







title: 算法竞赛进阶指南算法整理
date: 2022-10-25 11:39:26
tags:
算法竞赛进阶指南算法整理
基本算法
位运算
| 与 | 或 | 非 | 异或 |
|---|---|---|---|
| and,& | or,| | not,~ | xor,^(C++) |
算术右移(n>>1) 等于除以2向下取整 n/2为向零取整
| 操作(n为整数) | 运算 |
|---|---|
| 取n在二进制下的第k位 | (n>>k) & 1 |
| 取n在二进制下的第0到k-1位 | n & ((1<<k)-1) |
| 把n在二进制下的第k位取反 | n xor (1<<k) |
| 对n在二进制下的第k位赋值为1 | n | (1<<k) |
| 对n在二进制下的第k位赋值为0 | n & (~(1<<k)) |
n为偶数时,n xor 1 等于n+1
n为奇数时,n xor 1 等于n-1
lowbit运算(最低位的1及其后面所有的0)
lowbit(n) = n&(~n+1) = n&(-n)
二进制状态压缩
最短Hamilton路径
#include <bits/stdc++.h>
using namespace std;
int f[1 << 20][20];//第一个下标为枚举的状态,第二个下标为当前所在的点
// Hamilton路径的定义:从0到n-1不重不漏地经过每一点恰好一次
int hamilton(int n, int weight[20][20])
{
memset(f, 0x3f, sizeof(f));//这里就用到了上面提到的0x3f
f[1][0] = 0;
for (int i = 1; i < (1 << n); i++)//枚举每一个状态
{
for (int j = 0; j < n; j++)
if (i >> j & 1)//寻找可能的这次经过的点
for (int k = 0; k < n; k++)
if (((i ^ 1 << j) >> k) & 1) //寻找可能从哪个点来,并从中选取最小值
f[i][j] = min(f[i][j], f[i ^ (1 << j)][k] + weight[k][j]);
}
return f[(1 << n) - 1][n - 1];
}
int main()
{
int n;
cin >> n;
int weight[20][20];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
cin >> weight[i][j];
cout << hamilton(n, weight);
return 0;
}
快速幂
int power(int a, int b, int p)//快速幂函数模板,原理为位运算
{
int ans = 1 % p;//感觉,这个%p应该可以去掉,但,emmm,加上就加上了,加上就懒得去了/ww
for (; b; b >>= 1)
{
if (b & 1)
ans = (long long)ans * a % p;//这里一定要加上那个long long,当时做的时候,因为这东西,卡了两个小时,原因就是因为是先乘再取余,所以可能会越界,下同
a = (long long)a * a % p;
}
return ans;
}//从b的二进制的第一位开始计算,每一层,a肯定都要翻倍,如果b在该位为1,则答案即次方之后的值也要乘以当时的a(只是说一下自己的理解,后同,详细的当然还是要看书了/ww)
快速乘
long long mul(long long a, long long b, long long p)//原理同位运算,emmm,感觉,都差不多,反正,我感觉都差不多
{
long long ans = 0;
for (; b; b >>= 1)
{
if (b & 1)
ans = (ans + a) % p;
a = a * 2 % p;
}
return ans;
}
1+p+p2+…+pc(O(logc))
int power(int a, int b)//快速幂模板
{
int ans = 1 % q;
for (; b; b >>= 1)
{
if (b & 1)
ans = (long long)ans * a % q;
a = (long long)a * a % q;
}
return ans;
}
int sum(int p, int c)//书上公式的代码实现(自我建议,记下来(虽然,我也还没记下来吧/ww))(分治法)
{
if (c == 0)
return 1;
else
;
if (c % 2)
return ((1 + power(p, (1 + c) / 2)) * sum(p, (c - 1) / 2)) % q;
else
return ((1 + power(p, c / 2)) * sum(p, (c / 2) - 1) + power(p, c)) % q;
}
前缀和,差分
前缀和:
s[i] = s[i-1] + a[i]
二维前缀和:
s[i,j] = s[i-1,j] + s[i,j-1] - s[i-1,j-1] + a[i,j]
差分:
b[1] = a[1],b[i] = a[i] - a[i-1]
二分查找
整数集合
while(l<r)
{
int mid = (l+r)>>1;
if(a[mid]>=x) r=mid;
else l=mid+1;
}
return a[l];
while(l<r)
{
int mid = (l+r+1)>>1;
if(a[mid]<=x) l=mid;
else r=mid-1;
}
return a[l];
在互不相等的情况下
while(l<=r)
{
int mid=(l+r)>>1;
if(compare(res[mid],i))l=mid+1;//因为不可能会等于,所以可以这样写
else r=mid-1;
}
return r;//插入在r后面
实数域
while(l+1e-5<r)
{
double mid = (l+r)/2;
if(calc(mid)) r = mid;
else l = mid;
}
for(int i=0;i<100;i++)
{
double mid = (l+r)/2;
if(calc(mid)) r = mid;
else l = mid;
}
三分求单峰函数,l和r取二等分点极其接近的地方,每次缩小1/2的范围
答案具有单调性(最大值最小问题),可用二分转化为判定(直至缩小到l=r),把求最优解问题转化为判定是否存在可行方案使结果达到mid的问题
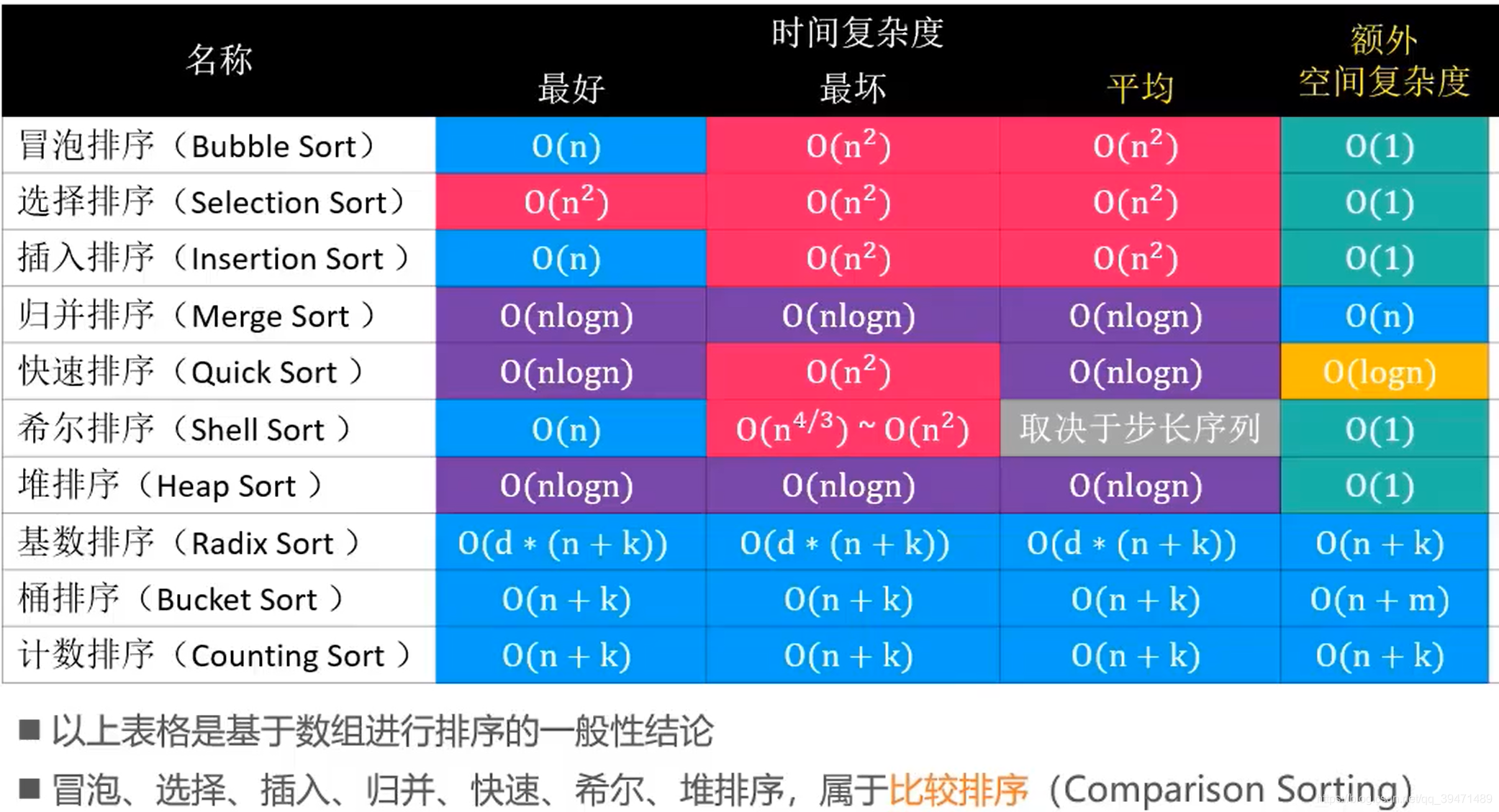
排序
冒泡排序
#include<iostream>
using namespace std;
int main() {
int i;
int arr[10] = { 1,5,2,3,6,8,7,9,4 ,0};//初始化数组
for (int i = 0; i < 9;i++) {//一共循环10次
for (int j = 0; j < 9-i; j++) {//执行的次数依次递减
if (arr[j]>arr[j + 1]) {
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;//交换值
}
}
}
for (int j = 0; j < 10; j++)//打印数组
{
cout << arr[j] << endl;
}
system("pause");
return 0;
}
选择排序
#include<iostream>
using namespace std;
int main() {
int i;
int arr[10] ;//初始化数组
for (i = 0; i < 10; i++)
{
cin >> arr[i];//输入10要排序的数
}
for (int i = 0; i < 10;i++) {//一共循环10次
for (int j = 0; j < 10; j++) {//找到10个数当中的最小值
if (arr[j]>arr[i ]) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;//交换值
}
}
}
for (int j = 0; j < 10; j++)//打印数组
{
cout << arr[j] << endl;
}
system("pause");
return 0;
}
插入排序,希尔排序(O(n^3/2))
#include<iostream>
using namespace std;
int main() {
int i;
int arr[10] ;//初始化数组
for (i = 0; i < 10; i++)
{
cin >> arr[i];//输入10要排序的数
}
for (int i = 1; i < 10;i++) {//10个数循环9次
for (int j = i; j >0; j--) {//从第二个数开始与第一个数比较,小的插入到前面
if (arr[j-1]>arr[j]) {
int temp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = temp;//插到前面来(交换值)
}
}
}
for (int j = 0; j < 10; j++)//打印数组
{
cout << arr[j] << endl;
}
system("pause");
return 0;
}
#include<iostream>
using namespace std;
int main() {
int i;
int arr[15] = {9,6,11,3,5,12,8,7,10,15,14,4,1,13,2};//初始化数组
for (int gap = 4; gap > 0; gap /=2)//定义一个空隙为4,依次减倍
{
for (int i = gap; i < 15; i++) {
for (int j = i; j >gap - 1; j -= gap) {
//从第0个数开始,每隔4个数进行两两比较
if (arr[j - gap]>arr[j]) {
int temp = arr[j - gap];
arr[j - gap] = arr[j];
arr[j] = temp;//插到前面来(交换值)
}
}
}
}
for (int j = 0; j < 15; j++)//打印数组
{
cout << arr[j] << endl;
}
system("pause");
return 0;
}
归并排序
#include <iostream>
#include <cstdlib>
#include <cstdio>
using namespace std;
int n,a[12000],b[12000];
void merge(int low,int mid,int high)
{
int i=low,j=mid+1,k=low;
while (i<=mid && j<=high)
{
if (a[i]<a[j])
b[k++]=a[i++];
else
b[k++]=a[j++];
}
while (i<=mid)
b[k++]=a[i++];
while (j<=high)
b[k++]=a[j++];
for (int i=low;i<=high;i++)
a[i]=b[i];
}
void mergesort(int x,int y)
{
if (x>=y) return;
int mid=(x+y)/2;
mergesort(x,mid);
mergesort(mid+1,y);
merge(x,mid,y);
}
int main()
{
cin >>n;
for (int i=1;i<=n;i++)
cin >>a[i];
mergesort(1,n); //调用函数
for (int i=1;i<=n;i++)
cout <<a[i] <<" ";
return 0;
}
快速排序
#include<iostream>
using namespace std;
void quickSort(int a[], int, int);//原型声明
int main()
{
int array[] = { 32,64,12,43,69,5,78,10,3,70 },k;
int len = sizeof(array) / sizeof(int);//数组长度
//cout << len << endl;
cout << "The orginal arrayare:" << endl;
for ( k = 0; k<len; k++)
cout << array[k] << " ";
cout << endl;
quickSort(array, 0, len - 1);
cout << "The sorted arrayare:" << endl;
for (k = 0; k<len; k++)
cout << array[k] << " ";//打印数组
cout << endl;
system("pause");
return 0;
}
void quickSort(int s[], int l, int r)
{
if (l< r)
{
int i = l, j = r, x = s[l];
while (i < j)
{
while (i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if (i < j)
s[i++] = s[j];
while (i < j && s[i]< x) // 从左向右找第一个大于等于x的数
i++;
if (i < j)
s[j--] = s[i];
}
s[i] = x;
quickSort(s, l, i - 1); // 递归调用
quickSort(s, i + 1, r);
}
}
堆排序
#include<iostream>
using namespace std;
void adjust(int arr[], int len, int index)
{
int left = 2 * index + 1;
int right = 2 * index + 2;
int max = index;
if (left<len && arr[left] > arr[max]) max = left;
if (right<len && arr[right] > arr[max]) max = right; // max是3个数中最大数的下标
if (max != index) // 如果max的值有更新
{
swap(arr[max], arr[index]);
adjust(arr, len, max); // 递归调整其他不满足堆性质的部分
}
}
void heapSort(int arr[], int size)
{
for (int i = size / 2 - 1; i >= 0; i--) // 对每一个非叶结点进行堆调整(从最后一个非叶结点开始)
{
adjust(arr, size, i);
}
for (int i = size - 1; i >= 1; i--)
{
swap(arr[0], arr[i]); // 将当前最大的放置到数组末尾
adjust(arr, i, 0); // 将未完成排序的部分继续进行堆排序
}
}
int main()
{
int array[8] = { 6, 0, 15, 4, 21, 5, 7, 10 };
heapSort(array, 8);
for (auto it : array)
{
cout << it << endl;
}
system("pause");
return 0;
}
计数排序
#include<iostream>
using namespace std;
int arr[] = {3,2,3,1,5,6,8,6}, temp[1001], result[1001], n;
int main() {
int len = sizeof(arr)/sizeof(int);//数组长度
cout << len << endl;
//cin >> n;
for (int i = 0; i < len; i++)
{
temp[arr[i]]++;
}
for (int i = 0; i < len; i++)
{
temp[i+1]+=temp[i];
}
for (int i = len - 1; i >= 0; i--)
{
result[--temp[arr[i]]] = arr[i];
}
for (int i = 0; i < len; i++)//打印数组
{
cout << result[i] << " ";
}
system("pause");
return 0;
}
基数排序
#include <iostream>
using namespace std;
//打印数组
void printArray(int array[], int length)
{
for (int i = 0; i < length; ++i)
{
cout << array[i] << " ";
}
cout << endl;
}
//求数据的最大位数,决定排序次数
int maxbit(int data[], int n)
{
int d = 1; //保存最大的位数
int p = 10;
for (int i = 0; i < n; ++i)
{
while (data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int temp[10];
int count[10]; //计数器
int i, j, k;
int radix = 1;
for (i = 1; i <= d; i++) //进行d次排序
{
for (j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for (j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for (j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将temp中的位置依次分配给每个桶
for (j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到temp中
{
k = (data[j] / radix) % 10;
temp[count[k] - 1] = data[j];
count[k]--;
}
for (j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = temp[j];
radix = radix * 10;
}
}
int main()
{
int array[10] = { 73,22,93,43,55,14,28,65,39,81 };
radixsort(array, 10);
printArray(array, 10);
system("pause");
return 0;
}
桶排序
#include <bits/stdc++.h>
using namespace std;
int n; //要给n个数排序
int bucket[1005]; //满足所有数不超过 bucket[x]的x
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
int a;
cin>>a;
bucket[a]++; //进入相应的区域(桶)
//如果题目要求把重复的数删掉(去重)
//可以写 bucket[a]=1;
}
for(int i=0;i<=1005;i++) //要把所有区域里的数“拽”出来
while(bucket[i]>0)
{
cout<<i<<' '; //i指的是数
bucket[i]--; //bucket[i]指的是区域 i里剩余数的数量
}
return 0;
}
离散化
把无穷大集合(尤其指数非常分散的情况)中的若干个元素映射为有限集合(中连续的数)以便于统计(和排序)的方法
void discrete()
{
sort(a+1,a+n+1);
for(int i=1;i<=n;i++)
if(i==1||a[i]!=a[i-1])
b[++m]=a[i];
}
int query(int x)
{
return lower_bound(b+1,b+m+1,x) - b;
}
第k大数(O(n))
快排思想
在每次选取基准值后,可以统计出大于基准值的数量cnt,如果k<=cnt,则在左半段寻找第k大数,否则在右半段寻找第k-cnt大数
逆序对(O(nlogn)
利用归并算法
void merge(int l,int mid,int r)
{
if (l == r)
return;
