






1 点的提取及参数初始化
初始化开始先设置第一帧 CoarseInitializer::setFirst,主要步骤包括:
1)生成图像金字塔的内参 CoarseInitializer::makeK;
2)逐层提取一定数量的点(局部梯度大的点),在点的提取过程中通过划分网格来尽可能保证获得的点均匀分布在平面上,另外这里还考虑了点的梯度的均匀分布 PixelSelector::select;
3)初始化点的参数,其中逆深度初始化为1;
4)通过构建kdtree来找到每个点在像素平面上的相邻点 CoarseInitializer::makeNN。
接下来考虑如何根据后来帧的信息完成初始化 CoarseInitializer::trackFrame。
2 误差函数
设第一帧(参考帧)为
I
1
I_1
I1,第二帧(当前帧)为
I
2
I_2
I2,参考坐标系到当前坐标系的相对位姿为
ξ
21
∈
s
e
(
3
)
\mathbf \xi_{21}\in \mathfrak {se}(3)
ξ21∈se(3), 假设参考帧中有一点
p
1
\mathbf p_1
p1(像素坐标,这里及后续都是归一化坐标)被选中,当其深度(逆深度
ρ
1
\rho_1
ρ1,初始化为1)和内参
K
\mathbf K
K(通过事先标定获得)已知时,可以通过一次逆投影变换
π
−
1
(
x
)
\pi^{-1}(\mathbf x)
π−1(x)得到参考帧坐标系下的三维点坐标
P
1
\mathbf P_1
P1:
P
1
=
π
−
1
(
p
1
)
=
K
−
1
p
1
/
ρ
1
(1)
\mathbf P_1=\pi^{-1}(\mathbf p_1) =\mathbf K^{-1}\mathbf p_1/\rho_1 \tag{1}
P1=π−1(p1)=K−1p1/ρ1(1)
其对应于当前帧中的像素坐标
p
2
\mathbf p_2
p2可以经过给定位姿变换后再通过一次投影变换获得:
p
2
=
π
(
exp
(
ξ
21
∧
)
P
1
)
=
π
(
exp
(
ξ
21
∧
)
π
−
1
(
p
1
)
)
(2)
\mathbf p_2=\pi(\exp(\mathbf \xi_{21}^\wedge)\mathbf P_1)=\pi(\exp(\mathbf \xi_{21}^\wedge)\pi^{-1}(\mathbf p_1)) \tag{2}
p2=π(exp(ξ21∧)P1)=π(exp(ξ21∧)π−1(p1))(2)
由于直接法严重依赖光照不变性假设,DSO在误差函数中加入了光度变换参数
[
a
,
b
]
T
[a,b]^T
[a,b]T来增强系统的可靠性,即理想情况下,所有追踪的点在前后两帧中满足:
I
2
(
p
2
)
=
exp
(
a
)
I
1
(
p
1
)
+
b
(3)
I_2(\mathbf p_2)=\exp(a)I_1(\mathbf p_1)+b \tag{3}
I2(p2)=exp(a)I1(p1)+b(3)
这里的
[
a
,
b
]
T
[a,b]^T
[a,b]T当然是相对值了,这里的
exp
(
a
)
\exp(a)
exp(a)等效于原文公式(4)中的
t
j
exp
(
a
j
)
t
i
exp
(
a
i
)
\frac{t_j\exp(a_j)}{t_i\exp(a_i)}
tiexp(ai)tjexp(aj),因此当曝光时间
t
1
,
t
2
t_1,t_2
t1,t2已知时,可以将其转化为对数形式,作为
a
a
a的初值,即
a
=
log
(
t
2
/
t
1
)
a=\log(t_2/t_1)
a=log(t2/t1),然后根据光照不变假设可以定义单个点的误差
r
(
p
1
)
=
I
2
(
p
2
)
−
exp
(
a
)
I
1
(
p
1
)
−
b
(4)
r(\mathbf p_1)=I_2(\mathbf p_2)-\exp(a)I_1(\mathbf p_1)-b \tag{4}
r(p1)=I2(p2)−exp(a)I1(p1)−b(4)
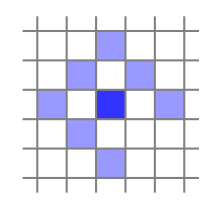
当然,单个点的区分度太小,因此DSO选取了一个包含8个点的小块,如图1所示
对每个点的误差加权求和之后得到整体的残差能量函数(Huber范数形式):
