










24年10月来自华中理工和地平线的论文“Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving”。
端到端自动驾驶凭借大规模数据展示强大的规划能力,但由于常识有限,在复杂、罕见场景中仍举步维艰。相比之下,大型视觉-语言模型 (LVLM) 在场景理解和推理方面表现出色。前进的道路在于融合两种方法的优势。以前使用 LVLM 预测轨迹或控制信号的方法会产生次优结果,因为 LVLM 不适合精确的数值预测。 Senna,是一种结合 LVLM(Senna-VLM)和端到端模型(Senna-E2E)的自动驾驶系统。Senna 将高级规划与低级轨迹预测分离。Senna-VLM 以自然语言生成规划决策,而 Senna-E2E 则预测精确的轨迹。Senna-VLM 采用多图像编码方法和多视图提示来高效理解场景。此外,引入面向规划的问答和三步训练策略,在保留常识的同时,提高 Senna-VLM 的规划性能。在两个数据集上进行的大量实验表明,Senna 实现最先进的规划性能。值得注意的是,通过在大型数据集 DriveX 上进行预训练并在 nuScenes 上进行微调,与未进行预训练的模型相比,Senna 显著降低 27.12% 的平均规划误差和 33.33% 的碰撞率。 Senna 跨场景泛化和可迁移性,对于实现全自动驾驶至关重要。
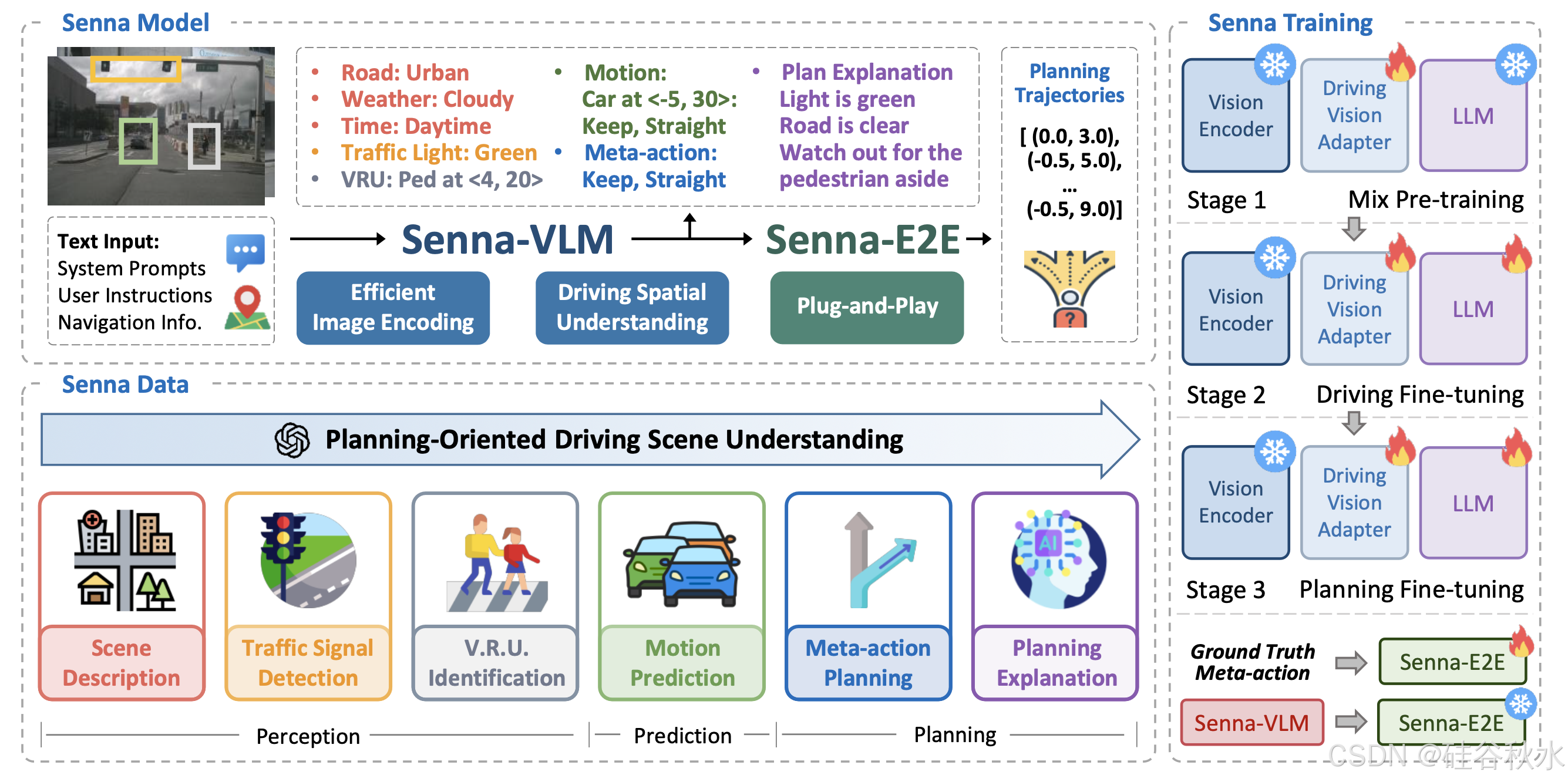
如图所示:Senna 是一个结构化的自动驾驶系统,由大型视觉-语言模型 (Senna-VLM) 和端到端驾驶模型 (Senna-E2E) 组成。Senna-VLM 以自然语言生成高级规划元动作,而 Senna-E2E 则预测低级规划轨迹。设计一系列面向规划的 QA,这些 QA 可以大规模自动标记,并采用三步训练策略,实现对驾驶场景的深刻理解和准确规划。