merge(l, (l + mid) / 2, mid);
merge(mid + 1, (mid + 1 + r) / 2, r);
//合并a[l~mid]与a[mid+1~r]
//a是待排序数组,b是临时数组,cnt是逆序对个数
int i = l,j = mid +1;
for(int k = l;k <= r;k++)
{
if(j > r || i <=mid && a[i] <= a[j])
b[k] = a[i++];
else
b[k] = a[j++],cnt += mid - i + 1;
}
for(int k = l;k <= r;k++)
a[k] = b[k];
}
奇数码问题
奇数码游戏,两个局面可达,当且仅当两个局面下网格中的数依次写成1行序列(不考虑空格)后,逆序对个数的奇偶性相同
倍增
l=0;
p=1;
while(p)//如果还能扩增范围(l)就继续
{
if(a[l+p]<12)
{
l+=p;//增加已知范围
p<<=1//成倍增长,相当于p*=2
}
else
{
p>>=1;//缩小范围
}
}
cout<<a[l];
ST算法
O(nlogn)预处理后,以O(1)在线回答数列中下标在l~r之间的数的最大值是多少
void ST_prework()
{
for(int i = 1;i <= n;i++) f[i][0] = a[i];
int t = log(n) / log(2) + 1;
for(int j = 1;j < t;j++)//区间的长度
for(int i = 1; i <= n - (1<<j) + 1;i++)
f[i][j] = max(f[i][j-1] , f[i + (1<<(j-1))][j-1]);
}
int ST_query(int l,int r)
{
int k = log(r - l + r) / log(2);//orO(N)预处理一下1~N对应的k值
return max(f[l][k] , f[r - (1<<k) + 1][k]);
}
贪心
使用要求问题的整体最优性可以由局部最优性导出
证明手段:;
微扰(邻项交换) : 任何对局部最优策略的微小改变都会导致整体结果变差
范围缩放 : 任何对局部最优策略作用范围的扩展都不会造成整体结果变差
决策包容性 : 这个局部最优策略提供的可能性包含其他所有策略提供的可能性
反证法
数学归纳法
感觉贪心问题的话,最主要,最难想到,最难证明的就是贪心的正确性了,证明了正确性之后,其实,挺简单的
大数的乘除运算
vector<int> mul(vector<int> a, int b)
{
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i++)
{
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (t)
{
c.push_back(t % 10);
t /= 10;
}
return c;
}
vector<int> div(vector<int> a, int b)
{
vector<int> c;
bool is_first = 1;
for (int i = a.size() - 1, t = 0; i >= 0; i--)
{
t = t * 10 + a[i];
int x = t / b;
if (!is_first || x)
{
is_first = 0;
c.push_back(x);
}
t %= b;
}
reverse(c.begin(), c.end());//这是一个反转函数,也就是,将c中数据反转一下
return c;
}
vector<int> max_vec(vector<int> a, vector<int> b)//这里是比较大数大小的方法
{
if (a.size() > b.size())
return a;
if (a.size() < b.size())
return b;
if (vector<int>(a.rbegin(), a.rend()) > vector<int>(b.rbegin(), b.rend()))
return a;
return b;
}
bool cmp(aaa a, aaa b)
{
return a.third < b.third;
}
基本数据结构
表达式计算
后缀表达式(O(N))
建立一个用于存数的栈,逐一扫描表达式中的元素
如是数,则把该数入栈
如是运算符,则取栈顶的两个数进行计算,并把结果入栈
扫描完成后,栈中剩下的那个数就是该表达式的值
中缀表达式转后缀表达式(O(N))
建立一个用于存运算符的栈,逐一扫描该中缀表达式中的元素
如果遇到一个数,则输出
如果遇到左括号,则把左括号入栈
如果遇到右括号,则不断取出栈顶并输出,直到栈顶为左括号,然后把左括号出栈
如果遇到运算符,则只要栈顶符号的优先级不低于新符号,就不断取出栈顶并输出,最后把新符号入栈(乘除 > 加减 > 左括号)
依次取出并输出栈中所有剩余符号,最终输出的序列就是对应的后缀表达式
中缀表达式递归求法 O(N^2)
目标:求解S[1~N]
拆解:求解S[L~R]
1.在L~R中考虑没有被人和括号包含的运算符
若存在加减号,选其中最后一个,分成左右两部分递归,结果相加减,返回 //即,加减优先级小于乘除,所以,先查找加减,再查找乘除
若存在乘除号,选其中最后一个,分成左右两部分递归,结果相乘除,返回
2.若不存在没有被任何括号包含的运算符
若首位字符是括号,则递归求解S[l+1~R-1],返回
否则说明S[L~R]是一个数,直接返回数值
对光标操作
对顶栈
单调栈算法(O(N))
借助单调性处理问题的思想,及时排除不可能的选项,保证策略集合的高度有效性和秩序性
单调队列算法(O(N))
在决策集合中及时排除一定不是最优解的选项
链表实现形式
指针形式
struct Node
{
int value;
Node *prev,*next;
};
Node *head,*tail;
void initilaize()
{
head = new Node();
tail = new Node();
head->next = tail;
tail->prev = head;
}
void insert(Node *p , int val)
{
q = new Node();
q->value = val;
p->next->prev = q;
q->next = p->next;
p->next = q;
q->prev = p;
}
void remove(Node *p)
{
p->prev->next = p->next;
p->next->prev = p->prev;
delete p;
}
void recycle()
{
while(head != tail)
{
head = head->next;
delete head->prev;
}
delete tail;
}
数组形式
struct Node
{
int value;
int prev , next;
}node[SIZE];
int head , tail , tot;
int initialize()
{
tot = 2;
head = 1 , tail = 2;
node[head].next = tail;
node[tail].prev = head;
}
int insert(int p , int val)
{
q = ++tot;
node[q].value = val;
node[node[p].next].prev = q;
node[q].next = node[p].next;
node[p].next = q;
node[q].prev = p;
}
void remove(int p)
{
node[node[p].prev].next = node[p].next;
node[node[p].next].prev = node[p].prev;
}
void clear()
{
memset(node , 0 , sizeof(node));
heaad = tail = tot = 0;
}
邻接表
Hash
Hash表又称为散列表,一般由Hash函数(散列函数)与链表结构共同实现.
当要对若干复杂信息进行统计时,可以用Hash函数把这些信息映射到一个容易维护的值域内
字符串Hash
作用 : 把一个任意长度的字符串映射成一个非负整数且冲突概率几乎为0
方式 : 取一固定值P(一般取131/13331),把字符串看作P进制数,并分配一个大于0的数值,代表每种字符(一般分配的数值都远小于P)
取一固定值M,求出该P进制数对M的余数,作为该字符串的Hash值(如果是unsigned long long 的话,可以不取M,自动对2^64取模)
如果为了进一步确定,可以多取一些恰当的q和M的值,只有结果都为相同的数据才认定为相同数据
已知H(S),H(S+T)
H(T) = (H(S+T) - H(S)*p^length(T))mod M
O(N)预处理字符串所有前缀Hash值,O(1)查询任何子串的Hash值
最长回文串
#include <bits/stdc++.h>
using namespace std;
unsigned long long f[1000006], p[1000006], ff[1000006];//f和ff分别是正方向和反方向的前缀和
char strr[1000006];
int n;
int jisuan(int a)
{
int P = 1, q = 0;//采用倍增算法来优化时间复杂度
while (P)
if (a - (q + P) - 1 >= 0 && a + (q + P) + 1 <= n + 1 && f[a] - f[a - (q + P) - 1] * p[(q + P) + 1]
== ff[a] - ff[a + (q + P) + 1] * p[(q + P) + 1])
q += P, P *= 2;
else
P /= 2;
P = 1;
int t = 0;
while (P)
if (a - (t + P) - 1 >= 0 && a + (t + P) <= n + 1 && f[a - 1] - f[a - (t + P) - 1] * p[(t + P)]
== ff[a] - ff[a + (t + P)] * p[(t + P)])
t += P, P *= 2;
else
P /= 2;
return max(q * 2 + 1, t * 2);//返回最大的回文字符串长度
}
int main()
{
scanf("%s", strr + 1);
int now = 1;
while (1)
{
if (strr[1] == 'E' && strr[2] == 'N' && strr[3] == 'D')
break;
n = strlen(strr + 1);
p[0] = 1;
f[0] = ff[n + 1] = 0;
for (int i = 1; i <= n; i++)
{
f[i] = f[i - 1] * 131 + (strr[i] - 'a' + 1);
p[i] = p[i - 1] * 131;
ff[n - i + 1] = ff[n - i + 2] * 131 + (strr[n - i + 1] - 'a' + 1);//构造"后缀和"(反方向构造前缀和)
}
int maxx = 0;
for (int i = 1; i <= n; i++)
{
maxx = max(maxx, jisuan(i));
}
cout << "Case " << now++ << ": " << maxx << '\n';
scanf("%s", strr + 1);
}
return 0;
}
KMP模式匹配(O(N+M)) 判断子串
next数组求法
next[1] = 0;
for(int i = 2 , j = 0;i <= n; i++)
{
while(j > 0 && a[i] != a[j+1]) j = next[j];
if(a[i] == a[j+1]) j++;
next[i] = j;
}
f数组求法(f[i]表示B中以i结尾的子串与A的前缀能匹配的最大长度)
for(int i = 1,j = 0; i <= m; i++)
{
while(j > 0 && (j == n || b[i] != a[j+1])) j = next[j];
if(b[i] == a[j+1]) j++;
f[i] = j;
// f[i] == n 时,为A在B中的一次出现
}
最小循环元
S[1~i]具有长度为len<i的循环元的充要条件是len能整除i,且S[len+1 ~ i] = S[1~i - len]
#include <bits/stdc++.h>
using namespace std;
char a[1000010];
int Next[1000010], n, t;
void calc_Next()
{
Next[1] = 0;
for (int i = 2, j = 0; i <= n; i++)
{
while (j > 0 && a[i] != a[j + 1])
j = Next[j];
if (a[i] == a[j + 1])
j++;
Next[i] = j;
}
}
int main()
{
while (cin >> n && n)
{
cin >> a + 1;
calc_Next();
cout << "Test case #" << ++t << '\n';
for (int i = 2; i <= n; i++)
{
if (i % (i - Next[i]) == 0 && i / (i - Next[i]) > 1)
cout << i << ' ' << i / (i - Next[i]) << '\n';
}
cout << '\n';
}
return 0;
}
最小表示法(循环同构的字符串中字典序最小的那个)(O(N))
int n = strlen(s + 1);
for(int i = 1; i <= n;i++) s[n+i] = s[i];
int i = 1,j = 2,k;
while(i <= n && j <= n)
{
for(k = 0;k < n && s[i + k] == s[j + k]; k++);
if(k == n) break;
if(s[i+k] > s[j+k])
{
i = i + k + 1;
if(i == j) i++;
}
else
{
j = j + k + 1;
if(i == j) j++;
}
}
ans = min(i , j);//B[ans]是最小表示
字典树(字符串快速检索)
初始化:
仅包含一个根节点,该点的字符指针均指向空
插入:
字符串S,令指针P起初指向根节点.然后,依次扫描S中的每个字符c:
若P的c字符指针指向一个已经存在的结点Q,则令P = Q;
若P的c字符指针指向空,则新建一个节点Q,令P的c字符指针指向Q,然后令P = Q
当S中的字符扫描完毕时,在当前结点P上标记它是一个字符串的末尾
检索:
字符串S,令指针P起初指向根节点,然后,依次扫描S中的每个字符c:
若P的c字符指针指向空,这说明S没有被插入过Trieste,结束检索;
若P的c字符指针指向一个已经存在的节点Q,则令P = Q;
当S中的字符扫描完毕时,若当前节点P被标记为一个字符串的末尾,则说明S在Trie中存在,否则说明S没有被插入过Trie
小写字母构成的字典树代码示例
int trie[SIZE][26], tot = 1;
void insert(char* str)
{
int len = strlen(str) , p = 1;
for(int k = 0;k < len; k++)
{
int ch = str[k] - 'a';
if(trie[p][ch] == 0) trie[p][ch] = ++tot; // 如果为空节点,则创建新节点,并且自动与父节点相连(p)
p = trie[p][ch];
}
end[p] = true;
}
bool search(char* str)
{
int len = strlen(str) , p =1;
for(int k = 0;k < len; k++)
{
p = trie[p][str[k] - 'a'];
if(p == 0) return false;
}
return end[p];
}
N中选2,两整数进行xor运算,求最大值
#include <bits/stdc++.h>
using namespace std;
long long a;
int trie[3200005][2], tot = 1;
void insert(long long val)
{
int p = 1;
for (int k = 31; k >= 0; k--)
{
int ch = ((val >> k) & 1);
if (trie[p][ch] == 0)
trie[p][ch] = ++tot;
p = trie[p][ch];
}
}
long long ans;
void find(long long vall)
{
int p = 1;
for (int k = 31; k >= 0; k--)
{
int t = p;
p = trie[p][(((vall >> k) & 1) + 1) % 2];//这里是标准化一下,属于是自认为的简化代码操作
if (p == 0)
{
p = trie[t][(vall >> k) & 1];
}
else
{
ans += (1 << k);
}
}
}
int main()
{
int n;
cin >> n;
long long sum = 0;
cin >> a;
insert(a);
for (int i = 1; i < n; i++)
{
cin >> a;
ans = 0;
find(a);
insert(a);
sum = max(sum, ans);
}
cout << sum;
return 0;
}
二叉堆(或直接用优先队列)
//Insert
//向二叉堆中插入一个带有权值val的新节点,
//把这个新节点直接放在储存二叉堆的数组末尾,然后通过交换的方式向上调整,
//时间复杂度为堆的深度,即O(logN)
int heao[SIZE], n;
void up(int p)
{
while(p > 1)
{
if(heap[p] > heap[p/2])
{
swap(heap[p] , heap[p/2]);
p/=2;
}
else break;
}
}
void insert(int val)
{
heap[++n] = val;
up(n);
}
//GetTop
//获取二叉堆顶的权值(最大值/最小值)
int GetTop()
{
return heap[1];
}
//Extract
//把堆顶从二叉堆中移除,
//把堆顶heap[1]与末尾结点heap[n]交换,然后移除数组末尾节点(n--),把堆顶通过交换向下调整
//时间复杂度为堆的深度,即O(logN)
void down(int p)
{
int s = p * 2;
while(s <= n)
{
if(s < n && heap[s] < heap[s+1]) s++;
if(heap[s] > heap[p])
{
swap(heap[s] , heap[p]);
p = s, s = p*2;
}
else break;
}
}
void Extract()
{
heap[1] = heap[n--];
down(1);
}
//Remove
//把存储在数组下标为p位置的节点从二叉堆中删除
void Remove(int k)
{
heap[k] = heap[n--];
up(k) , down(k);
}
Huffman树(哈夫曼树)
二叉Huffman树
建立一个小根堆,插入这n个叶子节点的权值
从堆中取出(并删除)两个最小的权值w1和w2,令ans= w1 + w2
建立一个新的树子节点w1+w2,令其成为w1和w2节点的父亲
在堆中插入权值w1 + w2
重复2-4行,直至堆的大小为1
k叉Huffman树
要使叶子节点的个数n满足(n-1)mod(k-1) = 0(不足补0),其余相同
搜索
树与图的深度优先遍历,树的DFS序、深度和重心
图的深度优先遍历
//深度优先遍历,就是在每个点x上面对多条分支时,任意选一条边走下去,执行递归,直至回溯到点x后,在考虑走向其他边
void dfs(int x) (O(N+M))
{
v[x] = 1;
for(int i = head[x];i;i = next[i])
{
int y = ver[i];
if(v[y]) continue;
dfs(y);
}
}
时间戳
按照深度优先遍历的过程,以每个节点第一次被访问的顺序,依次给予这N个节点1~N的整数标记,该标记被称为时间戳,记为dfn
