







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
目录
2.1 DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models (理想)
2.2 Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving (地平线)
2.3 EMMA: End-to-End Multimodal Model for Autonomous Driving (Waymo)
一、前言
- 自动驾驶端到端模型(end-to-end)是什么?
- 将感知、预测、规划和控制任务统一到一个模型中,输入传感器数据(如图像),输出控制指令
- 为什么要结合多模态大模型(VLM)做端到端任务?
- VLM本身具有:1. 视觉理解能力;2. 推理能力
- VLM能帮助理解传统模型理解长尾复杂场景,处理多车博弈情况
- VLM可以给出推理过程和解释
二、近期论文整理
2.1 DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models (理想)
- 要点:1. 设计用于自动驾驶任务的大模型【DriveVLM】;2. 提出VLM和传统端到端模型交互的系统【DriveVLM-Dual】,实现更精细的轨迹规划
- Pipeline:
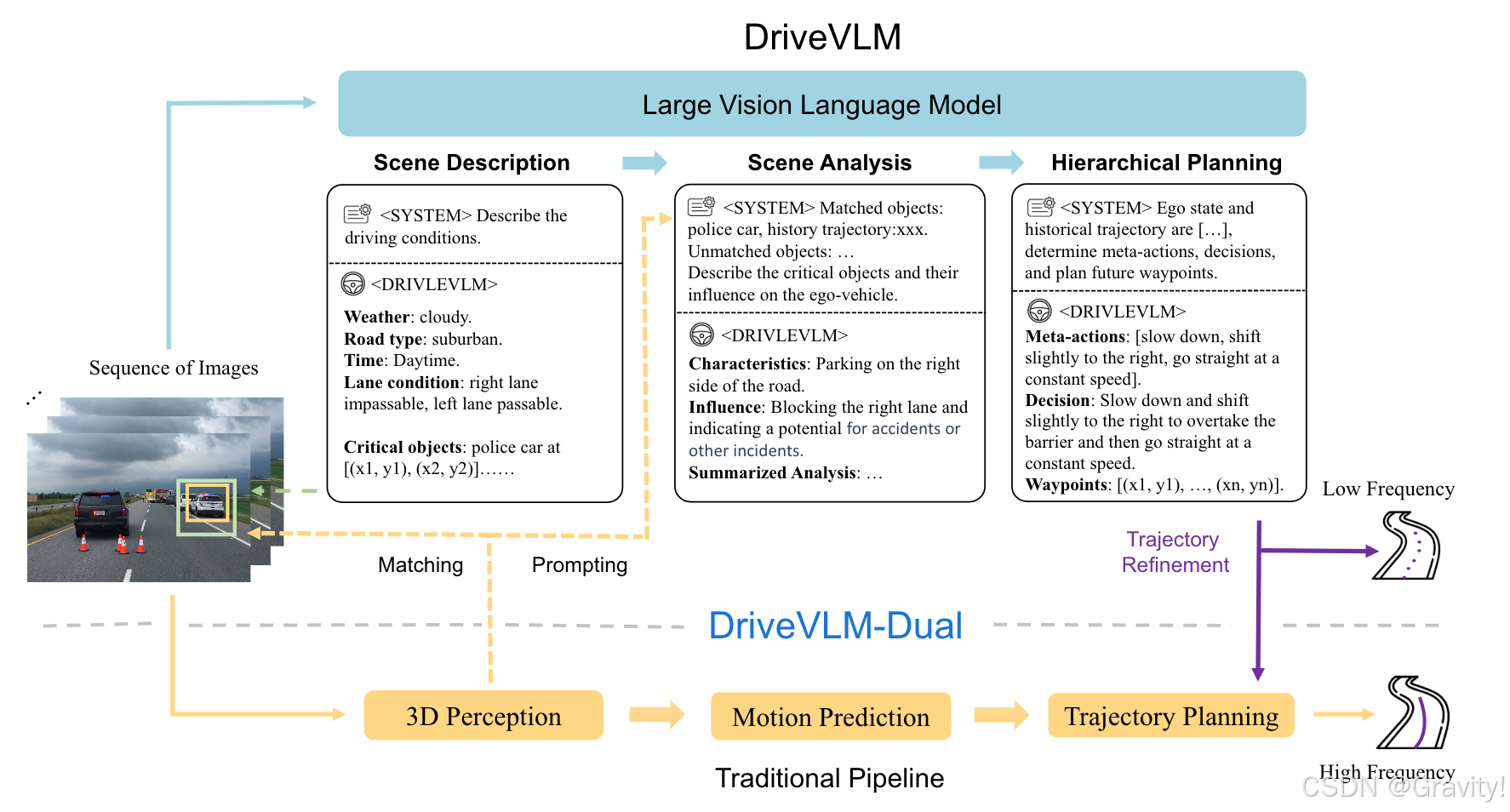
- DriveVLM:
- 思维链(Chain-of-Thought)推理:场景描述 → 场景分析 → 层级规划
- 场景描述
1. 环境:天气、时间、道路类型(如高速、城市)、车道线(自车车道)
2. 关键物体检测:物体类别和目标框 - 场景分析:
- 物体特征:静态属性(本身是什么)、运动状态(方位和动作)、特殊行为(比如交警手势)
- 场景总结【传给下一步规划】
- 层级规划(Hierarchical Planning)
- Prompt提供的信息: 场景总结、路线、自车位姿和速度
- Meta-actions(基本动作)→ 决策描述(物体&动作&持续时间)→ 轨迹点
- DriveVLM-Dual:
- 实现:VLM和传统端到端模型(E2E)协作