E
p
=
∑
p
1
∈
N
(
p
)
w
p
∥
I
2
(
p
2
)
−
exp
(
a
)
I
1
(
p
1
)
−
b
∥
γ
=
∑
p
1
∈
N
(
p
)
w
p
H
(
r
(
p
1
)
)
(5)
E_{\mathbf p}=\sum_{\mathbf p_1 \in \mathcal N(\mathbf p)}w_{\mathbf p}\|I_2(\mathbf p_2)-\exp(a)I_1(\mathbf p_1)-b\|_\gamma=\sum_{\mathbf p_1 \in \mathcal N(\mathbf p)}w_{\mathbf p}H(r(\mathbf p_1)) \tag{5}
Ep=p1∈N(p)∑wp∥I2(p2)−exp(a)I1(p1)−b∥γ=p1∈N(p)∑wpH(r(p1))(5)
其中
w
p
=
c
2
c
2
+
∥
∇
I
(
p
)
∥
2
2
(6)
w_{\mathbf p}=\frac {c^2} {c^2+\|\nabla I(\mathbf p)\|_2^2 } \tag{6}
wp=c2+∥∇I(p)∥22c2(6)
用来降低高梯度点的权重。
Huber范数可以写成如下形式:
H
(
r
)
=
{
r
2
/
2
,
∣
r
∣
<
σ
σ
(
∣
r
∣
−
σ
/
2
)
,
∣
r
∣
>
=
σ
(7)
H(r) = \left\{ \begin{array}{ll} r^2/2 & \textrm{$,|r|<\sigma$}\\ \sigma(|r|-\sigma/2) & \textrm{$,|r|>=\sigma$} \end{array} \right. \tag{7}
H(r)={r2/2σ(∣r∣−σ/2),∣r∣<σ,∣r∣>=σ(7)
其中
σ
\sigma
σ是一个常数,在DSO源码中被设为9。为了和代码一致,设
w
h
=
{
1
,
∣
r
∣
<
σ
σ
/
∣
r
∣
,
∣
r
∣
>
=
σ
(8)
w_h = \left\{ \begin{array}{ll} 1 & \textrm{$,|r|<\sigma$}\\ \sigma/|r| & \textrm{$,|r|>=\sigma$} \end{array} \right. \tag{8}
wh={1σ/∣r∣,∣r∣<σ,∣r∣>=σ(8)
这样公式(7)就变成了
H
(
r
)
=
w
h
r
2
(
1
−
w
h
/
2
)
(9)
H(r)=w_hr^2(1-w_h/2) \tag{9}
H(r)=whr2(1−wh/2)(9)
对参考帧中所有能投影到当前帧的点的误差进行累加,就得到了总的误差函数:
E
=
∑
E
p
(10)
E=\sum {E_{\mathbf p}} \tag{10}
E=∑Ep(10)
3 高斯牛顿法
高斯牛顿法是求解非线性最小二乘问题的一种常见方法,在非线性误差函数无法通过直接求导得到极值时,通过将该非线性误差函数一阶泰勒展开,寻找最优的状态增量,使整个误差函数逐步下降直至收敛。由于使用了Huber核函数,根据公式(9),我们将误差函数定义为:
f
(
x
)
=
w
h
r
=
w
h
(
I
2
(
p
2
)
−
exp
(
a
)
I
1
(
p
1
)
−
b
)
(11)
f(\mathbf x)=\sqrt {w_h} r=\sqrt {w_h} (I_2(\mathbf p_2)-\exp(a)I_1(\mathbf p_1)-b) \tag {11}
f(x)=whr=wh(I2(p2)−exp(a)I1(p1)−b)(11)
这里是为了凑出一个平方项的形式,因为高斯牛顿法只能求解最小二乘问题,而公式(9)后面部分我理解为小量忽略了,另外,这里似乎是把
w
h
\sqrt {w_h}
wh看做了常数,不然
f
(
x
)
f(\mathbf x)
f(x)在分界点就无法求导了。明确一下初始化过程要求解的参数:两帧图像的之间的相对位姿
ξ
21
\mathbf \xi_{21}
ξ21和光度参数
a
,
b
a,b
a,b共8个参数,加上
N
N
N个点在参考帧中的逆深度
ρ
1
\rho_1
ρ1,共
N
+
8
N+8
N+8个参数。由于后续求导时采用了扰动模型,这里设状态变量
x
=
[
ρ
1
(
1
)
,
.
.
.