树的dfs序(可把子树统计转化为序列上的区间统计),树的深度
特点:每个节点x的编号在序列中恰好出现两次.且设两次出现的位置为L[x]和R{x],那么闭区间[L[x],R[x]]就是以x为根的子树的DFS序
//在对树进行深度优先遍历时,对于每个节点,在刚进入递归后以及即将回溯前各记录一次该点的编号,最后产生的长度为2N的节点序列称为dfs序
//树的深度为自顶向下统计
void dfs(int x)
{
a[++m] = x;//以a数组储存DFS序
v[x] = 1;
for(int i = head[x];i;i = next[i])
{
int y = ver[i];
if(v[y]) continue;
//d[y] = d[x] + 1; // 树的深度,从父节点x到子节点y递推,计算深度
dfs(y);
}
a[++m] = x;
}
二叉树的前,中,后序遍历
typedef struct TreeNode
{
int data;
TreeNode * left;
TreeNode * right;
TreeNode * parent;
}TreeNode;
void pre_order(TreeNode * Node)//前序遍历递归算法
{
if(Node == NULL)
return;
printf("%d ", Node->data);//显示节点数据,可以更改为其他操作。在前面
pre_order(Node->left);
pre_order(Node->right);
}
void middle_order(TreeNode *Node)//中序遍历递归算法
{
if(Node == NULL)
return;
middle_order(Node->left);
printf("%d ", Node->data);//在中间
middle_order(Node->right);
}
void post_order(TreeNode *Node)//后序遍历递归算法
{
if(Node == NULL)
return;
post_order(Node->left);
post_order(Node->right);
printf("%d ", Node->data);//在最后
}
图的重心
//图的重心为自底向上统计
//对于一个节点x,如果我们把它从树中删除,那么原来的一棵树可能会分成若干个不相连的部分,其中每一部分都是一颗子树,设max_part(x)表示删除节点x后产生的子树中,最大的一棵的大小,使max_part函数取到最小值的节点p就称为整棵树的重心
void dfs(int x)
{
v[x] = 1 ;size[x] = 1;//子树x的大小
int max_part = 0; //删掉x后分成的最大子树的大小
for(int i = head[x];i;i = next[i])
{
int y = ver[i];
if(v[y]) continue; //点y已被访问过
dfs(y);
size[x] += size[y];//从子节点向父节点递推
max_part = max(max_part,size[y]);
}
max_part = max(max_part , n - size[x]);//n为整棵树的节点数
if(max_part < ans)
{
ans = max_part;//全局变量ans记录重心对应的max_part
pos = x; // 全局变量pos记录了重心
}
}
图的连通块划分(森林的树划分)
//cnt为无向图包含的连通块的个数,v数组标记了每个点属于哪一个连通块
void dfs(int x)
{
v[x] = cnt;
for(int i = head[x];i;i = next[i])
{
int y = ver[i];
if(v[y]) continue;
dfs(y);
}
}
//在int main中
for(int i = 1;i <= n; i++)
{
if(!v[i])
{
cnt++;
dfs(i);
}
}
树与图的广度优先遍历,拓扑排序
图的广度优先遍历(树的层次遍历) O(N+M)
性质:
1.在访问完所有的第i层节点后,才会开始访问第i+1层节点
2.任一时刻,队列中至多有两个层次的节点.并且所有第i层节点排在第i+1层节点之前 ---- 广度优先遍历队列中的元素关于层次满足两段性和单调性
//树和图的广度优先遍历需要使用一个队列实现.起初,队列中仅包含一个起点(根节点),在广度优先遍历的过程中,我们不断从队头取出一个节点x,对于x面对的多条分支,把沿着每条分支到达的下一个结点(如果尚未访问过)插入队尾,重复执行上述过程直到队列为空
void bfs()
{
msmset(d,0,sizeof(d));
queue<int> q;
q.push(1);//1为作为起点的节点
d[1] = 1;//深度(层次---从起点到点x需要经过的最少点数)
while(q.size() > 0)
{
int x = q.front();
q.pop();
for(int i = head[x];i;i = next[i])
{
int y = ver[i];
if(d[y]) continue;
d[y] = d[x] + 1;
q.push(y);
}
}
}
拓扑排序(可以判断图中是否存在环)
-----对任意有向图执行拓扑排序后检查序列A的长度.若A的长度小于图中点的数量,则说明某些节点未被遍历,进而说明图中存在环.
(环的入度不可能为0)
给定一张有向无环图,若一个由图中所有点构成的序列A满足:
对于图中的每个边(x,y),x在A中都出现在y之前,则称A是该有向无环图顶点的一个拓扑序,求解A的过程就称为拓扑排序.
思想:不断选择图中入度(以其为终点的边的条数)为0的节点x,然后把x连向的点的入度减一
过程:
/%
1.建立空的拓扑序列A
2.预处理出所有点的入度deg[i],起初吧所有入度为0的点入队
3.取出队头节点x,把x加入拓扑序列A的末尾
4.对于从x出发的每条边(x,y),把deg[y]减1.若被减为0,则把y入队
5.重复第3~4步操作直到队列为空,此时A即为所求
%/
void add(int x,int y) // 在邻接表中添加一条有向边
{
ver[++tot] = y,next[tot] = head[x], head[x] = tot;
}
void topsort() // 拓扑排序
{
queue<int> q;
for(int i = 1; i<= n ; i++)
{
if(deg[i] == 0) q.push(i);
}
while(q.size())
{
int x= q.front();
q.pop();
a[++cnt] = x; //a数组为拓扑排序结果
for(int i = head[x] ; i ; i = next[i])
{
int y = ver[i];
if(--deg[y] == 0) q.push(y);
}
}
}
int main()
{
cin >>n>>m;
for(int i = 1; i <= m; i++)
{
itn x,y;
scanf("%d%d",&x,&y);
add(x,y);
}
topsort();
for(int i = 1; i <= cnt ; i++)
{
printf("%d", a[i]);
}
cout<<endl;
return 0;
}
可达性统计(有向无环图中各点能够到达的点的数量)
1.先用拓扑排序求出一个拓扑序
2.按照拓扑序的倒序进行计算(利用二进制数(bitset)存储每个F(x)--点x所能达到的点数)
计算指前面的为它的直接后继节点的和+当前节点
深度优先搜索(回溯算法)
"深搜"是一类包括遍历形式,状态记录与检索,剪枝优化等算法整体设计的统称
我们称所有点(问题空间中的状态)与成功发生递归的边(访问两个状态之间的移动)构成的树为一棵"搜索树".
整个深搜算法就是基于该搜索树完成的
-----为了避免重复访问,我们对状态进行记录和检索:为了使程序更加高效,我们提前剪除搜索树上不可能是答案的子树和分支,不去进行遍历.
子集和问题(回溯算法+剪枝)
【问题描述】
子集和问题的一个实例为〈S,t〉。其中,S={ x1, x2,…, xn}是一个正整数的集合,c是一个正整数。子集和问题判定是否存在S的一个子集S1,使得子集S1和等于c。
【编程任务】
对于给定的正整数的集合S={ x1, x2,…, xn}和正整数c,编程计算S 的一个子集S1,使得子集S1和等于c。
【输入样例】
5 10
2 2 6 5 4
【输出样例】
2 2 6
#include<bits/stdc++.h>
using namespace std;
//含有剪枝
int a[999];//用于存储S的正整数集合
bool x[999];//用于记录各分支的结果情况
int tw=0,rw;//tw:当前整数和,rw:余下的整数和
bool flag=false;//记录是否有解
int n,c;
void backtrack(int i) {
if(i>n||flag==true)
return ;
if(tw==c) {
for(int j=0; j<i; j++)
if(x[j]==1)
cout<<a[j]<<" ";
flag=true;
return ;
}
if(tw+a[i]<=c) {//进入左子树,剪枝
x[i]=1;
tw=tw+a[i];
rw=rw-a[i];
backtrack(i+1);
tw=tw-a[i];
rw=rw+a[i];
}
if(tw+rw-a[i]>=c) {//进入右子树,剪枝
x[i]=0;
rw=rw-a[i];
backtrack(i+1);
rw=rw+a[i];
}
return ;
}
int main() {
cin>>n>>c;
for(int i=0; i<n; i++) {
cin>>a[i];
rw=rw+a[i];
}
backtrack(0);
if(flag==false)
cout<<"No Solution!\n";
return 0;
}
/*
5 10
2 2 6 5 4
2 2 6
*/
剪枝
1.优化搜索顺序
通过调整搜索顺序,来调整搜索树的各个层次,各个分支之间的顺序,通过减少分支数量来优化
2.排除等效冗余
如果能判定从搜索树的当前节点上沿着某几条不同分支到达的子树是等效的,那么只需要对其中的一条分支执行搜索
如先A后B和先B后A是一样的话,可以限制顺序
3.可行性剪枝(上下界剪枝)
及时对当前状态进行检查,如果发现分支已经无法到达递归边界,就执行回溯
4.最优性剪枝
如果当前花费的代价已经超过了当前搜到的最优解,那么此时可以停止对当前分支的搜索,执行回溯
5.记忆化
可以记录每个状态的搜索结果,在重复遍历一个状态时直接检索并返回.这就好比对图进行深度优先遍历时,标记一个节点是否已经被访问过(树形状态空间不用记录,因为不会重复访问)
搜索算法面对的状态可以看做一个多元组,其中每一元都是问题状态空间中的一个维度
搜索过程中的剪枝其实就是针对每个维度与该维度的边界条件,加以缩放和推导,得出一个相应的不等式,来减少搜索树分支的扩张
为了进一步提高剪枝的效果,除了当前花费的代价之外,我们还可以对未来至少需要花费的代价进行预算,这样更容易接近每个维度的上下界
*Dancing Links数据结构 ------- 精确覆盖问题
迭代加深
迭代加深思想:从小到大限制搜索的深度,如果在当前深度限制下搜不到答案,就把深度限制增加,重新进行一次搜索
虽然在深度限制在d时会重复1~d-1层的节点,但当搜索树节点分支数目较多时,随着层数的深入,每层节点数会呈指数级增长
当搜索树规模随着层次的深入增长很快,并且我们能够确保答案在一个较浅层的节点时,就可以采用迭代加深搜索的深度优先搜索算法来解决问题(甚至有些题目描述里会包含"如果10步以内搜不到结果就算无解"的字样)
双向搜索(双向DFS)
在一些题目中,问题不但具有"初态",还具有明确的"终态",并且从初态开始搜索和从终态开始逆向搜索产生的搜索树都能覆盖整个状态空间.
在这种情况下,就可以采用双向搜索-----从初态和终态出发各搜索一半状态,产生两颗深度减半的搜索树,在中间交会,组合成最终的答案.
广度优先搜索
注意:
地图边界的检查,记录数组d的初始化,用方向常数数组避免多个if(可用0,1,2,3指代上下左右四个方向)
广度优先搜索相当于对问题状态空间的广度优先遍历
借助队列来实现
起初,队列中仅包含起始状态,在广度优先搜索的过程中,我们不断从队头取出状态,对于该状态面临的所有分支,把沿着每条分支到达的下一个状态(如果尚未访问过或者能够被更新成更优的解)插入队尾,重复执行上述过程直到队列为空
善于解决"走地图"类问题-----“给定义一个矩形地图,控制一个物体在地图中按要求移动,求最少步数”
地图的整体形态固定不变,只有少数个体或特征随着每一步操作发生改变,我们只需要把这些变化的部分提取为状态,把起始状态加入队列.
广度优先搜索是逐层遍历搜索树的算法,所有状态按照入队的先后顺序具有层次带调性(也就是步数单调性).如果每一次扩展恰好对应一步,那么当一个状态第一次被访问时,就得到了从起始状态到达该状态的最少步数
技巧:
使用常数数组预先保存各种变化情况,避免使用大量if语句造成混乱
flood-fill算法
给定一个N*M的01矩阵和一个起点(0表示可通行点,1表示禁止点),每一步可以向上,下,左,右四个方向之一移动1单位距离,求从起点出发能够到达哪些位置,以及到达每个位置的最少步数.
在具有多个等价的起始状态的问题中,只需要在BFS开始之前把这企鹅起始状态全部插入队列.根据BFS逐层搜索的性质,每个位置第一次被访问时,就相当于距离它最近的那个起点拓展到了它,此时,从那个起点经历的步数就是最短距离.
广搜变形
双端队列BFS
对一张边权要么是0,要么是1的无向图,我们可以通过双端队列广搜来计算.算法的整体框架与一般的广搜类似,只是在每个节点上沿分支扩展时稍作改变:(保证了"两段性"和"单调性")
如果这条分支是边权为0的边,就把沿该分支到达的新节点从队头入队;
如果这条分支是边权为1的边,就像一般的广搜一样从队尾入队.
优先队列BFS O(NlogN) Dijkstra算法
对于更加具有普适性的情况,也就是每次扩展都有各自不同的代价时,求出起始状态到每个状态的最小代价,就相当于在一张带权图上求出从起点到每个节点的最短路
用优先队列进行广搜
在优先队列中,每个状态会被多次更新,多次进出队列,一个状态也可能以不同的代价在队列中同时存在.不过,当每个状态第一次从队列中被取出时,就得到了从起始状态到该状态的最小代价,之后若再被取出,则可以直接忽略,不进行扩展
双向BFS
思想同双向DFS(双向搜索)
以普通的求最少步数的双向BFS为例,只需从起始状态,目标状态分别开始,两边轮流进行,每次个扩展一整层.当两边各自有一个状态在记录数组中发生重复时,就说明这两个搜索过程相遇了,可以合并得出起点到终点的最少步数.
A*
带有估值函数f的优先队列BFS算法
用于求从初态到给定的一个目标状态的最小代价
估值函数:以任意状态输入,计算出从该状态到目标状态所需代价的估计值
基本准则(即估值不能大于未来实际代价)
设估计值为f(state)
实际最小代价为g(state)
g(state)<=g(state)
还应该尽可能反映未来实际代价的变化趋势和相对大小关系
只要能保证对于任意状态state都有f(state)<=g(state),A,B算法就一定能在目标状态第一次被从堆中取出时得到最优解,并且在搜索过程中每个状态只需要被扩展一次(之后再取出可以直接忽略),f(state)越准确,越接近g(state),A,B算法的效率就越高,个如果估价始终为0,就等价于普通的优先队列DFS
例:
在求第k短路问题中,可以把估价函数f(x)定为从x到T(终点)的最短路长度
IDA*
A*算法的本质是带有估值函数的优先队列BFS算法,有一个显而易见的缺点,就是需要维护一个二叉堆来存储状态及其估价,耗费空间较大,并且对堆进行一次操作也要花费O(logN)的时间
如果将估价函数与迭代加深的DFS算法结合,设计一个估价函数,估算从每个状态到目标状态需要的步数.然后以迭代加深的DFSDE搜索框架为基础,把原来简单的深度限制加强为:若当前深度+未来估计步数>深度限制,则立即从当前分支回溯(这就是IDA*算法)
数学知识
质数
若一个正整数无法被除了1和它本身之外的任何自然数整除,则称该数为质数(素数),否侧称该数为合数
对于一个足够大的整数N,不超过N的质数大约有N/lnN个,即lnN个数中大约有一个素数
质数的判定
试除法(O(sqrt(N))
//扫描2~sqrt(N)之间的所有整数,一次检查他们能否整除N,若都不能整除,则N是质数,否则为合数
//并且需要特判0和1这两个整数,它们既不是质数,也不是合数
//确定性算法
bool is_prime(int n)
{
if(n < 2) return false;
for(int i = 2; i <= sqrt(n); i++)
{
if(n % i == 0) return false;
}
return true;
}
还有一些效率更高的随机性算法,如"Miller-Robbin"等,有较小概率把合数错误判定为质数,但多次判定合起来的错误概率趋近于零
质数的筛选
给定一个整数N,求出1~N之间的所有质数
Eratosthenes筛法
埃拉托斯特尼筛法 (O(NloglogN) 接近线性
思想:任意整数x的倍数23x,3x…都不是质数
过程:从2开始,有小到大扫描每个数x,把他的倍数2x,3x,…floor(N/x)*x标记为合数.
当扫描到一个数时,若它尚未被标记,则它不能被2~x-1之间的任何数整除,该数就是质数
优化:对于每个数,我们只需要从x2开始,把x2,(x+1) * x…floor(N/x) * x标记为合数即可
void primes(int n)
{
memset(v,0,sizeof(v));//合数标记
for(int i = 2; i <= n; i++)
{
if(v[i]) continue;
cout << i << endl;
for(int j = i; j <= n/i; j++)
v[i*j] = 1;
}
}
线性筛法 O(N)
通过"从大到小累积质因子"的方式标记每个合数,即让12只有3 * 2 * 2一种产生方式.设数组v记录每个数的最小质因子,按以下步骤维护v:
1.依次考虑2~N之间的每一个数i;
2.若v[i] = i,说明i是质数,把它保存下来
3.扫描不大于v[i]的每个质数p,令v[i*p] = p,也就是在i的基础上累积一个质因子p,因为p<=v[i],所以p就是合数i * p的最小质因子.
int v[MAX_N],prime[MAX_N];
void primes(int n)
{
memset(v, 0, sizeof(v)); // 最小质因子
m = 0; //质数数量
for(int i = 2; i <= n; i++)
{
if(v[i] == 0)
{
v[i] = i;
prime[++m] = i;
}// i 是质数
//给当前的数i乘上一个质因子
for(int j = 1; j <= m; j++)
{
//i有比prime[j]更小的质因子,或者超出n的范围,停止循环
if(prime[j] > v[i] || prime[j] > n/i) break;
//prime[j]是合数i*prime[j]的最小质因子
v[i*prime[j] = prime[j];
}
}
for(int i = 1; i <= m; i++) cout << prime[i] << endl;
}
质因数分解
算数基本定理
任何一个大于1的正整数都能唯一分解为有限个质数的乘积
试除法
//结合质数判定的"试除法"和质数筛选的"Eratosthenes筛法",我们可以扫描2~floor(sqrt(N))的每个数d,若d能整除N,则从N中除掉所有的因子d,同时累计除去的d的个数.
//因为一个合数的因子一定在扫描到这个合数之前就从N中被除掉了,所以在上述过程中能整除N的一定是质数.最终就得到了质因数分解的结果
//易知时间复杂度为O(sqrt(N))
//若N没有被2~sqet(N)的数整除,则N是质数,无需分解
void divide(int n)
{
m = 0;
for(int i = 2; i <= sqrt(n); i++)
{
if(n % i == 0)
{
p[++m] = i,c[m] = 0;
while(n % i == 0) n/=i,c[m]++;//除掉所有的i
}
}
if(n > 1) //n是质数
p[++m] = n,c[m] = 1;
for(int i = 1; i <= m; i++)
{
cout << p[i] << '^' << c[i] << endl;
}
}
约数
若整数n除以整数d的余数为0,即d能整除n,则称d是n的约数,n是d的倍数,记为d|n
算术基本定理的推论