- 关键设计1:E2E给VLM提供3D感知信息
- (E2E感知模块输出的)3D物体检测框和(VLM输出的)2D物体检测框匹配
- 匹配上的物体:提供历史轨迹和位置信息给VLM的prompt作补充
【反过来想:对E2E模型,VLM可以补充未匹配上的物体(如长尾物体)信息】
- 关键设计2: 高频轨迹优化
- 快慢系统:在固定重叠时间,VLM轨迹【低频】优化 E2E轨迹【高频】
(E2E模型运行速度比VLM快)
- 快慢系统:在固定重叠时间,VLM轨迹【低频】优化 E2E轨迹【高频】
2.2 Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving (地平线)
- 三个中心问题 & 改进点:
- 怎么结合大模型和端到端?
两个主流思路:1. 直接用VLM输出规划轨迹点和控制信号(问题:大模型不擅长准确数值的预测); 2. 大模型辅助端到端模型(即本篇工作思路)
【改进点:规划过程从high-level动作指令(大模型输出)到low-level的轨迹点(端到端模型输出)】 - 怎么针对驾驶任务设计大模型?
主要问题:环视图会造成图像占用过多的token【改进点:设计更有效的多视图编码策略】 - 如何更有效地训练大模型?
- 当前的自动驾驶数据集不是针对规划任务设计的【提出planning-oriented QAs数据集】
- 传统的“通用预训练再微调”不是最优训练范式【改进点:针对驾驶任务,设计了三阶段的训练策略】
- 怎么结合大模型和端到端?
- QAs数据集(下面是涉及到的任务):
- 感知:场景描述,交通信号检测,弱势道路使用者(如行人、动物)
- 预测:物体动作预测
- 规划:Meta-Actions规划,规划解释【Meta-Actions指high-level动作指令,比如直行、左转、减速】
- Pipeline:
- Senna-VLM:图像序列、用户指令和导航命令【输入】→ Meta-Actions → Encoder → Meta-Actions特征
- Senna-E2E(端到端模型):场景图像 & Meta-Actions特征(规划阶段输入)→ 规划轨迹
【Meta-Actions指导E2E做更准确的轨迹规划】
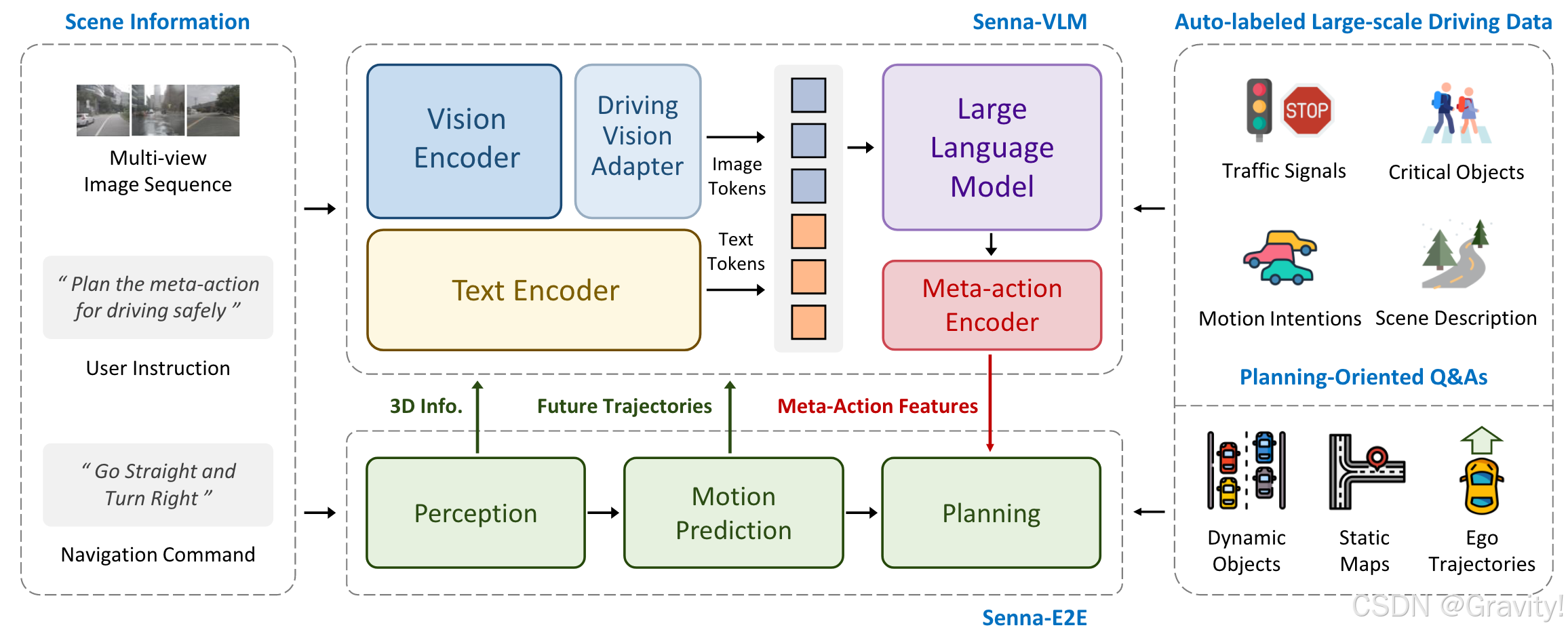