近年来,自动驾驶发展迅速[1]–[3]。在驾驶感知[4]–[6]、运动预测[7]–[9]和规划[10]–[12]等领域取得了重大进展。这些发展为实现更准确、更安全的驾驶决策奠定了坚实的基础。其中,端到端自动驾驶是一个重大突破。在大规模数据的推动下,端到端方法已经展现出卓越的规划能力。此外,大型视觉-语言模型(LVLM)[13]–[17]已经展现出越来越强大的图像理解和推理能力。通过利用常识和逻辑,LVLM 可以分析驾驶环境并在复杂场景中做出安全决策。利用大量驾驶数据来提高 LVLM 在自动驾驶中的性能,并将 LVLM 与端到端模型连接起来,对于实现安全、稳健和可推广的自动驾驶至关重要。
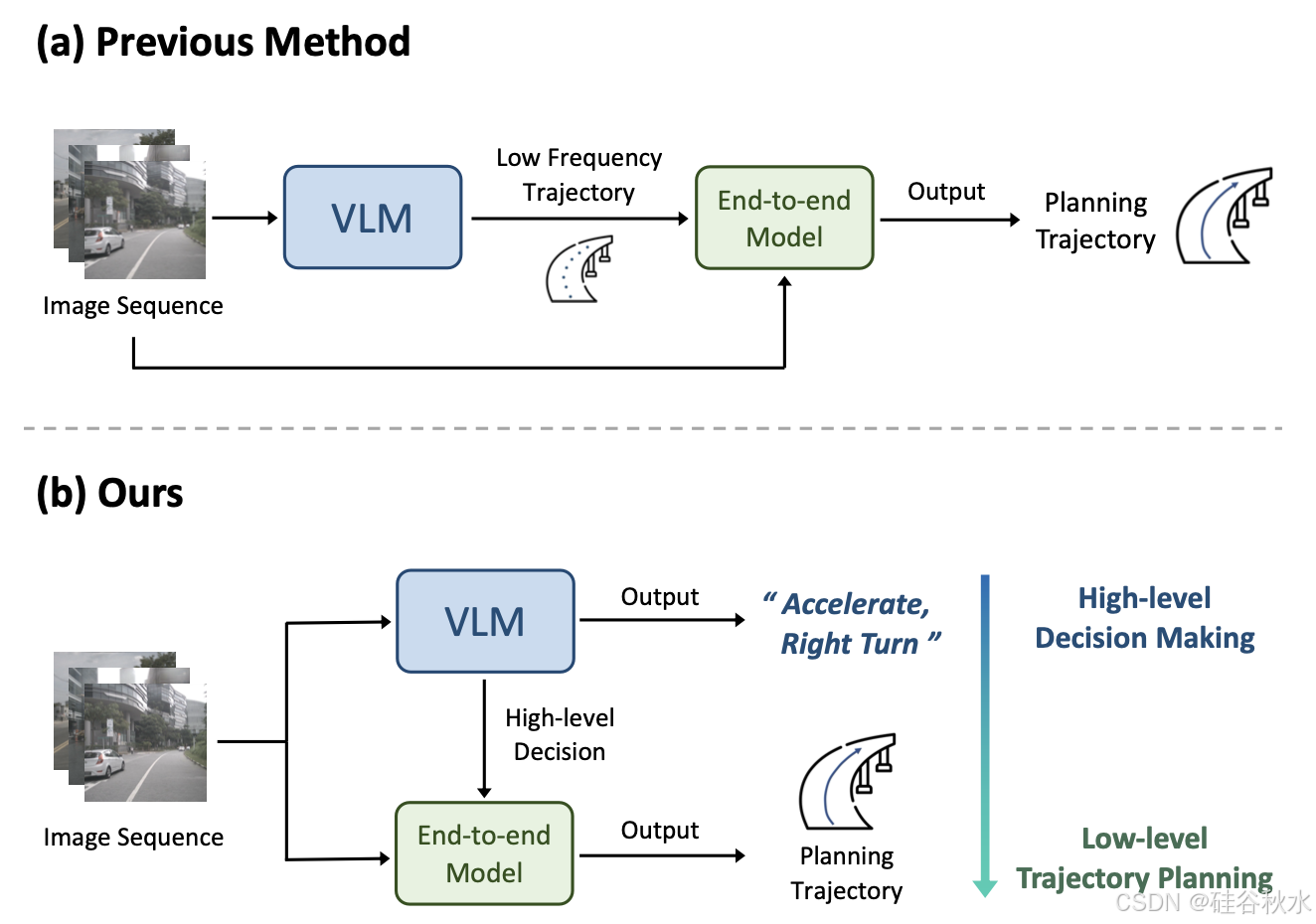
端到端自动驾驶的常见做法是直接预测未来轨迹或控制信号,而无需决策步骤。然而,这种方法可能会使模型学习更加困难,同时缺乏可解释性。相比之下,当人脑做出详细决策时,由分层高级决策和低级执行组成的系统起着至关重要的作用 [18]–[20]。此外,端到端模型通常缺乏常识,在简单场景中可能会出错。例如,它们可能会将载有交通锥的卡车误认为是路障,从而触发不必要的刹车。这些限制阻碍了端到端模型的规划性能。
端到端自动驾驶。传统的自动驾驶系统通常采用分阶段的模块化设计,并采用基于规则的规划器 [35]–[37],这面临着模型泛化能力有限和规划性能上限等挑战。相比之下,端到端自动驾驶利用神经网络将感知输入直接映射到规划输出。早期的研究 [11]、[38]、[39] 将此视为黑盒子方法,尽管缺乏可解释性,但它们展示了神经网络在端到端学习中的潜力。