






一、决策树
1、基本介绍
决策树(decision tree)是一种基本的分类与回归方法。其主要算法有:ID3、C4.5、CART。以及进化后的C4.5算法C5.0、分类有极大提升的Tsallis等算法。这些算法的区别就在于选择最优特征的方式。但C5.0的核心原理与C4.5是相同的,它对于C4.5的改进在于计算速率,尤其是对于大数据,C4.5的速度非常慢,而C5.0对大数据运算效率极高。但C5.0一直是商用算法,之前一直未开源,但官方提供了可将C5.0构建的分类器嵌入到自己组织中的C源码。
2、决策树事件处理流程
- 构建策略:
随着树的深度增加,节点的熵迅速降低。熵降低的速度越快越好,可以得到高度最矮的决策树 - 决策树
决策树的基本流程遵循“分而治之”策略。 - 伪代码

- 结束递归的三个条件
①样本全部属于同一类别;
②此属性集合为孔或者此时所有样本的哥哥属性值相同;
③数据集在某一个属性上没有样本;
3、理论基础
- 纯度(purity)
对于一个分支结点,如果该结点所包含的样本都属于同一类,那么它的纯度为1;纯度越高越好,尽可能多的样本属于同一类 - 信息熵(information entropy)
假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为:
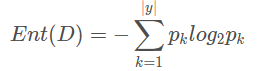
显然,Ent(D)值越小,D的纯度越高。因为0<=pk<= 1,故log2 pk<=0,Ent(D)>=0. 极限情况下,考虑D中样本同属于同一类,则此时的Ent(D)值为0(取到最小值)。当D中样本都分别属于不同类别时,Ent(D)取到最大值log2 |y|. - 信息增益(information gain)
假定离散属性a有V个可能的取值{a1,a2,…,aV}. 若使用a对样本集D进行分类,则会产生V个分支结点,记Dv为第v个分支结点包含的D中所有在属性a上取值为av的样本。不同分支结点样本数不同,我们给予分支结点不同的权重:|Dv|/|D|, 该权重赋予样本数较多的分支结点更大的影响、由此,用属性a对样本集D进行划分所获得的信息增益定义为:
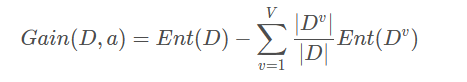
其中,Ent(D)是数据集D划分前的信息熵,∑v=1 |Dv|/|D|·Ent(Dv)可以表示为划分后的信息熵。“前-后”的结果表明了本次划分所获得的信息熵减少量,也就是纯度的提升度。显然,Gain(D,a) 越大,获得的纯度提升越大,此次划分的效果越好。 - 增益率(gain ratio)
基于信息增益的最优属性划分原则——信息增益准则,对可取值数据较多的属性有所偏好。C4.5算法使用增益率替代信息增益来选择最优划分属性,增益率定义为:
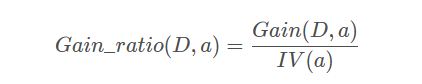
其中
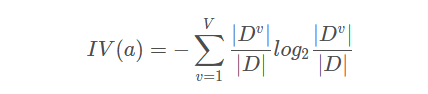
称为属性a的固有值。属性a的可能取值数目越多(即V越大),则IV(a)的值通常会越大。这在一定程度上消除了对可取值数据较多的属性的偏好。
事实上,增益率准则对可取值数目较少的属性有所偏好,C4.5算法并不是直接使用增益率准则,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。 - 基尼指数(Gini index)
CART决策树算法使用基尼指数来选择划分属性,基尼指数定义为:
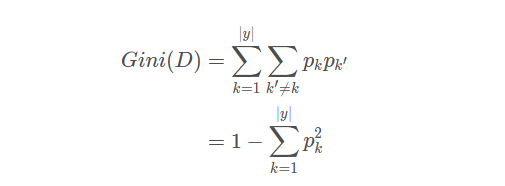
可以这样理解基尼指数:从数据集D中随机抽取两个样本,其类别标记不一致的概率。Gini(D)越小,纯度越高。
属性a的基尼指数定义:
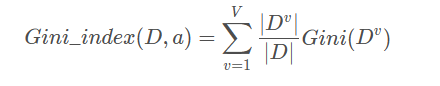
使用基尼指数选择最优划分属性,即选择使得划分后基尼指数最小的属性作为最优划分属性。
二、ID3决策树及Python实现
1、数据

