







大模型论文精读系列1:Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
本文主要突出:大模型+端到端,大模型高维驾驶决策-端到端低维轨迹规划
论文链接:https://arxiv.org/abs/2410.22313
代码链接:https://github.com/hustvl/Senna(目前还未开源)
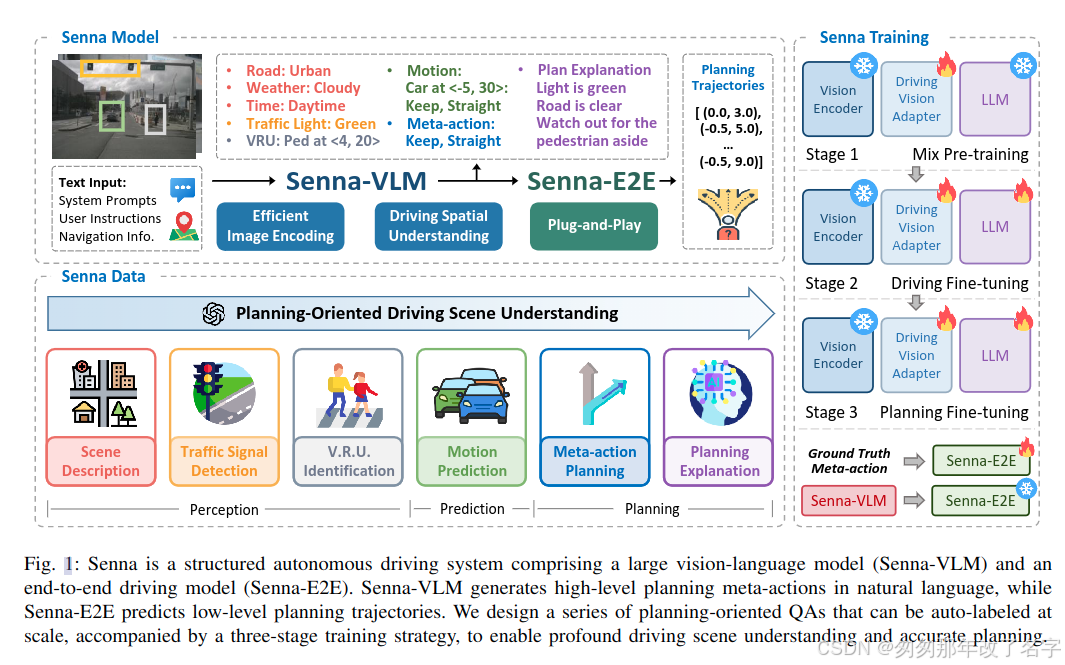
引言
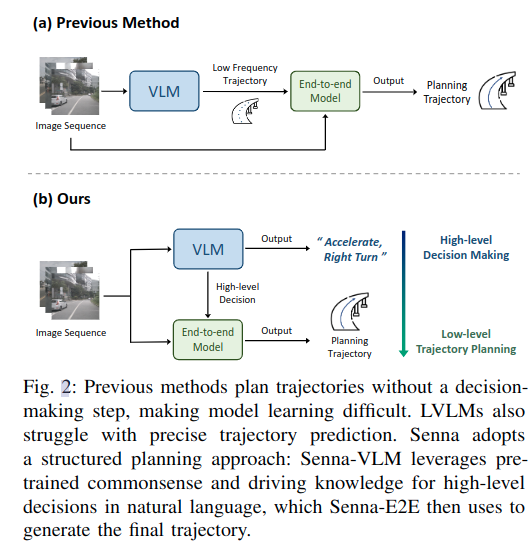
之前的大模型的自动驾驶方案都是让大模型直接作为端到端模型,也就是直接用大模型预测规划轨迹或者控制信号,但大模型不擅长预测精确的数值。Senna主要探索和解决以下三个问题:
(1)如何有效地结合多模态大模型和端到端自动驾驶模型?
大模型在驾驶数据上微调,增强其对驾驶场景的理解能力,然后用自然语言输出高维决策指令,端到端模型基于大模型提供的决策指令,生成具体的规划轨迹。优点是:使用大模型预测语言化的决策指令,可以最大利用其在语言任务上预训练的知识和常识,生成合理的决策,并且避免预测精确数字效果欠佳的缺陷;另一方面,端到端模型更擅长精确的轨迹预测,将高维决策的任务解耦,可以降低端到端模型学习的难度,提升其轨迹规划的精确。
(2)如何设计一个面向驾驶任务的多模态大模型?
之前针对驾驶任务的大模型仅支持前视输入,缺乏完整的空间感知。最初尝试简单基于LLaVA-1.5模型加入环视多图输入,但是效果并不符合预期。在LLaVA中,一张图像需要占用576个token,6张图则需要占用3456个token,这几乎要接近最大输入长度,导致图像信息占用的token数量过多。
Senna-VLM对图像token进行特征压缩,并设计了针对环视多图的prompt,使得Senna可以区分不同视角的图像特征并建立空间理解能力
(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