近年来,随着自动驾驶的快速发展,可用驾驶数据的爆炸式增长为端到端方法提供了大量支持 [2]、[3]、[40]–[43]。UniAD [2] 引入一个多任务框架,使用 Transformers [44] 来执行目标跟踪、轨迹预测、地图预测、占用预测和规划。这些辅助任务的额外监督显著提高模型的规划性能。 VAD [3] 引入矢量化场景表示,在准确率和速度之间取得了更好的平衡。VADv2 [43] 进一步提出概率规划,用多模态轨迹评分取代确定性规划,以更好地捕捉规划的不确定性。
大型视觉语言模型。随着表现出强大理解和对话能力的大型语言模型 (LLM) 的出现 [45]–[48],将这种能力从单一文本模态扩展到多模态系统是很自然的,其中视觉模态是最关键的模态之一 [13]–[16]、[28]、[49]、[50]。CLIP [51]、[52] 率先使用图像-文本对进行对比学习,使模型能够以自监督的方式实现大规模预训练。 BLIP [53],[54] 通过跨模态对比学习和生成任务在视觉和语言模型之间架起了桥梁。基于这些跨模态训练策略 [51],[55]-[57],LVLM 取得了一系列进步。GPT-4V [17] 在理解复杂场景和多任务推理方面表现出色。LLaVA [13],[30] 引入了视觉指令调整,利用 GPT-4 生成的语言图像指令跟踪数据进行跨模态学习。QwenVL [14] 在视觉连接器、训练策略和数据方面进行了改进,在多语言理解和 3D 感知方面表现出色。VILA [28] 通过优化跨模态预训练和监督微调策略来提高多模态性能。 Qwen2-VL [58] 采用更先进的 Qwen2 [48] 作为语言模型,并引入了多模态旋转位置嵌入和动态数量的视觉tokens,以支持任意分辨率的图像和视频输入。