2、步骤
- 计算初始信息熵
- 计算信息增益
- 按照信息增益的大小排序
- 选取最大的信息增益的特征,以此特征作为划分节点
- 该特征从特征列表删除,继续返回到上一步筛选,重复操作,知道特征列表 = 0
3、决策树实现
- 导入包
#导入模块
import pandas as pd
import numpy as np
from collections import Counter
from math import log2
- 数据的获取处理操作
#数据获取与处理
def getData(filePath):
data = pd.read_excel(filePath)
return data
def dataDeal(data):
dataList = np.array(data).tolist()
dataSet = [element[1:] for element in dataList]
return dataSet
- 获取属性名称
#获取属性名称
def getLabels(data):
labels = list(data.columns)[1:-1]
return labels
- 获取类别标记
#获取属性名称
def getLabels(data):
labels = list(data.columns)[1:-1]
return labels
#获取类别标记
def targetClass(dataSet):
classification = set([element[-1] for element in dataSet])
return classification
- 叶节点标记
#将分支结点标记为叶结点,选择样本数最多的类作为类标记
def majorityRule(dataSet):
mostKind = Counter([element[-1] for element in dataSet]).most_common(1)
majorityKind = mostKind[0][0]
return majorityKind
- 计算信息熵
#计算信息熵
def infoEntropy(dataSet):
classColumnCnt = Counter([element[-1] for element in dataSet])
Ent = 0
for symbol in classColumnCnt:
p_k = classColumnCnt[symbol]/len(dataSet)
Ent = Ent-p_k*log2(p_k)
return Ent
- 子数据集构建
#子数据集构建
def makeAttributeData(dataSet,value,iColumn):
attributeData = []
for element in dataSet:
if element[iColumn]==value:
row = element[:iColumn]
row.extend(element[iColumn+1:])
attributeData.append(row)
return attributeData
- 计算信息增益
#计算信息增益
def infoGain(dataSet,iColumn):
Ent = infoEntropy(dataSet)
tempGain = 0.0
attribute = set([element[iColumn] for element in dataSet])
for value in attribute:
attributeData = makeAttributeData(dataSet,value,iColumn)
tempGain = tempGain+len(attributeData)/len(dataSet)*infoEntropy(attributeData)
Gain = Ent-tempGain
return Gain
- 选择最优属性
#选择最优属性
def selectOptimalAttribute(dataSet,labels):
bestGain = 0
sequence = 0
for iColumn in range(0,len(labels)):#不计最后的类别列
Gain = infoGain(dataSet,iColumn)
if Gain>bestGain:
bestGain = Gain
sequence = iColumn
print(labels[iColumn],Gain)
return sequence
- 建立决策树
#建立决策树
def createTree(dataSet,labels):
classification = targetClass(dataSet) #获取类别种类(集合去重)
if len(classification) == 1:
return list(classification)[0]
if len(labels) == 1:
return majorityRule(dataSet)#返回样本种类较多的类别
sequence = selectOptimalAttribute(dataSet,labels)
print(labels)
optimalAttribute = labels[sequence]
del(labels[sequence])
myTree = {optimalAttribute:{}}
attribute = set([element[sequence] for element in dataSet])
for value in attribute:
print(myTree)
print(value)
subLabels = labels[:]
myTree[optimalAttribute][value] = \
createTree(makeAttributeData(dataSet,value,sequence),subLabels)
return myTree
def main():
filePath = 'E:\Ai\watermelon\watermalon.xls'
data = getData(filePath)
dataSet = dataDeal(data)
labels = getLabels(data)
myTree = createTree(dataSet,labels)
return myTree

运行结果:



三、Sklearn实现决策树
1、基于信息增益准则方法建立决策树
- 导入相关库
#导入相关库
import pandas as pd
import graphviz
from sklearn.model_selection import train_test_split
from sklearn import tree
- 导入数据
f = open('watermalon.csv','r')
data = pd.read_csv(f)
x = data[["色泽","根蒂","敲声","纹理","脐部","触感"]].copy()
y = data['好瓜'].copy()
print(data)

- 进行数据转换
#将特征值数值化
x = x.copy()
for i in ["色泽","根蒂","敲声","纹理","脐部","触感"]:
for j in range(len(x)):
if(x[i][j] == "青绿" or x[i][j] == "蜷缩" or data[i][j] == "浊响" \
or x[i][j] == "清晰" or x[i][j] == "凹陷" or x[i][j] == "硬滑"):
x[i][j] = 1
elif(x[i][j] == "乌黑" or x[i][j] == "稍蜷" or data[i][j] == "沉闷" \
or x[i][j] == "稍糊" or x[i][j] == "稍凹" or x[i][j] == "软粘"):
x[i][j] = 2
else:
x[i][j] = 3
y = y.copy()
for i in range(len(y)):
if(y[i] == "是"):
y[i] = int(1)
else:
y[i] = int(-1)
#需要将数据x,y转化好格式,数据框dataframe,否则格式报错
x = pd.DataFrame(x).astype(int)
y = pd.DataFrame(y).astype(int)
print(x)
print(y)


- 建立模型并进行训练
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
print(x_train)

#决策树学习
clf = tree.DecisionTreeClassifier(criterion="entropy") #实例化
clf = clf.fit(x_train, y_train)
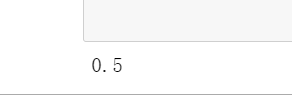
score = clf.score(x_test, y_test)
print(score)
- 绘制决策树
# 加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph

2、CART算法实现
clf = tree.DecisionTreeClassifier(criterion="gini") #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)

# 加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph

四、总结
对决策树算法有了一定了解,熟悉了Sklearn库使用















 8027
8027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