求N的正正约数集合–试除法 (O(sqrt(N))
//若d>=sqrt(N)是N的约数,则N/d<=sqrt(N)也是N的约数,即约数总是成对存在的(除了sqrt(N))
//因此,只要扫描1~sqrt(N),尝试d能否整除N,若能整出,则N/d也是N的约数
int factor[1600],m = 0;
for(int i = 1; i*i <= n; i++)
{
if(n % i == 0)
{
factor[++m] = i;
if(i != n/i) factor[++m] = n/i;
}
}
for(int i = 1; i <= m; i++)
{
cout << factor[i] << endl;
}
//推论:
//一个整数N的约数个数上界为2sqrt(N)
求1~N每个数的正约数集合—倍数法 (O(NlogN))

//对每个数d,1~N中以d为约数的数就是d的倍数
vector<int> factor[500010];
for(int i = 1; j <= n; i++)
for(int j = 1; j <= n/i; j++)
factor[i*j].push_back[i];
for(int i = 1; i <= n; i++)
{
for(int j = 0; j < factor[i].size(); j++)
cout << factor[i][j];
puts("");
}
//推论:
//1~N每个数的约数个数的总和大约是NlogN
最大公约数
若自然数d同时是自然数a和b的约数,则称d是a和b的公约数.在所有a和b的公约数中最大的一个,称为a和b的最大公约数,记为gcd(a,b)
若自然数m同时是自然数a和b的倍数,则称m是a和b的公倍数.在所有a和b的公倍数中最小的一个,称为a和b的最小公倍数,记为lcm(a,b)
定理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FhuWizIY-1675572431848)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122807.png)]
lcm(a,b) = a*b/gcd(a,b)
九章算术·更相减损术(高精度时使用)
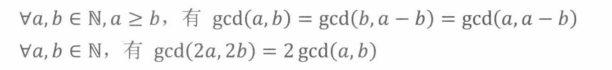
欧几里得算法(常用, O(log(a+b))
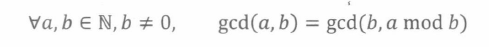
int gcd(int a,int b)
{
return b ? gcd(b , a % b) : a;
}
互质与欧拉函数
若gcd(a,b) = 1,则称a,b互质
对于三个数或更多数的情况,我们把gcd(a,b,c)= 1称为a,b,c互质,把gcd(a,b)=gcd(a,c)=gcd(b,c)=1称为a,b,c两两互质
1~N中与N互质的数的个数被称为欧拉函数,记为φ(N)
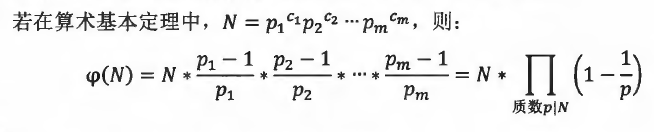
分解质因数并求出欧拉函数
int phi(int n)
{
int ans = n;
for(int i = 2; i <= sqrt(n); i++)
if(n % i == 0)
{
ans = ans / i * (i-1);
while(n % i == 0) n /= i;
}
if(n > 1) ans = ans/n*(n-1);
return ans;//ans即为欧拉函数的值
}
欧拉函数的性质
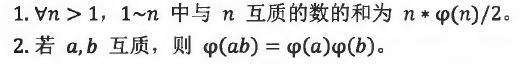
(与n互质的数的平均值是n/2)
积性函数:
如果当a,b互质时,有f(ab)=f(a)*f(b),那么称函数f为积性函数

狄利克雷卷积,莫比乌斯反演
同余
若整数a和整数b除以正整数m的余数相等,则称a,b模m同余,记为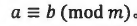
同余类与剩余系
对于任意a∈[0,m-1],集合{a+km}的所有数模m同余,余数都是a.该集合称为一个模m的同余类


费马小定理

欧拉定理
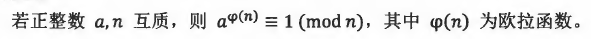
欧拉定理的推论
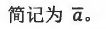

扩展欧几里得算法
Bezout定理
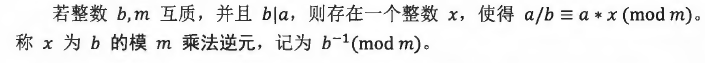
int exgcd(int a,int b, int &x, int &y)
{
if(b == 0)
{
x = 1, y = 0;
return a;
}
int d = exgcd(b, a%b, x, y);
int z = x;
x = y;
y = z - y * (a / b);
return d;
}
//求出方程ax+by=gcd(a,b)的一组特解,并返回a,b的最大公约数d
对于更为一般的方程ax+by=c,它有解当且仅当d|c.我们可以先求出ax+by=d的一组特解x0y0,然后令x0y0同时乘上c/d,就得到了ax+by=c的一组特解(c/d)x0,(c/d)y0

乘法逆元

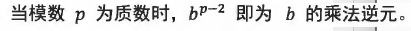

有了乘法逆元,在计数类问题中遇到a/b这样的除法算式,也可以先把a,b各自对模数p取模,再计算a*b^-1modp作为最终的结果(前提是必须保证b,p互质,当p是质数时,等价于b不是p的倍数)
线性同余方程
给定整数a,b,m,求一个整数x满足a*x==b(modm),或者给出无解.因为微指数的指数为1,所以我们称之为一次同余方程,也称线性同余方程
中国剩余定理

高次同余方程
Baby Step,Giant Step算法

int baby_step_giant_step(int a,int b,int p)
{
map<int,int> hash;hash.clear();
b %= p;
int t = (int)sqrt(p)+1;
for(int j = 0;j < t; j++)
{
int val = (long long)b * power(a, j, p) % p;//b*a^j
hash[val] = j;
}
a = power(a, t, p); // a^t
if(a == 0) return b == 0 ? 1 : -1;
for(itn i = 0; i <= t; i++)
{
int val = power(a, i, p); // (a^t)^i
int j = hash.find(val) == hash.end() ? -1 : hash[val];
if(j >= 0 && i * t - j >= 0) return i * t - j;
}
return -1;
}
矩阵乘法