,
ρ
1
(
N
)
,
ϵ
T
,
a
,
b
]
(
N
+
8
)
×
1
T
=
[
x
α
,
x
β
]
T
\mathbf x=[\rho_1^{(1)},...,\rho_1^{(N)},\epsilon^T,a,b]^T_{(N+8)\times1}=[\mathbf x_\alpha,\mathbf x_\beta]^T
x=[ρ1(1),...,ρ1(N),ϵT,a,b](N+8)×1T=[xα,xβ]T,其中
ϵ
\epsilon
ϵ是位姿增量。
3.1 雅克比矩阵
3.1.1 光度参数求导
∂
f
(
x
)
∂
a
=
−
w
h
exp
(
a
)
I
1
(
p
1
)
(12)
\frac {\partial f(\mathbf x)}{\partial a}=-\sqrt {w_h}\exp(a)I_1(\mathbf p_1) \tag {12}
∂a∂f(x)=−whexp(a)I1(p1)(12)
∂
f
(
x
)
∂
b
=
−
w
h
(13)
\frac {\partial f(\mathbf x)}{\partial b}=-\sqrt {w_h} \tag {13}
∂b∂f(x)=−wh(13)
3.1.2 相对位姿求导
采用左乘扰动模型,对位姿的增量
ϵ
\epsilon
ϵ求导,根据链式法则:
∂
f
(
x
)
∂
ϵ
=
∂
f
(
x
)
∂
p
2
∂
p
2
∂
ϵ
(14)
\frac {\partial f(\mathbf x)}{\partial \epsilon}=\frac {\partial f(\mathbf x)}{\partial \mathbf p_2}\frac {\partial \mathbf p_2}{\partial \epsilon} \tag {14}
∂ϵ∂f(x)=∂p2∂f(x)∂ϵ∂p2(14)
设
▽
I
x
,
▽
I
y
\bigtriangledown I_x, \bigtriangledown I_y
▽Ix,▽Iy分别为
p
2
\mathbf p_2
p2处的水平和垂直方向上的梯度,则第一部分
∂
f
(
x
)
∂
p
2
=
w
h
∂
I
2
(
p
2
)
∂
p
2
=
w
h
[
▽
I
x
▽
I
y
]
(15)
\frac {\partial f(\mathbf x)}{\partial \mathbf p_2}=\sqrt {w_h}\frac {\partial I_2(\mathbf p_2)}{\partial \mathbf p_2}=\sqrt {w_h} \begin{bmatrix} \bigtriangledown I_x & \bigtriangledown I_y\end{bmatrix} \tag {15}
∂p2∂f(x)=wh∂p2∂I2(p2)=wh[▽Ix▽Iy](15)
第二部分同样根据链式法则有:
∂
p
2
∂
ϵ
=
∂
p
2
∂
P
2
∂
P
2
∂
ϵ
(16)
\frac {\partial \mathbf p_2}{\partial \epsilon}=\frac {\partial \mathbf p_2}{\partial \mathbf P_2}\frac {\partial \mathbf P_2}{\partial \epsilon} \tag {16}
∂ϵ∂p2=∂P2∂p2∂ϵ∂P2(16)
其中,先看第一部分,关于像素坐标和空间坐标的关系,通过相机模型可知(见公式(1))
[
u
2
v
2
1
]
=
ρ
2
[
f
x
0
c
x
0
f
y
c
y
0
0
1
]
[
X
2
Y
2
Z
2
]
(17)
\begin{bmatrix}u_2\\v_2\\1\end{bmatrix}=\rho_2 \begin{bmatrix} f_x & 0 & c_x\\ 0 & f_y & c_y\\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix}X_2\\Y_2\\Z_2\end{bmatrix} \tag {17}
⎣⎡u2v21⎦⎤=ρ2⎣⎡fx000fy0cxcy1⎦⎤⎣⎡X2Y2Z2⎦⎤(17)
这里
ρ
2
=
1
/
Z
2
\rho_2=1/Z_2
ρ2=1/Z2,
P
2
=
[
X
2
,
Y
2
,
Z
2
]
T
\mathbf P_2=[X_2,Y_2,Z_2]^T
P2=[X2,Y2,Z2]T,因此不考虑齐次项的话,
∂
p
2
∂
P
2
=
[
∂
u
2
∂
X
2
∂
u
2
∂
Y
2
∂
u
2
∂
Z
2
∂
v
2
∂
X
2
∂
v
2
∂
Y
2
∂
v
2
∂
Z
2
]
=
[
ρ
2
f
x
0
−
ρ
2
2
f
x
X
2
0
ρ
2
f
y
−
ρ
2
2
f
y
Y
2
]
(18)
\frac {\partial \mathbf p_2}{\partial \mathbf P_2}= \begin{bmatrix} \frac {\partial u_2}{\partial X_2} & \frac {\partial u_2}{\partial Y_2} & \frac {\partial u_2}{\partial Z_2} \\ \frac {\partial v_2}{\partial X_2} & \frac {\partial v_2}{\partial Y_2} & \frac {\partial v_2}{\partial Z_2} \end{bmatrix}= \begin{bmatrix} \rho_2 f_x & 0 & -\rho_2^2f_xX_2 \\ 0 & \rho_2 f_y & -\rho_2^2f_yY_2 \end{bmatrix} \tag {18}
