图片路径}"}
]
)
描述 = chat_model.invoke([图片消息])
图片描述列表.append(描述.content)
# 创建报告结构提示
结构提示 = PromptTemplate(
template="基于以下内容和主题'{topic}',生成一个报告结构:\n文本内容:{text}\n图片描述:{images}\n{format_instructions}",
input_variables=["text", "images", "topic"],
partial_variables={"format_instructions": PydanticOutputParser(pydantic_object=报告结构).get_format_instructions()}
)
# 创建报告生成链
结构解析器 = PydanticOutputParser(pydantic_object=报告结构)
结构链 = LLMChain(
llm=llm,
prompt=结构提示,
output_key="报告结构"
)
# 定义内容生成提示
内容提示 = PromptTemplate(
template="根据以下报告结构和资料,生成完整的报告内容:\n结构:{报告结构}\n文本:{text}\n图片描述:{images}",
input_variables=["报告结构", "text", "images"]
)
内容链 = LLMChain(
llm=llm,
prompt=内容提示,
output_key="最终报告"
)
# 组合链
报告链 = SequentialChain(
chains=[结构链, 内容链],
input_variables=["text", "images", "topic"],
output_variables=["最终报告"],
verbose=True
)
# 生成报告
return 报告链.run(
text=文本内容,
images=图片描述列表,
topic=报告主题
)
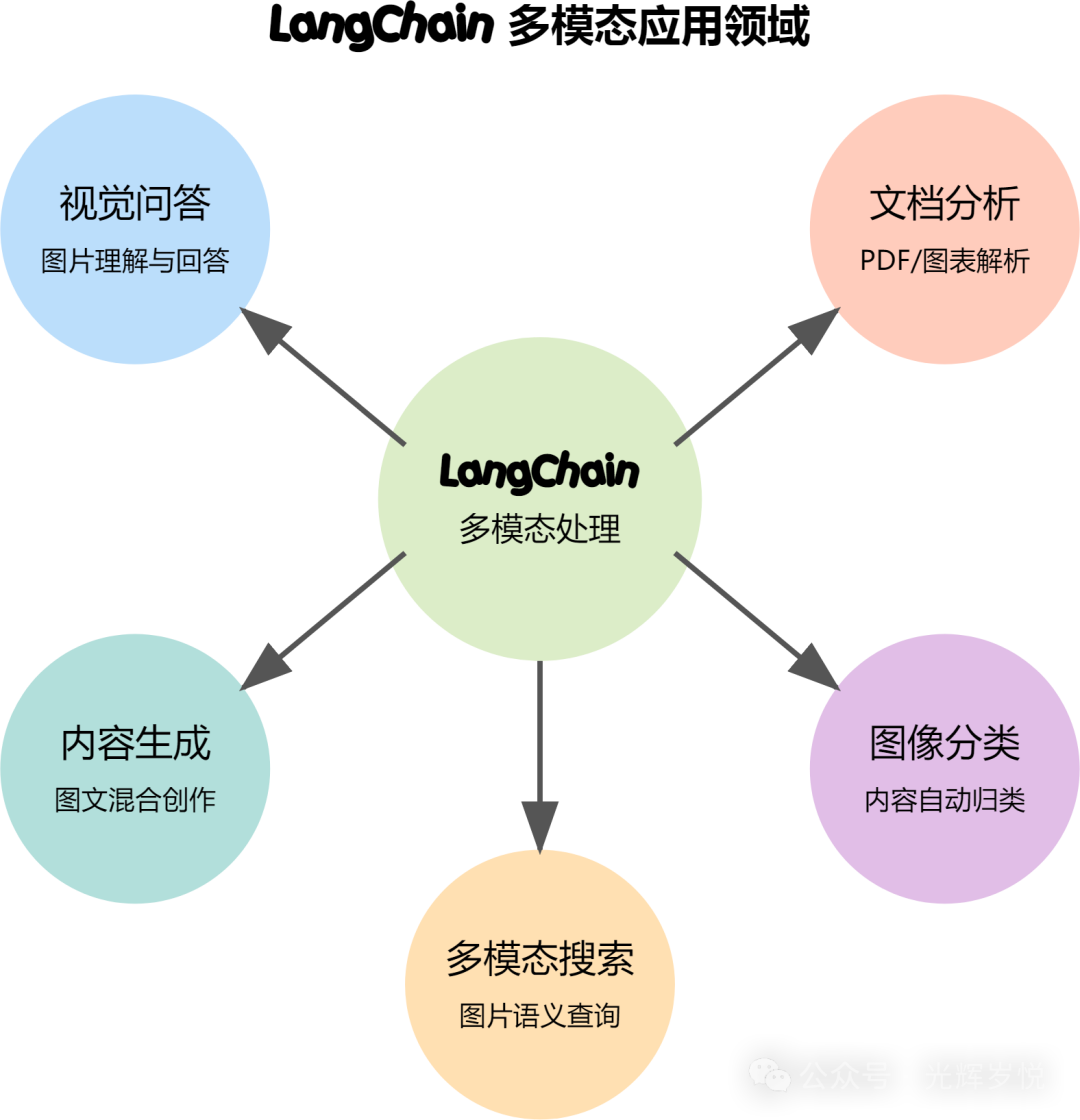
注意事项
- API密钥需单独配置,别把它提交到代码仓库
- 图片处理很费算力,注意控制批量任务规模
- 多模态模型理解能力有限,复杂图表可能不准确
- 处理大量图片时注意成本控制和请求速率限制
- 本地处理图片前记得检查格式兼容性和大小限制
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