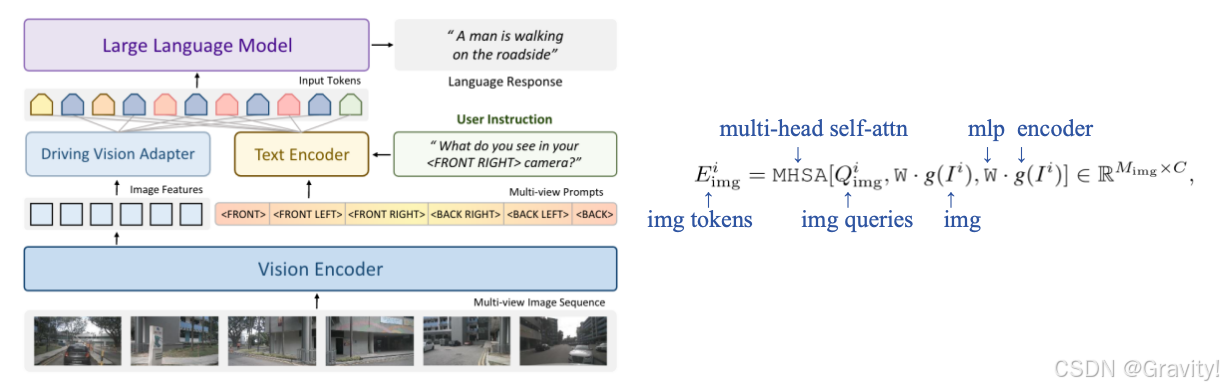
- 核心模块:VLM中的 Driving Vision Adapter
- 作用:1. 将图像特征映射到文本特征空间;2. 进一步编码和压缩图像token
- 用多头自注意力压缩,图像Tokens数量变化: 576×6 → 128×6 (压缩到一个视图128 tokens,共6个相机视角)
- 训练策略:
- Senna-VLM(分三阶段)
- 阶段一 Mix Pretraining:混合多数据集,主要训练Driving Vision Adapter,做特征对齐
- 阶段二 Driving Fine-tuning:用QAs数据集中的感知和预测相关的训练数据微调
- 阶段三 Planning Fine-tuning:用QAs数据集中的规划相关的训练数据微调
(阶段二、三都冻住VLM中的Vision Encoder)
- Senna-E2E:
- 训练时用真值meta-actions,推理时用VLM预测的meta-actions
- Senna-VLM(分三阶段)
2.3 EMMA: End-to-End Multimodal Model for Autonomous Driving (Waymo)
- 思路:用VLM直接做端到端输出,并同时给决策理由
- Pipeline:
环视图 & high-level指令 & 自车历史状态【输入】→ Gemini大模型【两路处理:1. 端到端决策 2. 思维链推理】 → 轨迹点 & 决策过程和理由【输出】
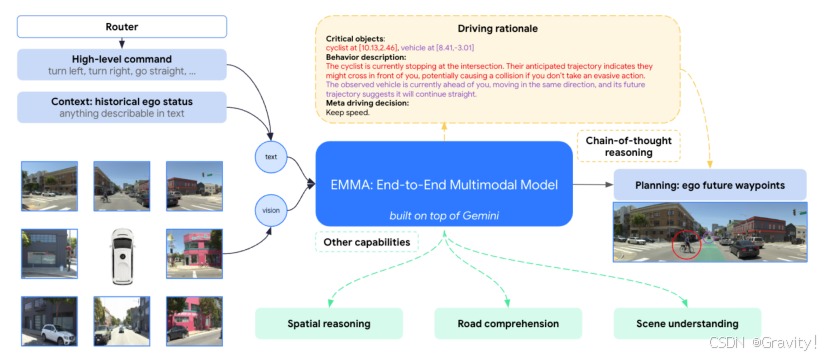
- 核心模块:思维链(Chain-of-Thought) 推理规划过程
- 推理策略:粗糙到精细(coarse-to-fine)
- 推理线路:场景描述 → 重要物体检测(输出坐标)→ 重要物体描述(状态和意图) → 高级驾驶决策(Mata Actions)
- 其他能做的任务(通过混合训练实现)
- 空间推理(3D目标检测任务)
- 关键道路要素检测(道路图)
- 场景理解(检测是否暂时受阻)
2.4 (LeapAD) Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving [NIPS2024]