大视觉语言模型与自动驾驶。LVLM 的常识性知识、推理能力和可解释性可以有效弥补端到端模型的不足。Drive-with-LLMs [22] 使用真值驾驶感知数据和 Transformer 网络将感知信息编码到潜空间中,然后将其输入到 LLM 中以预测未来的规划轨迹。DriveGPT4 [21] 接受前置摄像头视频输入,并使用 LVLM 预测规划控制信号并提供决策解释。LanguageMPC [59] 将历史真值感知信息和高清地图转换为自然语言格式,并使用思维链推理来分析驾驶场景并生成规划动作。 DriveMLM [23] 在闭环仿真环境中验证基于 LVLM 规划模型的有效性 [60]。ELM [29] 使用互联网规模的跨域视频数据对 LVLM 进行大规模预训练,表明结合多种来源和特定于任务的训练数据可显著提高 LVLM 在驾驶任务中的表现。其他几项研究提出针对驾驶任务量身定制的数据收集策略和数据集,进一步推动自动驾驶领域 LVLM 的发展 [31]–[33]、[61]–[63]。DriveVLM [27] 首次将 LVLM 与端到端模型相结合,其中 LVLM 预测低频轨迹,端到端模型对其进行细化以生成最终的规划轨迹。DriveVLM 在 nuScenes 数据集和他们提出的数据集上都展示强大的规划性能。然而,由于 LVLM 不太适合精确的数学计算,使用 LVLM 预测轨迹点可能会导致性能不佳。
如图所示:(a)以前的方法在没有决策步骤的情况下规划轨迹,这使得模型学习变得困难;LVLM 也难以进行精确的轨迹预测。(b)Senna 采用结构化规划方法:Senna-VLM 利用预训练的常识和驾驶知识以自然语言进行高级决策,然后 Senna-E2E 使用这些决策来生成最终轨迹。
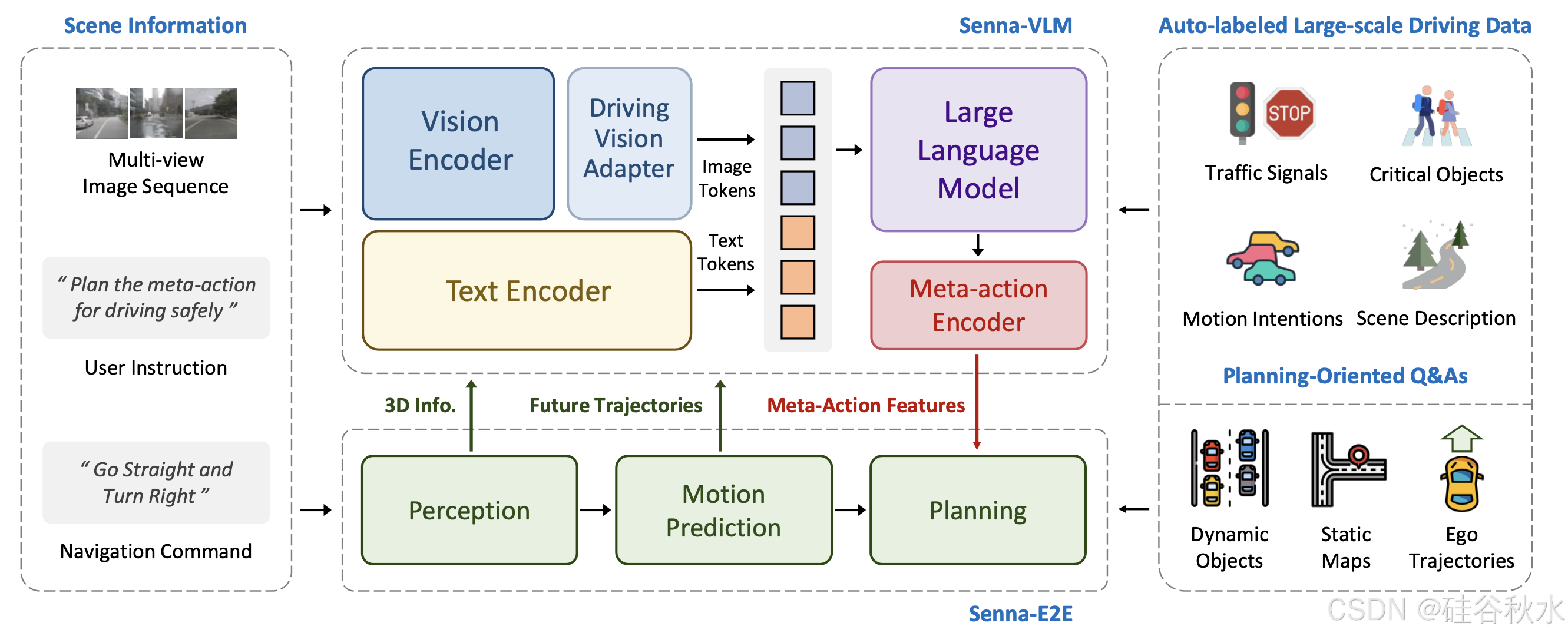