∂P2∂p2=[∂X2∂u2∂X2∂v2∂Y2∂u2∂Y2∂v2∂Z2∂u2∂Z2∂v2]=[ρ2fx00ρ2fy−ρ22fxX2−ρ22fyY2](18)
然后考虑第二部分,根据左乘扰动模型,给定一个微小扰动
Δ
T
=
e
x
p
(
δ
ξ
∧
)
\Delta \mathbf T=exp(\delta\mathbf\xi^\land)
ΔT=exp(δξ∧),其中
δ
ξ
=
[
δ
η
,
δ
ϕ
]
T
\delta\mathbf\xi=[\delta\mathbf\eta,\delta\mathbf\phi]^T
δξ=[δη,δϕ]T,则
∂
P
2
∂
ϵ
=
lim
δ
ξ
→
0
e
x
p
(
δ
ξ
∧
)
P
2
−
P
2
δ
ξ
≈
lim
δ
ξ
→
0
(
I
+
δ
ξ
∧
)
P
2
−
P
2
δ
ξ
=
lim
δ
ξ
→
0
δ
ξ
∧
P
2
δ
ξ
=
lim
δ
ξ
→
0
[
δ
ϕ
∧
δ
η
0
T
0
]
[
P
2
1
]
δ
ξ
=
[
I
−
P
2
∧
0
T
0
T
]
(19)
\begin{aligned} \frac {\partial \mathbf P_2}{\partial \epsilon} &=\lim_{\delta\mathbf\xi \to \mathbf 0} \frac {exp(\delta\mathbf\xi^\land)\mathbf P_2-\mathbf P_2}{\delta\mathbf\xi}\\ &\approx\lim_{\delta\mathbf\xi \to \mathbf 0} \frac {(\mathbf I+\delta\mathbf\xi^\land)\mathbf P_2-\mathbf P_2}{\delta\mathbf\xi}\\ &=\lim_{\delta\mathbf\xi \to \mathbf 0} \frac {\delta\mathbf\xi^\land \mathbf P_2}{\delta\mathbf\xi}\\ &=\lim_{\delta\mathbf\xi \to \mathbf 0} \frac {\begin{bmatrix} \delta\phi^\land & \delta\eta \\ \mathbf 0^T & 0\end{bmatrix}\begin{bmatrix} \mathbf P_2 \\ 1\end{bmatrix}}{\delta\mathbf\xi} \\ &=\begin{bmatrix}\mathbf I & -\mathbf P_2^{\land} \\\ \mathbf 0^T & \mathbf 0^T\end{bmatrix} \end{aligned} \tag {19}
∂ϵ∂P2=δξ→0limδξexp(δξ∧)P2−P2≈δξ→0limδξ(I+δξ∧)P2−P2=δξ→0limδξδξ∧P2=δξ→0limδξ[δϕ∧0Tδη0][P21]=[I 0T−P2∧0T](19)
注意中间有一次齐次变换,如果是非齐次式的形式的话,
∂
P
2
∂
ϵ
=
[
I
−
P
2
∧
]
=
[
1
0
0
0
Z
2
−
Y
2
0
1
0
−
Z
2
0
X
2
0
0
1
Y
2
−
X
2
0
]
(20)
\frac {\partial \mathbf P_2}{\partial \epsilon}= \begin{bmatrix}\mathbf I & -\mathbf P_2^{\land} \end{bmatrix}= \begin{bmatrix} 1&0&0&0&Z_2&-Y_2\\ 0&1&0&-Z_2&0&X_2\\ 0&0&1&Y_2&-X_2&0 \end{bmatrix} \tag{20}
∂ϵ∂P2=[I−P2∧]=⎣⎡1000100010−Z2Y2Z20−X2−Y2X20⎦⎤(20)
结合公式(18)和(20),公式(16)变为了
∂
p
2
∂
ϵ
=
[
ρ
2
f
x
0
−
ρ
2
2
f
x
X
2
−
ρ
2
2
f
x
X
2
Y
2
f
x
+
ρ
2
2
f
x
X
2
2
−
ρ
2
f
x
Y
2
0
ρ
2
f
y
−
ρ
2
2
f
y
Y
2
−
f
y
−
ρ
2
2
f
y
Y
2
2
ρ
2
2
f
y
X
2
Y
2
ρ
2
f
y
x
2
]
=
[
ρ
2
f
x
0
−
ρ
2
f
x
u
2
′
−
f
x
u
2
′
v
2
′
f
x
+
f
x
u
′
2
2
−
f
x
v
2
′
0
ρ
2
f
y
−
ρ
2
f
y
v
2
′
−
f
y
−
f
y
v
′
2
2
f
y
u
2
′
v
2
′
f
y
u
2
′
]
(21)
\begin{aligned} \frac {\partial \mathbf p_2}{\partial \epsilon} &= \begin{bmatrix} \rho_2 f_x & 0 & -\rho_2^2f_xX_2 & -\rho_2^2f_xX_2Y_2 & f_x+\rho_2^2f_xX_2^2 &-\rho_2 f_xY_2\\ 0 & \rho_2 f_y & -\rho_2^2f_yY_2 & -f_y-\rho_2 ^2f_yY_2^2 & \rho_2^2f_yX_2Y_2 & \rho_2 f_yx_2 \end{bmatrix}\\ &= \begin{bmatrix} \rho_2 f_x & 0 & -\rho_2 f_xu'_2 & -f_xu'_2v'_2 & f_x+f_x{u'}_2^2 & -f_xv'_2\\ 0 & \rho_2 f_y & -\rho_2 f_yv'_2 & -f_y-f_y{v'}_2^2 & f_yu'_2v'_2 & f_yu'_2 \end{bmatrix} \end{aligned} \tag {21}
