







注:由于tensorflow版本的不同,这个函数所在的模块可能不同,如:tf.nn.seq2seq.sequence_loss_by_example和tf.contrib.legacy_seq2seq.sequence_loss_by_example
在正式进入sequence_loss_by_example()函数的计算过程之前,需要先复习下两个基本的知识点,softmax的计算和交叉熵的计算。
1 softmax的计算过程
可以直接网上已经写好的博客:三分钟带你对 Softmax 划重点,这篇文章中有举具体的例子,最好自己动手算一下,不自己动手计算,往往看了就忘了。
2 交叉熵的计算过程
交叉熵网上的文章也很多,一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉这篇文章讲得非常详细,还举了各种例子。
以上复习了softmax和交叉熵的计算过程,为啥要使用softmax和交叉熵,可以自行网上搜搜。接下来就进入sequence_loss_by_example()函数的计算过程。
3 sequence_loss_by_example()函数的计算过程(以TF的ptb构建语言模型例子为例)
注:例子中的batch_size=20,num_steps=20,为了更直观的查看各个数据的维度,我将num_steps改为了15.(因为本例是通过上一个词预测下一个词,其实num_steps改为多少并没有影响)。
(1)LSTM的输出
LSTM的隐藏层的单元个数为200,因此,LSTM每一步的输出数据的维度为(batch_size,hidden_size)。有因为LSTM展开的时间步数为num_steps,于是通过
outputs.append(cell_output)
将每一时刻的输出都收集起来,这样,最后的outputs是一个list,其样式为:
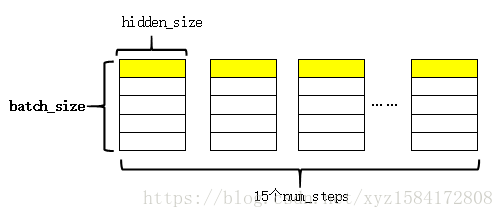
图中黄色的部分表示同一个序列在LSTM不同时刻的输出。
紧接着对outputs进行拼接和reshape,其过程如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