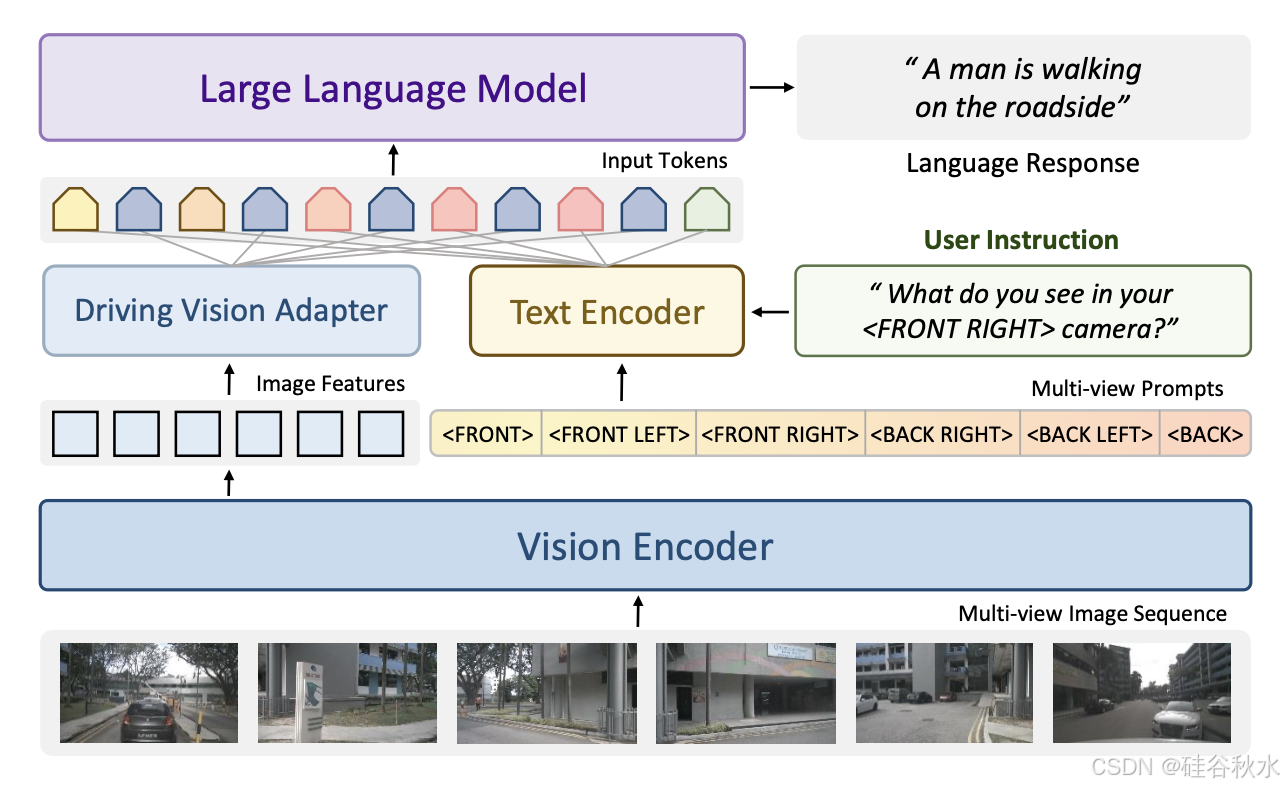
如图展示 Senna 的整体架构。输入的场景信息包括多视角图像序列、用户指令和导航命令。用户指令作为提示输入到 Senna-VLM,其他指令则同时发送给 Senna-VLM 和 Senna-E2E。Senna-VLM 将图像和文本信息分别编码为图像和文本tokens,然后由 LLM 进行处理。LLM 生成高级决策,这些决策通过Meta- action编码器编码为高维特征。Senna-E2E 根据场景信息和 Senna-VLM 生成的 meta- action 特征预测最终的规划轨迹。设计一系列面向规划的 QA 来训练 Senna-VLM,这些 QA 不需要人工注释,并且可以完全通过自动标记流程大规模生成。
驾驶场景理解
了解驾驶场景中的关键因素对于安全准确的规划至关重要。设计一系列面向规划的 QA,增强 Senna-VLM 对驾驶场景的理解。每种类型的 QA 的细节如图所示。用于生成这些 QA 的原始数据(例如 3D 目标检测框和跟踪轨迹)可以通过自动注释系统获得。此外,描述 QA 可以由 GPT-4o [17] 等 LVLM 生成。
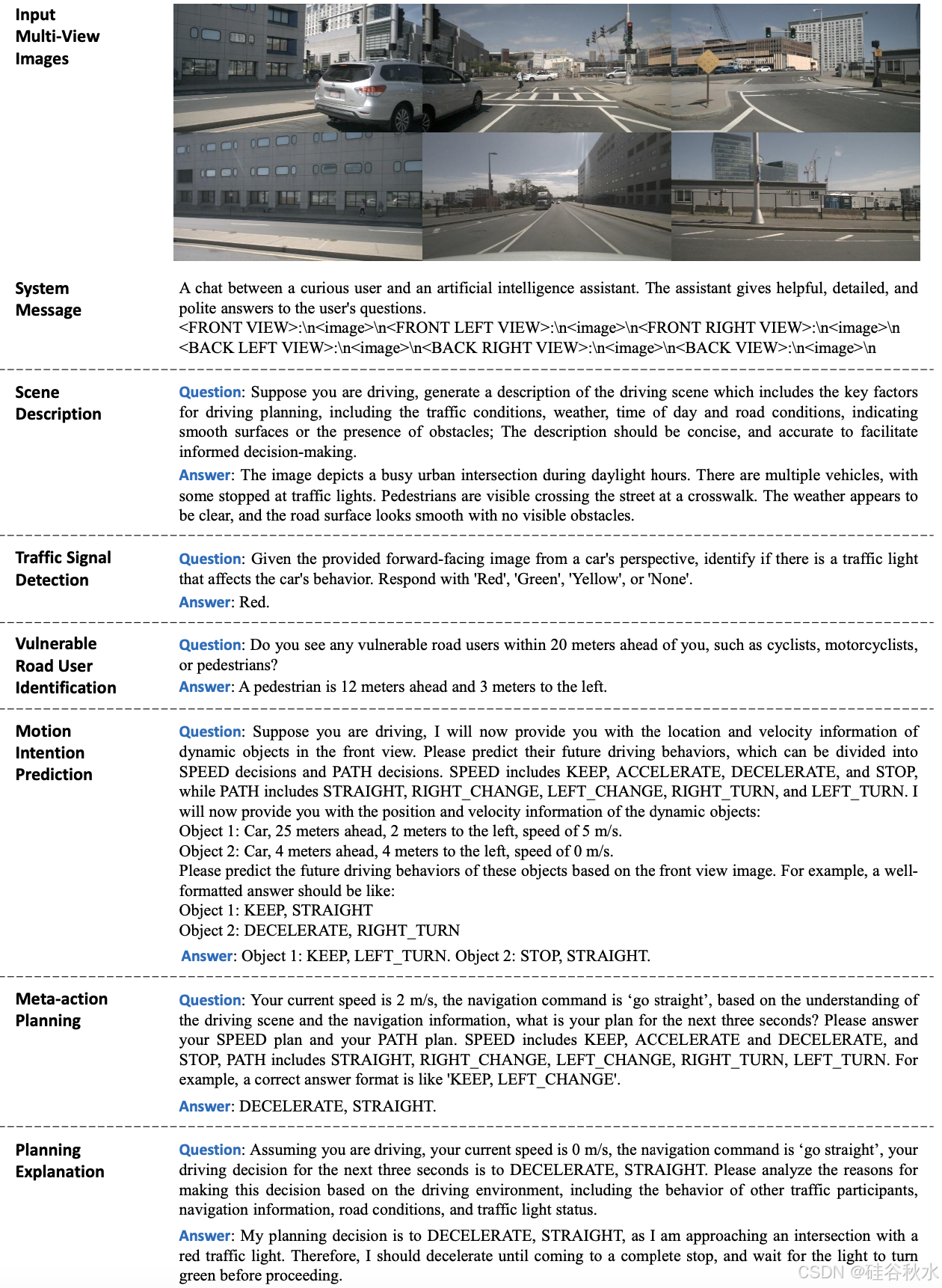
场景描述。利用预训练的 LVLM 根据环视图像生成驾驶场景的描述。为了避免生成与规划无关的冗余信息,在提示中指定所需的信息,包括:交通状况、环境(例如,城市、乡村等)、道路类型(例如,铺装道路、高速公路)、天气状况、一天中的时间以及道路状况(例如,道路是否平坦或是否有任何障碍物)。通过以这种方式构造提示,可以获得简洁且信息丰富的场景描述。
