








(图片来自于B站datawhale)【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集_哔哩哔哩_bilibili
1.本节大纲

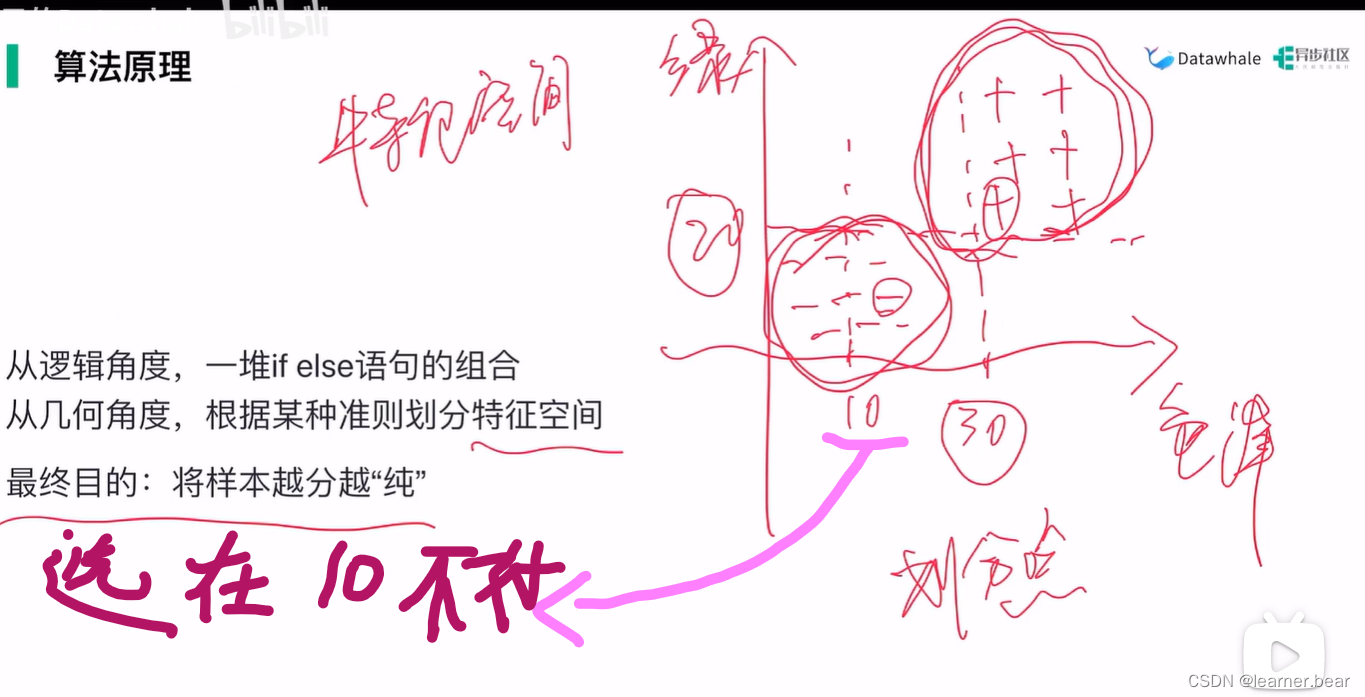
2.决策树的算法原理:
3.ID3决策树:




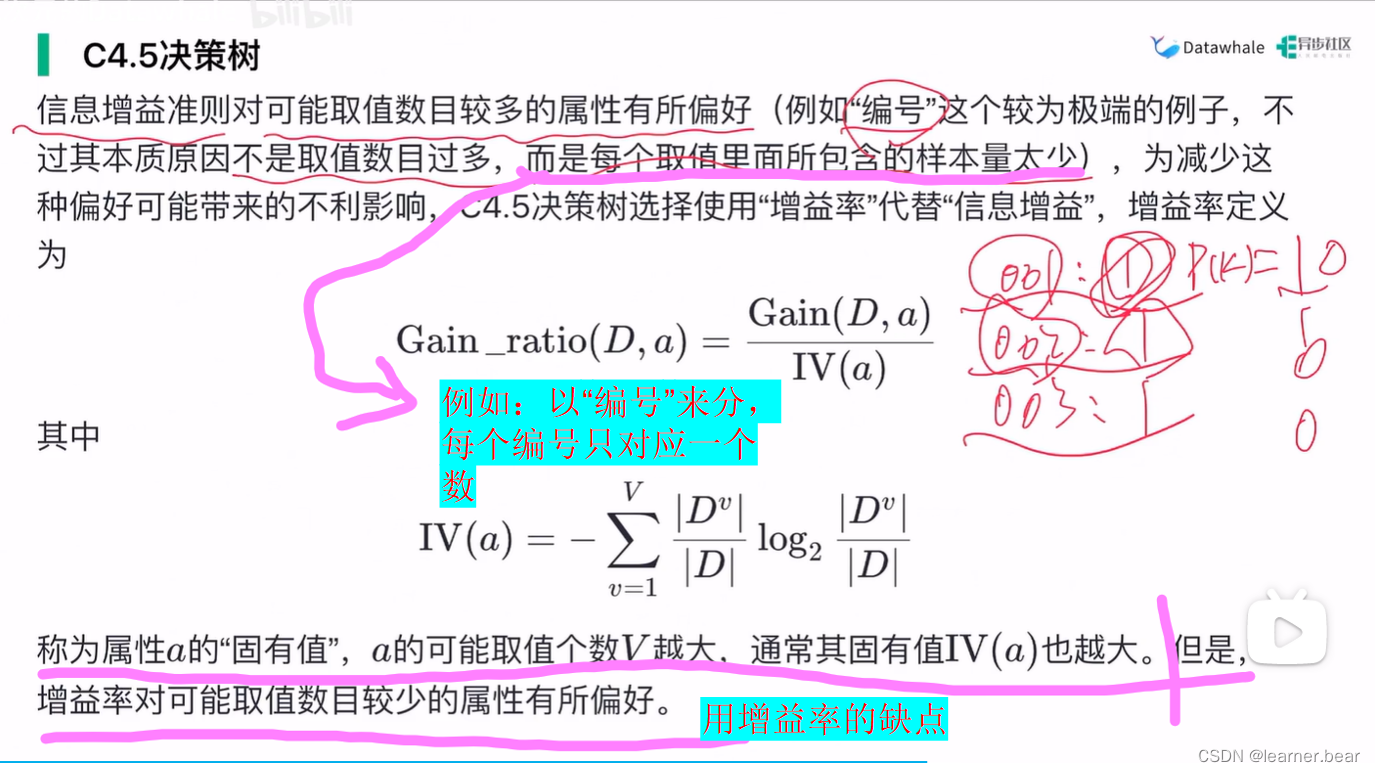
4.C4.5决策树

5.CART决策树:




(图片来自于B站datawhale)【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集_哔哩哔哩_bilibili
1.本节大纲
2.决策树的算法原理:
3.ID3决策树:
4.C4.5决策树
5.CART决策树:
 2470
2470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