矩阵乘法加速递推
特点:
可以抽象出一个长度为n的一维向量,该向量在每个单位时间发生一次变化
变化的形式是一个线性递推(只有若干"加法"或"乘一个系数"的运算)
该递推式在每个时间可能作用于不同的数据上,但本身保持不变
向量变化时间(即递推的轮数)很长,但向量长度n不大
方法:
我们把这个长度为n的一维向量称为"状态矩阵",把用于与"状态矩阵"相乘的固定不变的矩阵A称为"转移矩阵".若状态矩阵中的第x个数对下一单位时间状态矩阵中的第y个数产生影响,则把转移矩阵的第x行第y列赋值为适当的系数
矩阵乘法加速递推的关键在于定义出"状态矩阵",并根据递推式构造出正确的"转移矩阵",之后就可以利用快速幂和矩阵乘法完成程序实现.
时间复杂度为O(n^3logT),其中T为递推总轮数
例:斐波那契数列
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yuRFFnjO-1675572431854)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-13.png)]
const int mod = 10000;
int n;
void mul(int f[2], int a[2][2])
{
int c[2];
memset(c,0,sizeof(c));
for(int j = 0; j < 2 ; j++)
for(int k = 0; k < 2; k++)
c[j] = (c[j] + (long long)f[k] * a[k][j]) % mod;
memcpy(f,c,sizeof(c));
}
void mulself(int a[2][2])
{
int c[2][2];
memset(c, 0, sizeof(c));
for(int i = 0; i < 2; i++)
for(int j = 0; j < 2; j++)
for(int k = 0; k < 2; k++)
c[i][j] = (c[i][j] + (long long)a[i][k] * a[k][j]) % mod;
memcpy(a, c, sizeof(c));
}
int main()
{
while(cin >> n && n != -1)
{
int f[2] = {0,1};
int a[2][2] = {{0,1},{1,1}};
for(; n; n >>= 1)
{
if(n & 1) mul(f, a);
mulself(a);
}
cout << f[0] << endl;
}
}
高斯消元与线性空间
高斯消元
高斯消元是一种求解线性方程组的方法,所谓线性方程组,是由M个N元一次方程共同构成的.线性方程组的所有系数可以写成一个M行N列的"系数矩阵",再加上每个方程等号右侧的常数,可以写成一个M行N+1列的"增广矩阵"
求解这种方程组的步骤可以概括成对"增广矩阵"的三类操作(初等行变换):
用一个非零的数乘某一行
把其中一行的若干倍加到另一行上
交换两行位置
同理,也可以定义矩阵的"初等列变换"
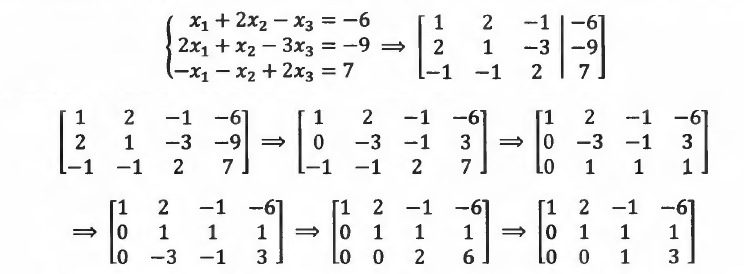
最后求得的矩阵被称为"阶梯形矩阵",它的系数矩阵部分被称为"上三角矩阵",名字来源于其形状,所表达的信息是: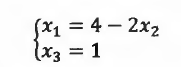
因此,我们已经知道了最后一个未知量的值,从下往上依次代回方程组,即可得到每个未知量的解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XeHyQenc-1675572431854)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-16.png)]
通过初等行变换把增广矩阵变为简化梯形矩阵的现象方程组求解算法就是高斯消元算法
思想:
对每个未知量xi,找到一个xi的系数非零,但x1~xi-1的系数都是零的方程,然后用初等黄变换把其他方程的xi的系数全部消成零(比较理想的情况)
特殊情况:
在高斯消元过程中,可能出现0=d这样的方程,其中d是一个非零常数.这表明某些方程之间存在矛盾,方程组无解
有可能找不到一个xi的系数非零,但x1~xi-1的系数都是零的方程,例如:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S049aRJD-1675572431855)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-17.png)]
上例中找不到x2的系数非零,但x1的系数为零的方程,方程组的解可以写作:
x2取任意值都可以计算出一个对应的x1,并且满足原方程组,即方程组有无穷多个解,我们把x1,x3这样的未知量称为"主元",把x2这样的未知量称为"自由元"
对于每个主元,整个简化阶梯形矩阵有且仅有一个位置(i,j),满足该主元的系数非零.第j列的其他位置都是零,第i行的第1~j-1列都是零
综上所述,在高斯消元完成后,若存在系数全为零,常数不为零的行,则方程组无解
若系数不全为零的行恰好有n个,则说明主元有n个,方程组有唯一解
若系数不全为零的行有k<n个,则说明主元有k个,自由元有n-k个,方程组有无穷多个解
例:

double a[20][20], b[20], c[20][20];
int n;
int main()
{
cin >> n;
for(int i = 1; i <= n+1; i++)
for(int j = 1; j <= n; j++) scanf("%lf", &a[i][j]);
//c:系数矩阵, b:常数, 二者一起构成增广矩阵
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
{
c[i][j] = 2 * (a[i][j] - a[i+1][j]);
b[i] += a[i][j] * a[i][j] - a[i+1][j] * a[i+1][j];
}
//高斯消元(数据保证有唯一解)
for(int i = 1; i <= n; i++)
{
//找到x[i]的系数不为0的一个方程
for(int j = 1; j <= n; j++)
{
if(fabs(c[j][i]) > 1e-8)
{
for(int k = 1; k <= n; k++) swap(c[i][k], c[j][k]);
swap(b[i], b[j]);
}
}
//消去其他方程x[i]的系数
for(int j = 1; j <= n; j++)
{
if(i == j) continue;
double rate = c[j][i] / c[i][i];
for(int k = i; k <= n; k++) c[j][k] -= c[i][k] * rate;
b[i] -= b[i] * rate;
}
}
for(int i = 1; i < n; i++) printf("%.3f", b[i] / c[i][i]);
printf("%.3f\n", b[n] / c[n][n]);
}
线性空间
线性空间是一个关于以下两个运算封闭的向量集合
1.向量加法a+b,其中a,b均为向量
2.标量乘法k*a,也称数乘运算,其中a是向量,k是常数(标量)
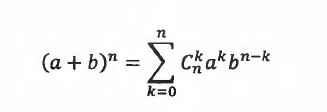



组合计数

组合数的求法
根据性质2,用递推法可以求出[0,n]的所有组合数Cxy,复杂度为O(n^2).
若题目要求出Cmn对一个数p取模后的值,并且1~n都存在模p乘法逆元,则可以先计算分子n!modp,再计算分母m!(n-m)!modp的逆元,乘起来得到Cmnmodp,复杂度为O(n)
若在计算阶乘的过程中,把[0,n]的每个k!modp及其逆元分别保存在两个数组jc和jc_inv中,则可以在O(nlogn)的预处理后,以O(1)的时间回答[0,n]的所有组合数C一些modp = jc[x] * jc_inv[y] * jc_inv[x-y] mod p
若题目要求我们对Cmn进行高精度运算,为避免除法,可用"阶乘分解"的做法,把分子,分母快速分解成质因数,在数组中保存各项质因子的质数.然后把分子,分母各个质因子的质数对应相减(把分母消去),最后把剩余质因子乘起来,时间复杂度为O(nlogn)
二项式定理

多重集的排列数

多重集的组合数

Lucas定理

Catalan数列


容斥原理与Mobius函数
容斥原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NIkxEXyl-1675572431859)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-31.png)]

Mobius函数

若只求一项Mobius函数,则分解质因数即可计算.若求1~N的每一项Mobius函数,可以利用Eratosthenes筛法计算,把所有u值初始化为1,接下来,对于筛出的每个质数p,令u§=-1,并扫描p的倍数,检查x能否被p^2整除.若能,令u(x)=0,否则,令u(x)=-u(x)
for(int i = 1; i <= n; i++) miu[i] = 1, v[i] = 0;
for(int i = 2; i <= n; i++)
{
if(v[i])
continue;
miu[i] = -1;
for(int j = 2 * i; j <= n; j += i)
{
v[j] = 1;
if((j/i) % i == 0) miu[j] = 0;
else miu[j] *= -1;
}
}
概率与数学期望



性质: 数学期望是线性函数,满足E(aX+bY) = a * E(X) + b * E(Y)

0/1分数规划



博弈论之SG函数
NIM博弈

定理: NIM博弈先手必胜,当且仅当
公平组合游戏ICG
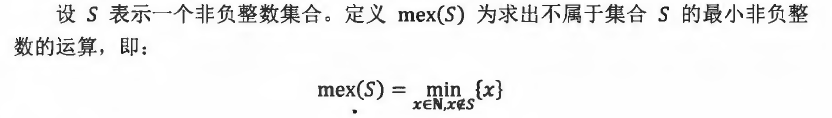
有向图游戏
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YJpf9ETf-1675572431863)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-44.png)]
Mex运算

SG函数

有向图游戏的和

定理
数据结构进阶
并查集
一种可以动态维护若干个不重叠的集合,并支持合并与查询的数据结构
并查集包括两个基本操作:
1.Get,查询一个元素属于哪一个集合.
2.Merge,把两个集合合并成一个大集合.
集合表示方法:“代表元"法,即为每个集合选择一个固定的元素,作为整个集合的"代表”
归属关系的表示方法:
第一种思路:维护一个数组f,用f[x]保存元素x所在集合的"代表"可以快速查询元素归属的集合,但在合并时需要修改大量元素的f值
第二种思路:使用一个树形结构存储每个集合,树上的每个节点都是一个元素,树根是集合的代表元素.整个并查集实际上是一个森林.我们仍然可以维护一个数组fa来记录森林,用fa[x]保存x的父节点.特别的,令树根fa值为它自己.这样一来,在合并两个集合时,只需连接两个树根(令其中一个树根为另一个树根的子节点).不过在查询元素的归属时,需要从该元素开始通过fa存储的值不断地柜访问父节点,直至到达树根,为提高查询效率,并查集引入了路径压缩和按秩合并两种思想
路径压缩和按秩合并
因为我们只关心每个集合对应的树形结构的根节点是什么,并不关心这棵树的具体形态,因此我们可以在每次执行Get操作的同时,把访问过的每个节点(也就是所查询元素的全部祖先)都直接指向树根,这种优化方法被称为路径压缩.采用路径压缩优化的并查集,每次Get操作的均摊复杂度为O(logN)

按秩合并:
所谓"秩",一般有两种定义.有的资料把并查集中集合的"秩"定义为树的深度(未路径压缩时).有的资料把集合的"秩"定义为集合的大小.无论采取哪种定义,我们都可以把集合的"秩"记录在"代表元素",也就是树根上.在合并时,都把"秩"较小的树根作为"秩"较大的树根的子节点.
当"秩"定义为 集合的大小时,“按秩合并"也称为"启发式合并”,它是数据结构相关问题中一种重要的思想,不只局限于并查集中.启发式合并的原则是:把"小的结构"合并到"大的结构"中,并且只增加"小的结构"的查询代价.这样一来,把所有结构全部合并起来,增加的总代价不会超过NlogN.故,单独采用"按秩合并"优化的并查集,每次Get操作的均摊复杂度也是O(logN)

实际应用中,我们一般只用路径压缩优化就足够了.
并查集的具体代码实现
//并查集的存储
//使用一个数组fa保存父节点(根的父节点设为自己)
int fa[SIZE];
//并查集的初始化
//设有n个元素,起初所有元素个字构成一个独立的集合,即有n棵1个点的树
for(int i = 1; i<= n; i++) fa[i] = i;
//并查集的Get操作
//若x是树根,则x就是集合代表,否则递归访问fa[x]直至根节点
int get(int x)
{
if(x == fa[x]) return x;
return fa[x] = get(fa[x]); // 路径压缩,fa直接赋值为代表元素
}
//并查集的Merge操作
//合并元素x和元素y所在的集合,等价于让x的树根作为y的树根的子节点
void merge(int x, int y)
{
fa[get(x)] = get(y);
}
并查集能在一张无向图中维护节点之间的连通性,这是它的基本用途之一
实际上,并查集擅长动态维护许多具有传递性的关系
"扩展域"与"边带权"的并查集
并查集实际上是由若干棵树构成的森林,我们可以在树中的每条边上记录一个权值,即维护一个数组d,用d[x]保存节点x到父节点fa[x]之间的边权.在每次路径压缩后,每个访问过的节点都会直接指向树根,如果我们同时更新这些节点的d值,就可以利用路径压缩过程来统计每个节点到树根之间的路径上的一些信息.
"扩展域"的并查集(没看懂)
树状数组


计算出区间[1,x]分成的O(logx)个小区间的代码:
while(x > 0)
{
printf("[%d, %d]\n", x - (x & -x) + 1,x);
x -= x & -x;
}

性质:


基本操作:
查询前缀和 O(logN)
int ask(int x)
{
int ans = 0;
for(; x; x-= x & -x) ans += c[x];
return ans;//ans即为x的前缀和
}
单点增加 O(logN)
意思是给序列中的一个数a[x]加上y,同时正确维护序列的前缀和.
只有节点c[x]及其所有祖先节点保存的区间和包含a[x],而任意一个节点的祖先至多只有logN个
void add(int x, int y)
{
for(; x <= N; x += x & -x) c[x] += y;
}
初始化方法
比较简便一般的初始化方法O(NlogN):
直接建立一个全为0的数组c.然后对每个位置x执行add(x,a[x]),就完成了对原始序列a构造树状数组的过程(通常足够)
更搞笑的初始化方法(O(N)):
从小到大依次考虑每个节点x,借助lowbit运算扫描它的子节点并求和.
树状数组与逆序对 O((N+M)logM),M为数值范围的大小
对于一个序列a,若i<j且a[i]>a[j],则称a[i]与a[j]构成逆序对,利用树状数组也可以求出一个序列的逆序对个数:

for(int i = n; i; i--)
{
ans += ask(a[i] - 1);
add(a[i], 1);
}
当数值范围较大时,当然可以先进行离散化,再用树状数组进行计算,但这种情况下不如直接用归并排序来计算逆序对数快捷方便
树状数组的扩展应用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oQxsnSgR-1675572431873)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-58.png)]
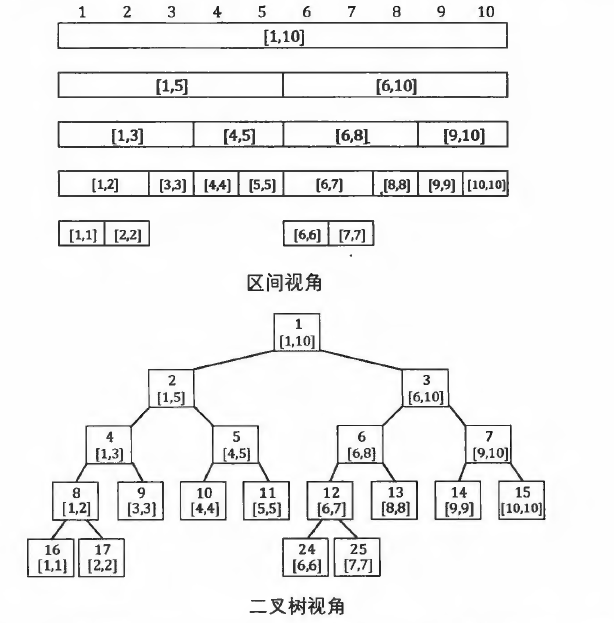
线段树
线段树是一种基于分治思想的二叉树结构,用于在区间上进行信息统计
除去树的最后一层,整棵线段树一定是一棵完全二叉树,树的深度为O(logN).因此,我们可以按照与二叉堆类似的"父子2倍"的节点编号方法:
1.根节点编号为1;
2.编号为x的节点的左子节点编号为x * 2,右子节点编号为x * 2+1
注意:保存线段树的数组长度要不小于4N才能保证不会越界
线段树的建树
线段树的基本用途为对序列进行维护,支持查询与修改指令.给定一个长度为N的序列A,我们可以在区间[1,N]上建立一棵线段树,每个叶节点[i,i]保存A[i]的值.线段树的二叉树结构可以很方便地从下往上传递信息.
例:区间最大值问题,dat(l,r) = max(dat(l,mid),dat(mid+1,r))
//建立一棵线段树并在每个节点上保存对应区间的最大值
struct SegmentTree
{
int l,r;
int dat;
}t[SIZE*4]; // struct数组存储线段树
void build(int p, int l, int r)
{
t[p].l = l, t[p].r = r;//节点p代表区间[l,r]
if(l == r) {t[p].dat = a[l]; return ;}//叶节点
int mid = (l + r) / 2;//折半
build(p*2, l, mid);//左子节点[l,mid],编号p*2
build(p*2+1, mid+1, r);//右子节点[mid+1,r],编号p*2+1
t[p].dat = max(t[p*2].dat, t[p*2+1].dat);//从下往上传递信息
}
build(1,1,n);//调用入口
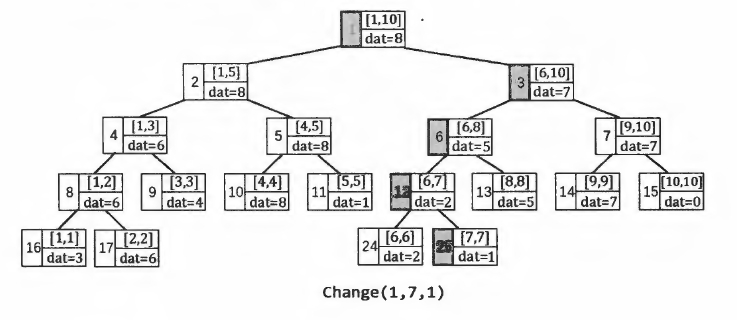
线段树的单点修改 O(logN)
单点修改是一条形如"Cxv"的指令,表示把A[x]的值修改为v
在线段树中,根节点(编号为1的节点)是执行各种指令的入口.我们需要从根节点出发,递归找到代表区间[x,x]的叶节点,然后从下往上更新[x,x]以及它的所有祖先节点上保存的信息
void change(int p, int x, int v)
{
if(t[p].l == t[p].r) { t[p].dat = v; return;} //找到叶节点
int mid = (t[p].l + t[p].r) / 2;
if(x <= mid) change(p*2, x, v); // x属于左半区间
else change(p*2+1, x, v); //x属于右半区间
t[p].dat = max(t[p*2].dat, t[p*2+1].dat); //从下往上更新信息
}
change(1, x, v); // 调用入口

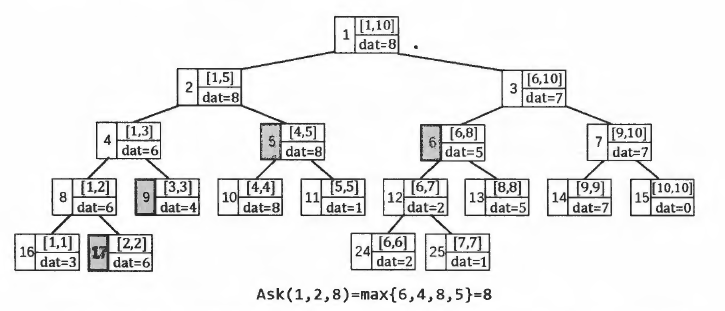
线段树的区间查询
区间查询是一条形如"Q l r"的指令,例如查询序列A在区间[l,r]上的最大值.我们只需要从根节点开始,递归执行以下过程:
1.若[l,r]完全覆盖了当前节点代表的区间,则立即回溯,并且该节点的dat值为候选答案.
2.若左子节点与[l,r]有重叠部分,则递归访问左子节点.
3.若右子节点与[l,r]有重叠部分,则递归访问右子节点.
int ask(int p, int l, int r)
{
if(了<= t[p].l && r >= t[p].r) return t[p].dat; //完全包含
int mid = (t[p].l + t[p].r) / 2;
int cal = -(1<<30); //负无穷大
if(l <= mid) val = max(val, ask(p*2, l, r)); //左子节点有重叠
if(r > mid) val = max(val, ask(p*2+1, l, r)); //右子节点有重叠
return val;
}
cout << aks(1, l, r) <, endl; //调用入口

该查询过程会把询问区间[l,r]在线段树上分成O(logN)个节点,取它们的最大值作为答案
延迟标记
在"区间修改"指令中,如果某个节点被修改区间[l,r]完全覆盖,那么以该节点为根的整棵子树中的所有节点存储的信息都会发生变化,若逐一进行更新,将使得一次区间修改指令的时间复杂度增加到O(N),这是我们不能接受的
如果我们在一次修改指令中发现节点p代表的区间[pl,pr]被修改区间[l,r]完全覆盖,并且逐一更新了子树p中的所有结点,但在之后的查询指令中根本没有用到[l,r]的子区间作为候选答案,那么更新p的整棵子树就是徒劳的
我们在执行修改指令时,同样可以在l<=pl<-pr<=r的情况下立即返回,只不过在回溯之前向节点p增加一个标记,标识"该节点曾经被修改,但其子节点尚未被更新".
如果在后续的指令中需要从节点p向下递归,我们再检查p是否具有标记.若有标记,就根据标记信息更新p的两个子节点,同时为p的两个子节点增加标记,然后清除p的标记.
也就是说,除了在修改指令中直接划分的O(logN)个节点之外,对于任一节点的修改都延迟到"在后续操作中递归进入它的父节点时"再执行.这样一来,每条查询或修改指令的时间复杂度都降低到了O(logN).这些标记被称为"延迟标记".延迟标记提供了线段树中从上往下传递信息的方式.这种"延迟"也是设计算法与解决问题的一个重要思路.

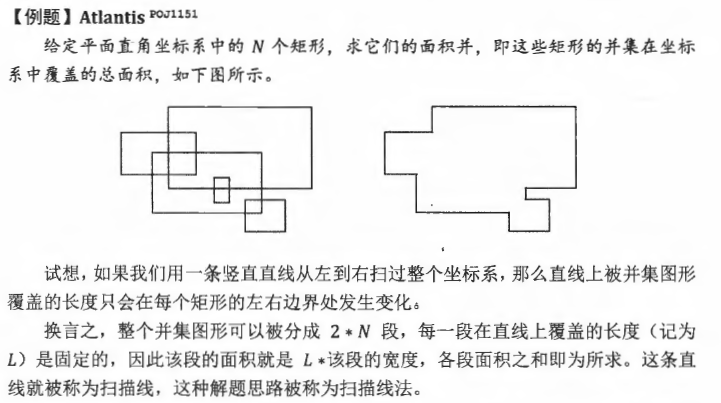
扫描线
具体来说,我们可以取出N个矩阵的左右边界.若一个矩阵的两个对角顶点坐标为(x1,y1)和(x2,y2),不妨设x1<x2,y1<y2,则左边界即为四元组(x1,y1,y2,1),右边界记为四元组(x2,y1,y2,-1).把这2N个四元组按照x递增排序
动态开点与线段树合并
在一些计数问题中,线段树用于维护值域(一段权值范围),这样的线段树也称为权值线段树.为了降低空间复杂度,我们可以不建出整棵线段树的结构,而是在最初只建立一个根节点,代表整个区间,当需要访问线段树的某棵子树(某个子区间)时,再简历代表这个子区间的节点.采用这种方法维护的线段树称为动态开点的线段树.动态开点的线段树抛弃了完全二叉树父子节点的2倍编号规则,改为使用变量记录左右子节点的编号(相当于指针).同时,他也不再保存每个节点代表的区间,而是在每次递归访问的过程中作为参数传递.
动态开点的线段树的节点机构
struct SegmentTree
{
int lc,rc;//左右子节点的编号
int dat;//区间最大值
}tr[SIZE * 2];
int root, tot;
int build()
{
//新建一个节点
tot++;
tr[tot].lc = tr[tot].rc = tr[tot].dat = 0;
return tot;
}
//在main函数中
tot = 0;
root = build(); //根节点
在动态开点的线段树中把val位置上的值加delta,同时维护区间最大值的操作
void insert(int p, int l, int r, int val, int delta)
{
if(l == r){tr[p].dat += delta; return ;}
int mid = (l + r) >> 1;//代表的区间[l,r]作为递归参数传递
if(val <= mid)
{
if(!tr[p].lc) tr[p].lc = build(); //动态开点
insert(tr[p].lc, l, mid, val, delta);
}
else
{
if(!tr[p].rc) tr[p].rc = build(); //动态开点
insert(tr[p].rc, mid + 1, t, val, delta);
}
tr[p].dat = max(tr[tr[p].lc].dat, tr[tr[p].rc].dat);
}
insert(root, 1, n, val, delta); //调用
一棵维护值域[1,n]的动态开点的线段树在经历m次单点操作后,节点数量的规模为O(mlogn),最终至多有2n-1个节点.
线段树合并算法 O(mlogn)
如果有若干棵线段树,他们都维护相同的值域[1,n],那么他们对各个子区间的划分显然是一致的.假设有m次单点修改操作,每次操作在某一棵线段树上执行.所有操作完成后,我们希望把这些线段树对应位置上的值相加,同时维护区间最大值.
我们依次合并这些线段树.合并两颗线段树时,用两个指针p,q从两个根节点出发,以递归的方式同步遍历两颗线段树.换句话说,p,q指向的节点总是代表相同的子区间.
1.p,q之一为空,则以非空的那个作为合并后的节点
2.p,q均不为空,则递归合并两颗左子树和两颗右子树,然后删除节点q,以p为合并后的节点,自底向上更新最值信息.若已到达叶子节点,则直接把两个最值相加即可.
int merge(int p, int q, int l, int r)
{
if(!p) return q; //p,q之一为空
if(!q) return p;
if(l == r)
{
//到达叶子
tr[p].dat += tr[q].dat;
return p;
}
int mid = (l + r) >> 1;
tr[p].lc = merge(tr[p].lc,tr[q].lc,l,mid);//递归合并左子树
tr[p].rc = merge(tr[p].rc,tr[q].rc,mid+1,r); //递归合并右子树
tr[p].dat = max(tr[tr[p].lc].dat,tr[tr[p].rc].dat);//更新
return p; //以p为合并后的节点,相当于删除q
}
分块
树状数组基于二进制划分与倍增思想,线段树基于分治思想,他们之所以能够高效地在一个序列上执行指令并统计信息,就是因为他们把序列中的元素聚合成大大小小的"段",花费额外的代价对这些"段"进行维护,从而使得每个区间的信息可以快速的由几个已有的"段"结合而成.
但,树状数组与线段树也有其缺点,比如在维护较为复杂的信息(尤其是不满足区间可加,可减性的信息)时,显得吃力,代码实现也不是那么简单,直观.
本节,我们将介绍分块算法.分块的基本思想是通过适当的划分,预处理一部分信息并保存下来,用空间换取时间,达到时空平衡.事实上,分块更接近于"朴素",效率往往比不上树状数组与线段树,但是它更加通用,容易实现.
点分治
到目前为止,我们用数据结构处理的大多是序列上的问题.这些问题的形式一般是给定序列中的两个位置l和r,在区间[l,r]上执行查询或修改指令.如果给定一棵树,以及树上两个节点x和y,那么与"序列上的区间"相对应的就是"树上两点之间的路径".本节中介绍的点分治就是在一棵树上,对具有某些限定条件的路径静态地进行统计的算法.
略
二叉查找树与平衡树初步
在二叉树中,有两组非常重要的条件,分别是两类数据结构的基础性质.
其一是"堆性质",二叉堆以及高级数据结构中的所有可合并堆,都满足"堆性质".
其二就是本节即将探讨的"BST性质",他是二叉查找树以及所有平衡树的基础.
BST
给定一棵二叉树,树上的每个节点都带有一个数值,称为节点的"关键码".所谓"BST"性质是指,对于树中的任意一个节点:
1.该节点的关键码不小于它的左子树中任意节点的关键码;
2.该节点的关键码不大于它的右子树中任意节点的关键码.
满足上述性质的二叉树就是一颗"二叉查找树"(BST).显然,二叉查找树的中序遍历是一个关键码单调递增的节点序列.
BST的建立
为了避免越界,减少边界情况的特殊判断,我们一般在BST中额外插入一个关键码为正无穷和一个关键码为负无穷的节点.仅由这两个节点构成的BST就是一颗初始的空BST.
简便起见,在接下来的操作中,我们假设BST不会含有关键码相同的节点.
struct BST
{
int l,r; // 左右子节点在数组中的下标
int val; // 节点关键码
} a[SIZE]; // 数组模拟链表
int tot, root, INF = 1 <<30;
int New(int val)
{
a[++tot].val = val;
return tot;
}
void BUild()
{
New(-INF),New(INF);
root = 1, a[1].r = 2;
}
BST的检索
在BST中检索是否存在关键码为val的节点
设变量p等于根节点root,执行以下过程:
1.若p的关键码等于val,则已经找到.
2.若p的关键码大于val
(1)若p的左子节点为空,则说明不存在val
(2)若p的左子节点不为空,在p的左子树中递归进行检索
3.若p的关键码小于val
(1)若p的右子节点为空,则说明不存在val
(2)若p的右子节点不为空,在p的右子树中递归进行检索
int Get(int p, int val)
{
if(p == 0) return 0; // 检索失败
if(val == a[p].val) return p; //检索成功
return val < a[p].val ? Get(a[p].l, val) : Get(a[p].r, val);
}
BST的插入
在BST中插入一个新的值val(假设目前BST中不存在关键码为val的节点)
与BST的检索过程类似
在发现要走向的p的子节点为空,说明val不存在时,直接建立关键码为val的新节点作为p的子节点
void Insert(int &p, int val)
{
if(p == 0)
{
p = New(val); //注意p用的是引用,其父节点的l或r值会被同时更新
return ;
}
if(val == a[p].val) return ;
if(val < a[p].val) Insert(a[p].l, val);
else Insert(a[p].r, val);
}
BST求前驱/后继
以"后继"为例.val的"后继"指的是在BST中关键码大于val的前提下,关键码最小的节点.
初始化ans为具有正无穷关键码的哪个节点的编号.然后,在BST中检索val.在检索过程中,每经过一个节点,都检查该节点的关键码,判断能否更新所求的后继ans.
检索完成后,有三种可能的结果:
1.没有找到val,此时val的后继就在已经经过的节点中,ans即为所求
2.找到了关键码为val的节点p,但p没有右子树.与上一种情况相同,ans即为所求
3.找到了关键码为val的节点p,且p有右子树
从p的右子节点出发,一直向左走,就找到了val的后继
int GetNext(int val)
{
int ans = 2; //ans[2].val == INF
int p = root;
while(p)
{
if(val == a[p].val)
{
//检索成功
if(a[p].r > 0)
{
//有右子树
p = a[p].r;
//右子树一直向左走
while(a[p].l > 0) p = a[p].l;
ans = p;
}
break;
}
//每经过一个节点,都尝试更新后继
if(a[p].val > val && a[p].val < a[ans].val) ans = p;
p = val < a[p].val ? a[p].l : a[p].r;
}
return ans;
}
BST的节点删除
从BST中删除关键码为val的节点
首先,在BST中检索val,得到节点p.
若p的子节点个数小于2,则直接删除p,并令p的子节点代替p的位置,与p的父节点相连.
若p既有左子树又有右子树,则在BST中求出val的后继节点next.因为next没有左子树,所以可以直接删除next,并令next的右子树代替next的位置.最后,再让next节点代替p节点,删除p即可.
void Remove(int &p, int val)
{
//从子树p中删除值为val的节点
if(p == 0) return ;
if(val == a[p].val)
{
//已经检索到值为val的节点
if(a[p].l == 0)
{
//没有左子树
p = a[p].r;//右子树代替p的位置,注意p是引用
}
esle if(a[p].r == 0)
{
//没有右子树
p = a[p].l;//左子树代替p的位置,注意p是引用
}
else
{
//既有左子树,又有右子树
//求后继节点
int next = a[p].r;
while(a[next].l > 0) next = a[next].l;
//next一定没有左子树,直接删除
Remove(a[p].r, a[next].val);
//令节点next代替节点p的位置
a[next].l = a[p].l, a[next].r = a[p].r;
p = next; //注意p是引用
}
return;
}
if(val < a[p].val)
{
Remove(a[p].l, val);
}
else
{
Remove(a[p].r, val);
}
}
在随机数据中,BST依次操作的期望复杂度为O(logN).然而BST很容易退化.例如在BST中依次插入一个有序序列,将会得到一条链,平均每次操作的复杂度为O(N).我们称这种左右子树大小相差很大的BST是"不平衡"的.有很多方法可以维持BST的平衡,从而产生了各种平衡树.下面将介绍一种入门级平衡树----Treap.
Treap
满足BST性质且中序遍历为相同序列的二叉查找树是不唯一的.这些二叉查找树是等价的,它们维护的是相同的一组数值.在这些二叉查找树上执行同样的操作,将得到相同的结果.因此,我们可以在维持BST性质的基础上,通过改变二叉查找树的形态,使得树上的每个节点的左右子树大小达到平衡,从而使整棵树的深度维持在O(logN)级别
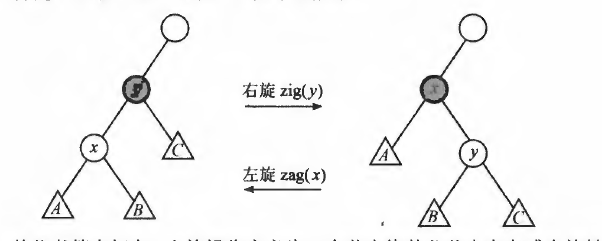
改变形态并保持BST性质的方法就是"旋转".最基本的旋转操作称为"单旋转",它又分为"左旋"和"右旋".
以右旋为例,在初始情况下,x是y的左子节点,A,B分别是x的左右子树,C是y的右子树.
"右旋"操作在保持BST性质的基础上,把x变为y的父节点.因为x的关键码小于y的关键码,所以y应该作为x的右子节点.
当x变成y的父节点后,y的左子树就空了出来,于是x原来的右子树B就恰好作为y的左子树.
代码如下:
//右旋代码,zig(p)可以理解成把p的左子节点绕着p向右旋转
void zig(int &p)
{
int q = a[p].l;
a[p].l = a[q].r, a[q].r = p;
p = q; // 注意p是引用
}
//左旋代码,zag(p)可以理解成把p的右子节点绕着p向左旋转
void zag(int &p)
{
int q = a[p].r;
a[p].r = a[q].l, a[q].l = p;
p = q; // 注意p是引用
}
合理的旋转操作可使BST变得更"平衡"
我们发现,在随机数据下,普通的BST就是趋于平衡的.Treap的思想就是利用"随机"来创造平衡条件.因为在旋转过程中必须维持BST性质,所以Treap就把"随机"作用在堆性质上.
Treap是英文tree和Heap的合成词.Treap在插入每个新节点时,给该节点随机生成一个额外的权值.然后像二叉堆的插入过成一样,自底向上依次检查,当某个节点不满足大根堆性质时,就执行单旋转,使该点与其父节点的关系发生对换.
特别地,对于删除操作,因为Treap支持旋转,我们可以直接找到需要删除的节点,并把它向下旋转成叶节点,最后直接删除.这样就避免了采取类似普通BST的删除方法可能导致的节点信息更新,堆性质维护等复杂问题.
总而言之,Treap通过适当的单旋转,在维持节点关键码满足BST性质的同时,还使每个节点上随机生成的额外权值满足大根堆性质.Treap是一种平衡二叉查找树,检索,插入,求前驱后继以及删除节点的时间复杂度都是O(logN)
除Treap以外,还有一些常见的平衡二叉查找树.其中STL的set,map就采用了效率很高的红黑树的一种变体.不过,大多数平衡树在算法竞赛等短时间程序设计中并不常用.在这些平衡树中Splay(伸展树)灵活多变,应用广泛,能够很方便地支持各种动态的区间操作,是用于解决复杂问题的一个重要的高级数据结构
离线分治算法
大多数数据结构问题都可以抽象为"维护一系列数据,并对一系列操作依次作出相应"的形式.这些操作一般分为统计数据信息的"查询"型操作和更新数据状态的"修改"型操作.其中执行各项操作的"顺序"是一个要点,我们把它称为"时间轴".
根据"查询"响应时间的不同,可以把解决上述数据结构问题的算法分为"在线"和"离线"两类.一个在线算法以此获得每项操作,并能够在每次"查询"时立即回答正确的结果,然后再继续下一次操作.一个离线算法需要预先知晓整个操作序列,经过一系列计算,最后再批量回答所有"查询"的结果.
根据两种操作在"时间"轴上分布的不同,可以把上述数据结构问题分成"动态"和"静态"两类.只包含"查询"型操作,或一切"查询"型操作都在一切"修改"型操作之后的问题称为静态问题,其余问题称为动态问题.
本节介绍的第一类分治算法提供了一种把动态问题划分为若干个静态子问题,并使用离线算法进行求解的框架.
基于时间的分治算法
对于操作序列中的每个"查询",计算其结果等价于计算"初始数据"以及"之前的所有修改"对该查询造成的影响

