









用梯度下降法解决最优化的问题:


步骤一:
调整学习速率:
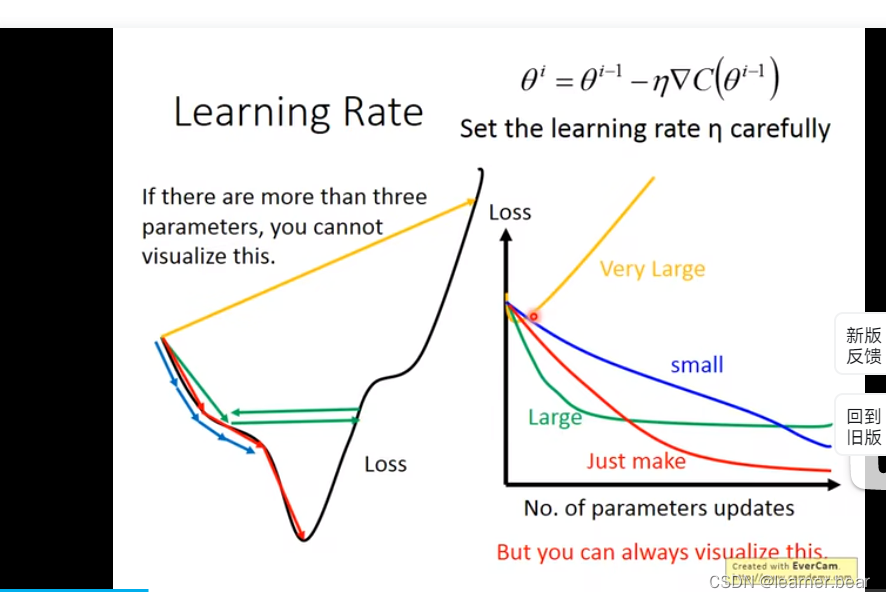
由图可知,学习速率不同造成的结果不同,学习率过大可能导致一下子到终点,略过了中间的关键部分。学习率过低则又会显得机器效率低下。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
由此,机器能不能自己调节自己的学习率最终来提高机器效率呢?
自适应学习率
举一个简单的思想:随着次数的增加,通过一些因子来减少学习率
-
通常刚开始,初始点会距离最低点比较远,所以使用大一点的学习率
-
update好几次参数之后呢,比较靠近最低点了,此时减少学习率
-
比如一个数学模型,随着t的增加,y减小
学习率不能是一个值通用所有特征,不同的参数需要不同的学习率
其中Adagrad算法是能解决该问题的一种算法:

步骤二:
随机梯度下降法:

