






类型转换
类型转换分为隐式类型转换和显示类型转换
隐式类型转换
int和unsigned int之间的隐式类型转换,
int和uint相互转换时二进制表示不变,变的是翻译的方法。int是用补码来表示,最高位是符号位,uint则没有符号位,以32位机器为例,int和uint都是4字节,但是表示范围分别是-231~231-1, 0~232-1。如果执行下列语句:
unsigned int u=4294967295;
int i=u;
cout<<i<<endl;
会输出-1;
原因在于4,294,967,295=232-1,表示为0xFFFFFFFF;转换为int,那么表示还是0xFFFFFFFF,但是第一位变符号位了,翻译过来就变成了-1。这就与我们的本意相差甚远,而且这种错误往往很难发现,避免这种bug的有效方法就是不要混用int和unsigned int。
数组转换为指针
大多数用到数组的表达式中,数组都会自动转换为指针。如:
int a[4]={1,2,3,4};
int *p=a;//a转换为指向数组首元素的指针
但是以下情况例外:
(1)数组被用作decltype的参数
decltype(a) b;//b为数组
(2)数组作为&的运算对象
int (*p)[4] = &a;//使用数组a的引用初始化数组p,这里p是指针,指向存放4个int的数组
(3)数组作为sizeof的运算对象
int size=sizeof(a);//size==4;
(4)数组作为typeid的运算对象
//会输出1,因为a在这里不转换为指针,他的类型是int[4]
if (typeid(a) == typeid(*p))
{
cout << 1;
}
显示类型转换
(1)static_cast:用于非多态类型的转换。
(2)dynamic_cast:用于多态类型的转换。
(3)const_cast:用于删除const、volatile和__unaligned属性。
(4)reinterpret_cast:用于位的简单重解释。
static_cast
任何具有明确定义的类型转换,只要不包含底层const,都可以使用static_cast。
const int a = 1;
int b = static_cast<int>(a);//包含顶层const,合法,但没啥实际意义,因为a还是const int类型,这句话相当于int b=a;
但是如果改成底层const,如下
const int c = 1;
const int *a = &c;
int *b = static_cast<int*>(a);//编译错误!!a指向的是常量,为底层const
既然static_cast无法改变const,那么谁能呢?
const_cast
const_cast能改变运算对象的底层const
const int c = 1;
const int *a=&c;
int *b = const_cast<int*>(a);//正确
*b = 2;//这里书上说是未定义的,但我在VS2017上试了试好像没啥问题,不过为了保险起见还是不要用的好
const_cast主要用在函数重载,如
const string &shorterString(const string &s1,const string &s2)
{
return s1.size()<=s2.size()?s1:s2;
}
这个函数的形参和返回值都是const string的引用,如果我们使用两个非常量的实参string调用这个函数,返回的还是const string,因此我们需要一种新的shorterString函数,当传入非常量实参时,返回的是非常量的引用。
string &shorterString(string &s1,string &s2)
{
auto &r=shorterString(const_cast<const string&>(s1),
const_cast<const string&>(s2));
return const_cast<string&>(r);
}
重载的shorterString函数中,先使用const_cast将s1,s2转换为const string&,然后调用常量版本的shorterString,再将得到的const string&用const_cast转换为string&返回,因为得到的const string&其实是绑定在非常量s1或s2上的,所以这样做是完全安全的。
reinterpret_cast
reinterpret_cast通常为运算对象的位模式提供较低层次上的重新解释。如:
int *ip;
char *pc = reinterpret_cast<char*>(ip);
ip其实是指向int的,使用reinterpret_cast强制转换成char* 之后,相当于告诉编译器pc是指向char的了,但其实他是指向int的,这是如果把pc当成普通的char*使用就可能出现异常的运行时行为。如:
string str(pc);
这里用pc初始化string对象,看起来好像是用char* 初始化string,没啥问题,但是其实pc指向的是int啊,实质上是用int*初始化string,这种操作很可能会发生错误,而且最关键的是这种操作被编译器认为是没有语法问题的,很难debug,所以尽量少用reinterpret_cast。
dynamic_cast
为什么要有dynamic_cast运算符?