∂ϵ∂p2=[ρ2fx00ρ2fy−ρ22fxX2−ρ22fyY2−ρ22fxX2Y2−fy−ρ22fyY22fx+ρ22fxX22ρ22fyX2Y2−ρ2fxY2ρ2fyx2]=[ρ2fx00ρ2fy−ρ2fxu2′−ρ2fyv2′−fxu2′v2′−fy−fyv′22fx+fxu′22fyu2′v2′−fxv2′fyu2′](21)
其中
u
2
′
=
X
2
/
Z
2
u'_2=X_2/Z_2
u2′=X2/Z2,
v
2
′
=
Y
2
/
Z
2
v'_2=Y_2/Z_2
v2′=Y2/Z2,为归一化坐标。
结合公式(15)和(21),公式(14)变为了
∂
f
(
x
)
∂
ϵ
=
w
h
[
▽
I
x
ρ
2
f
x
▽
I
y
ρ
2
f
y
−
ρ
2
(
▽
I
x
f
x
u
2
′
−
▽
I
y
f
y
v
2
′
)
−
▽
I
x
f
x
u
2
′
v
2
′
−
▽
I
y
f
y
(
1
+
v
′
2
2
)
▽
I
x
f
x
(
1
+
u
′
2
2
)
+
▽
I
y
f
y
u
2
′
v
2
′
−
▽
I
x
f
x
v
2
′
+
▽
I
y
f
y
u
2
′
]
T
(22)
\frac {\partial f(\mathbf x)}{\partial \epsilon}=\sqrt {w_h} \begin{bmatrix} \bigtriangledown I_x\rho_2 f_x \\ \bigtriangledown I_y\rho_2 f_y \\ -\rho_2(\bigtriangledown I_x f_xu'_2-\bigtriangledown I_yf_yv'_2) \\ -\bigtriangledown I_xf_xu'_2v'_2-\bigtriangledown I_yf_y(1+{v'}_2^2) \\ \bigtriangledown I_xf_x(1+{u'}_2^2)+\bigtriangledown I_yf_yu'_2v'_2 \\ -\bigtriangledown I_xf_xv'_2+\bigtriangledown I_yf_yu'_2 \end{bmatrix}^T \tag {22}
∂ϵ∂f(x)=wh⎣⎢⎢⎢⎢⎢⎢⎡▽Ixρ2fx▽Iyρ2fy−ρ2(▽Ixfxu2′−▽Iyfyv2′)−▽Ixfxu2′v2′−▽Iyfy(1+v′22)▽Ixfx(1+u′22)+▽Iyfyu2′v2′−▽Ixfxv2′+▽Iyfyu2′⎦⎥⎥⎥⎥⎥⎥⎤T(22)
3.1.3 逆深度求导
根据链式法则
∂
f
(
x
)
∂
ρ
1
=
∂
f
(
x
)
∂
p
2
∂
p
2
∂
ρ
1
(23)
\frac {\partial f(\mathbf x)}{\partial \rho_1}=\frac {\partial f(\mathbf x)}{\partial \mathbf p_2}\frac {\partial \mathbf p_2}{\partial \rho_1} \tag{23}
∂ρ1∂f(x)=∂p2∂f(x)∂ρ1∂p2(23)
第一部分已有公式(15)给出,第二部分继续分解:
∂
p
2
∂
ρ
1
=
∂
p
2
∂
P
2
∂
P
2
∂
ρ
1
(24)
\frac {\partial \mathbf p_2}{\partial \rho_1}=\frac {\partial \mathbf p_2}{\partial \mathbf P_2}\frac {\partial \mathbf P_2}{\partial \rho_1} \tag {24}
∂ρ1∂p2=∂P2∂p2∂ρ1∂P2(24)
其中第一部分已经在式(18)中得到,现考虑第二部分,已知
P
2
=
R
K
−
1
P
1
/
ρ
1
+
t
(25)
\mathbf P_2=\mathbf R\mathbf K^{-1}\mathbf P_1/\rho_1+\mathbf t \tag {25}
P2=RK−1P1/ρ1+t(25)
则
∂
P
2
∂
ρ
1
=
−
R
K
−
1
P
1
ρ
1
2
=
−
ρ
1
−
1
(
P
2
−
t
)
=
−
ρ
1
−
1
[
X
2
−
t
x
Y
2
−
t
y
Z
2
−
t
z
]
T
(26)
\frac {\partial \mathbf P_2}{\partial \rho_1}=-\frac {\mathbf R\mathbf K^{-1}\mathbf P_1}{\rho_1^2}=-\rho_1^{-1}(\mathbf P_2-\mathbf t)=-\rho_1^{-1}\begin{bmatrix} X_2-t_x & Y_2-t_y & Z_2-t_z \end{bmatrix}^T \tag{26}
∂ρ1∂P2=−ρ12RK−1P1=−ρ1−1(P2−t)=−ρ1−1[X2−txY2−tyZ2−tz]T(26)
结合公式(18)和(26),公式(24)变为了
∂
p
2
∂
ρ
1
=
−
ρ
1
−
1
ρ
2
[
f
x
(