- 任务:闭环自动驾驶决策系统(不输出轨迹点,只决策动作)
- 为什么做闭环任务?
- 符合现实:人类是在有实时反馈的环境中驾驶并且提升驾驶能力的
- 对系统:让模型有持续学习,不断适应并且进步的能力
- 动机:模仿人类认知过程
- 系统一(快系统):靠直觉和经验得出结果(判断简单事情)
- 系统二(慢系统):靠逻辑推理和分析得出结论(分析复杂情况)
- Pipeline:
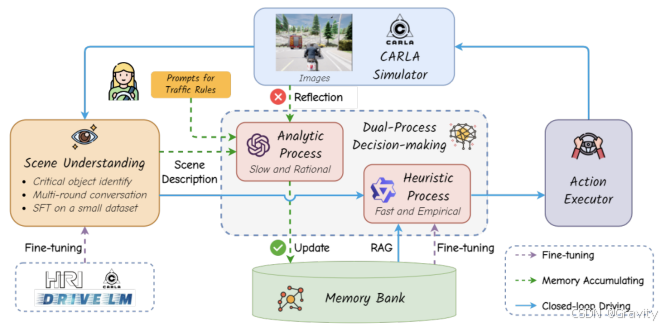
- 分析过程(不参与闭环线路):
- 作用:1. 累积驾驶分析和决策的经验; 2. 遇到事故的时候介入(反思机制)
- 实现:图像 & 场景理解文本 & 交通规则prompt【输入】→ GPT4【推理决策分析】→ 结果存入Memory Bank
- 反思机制(由事故触发):分析事故原因 → 定位事故位置 → 给出正确推理和决策 → 存入Memory Bank
- 启发过程(闭环线路):
- 作用:调用过往经验(Few-shots),对当前场景快速决策
- 过程:图像(From Carla) → Qwen-VLM-7B【场景理解】→ Qwen-1.5-1.8B【从Memory Bank调用相似场景信息,做出规划决策】→ 动作执行 → Carla【闭环】
- 分析过程(不参与闭环线路):
- 模型训练:
- 微调Qwen-VLM-7B(参数量为7B):数据多来源(Carla, DriveLM等),输入图像,学习场景理解
- 微调Qwen-1.5-1.8B(参数量为1.8B):输入场景理解,学习动作决策
三、往期笔记
自动驾驶Occupancy梳理笔记(二):SurroundOcc, OccFormer, VoxFormer, FB-OCC-CSDN博客
自动驾驶Occupancy梳理笔记(三): SelfOcc, SparseOcc(华为&上交), SparseOcc(上海AI Lab), OccWorld_self-occ-CSDN博客
自动驾驶Occupancy梳理笔记(四):GaussianFormer, OSP, ViewFormer, OPUS-CSDN博客

















 1841
1841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