考虑这样一个场景:当基类指针指向派生类对象,而我们想通过该指针调用派生类对象里的一个函数,一般情况下,我们会把这个函数设为虚函数,然后直接用基类指针执行调用,这时编译器会在运行时发现基类指针绑定的是派生类对象,会选择派生类对象版本的函数执行。如下
class A {
public:
virtual void f() { cout << "base f"; }
};
class B:public A {
public:
void f() override { cout << "derived f"; }
};
int main() {
B b;
A *a = &b;
a->f();
}
输出结果:
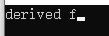
但是,有的时候我们想调用的函数并不是虚函数,这时直接用基类指针调用并不会调用派生类里的函数了。dynamic_cast就可以解决这种问题。
那么dynamic_cast是什么呢?
dynamic_cast其实就是用来实现基类指针(或引用)和派生类指针(或引用)之间互相转换的。
dynamic_cast具体怎么用?可以看下面的例子:
class A {
public:
virtual void f(){ cout << "base f" << endl; }//得有个虚函数,不然A不是多态类型,没法dynamic_cast。
void noVirtual() { cout << "base noVirtual"; }
};
class B:public A {
public:
void noVirtual() { cout << "derived noVirtual"; }
};
int main() {
B b;
A *a = &b;
a->noVirtual();//noVirtual不是虚函数,调用A中的noVirtual
B* da=dynamic_cast<B*>(a);//将a从A*转换为B*,并赋值给da,da绑定的就是B类型对象,并且da本身的静态类型也是B*,所以da会调用B中的noVirtual
da->noVirtual();
}
输出:
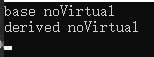
上图中尽管指针a动态绑定了B对象,但是由于noVirtual不是虚函数,所以通过a还是会调用A中的noVirtual。
那我们想通过指针a调用B中的noVirtual函数怎么办呢?需要先将a从A转换为B,并赋值给da,da绑定的就是B类型对象,并且da本身的静态类型也是B*,所以da会调用B中的noVirtual。
类型推导
模板类型推导
一个模板的伪代码表示:
template<typename T>
void f(ParamType param);
f(expr); // call f with some expression
在编译过程中,编译器使用expr来推断T和ParamType的类型。如下:
template<typename T>
void f(const T& param); // ParamType is const T&
int x = 0;
f(x); // call f with an int
T被推断为int,而ParamType被推断为const int&。
很容易想当然的认为T的类型就是expr的类型,但是实际上推断出的T的类型不仅取决于expr的类型,还取决于ParamType的形式。
ParamType有以下三种形式:
(1)指针或者引用但非万能引用
(2)万能引用
(3)既不是指针也不是引用
指针或者引用但非万能引用
•如果expr的类型是引用,忽略引用特性,然后对ParamType进行模式匹配expr的类型来推断T。如:
template<typename T>
void f(T& param);
int x = 27; // x is an int
const int cx = x; // cx is a const int
const int& rx = x; // rx is a reference to x as a const int
f(x); // T is int, param's type is int&
f(cx); // T is const int,
// param's type is const int&
f(rx); // T is const int,
// param's type is const int&
万能引用
•如果expr是左值,那么T和ParamType都推断为左值引用。
这是模板类型推导中T是一个引用的唯一的情况。尽管声明中ParamType使用右值引用的语法,但其推导的类型是左值引用。
•如果expr是一个右值,情况1规则适用。
如:
template<typename T>
void f(T&& param); // param is now a universal reference
int x = 27; // as before
const int cx = x; // as before
const int& rx = x; // as before
f(x); // x is lvalue, so T is int&,
// param's type is also int&
f(cx); // cx is lvalue, so T is const int&,
// param's type is also const int&
f(rx); // rx is lvalue, so T is const int&,
// param's type is also const int&
f(27); // 27 is rvalue, so T is int,