u
2
′
t
z
−
t
x
)
f
y
(
v
2
′
t
z
−
t
y
)
]
(27)
\frac {\partial \mathbf p_2}{\partial \rho_1}=-\rho_1^{-1}\rho_2 \begin{bmatrix} f_x(u'_2t_z-t_x)\\ f_y(v'_2t_z-t_y) \end{bmatrix} \tag{27}
∂ρ1∂p2=−ρ1−1ρ2[fx(u2′tz−tx)fy(v2′tz−ty)](27)
带入公式(23)得
∂
f
(
x
)
∂
ρ
1
=
w
h
ρ
1
−
1
ρ
2
(
▽
I
x
f
x
(
t
x
−
u
2
′
t
z
)
+
▽
I
y
f
y
(
t
y
−
v
2
′
t
z
)
)
(28)
\frac {\partial f(\mathbf x)}{\partial \rho_1}=\sqrt {w_h}\rho_1^{-1}\rho_2(\bigtriangledown I_xf_x(t_x-u'_2t_z)+\bigtriangledown I_yf_y(t_y-v'_2t_z)) \tag{28}
∂ρ1∂f(x)=whρ1−1ρ2(▽Ixfx(tx−u2′tz)+▽Iyfy(ty−v2′tz))(28)
另外,并不是所有点都对逆深度求导的,代码中不断地对每一个点进行分类,判断当前点是否是一个足够好的点。基本逻辑如下:
(1) 所有点初始化时被标记为good;
(2) 在计算每个点的雅克比时,如果点落在平面外,bad;点落在平面内,但得到的残差和大于阈值,bad;
(3) 只有good的点的雅克比才会被归入到总的雅克比中参与增量方程的求解;
(4)在coarse到fine的过程中,每次开始时,如果bad的点在上一层中存在good的点,则继承该点(parent)的逆深度,并设为good;
(5) 在得到增量后,对good的点进行逆深度更新。
综上,我们已经得到了误差函数关于变量
x
α
\mathbf x_\alpha
xα的雅克比矩阵
J
α
=
[
∂
f
(
x
)
∂
ρ
1
(
1
)
,
.
.
.
,
∂
f
(
x
)
∂
ρ
1
(
N
)
]
1
×
N
\mathbf J_\alpha=[\frac {\partial f(\mathbf x)}{\partial \rho_1^{(1)}},...,\frac {\partial f(\mathbf x)}{\partial \rho_1^{(N)}}]_{1\times N}
Jα=[∂ρ1(1)∂f(x),...,∂ρ1(N)∂f(x)]1×N,关于变量
x
β
\mathbf x_\beta
xβ的雅克比矩阵
J
β
=
[
∂
f
(
x
)
∂
ϵ
,
∂
f
(
x
)
∂
a
,
∂
f
(
x
)
∂
b
]
1
×
8
\mathbf J_\beta=[\frac {\partial f(\mathbf x)}{\partial \epsilon},\frac {\partial f(\mathbf x)}{\partial a},\frac {\partial f(\mathbf x)}{\partial b}]_{1\times8}
Jβ=[∂ϵ∂f(x),∂a∂f(x),∂b∂f(x)]1×8,因此总的雅克比矩阵为
J
=
[
J
α
,
J
β
]
1
×
(
N
+
8
)
\mathbf J=[\mathbf J_\alpha,\mathbf J_\beta]_{1\times(N+8)}
J=[Jα,Jβ]1×(N+8)。
3.2 增量方程
将误差函数在当前状态一阶展开
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
J
Δ
x
(29)
f(\mathbf x+\Delta \mathbf x)\approx f(\mathbf x)+\mathbf J\Delta \mathbf x \tag{29}
f(x+Δx)≈f(x)+JΔx(29)
带入能量函数中,并对增量求微分
∂
1
2
f
2
(
x
+
Δ
x
)
∂
Δ
x
=
f
(
x
+
Δ
x
)
∂
f
(
x
+
Δ
x
)
∂
Δ
x
≈
(
f
(
x
)
+
J
Δ
x
)
J
(30)
\frac {\partial \frac 12f^2(\mathbf x+\Delta \mathbf x) }{\partial \Delta \mathbf x}=f(\mathbf x+\Delta \mathbf x)\frac {\partial f(\mathbf x+\Delta \mathbf x) }{\partial \Delta \mathbf x}\approx (f(\mathbf x)+\mathbf J\Delta \mathbf x)\mathbf J \tag{30}
∂Δx∂21f2(x+Δx)=f(x+Δx)∂Δx∂f(x+Δx)≈(f(x)+JΔx)J(30)
令该式等于0即得到增量方程
J
T
J
Δ
x
=
−
J
T
f
(
x
)
(31)
\mathbf J^T\mathbf J\Delta \mathbf x=-\mathbf J^Tf(\mathbf x) \tag {31}
JTJΔx=−JTf(x)(31)
令
H
=
∑
J
T
J
,
g
=
−
∑
J
T
f
(
x
)
\mathbf H=\sum \mathbf J^T\mathbf J,\mathbf g=-\sum \mathbf J^Tf(\mathbf x)
H=∑JTJ,g=−∑JTf(x),则增量方程变为