步骤三:
特征缩放:
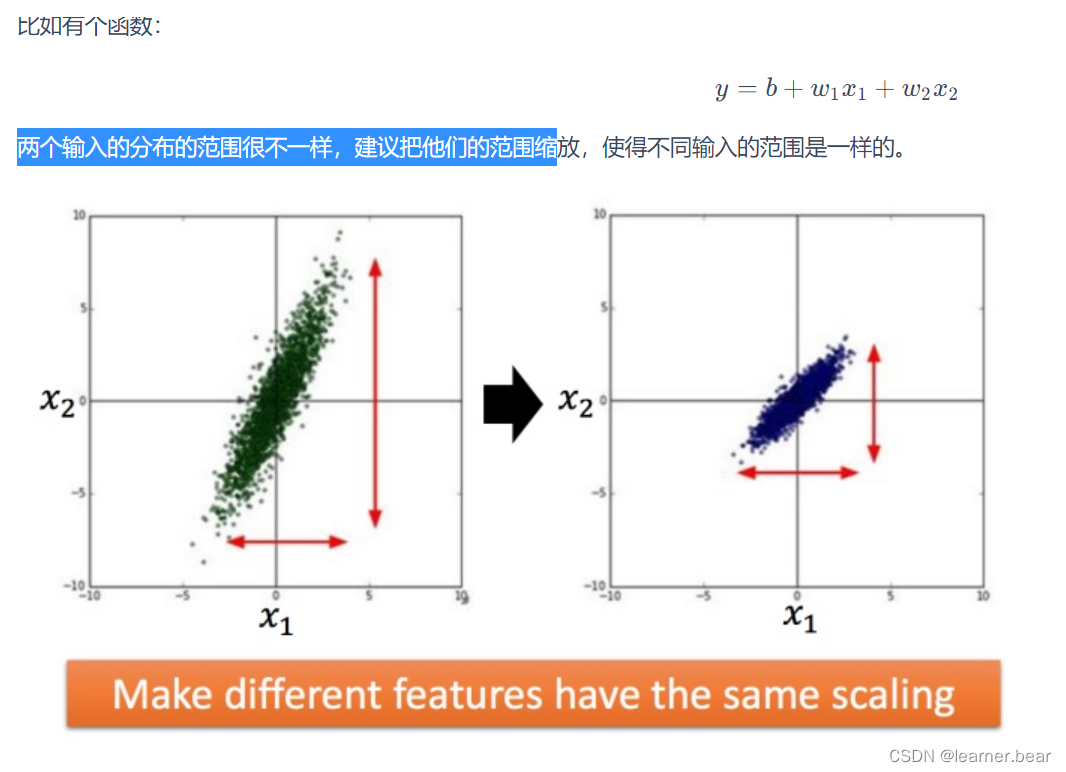

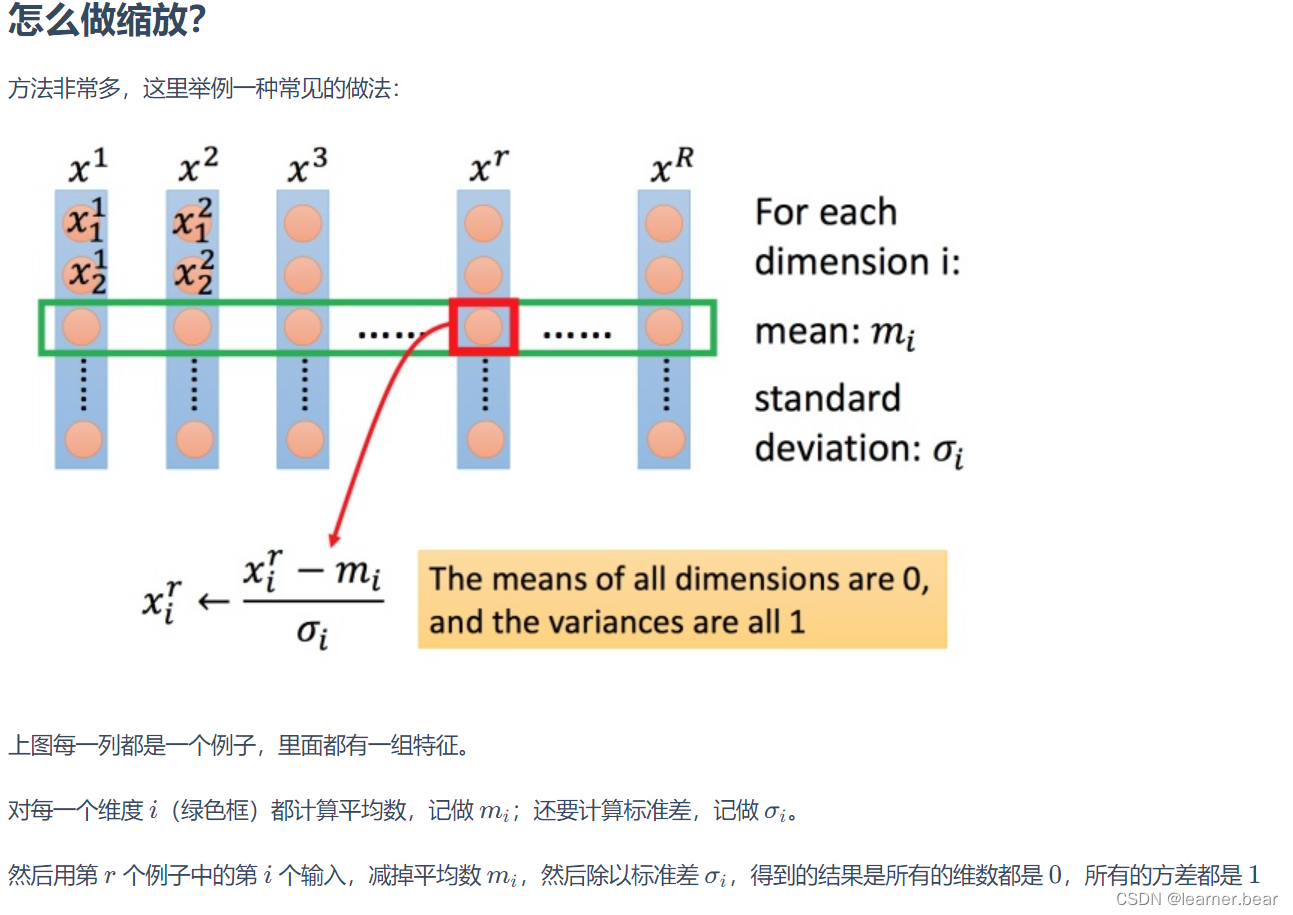
如何做到特征缩放呢?















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