交通信号检测。交通信号有多种类型,但这里主要关注最关键的一种:交通信号灯。交通信号灯的状态可分为四种:红色、绿色、黄色和无,其中无表示在自车前方未检测到交通信号灯。
弱势道路使用者识别。通过识别环境中的弱势道路使用者 (VRU),增强 Senna 对这些关键目标的感知并提高了规划的安全性。具体而言,用真值 3D 检测结果来获取 VRU 的类别和位置,然后以文本形式描述此信息。位置信息以自车为中心,包括每个 VRU 相对于自车的横向和纵向距离。仅使用 Senna-VLM 来预测距离的整数部分,以在构建距离感知的同时降低学习复杂性。
运动意图预测。准确预测其他车辆的未来运动意图是安全规划的先决条件。还采用了meta-action方法,使 Senna 能够预测周围车辆的未来行为。这增强 Senna 对场景动态特征的理解,并使其能够做出更明智的决策。
meta-action规划。为了避免使用 LVLM 进行精确的轨迹预测,将自车的未来轨迹转换为meta-action以进行高级规划。具体而言,meta-action包括横向和纵向决策。横向meta-action包括左转、直行和右转,而纵向meta-action包括加速、保持、减速和停止。横向meta-action是根据预测的未来时间步长 T 内的横向位移确定的,纵向meta-action是根据预测期间的速度变化确定的。最终的meta-action包括横向和纵向元动作。
规划解释。还根据车辆的真实未来运动使用 LVLM 生成规划解释。换句话说,告知 LVLM 车辆的实际未来运动(例如加速和左转),并要求它们分析此类决策背后的原因。在提示中,引导模型通过考虑以下影响规划的因素来分析决策:其他交通参与者的行为、导航信息、道路状况和交通信号灯状态。