H
Δ
x
=
g
(32)
\mathbf H\Delta \mathbf x=\mathbf g \tag{32}
HΔx=g(32)
求解增量方程就可以得到最优的增量
Δ
x
∗
\Delta \mathbf x^*
Δx∗,然后对状态进行更新,比如对相对位姿进行更新:
e
x
p
(
ξ
21
∧
)
←
e
x
p
(
Δ
x
β
1
:
6
∗
∧
)
e
x
p
(
ξ
21
∧
)
(33)
exp(\mathbf \xi_{21}^{\land})\gets exp(\Delta {\mathbf {x_\beta}^*_{1:6}}^{\land})exp(\mathbf \xi_{21}^{\land}) \tag {33}
exp(ξ21∧)←exp(Δxβ1:6∗∧)exp(ξ21∧)(33)
需要注意的是,DSO在初始化过程中似乎是固定了光度参数,没有对
a
,
b
a,b
a,b进行更新。雅克比和误差计算的这一部分的代码主要在 CoarseInitializer::calcResAndGS 函数中。
3.3 增量方程的求解
增量方程可以表示为
[
H
α
α
H
α
β
H
β
α
H
β
β
]
[
x
α
x
β
]
=
[
g
α
g
β
]
(34)
\begin{bmatrix} \mathbf H_{\alpha\alpha} & \mathbf H_{\alpha\beta}\\ \mathbf H_{\beta\alpha} & \mathbf H_{\beta\beta} \end{bmatrix} \begin{bmatrix} \mathbf x_{\alpha} \\ \mathbf x_{\beta} \end{bmatrix}= \begin{bmatrix} \mathbf g_{\alpha} \\ \mathbf g_{\beta} \end{bmatrix} \tag{34}
[HααHβαHαβHββ][xαxβ]=[gαgβ](34)
其中,
H
α
α
=
∑
J
α
T
J
α
\mathbf H_{\alpha\alpha}=\sum \mathbf J_\alpha^T\mathbf J_\alpha
Hαα=∑JαTJα,
H
α
β
=
∑
J
α
T
J
β
\mathbf H_{\alpha\beta}=\sum \mathbf J_\alpha^T\mathbf J_\beta
Hαβ=∑JαTJβ,
H
β
α
=
∑
J
β
T
J
α
\mathbf H_{\beta\alpha}=\sum \mathbf J_\beta^T\mathbf J_\alpha
Hβα=∑JβTJα,
H
β
β
=
∑
J
β
T
J
β
\mathbf H_{\beta\beta}=\sum \mathbf J_\beta^T\mathbf J_\beta
Hββ=∑JβTJβ,
g
α
=
−
∑
J
α
T
f
(
x
)
\mathbf g_\alpha=-\sum \mathbf J_{\alpha}^Tf(\mathbf x)
gα=−∑JαTf(x),
g
β
=
−
∑
J
β
T
f
(
x
)
\mathbf g_\beta=-\sum \mathbf J_{\beta}^Tf(\mathbf x)
gβ=−∑JβTf(x)。
通过Schur Complement进行消元:
[
I
0
−
H
β
α
H
α
α
−
1
I
]
[
H
α
α
H
α
β
H
β
α
H
β
β
]
[
x
α
x
β
]
=
[
I
0
−
H
β
α
H
α
α
−
1
I
]
[
g
α
g
β
]
(35)
\begin{bmatrix} \mathbf I & \mathbf 0\\ -\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1} & \mathbf I \end{bmatrix} \begin{bmatrix} \mathbf H_{\alpha\alpha} & \mathbf H_{\alpha\beta}\\ \mathbf H_{\beta\alpha} & \mathbf H_{\beta\beta} \end{bmatrix} \begin{bmatrix} \mathbf x_{\alpha} \\ \mathbf x_{\beta} \end{bmatrix}= \begin{bmatrix} \mathbf I & \mathbf 0\\ -\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1} & \mathbf I \end{bmatrix} \begin{bmatrix} \mathbf g_{\alpha} \\ \mathbf g_{\beta} \end{bmatrix} \tag{35}
[I−HβαHαα−10I][HααHβαHαβHββ][xαxβ]=[I−HβαHαα−10I][gαgβ](35)
[
H
α
α
H
α
β
0
−
H
β
α
H
α
α
−
1
H
α
β
+
H
β
β
]
[
x
α
x
β
]
=
[
g
α
−
H
β
α
H
α
α
−
1
g
α
+
g
β
]
(36)