// param's type is therefore int&&
既不是指针也不是引用
既不是指针也不是引用,那么就是按值传递。
template<typename T>
void f(T param); // param is now passed by value
•与前面一样,如果expr的类型是一个引用,则忽略引用部分。
•如果在忽略expr的引用性之后,expr是const,也忽略它。如果它是volatile的,也忽略。
总的来说:
•在模板类型推断期间,实参的引用性被忽略。
•当推导万能引用形参的类型时,如果传入的是左值表达式,那么T和ParamType都被推导为左值引用。
•推导按值传递的参数的类型时,const和/或volatile参数被视为non-const和non-volatile。
•在模板类型推导过程中,数组或函数名作为参数退化为指针,除非它们用于初始化引用。
auto类型推导
•auto类型推导通常与模板类型推导是一样的,但auto类型推导假设括起来的初始化列表的类型为std::initializer_list,而模板类型推导则不这么做。如:
auto x = { 11, 23, 9 }; // x's type is
// std::initializer_list<int>
template<typename T> // template with parameter
void f(T param); // declaration equivalent to
// x's declaration
f({ 11, 23, 9 }); // error! can't deduce type for T
•当auto作为函数返回类型或lambda表达式的参数时,其实用的是模板类型推导。如:
auto createInitList()
{
return { 1, 2, 3 }; // error: can't deduce type
} // for { 1, 2, 3 }
std::vector<int> v;
…
auto resetV =
[&v](const auto& newValue) { v = newValue; }; // C++14
…
resetV({ 1, 2, 3 }); // error! can't deduce type
// for { 1, 2, 3 }
item5:auto比显示类型声明好用
•auto变量必须初始化,一般可以免疫由于类型不匹配带来的可移植性问题或效率问题,且能够使重构进程更轻松,需要打的字也更少
item6:
Use the explicitly typed initializer idiom when auto deduces undesired
types.
•“隐形”的代理类型会导致auto为初始化表达式推导出“错误”的类型
•使用显示类型初始化器强制auto推断出你想要的类型
代理类型例子:
vector<bool>features(const Widget& w);
Widget w;
…
auto highPriority = features(w)[5]; // is w high priority?
…
processWidget(w, highPriority); // undefined behavior!
vector< bool >的[]返回的不是bool&,而是一个代理类型vector< bool >::reference,feartures(w)返回一个vector< bool >临时变量,对这个临时变量调用[]操作,返回vector< bool >::reference赋值给highPriority,当这个语句结束,临时变量被销毁,highPriority就成了一个悬空指针,使用它就会出现未定义的行为。
应该改用 the explicitly typed initializer idiom:
auto highPriority=static_cast< bool >features(w)[5];
理解decltype
•Decltype几乎总是在不做任何修改的情况下生成变量或表达式的类型。
•对于不是名称的左值表达式的类型T,decltype会得到T&类型。
• C++14 支持decltype(auto), 它使用decltype 的规则来进行类型推导
在C++11中,decltype常用在以下情形:
定义一个函数模板,该函数模板的返回值取决于模板的参数类型,如:
我们写一个函数,参数为支持[]操作的容器,和下标i,返回[i]操作的结果。
[]操作大多数时候返回T&类型,比如std::deque,以及绝大多数情况下的std::vector,但有些时候,比如std::vector就不返回bool&。
template<typename Container,typename Index>
auto antuAndAccess(Container&& c,Index i)
-> decltype(std::forward<Container>(c)[i]){
authenticateUser();
return std::forward<Container>(c)[i];
}
这里的auto并不参与类型推导,而是将返回类型推导交给后缀
->decltype(std::forward<Container>(c)[i])
为了使函数模板既能接收左值又能接收右值作为参数,这里c使用了万能引用。
此外,std::forward被用来与万能引用搭配,实现完美转发。














 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