Senna-VLM 由四个组件组成。视觉编码器以多视角图像序列 I 作为输入并提取图像特征,然后由驾驶视觉适配器进一步编码和压缩,得到图像tokens Eimg。文本编码器将用户说明和导航命令编码为文本tokens Etxt。图像和文本tokens都被输入到 LLM 中,LLM 用来预测高级决策。在实践中,用 Vicuna-v1.5-7b [64] 作为 LLM。最后,meta-action编码器对决策进行编码并输出meta-action特征e/act。
用CLIP [51]中的ViT-L / 14作为视觉编码器,其中每幅图像的大小调整为 H = W = 224,从而产生576个图像tokens。对于多图像输入,这会导致图像tokens数量过多,这不仅会减慢VLM训练和推理的速度,还会导致模型崩溃和解码失败。因此,引入驾驶视觉适配器模块。该模块不仅功能类似于以前的研究[13],[54],将图像特征映射到LLM特征空间,而且还对图像特征执行额外的编码和压缩以减少图像tokens的数量。
实验表明,进一步编码和压缩图像特征不会降低模型性能。但是,过多的图像tokens会导致模型崩溃和解码失败。
为了使Senna-VLM能够区分不同视图的图像特征并建立空间理解,为驾驶场景设计一个简单而有效的环视提示。以正面视图为例,相应的提示为::\n\n,其中是LLM的特殊token,在生成过程中将被图像token替换。如图说明提出的多视图提示和图像编码方法的设计。
最后,提出meta-action编码器φ,它将LLM输出的高级决策转换为meta-action特征e/act。由于使用一组格式化的meta-action,因此meta-action编码器φ使用一组可学习的嵌入E/act实现了从meta-action到meta-action特征的一对一映射。 LLM是Senna的大语言模型。随后,met-action特征将被输入到Senna-E2E中以预测规划轨迹。