\begin{bmatrix} \mathbf H_{\alpha\alpha} & \mathbf H_{\alpha\beta}\\ \mathbf 0 & -\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1}\mathbf H_{\alpha\beta}+\mathbf H_{\beta\beta} \end{bmatrix} \begin{bmatrix} \mathbf x_{\alpha} \\ \mathbf x_{\beta} \end{bmatrix}= \begin{bmatrix} \mathbf g_{\alpha} \\ -\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1}\mathbf g_{\alpha}+\mathbf g_{\beta} \end{bmatrix} \tag{36}
[Hαα0Hαβ−HβαHαα−1Hαβ+Hββ][xαxβ]=[gα−HβαHαα−1gα+gβ](36)
令
H
ϕ
=
H
β
α
H
α
α
−
1
H
α
β
\mathbf H_\phi=\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1}\mathbf H_{\alpha\beta}
Hϕ=HβαHαα−1Hαβ,
g
ϕ
=
H
β
α
H
α
α
−
1
g
α
\mathbf g_\phi=\mathbf H_{\beta\alpha}\mathbf H_{\alpha\alpha}^{-1}\mathbf g_{\alpha}
gϕ=HβαHαα−1gα,则
x
β
=
(
H
β
β
−
H
ϕ
)
−
1
(
g
β
−
g
ϕ
)
(37)
\mathbf x_{\beta}={(\mathbf H_{\beta\beta}-\mathbf H_{\phi})}^{-1}(\mathbf g_{\beta}- \mathbf g_{\phi}) \tag{37}
xβ=(Hββ−Hϕ)−1(gβ−gϕ)(37)
x
α
=
H
α
α
−
1
(
g
ϕ
−
H
α
β
x
β
)
(38)
\mathbf x_{\alpha}=\mathbf H_{\alpha\alpha}^{-1}(\mathbf g_\phi-\mathbf H_{\alpha\beta}\mathbf x_{\beta}) \tag{38}
xα=Hαα−1(gϕ−Hαβxβ)(38)
因为
H
α
α
\mathbf H_{\alpha\alpha}
Hαα是对角矩阵,它的逆就很好求了,也是对角矩阵,对角线上原先不为0倒一下。因此
H
ϕ
,
g
ϕ
\mathbf H_\phi,\mathbf g_\phi
Hϕ,gϕ也很好求了,可以直接通过累加的方式:
H
ϕ
=
∑
1
J
α
J
α
T
(
J
α
T
J
β
)
T
J
α
T
J
β
(39)
\mathbf H_\phi=\sum \frac {1}{\mathbf J_\alpha\mathbf J_\alpha^T}(\mathbf J_\alpha^T\mathbf J_\beta)^T\mathbf J_\alpha^T\mathbf J_\beta \tag{39}
Hϕ=∑JαJαT1(JαTJβ)TJαTJβ(39)
g
ϕ
=
−
∑
1
J
α
J
α
T
(
J
α
T
J
β
)
T
J
α
T
f
(
x
)
(40)
\mathbf g_\phi=-\sum \frac {1}{\mathbf J_\alpha\mathbf J_\alpha^T}(\mathbf J_\alpha^T\mathbf J_\beta)^T\mathbf J_\alpha^Tf(\mathbf x) \tag{40}
gϕ=−∑JαJαT1(JαTJβ)TJαTf(x)(40)
这里的
H
ϕ
,
g
ϕ
\mathbf H_\phi,\mathbf g_\phi
Hϕ,gϕ就是代码中的Hsc,bsc,
H
β
β
,
g
β
\mathbf H_{\beta\beta}, \mathbf g_\beta
Hββ,gβ就是代码中的H,b,此外,DSO在迭代的过程中设置了一个参数lambda来调整下一次的迭代,类似于列文伯格方法中的
λ
\lambda
λ:
(
H
+
λ
D
T
D
)
Δ
x
=
g
(41)
(\mathbf H+\lambda \mathbf D^T\mathbf D)\Delta\mathbf x=\mathbf g \tag{41}
(H+λDTD)Δx=g(41)
最后将得到的增量更新到状态变量上就完成了一次迭代过程。注意点的逆深度以及位姿中的平移分量最后要进行归一化操作。
4 初始化主要流程
参考文献
[1] Engel J, Koltun V, Cremers D. Direct sparse odometry[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(3): 611-625.
[2] 高翔. 视觉 SLAM 十四讲: 从理论到实践[M]. 电子工业出版社, 2017.
[3] JingeTU. 直接法光度误差导数推导[OL]. 博客园, 2018/01/05 [2019/05/24] http://www.cnblogs.com/JingeTU/p/8203606.html.
[4] JingeTU. DSO 优化代码中的 Schur Complement[OL]. 博客园, 2018/01/16 [2019/05/24] https://www.cnblogs.com/JingeTU/p/8297076.html.














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