第三部分显然是一个"静态问题".该分治算法把一个动态问题划分为O(M)个静态问题,其中原始问题中每个"查询"的结果是由O(logM)个静态问题的结果共同组成的.
一般来说,一个静态问题要比动态问题简单许多.如果我们能在仅与r-l的规模相关(与M或整个数据集的规模无关)的时间复杂度内解决solve(l,r)的第三部分,那么整个分治算法解决动态问题的时间复杂度就仅比解决同类静态问题的时间复杂度多了O(logM)
这种离线分治算法是基于"时间"顺序对操作序列进行分治的,因此我们称它为基于时间的分治算法,又称CDQ分治算法.
基于值域的整体分治算法



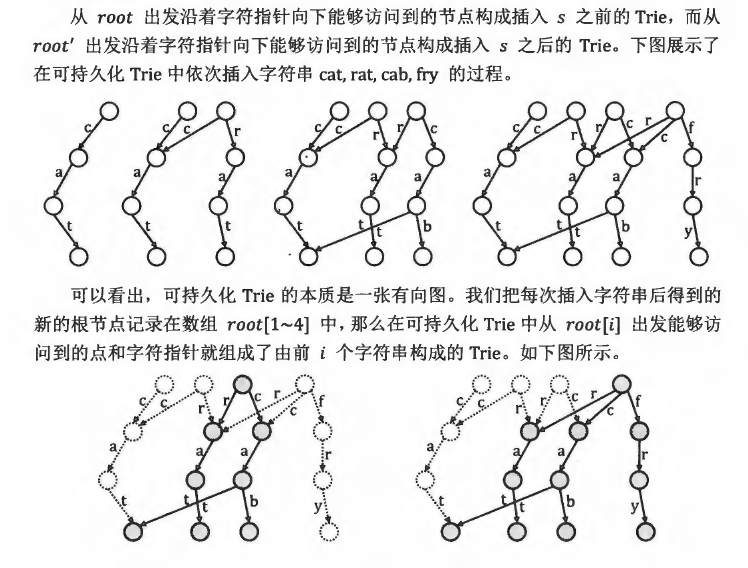
可持久化数据结构
到目前为止,我们学习的数据结构维护的都是"数据集的最新状态".若想知道数据集在任意时间的历史状态,一种朴素的做法是在第i项操作结束后,把整个数据结构拷贝一遍,存储在history[i]中,多耗费M倍的空间."可持久化"提供了一种思想,在每项操作结束后,仅创建数据结构中发生改变的部分的副本,不拷贝其他部分.这样一来,维护数据结构的时间复杂度没有增加,空间复杂度仅增长为与时间同级的规模.换言之,可持久化数据结构能够高效地记录一个数据结构的所有历史状态.
可持久化Trie
与Tire的节点一样,可持久化Trie的每个节点也有若干字符指针指向子节点,可以用trie[x,c]保存节点x的字符指针c指向的子节点的编号(0代表指向空).可持久化Trie按照以下步骤插入一个新的字符串s:

构建可持久化Trie所需的空间和时间复杂度都是字符串的总长度的线性函数
可持久化线段树
基于可持久化Trie的思想,我们很容易设计出多种数据结构的可持久化版本—前提是数据结构的"内部结构"在操作过程中不发生变化(例如平衡树的旋转就改变了平衡树的"内部结构").可持久化线段树,又称函数式线段树,是最重要的可持久化数据结构之一.

动态规划
针对满足特定条件的一类问题,对各状态维度进行分阶段,有顺序,无重复,决策性的遍历求解.
动态规划算法把原问题视作若干个重叠子问题的逐层递进,每个子问题的求解过程都构成一个"阶段".在完成前一个阶段的计算后,动态规划才会执行下一阶段的计算.
为了保证这些计算能够按顺序,不重复地进行,动态规划要求已经求解的子问题不受后续阶段的影响.这个条件也叫做"无后效性".换言之,动态规划对状态空间的遍历构成一张有向无环图,遍历顺序就是该有向无环图的一个拓扑序.有向无环图中的节点对应问题中的"状态",图中的边则对应状态之间的"转移",转移的选取就是动态规划中的"决策".
在很多情况下,动态规划用于求解最优化问题.此时,下一阶段的最优解应该能够由前面各阶段子问题的最优解导出.这个条件被称为"最优子结构性质".当然,这是一种比较片面的说法,他其实告诉我们,动态规划在阶段计算完成时,只会在每个状态上保留与最终解集相关的部分代表信息,这些代表信息应该具有可重复的求解过程,并能够导出后续阶段的代表信息.这样一来,动态规划对状态的抽象和子问题的重叠递进才能够起到优化作用.
“状态”"阶段"和"决策"是构成动态规划算法的三要素
“子问题重叠性”"无后效性"和"最优子结构性质"是问题能用动态规划求解的三个基本条件.
动态规划算法把相同的计算过程作用域各阶段的同类子问题,因此,我们一般只需要定义出DP的计算过程,就可以编程实现了.这个计算过程就被称为"状态转移方程".
线性DP
具有线性"阶段"划分的动态规划算法被统称为线性DP