Senna-E2E 扩展 VADv2 [43]。具体来说,Senna-E2E 的输入包括多视图图像序列、导航命令和meta-action特征。它由三个模块组成:感知模块,用于检测动态目标并生成局部地图;运动预测模块,用于预测动态目标的未来轨迹;规划模块,使用一组通过注意机制 [44] 与场景特征交互的规划tokens来预测规划轨迹 V。将meta-action特征集成为一个 Senna-E2E 的附加交互tokens。由于meta-action特征采用嵌入向量的形式,因此 Senna-VLM 可以轻松地与其他端到端模型相结合。
为 Senna-VLM 提出了一种三步训练策略。第一步是混合预训练,用单图像数据训练驾驶视觉适配器,同时保持 Senna-VLM 中其他模块的参数不变。这样可以将图像特征映射到 LLM 特征空间。混合是指使用来自多个来源的数据,包括 LLaVA [13] 中使用的指令跟踪数据和提出的驾驶场景描述数据。第二步是驾驶微调,根据提出的面向规划 QA 对 Senna-VLM 进行微调,但不包括meta-action规划 QA。在此步,使用环视多图像输入代替单图像输入。第三步是规划微调,仅使用meta-action规划 QA 进一步微调 Senna-VLM。在第二步和第三步,都微调 Senna-VLM 的所有参数,但视觉编码器除外,它保持冻结状态。
对于 Senna-E2E,在训练阶段使用真值meta-action作为输入,而在推理阶段,它依赖于 Senna-VLM 预测的met-action。

















 1570
1570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