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lAbmIEC9-1675572431879)(https://gitee.com/yzs1/picture/raw/master/Typora-Images/20230205122852-78.png)]
DP算法在这些问题上都体现为"作用在线性空间上的递推"—DP的阶段沿着各个维度线性增长,从一个或多个"边界点"开始有方向地向整个状态空间转移,扩展,最后每个状态上都保留了以自身为"目标"的子问题的最优解.
图论
综合技巧与实践
C++ STL
vector
size函数返回vector的实际长度
empty函数返回一个bool类型,表示vector是否为空
clear函数把vector清空
迭代器:vector::iterator it;
随机访问迭代器,可以把vector的迭代器与一个证书相加减,相减得到两个迭代器对应下标之间的距离
begin/end:*a.begin() = a[0]; *a.end() = a[n] (都是越界访问)
for(int i = 0;i < a.size();i++)
= for(vector< int >::iterator it = a.begin() ;it != a.end() ; it++)
front/back
front函数返回vector的第一个元素 , = *a.begin() = a[0]
back函数返回vector的最后一个元素, = *–a.end() = a[a.size() - 1]
push_back/pop_back
a.push_back(x)把元素x插入到vector a的尾部
a.pop_back()删除vector a的最后一个元素
queue
q.push(element) 入队
q.pop() 出队
int x = q.front() 队头元素
int y = q.back() 队尾元素
priority_queue
相当于大根二叉堆(默认规则为根据<)
priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式
例:priority_queue<int, vector, greater> heap;
q.push(x) O(logn) 插入堆
q.pop() O(logn) 删除堆顶元素
int x = q.top() 查询堆顶元素(最大值)
实现小根堆
对于内置数值类型,可以把要插入的元素的相反数放入堆
自定义结构体类型,重载<,但当做>使用
自定义排序规则
懒惰删除法(解决不支持删除堆中任意元素)
当遇到删除操作时,仅在优先队列之外做一些特殊的记录(例如记录元素的最新值),用于辨别那些堆中尚未清除的"过时"元素.当从堆顶取出最值时,再检查"最值元素"是不是过时的,若是,则删除并再次取最值,判断.
deque
双端队列
a[3] 随机访问
begin/end 头/尾迭代器
front/back 队头/队尾元素
push_front 从队尾入队
pop_front 从队尾出队
push_back 从队头入队
pop_back 从队头出队
clear 清空队列
set
主要包括set和multiset,分别是"有序集合"和"有序多重集",即前者的元素不能重复,而后者可以包含若干个相等的元素.
内部实现为红黑树,支持函数基本相等
默认判断规则为<
size/empty/clear
迭代器
双向访问迭代器,不支持随机访问,仅支持++,–(复杂度为O(logn))
set::iterator it
s.begin() 指向集合中最小元素的迭代器
s.end() 指向集合中最大元素的下一个位置的迭代器(–s.end()是指向集合中最大元素的迭代器)
s.insert(x) 把一个元素x插入到集合s中,(O(logn))
s.find(x) 在集合s中查找等于x的元素,并返回指向该元素的迭代器,弱不存在,则返回s.end() (O(logn))
s.lower_bound/upper_bound(x) (O(logn))
查找>=x的元素中最小的一个,并返回指向该元素的迭代器
查找>x的元素中最小的一个,并返回指向该元素的迭代器
erase
如it是一个迭代器,s.erase(it)为从s中删除迭代器it指向的元素,时间复杂度为O(logn)
如x是一个元素,s.erase(x)为冲s中删除所有等于x的元素,时间复杂度为O(k+log(n)),k为被删除的元素的个数
如果想从multiset中删掉至多1个等于x的元素,可以执行:
if((it= s.find(x)) != s.end()) s.erase(it);
s.count(x) 返回集合s中等于x的元素个数,时间复杂度为O(k+logn),其中k为元素x的个数
map
是一个键值对key-value的映射.内部实现为一棵以key为关键码的红黑树,key和value可以是任意类型,其中key必须定义<运算符
大部分操作时间复杂度为O(logn)
可用于Hash表,建立从复杂信息key到简单信息value的映射
size/empty/clear/begin/end
迭代器 双向访问迭代器,对map的迭代器接触引用后,将得到一个二元组 pair<key_type,value_type>
insert
参数为pair<key_type,vlaue_type>
map<int,int> h;
h.insert(make_pair(1,2));
erase
参数可以是pair或者迭代器
find(O(logn))
h.find(x)为在变量名为h的map中查找key为x的二元组,并返回指向x的迭代器,若不存在,则返回h.end()
[]操作符
h[key] 返回key映射到的value的引用,也可进行复制操作,改变h[key]对应的value 时间复杂度为O(logn)
若查找的key不存在,h会自动新建一个二元组(key,zero),并返回zero的引用,这里zero表示一个广义"零值",如整数0,空字符串等.
可以在用[]操作符查询之前,先用find方法检查key的存在性
bitset
bitset可以看作一个多位二进制数,每8位占用一个字节,相当于用了状态压缩的二进制数组,并支持基本的位运算.
n为bitset执行一次位运算的复杂度可视为n/32,效率较高(一般以32位整数的运算次数为基准)
bitset<1000> s; //表示一个1000位二进制数,<>中填写位数
位运算操作符
~s 返回对bitset s 按位取反的结果
&,|,^ 返回对两个位数相同的bitset执行按位与,或,异或运算的结果
>> , << 返回把一个bitset右移,左移若干位的结果
==,!= 比较两个bitset代表的二进制数是否相等
[]操作符
s[k]表示s的第k位,既可以取值,也可以赋值,(0~n-1)
s.count()返回有多少位为1
s.any/none()
若s所有位都为0,则s.any()返回false,s.none返回true
若s至少一位为1,则s.any()返回true,s.none()返回false
set/reset/filp
s.set() 把s所有位变为1
s.set(k,v) 把s的第k位改为v
s.reset() 把s所有位变为0
reset(k) s[k]= 1
s.filp() 把s所有位取反 ,即 s = ~s
s.filp(k) 把s的第k位取反,即s[k]^=1
algorithm
reverse翻转
翻转一个vector
reverse(a.begin(),a.end());
翻转一个数组,元素存放在下标1~n:
reverse(a+1,a+n+1);
unique去重
返回去重之后的尾迭代器(或指针),为去重后末尾元素的下一个位置.常用于离散化
把一个vector去重:
int m = unique(a.begin(),a.end()) - a.begin();
把一个数组去重,1~n
int m = unique(a+1,a+n+1) - (a+1);
random_shuffle随机打乱
用法同reverse
next_permutation下一个排列 / prev_permutation 上一个排列
把两个迭代器(或指针)指定的部分看做一个排列,求出这些元素构成的全排列中,字典序排在下一个的排列,并直接在序列上更新,
若不存在排名更靠后的排列,则返回false,否则返回true
for(int i = 1;i <= n;i++) a[i] = i;
do
{
for(int i = 1; i<n;i++) cout<<a[i] <<' ';
cout<<a[n]<<'\n';
}while(next_permutation(a+1,a+n+1));
sort快速排序
对两个迭代器(或指针)指定的部分进行快速排序
可以在第三个参数传入定义比较函数,或者重载<运算符
默认比较规则为<
lower_bound/upper_bound二分
要求:指定的部分应该是提前排好序的
lower_bound第三个参数传入一个元素x,在两个迭代器(或指针)指定部分上执行二分查找,返回指向第一个大于等于x的元素的位置的迭代器
upper_bound大致相同,唯一区别为是查找第一个大于x的元素
在有序int数组(1~n)中查找大于等于x的最小整数的下标
int i = lower_bound(a+1,a+n+1,x) - a;
在有序vector<int>中查找小于等于x的最大整数
int y = *--upper_bound(a.begin(),a.end(),x);
随机数据生成与对拍
随机数据生成
头文件 cstdlib
rand和srand函数以及RAND_MAX常量(不小于32767的整数常量,与操作系统环境,编译器环境有关,一般windows为32767,Unix为214783647)
rand()函数返回一个0~Rand_MAX之间的随机整数int
srand()函数接受unsigned int类型的参数seed,一seed为"随机种子",rand函数基于线性同余递推式生成随机数,"随机种子"相当于计算线性同余时的一个初始参数,若不执行srand函数,种子默认为1
当种子确定后,产生的随机数列固定,所以称这种随机方法为"伪随机",
因此,一般在随机数据生成程序main函数的开头,用当前系统时间作为随机种子
模板:
#include<bits/stdc++.h>
using namespace std;
int random(int n)//返回0~n-1之间的随机整数
{
return (long long)rand() * rand() %n;
}
int main()
{
srand((unsigned)time(0));
//具体内容
return 0;
}
/*
若要产生随机实数,可以先产生一个较大的随机整数,再用它除以10的次幂
若要同时产生负数,则可以先产生一个0~2n(2*n+1)的随机整数,再减去n
*/
随机生成树
//随机生成一棵n个点的树,用n个点,n-1条边的无向图形式输出,每条边附带一个10e9以内的正整数权值
for(int i = 2; i <= n; i++)
{
//从2~n之间的每一个点i向1~i-1之间的点随机连一条边
int fa = random(i-1) + 1;
itn val = random(1000000000) + 1;
printf("%d %d %d\n",fa ,i , val);
}
随机生成图
//随机生成一张n个点,m条边的无向图,图中不存在重边,自环,且保证了连通,保证 5<=n<=n*(n-1)/4<=10e6
//当n<5时可能存在边界情况,需要在参考程序中添加特判,当m>n*(n-1>/4时,可能造成参考程序的随机效率降低,此时应当考虑随机生成补图,再转化得到原图
pair<int,int> e[1000005]; //保存数据
map<pair<int,int>,bool> h;//防止重边
//先生成一棵树,保证连通
for(int i = 1;i <= n; i++)
{
int fa = random(i) + 1;
e[i] = make_pair(fa,i+1);
h[e[i]] = h[make_pair(i+1,fa)] = 1;
}
//在生成剩余的m-n+1条边
for(int i = n; i <= m; i++)
{
int x,y;
do
{
x = random(n) + 1,y = random(n) + 1;
}while(x == y ||h[make_pair(x,y)]);
e[i] = make_pair(x,y);
h[e[i]] = h[make_pair(y,x)] = 1;
}
//随机打乱,输出
random_shuffle(e+1,e+m+1);
for(int i =1; i<= m ; i++)
printf("%d %d\n", e[i].first, e[i].second);
在树,图结构中,有三类特殊数据常用于对程序进行极端状况下的效率测试:
1.链形数据-----有很长的直径
把N个结点用N-1条边连成一条长度为N-1的"链",会造成很大的递归深度,是点分治等算法需要特别注意的数据
2.菊花形数据-----有度数很大的节点
以1号节点为中心,2~N号节点都用一条边与1号结点相连,最终1号节点的度数为N-1.缩点等图论算法若处理不当,复杂度容易在这种数据上退化
3.蒲公英形数据----链形+菊花形
令树的一部分构成链,一部分构成菊花再把两部分连接
对拍
运行"正解"(sol.exe),“朴素算法”(bf.exe)和随机数据生成程序(random.exe)并对比结果的程序
#include<bits/stdc++.h>
using namespace std;
int main()
{
for(int T = 1; T <= 10000;T++)
{
//自行设定适当的路径
system("???\\random.exe");
//当前程序已经运行的CPU时间,windows下单位为ms,Unix下单位为s
double st = clock();
system("???\\sol.exe");
double ed = clock();
system("???\\bf.exe");
if(system("fc ???\\data.out ???\\data.ans"))
{
puts("Wrong Answer");
//程序立即退出,此时data.in即为发生的数据
return 0;
}
else{
printf("Accepted, 测试点 #%d, 用时 %.01fms\n",T,ed-st);
}
}
}
杂项
0x表示十六进制,0x00~0xFF
int 最大取值:2 147 483 647 (≈2*1e9)(0x 7F FF FF FF)(0x3F 3F 3F 3F二倍不超过0x7F FF FF)
memset(a,val,sizeof(a)) 原理:把数值val(以十六进制形式)填充到数组a的每个字节上(可用0x3f给a赋值为较大数字)
| 枚举形式 | 状态空间规模 | 一般遍历方式 |
|---|---|---|
| 多项式 | n^k,k为常数 | for循环,递推 |
| 指数 | k^n,k为常数 | 递归,位运算 |
| 排列 | n! | 递归,C++ next_permutation(下一个排列方式) |
| 组合 | Cmn(不会打) | 递归+剪枝 |
lower_bound(first,last,val) 函数用于在指定区域内查找不小于目标值的第一个元素。也就是说,使用该函数在指定范围内查找某个目标值时,最终查找到的不一定是和目标值相等的元素,还可能是比目标值大的元素。
vector<int>::iterator iter = lower_bound(myvector.begin(), myvector.end(),3,mycomp2());
cout << "*iter = " << *iter;
upper_bound(first,last,val) 类似上
equel_range(first,last,val)
该函数会返回一个 pair 类型值,其包含 2 个正向迭代器。当查找成功时:
- 第 1 个迭代器指向的是 [first, last) 区域中第一个等于 val 的元素;
- 第 2 个迭代器指向的是 [first, last) 区域中第一个大于 val 的元素。
//找到 [first, last) 范围内所有等于 val 的元素
pair<ForwardIterator,ForwardIterator> equal_range (ForwardIterator first, ForwardIterator last, const T& val, Compare comp);
binary_search(first,last,val)
如果 binary_search() 函数在 [first, last) 区域内成功找到和 val 相等的元素,则返回 true;反之则返回 false。
//查找 [first, last) 区域内是否包含 val
bool binary_search (ForwardIterator first, ForwardIterator last,
const T& val);
//根据 comp 指定的规则,查找 [first, last) 区域内是否包含 val
bool binary_search (ForwardIterator first, ForwardIterator last,
const T& val, Compare comp);
完全二叉树中的层次遍历,父节点编号等于子节点编号除以2,做子节点编号等于父节点编号乘2,右子节点编号等于父节点编号乘2加1
c++11新增语法
int a[5] = {1, 2, 2, 5, 1};
for (int i : a)
{
printf("%d\n", i);
}
状态空间 :一个问题的 全部状态 及一切 可用算符 构成的 集合 。 常用一个三元组表示为: (S, F, G) ,其中,S为问题的 所有初始状态集合 ;F为 算符的集合 ;G为 目标状态的集合 。 状态空间也可用一个 有向图 来表示,该有向图称为 状态空间图 。
一个问题的求解可以理解为对问题状态空间的遍历与映射,其中状态类比为节点,状态之间的联系与可达性可以用图上的边来表示NPC问题及其解决方法(回溯法、动态规划、贪心法、深度优先遍历)
NP问题(Non-deterministic Polynomial ):多项式复杂程度的非确定性问题,这些问题无法根据公式直接地计算出来。比如,找大质数的问题(有没有一个公式,你一套公式,就可以一步步推算出来,下一个质数应该是多少呢?这样的公式是没有的);再比如,大的合数分解质因数的问题(有没有一个公式,把合数代进去,就直接可以算出,它的因子各自是多少?也没有这样的公式)。
NPC问题(Non-deterministic Polynomial complete):NP完全问题,可以这么认为,这种问题只有把解域里面的所有可能都穷举了之后才能得出答案,这样的问题是NP里面最难,但是这样算法的复杂程度,是指数关系。一般说来,如果要证明一个问题是NPC问题的话,可以拿已经是NPC问题的一个问题经过多项式时间的变化变成所需要证明的问题,那么所要证明的问题就是一个NPC问题了。NPC问题是一个问题族,如果里面任意一个问题有了多项式的解,即找到一个算法,那么所有的问题都可以有多项式的解。
著名的NPC问题:
背包问题(Knapsack problem):01背包是在M件物品取出若干件放在空间为W的背包里,每件物品的体积为W1,W2……Wn,与之相对应的价值为V1,V2……Vn。求出获得最大价值的方案。
旅行商问题(Traveling Saleman Problem,TSP),该问题是在寻求单一旅行者由起点出发,通过所有给定的需求点之后,最后再回到原点的最小路径成本。
哈密顿路径问题(Hamiltonian path problem)与哈密顿环路问题(Hamiltonian cycle problem)为旅行推销员问题的特殊案例。哈密顿图:由指定的起点前往指定的终点,途中经过所有其他节点且只经过一次。
欧拉回路(从图的某一个顶点出发,图中每条边走且仅走一次,最后回到出发点;如果这样的回路存在,则称之为欧拉回路。)与欧拉路径(从图的某一个顶点出发,图中每条边走且仅走一次,最后到达某一个点;如果这样的路径存在,则称之为欧拉路径。)
子集和问题(回溯算法+剪枝)
全排列问题
N皇后问题
一棵树是由N个点,N-1条边构成的无向连通图,我们把这种树称为"无根树",也就是说可以任意指定一个节点为根节点,而不影响问题的答案.















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









