







 文章详细介绍了网络-on-chip(NoC)中的流控制策略,包括Bufferless、Buffered以及Virtual-ChannelFlowControl,分析了各种策略的优缺点。Bufferless策略简单但可能导致资源浪费,Buffered策略通过引入Buffer提高效率,而Virtual-ChannelFlowControl通过多通道分配优化资源使用。此外,文章还讨论了backpressure机制,如Credit-Based、On/Off和Ack/NackFlowControl,以及它们在资源管理和延迟控制上的应用。
文章详细介绍了网络-on-chip(NoC)中的流控制策略,包括Bufferless、Buffered以及Virtual-ChannelFlowControl,分析了各种策略的优缺点。Bufferless策略简单但可能导致资源浪费,Buffered策略通过引入Buffer提高效率,而Virtual-ChannelFlowControl通过多通道分配优化资源使用。此外,文章还讨论了backpressure机制,如Credit-Based、On/Off和Ack/NackFlowControl,以及它们在资源管理和延迟控制上的应用。
文章目录
Flow Control 简介
NoC 的流控制决定了网络的资源(信道的带宽、buffer 容量、控制状态等)在 packet 传输过程中如何被分配。
优秀的流控制策略,能最大限度地利用网络的各种资源,在较低且可预测的延时内,传递 packet。
可以从两个角度可以理解 flow control 的作用:
- 资源分配:在每一个 packet 传输过程中都需要为其分配资源。
- 争用解决:在多个包争用同一资源时,根据优先级仲裁。
分类及待分配的资源
流控制策略大体上可分为以下三类:
- Bufferless:对于阻塞的 packet 不采取临时储存,而是丢弃或错误路由。
- Circuit Switching:packet header 会先于 payload 首先在网络中传输。在 header 经过的路径上,所有需要的资源都会被保留。如果 header 暂时不能被分配资源,原地等待直到资源空闲。当整条路径的资源都被取得后,数据开始源源不断地在这条路径上传输,直到发送结束,断开电路连接,释放全部资源。
- Buffered:在 packet 暂时不能被分配资源时,由 buffer 暂存 packet。
当 packet 在网络中传输时,必须对 信道带宽(channel bandwidth)、buffer 容量、控制状态(control state) 进行分配。
控制状态记录了 channel 和 buffer 的分配情况,以及 packet 在 node 中的当前传输状态。
信道带宽指向下一个 node 发送 packet 所需的 channel 资源。
Buffer 用来将暂时无法获取足够 channel 资源的 packet 暂存。
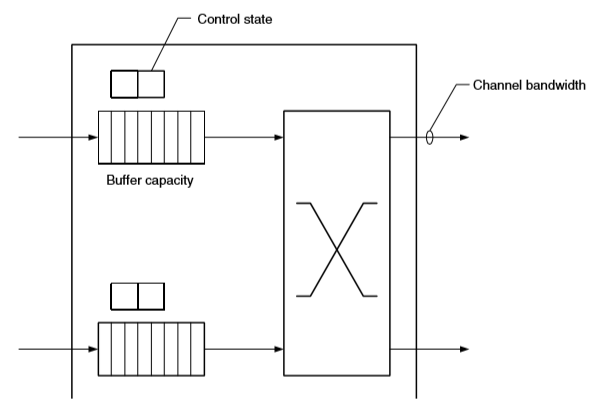
NoC 中分配资源的基本单位
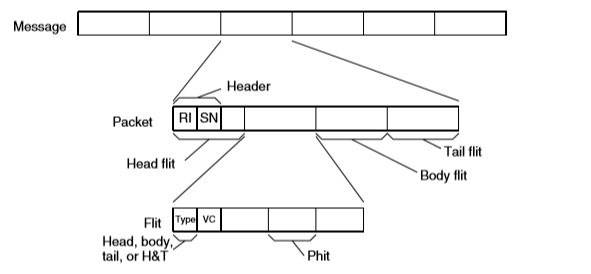
-
Message:由 source 向 destination 发送的一组连续的数据。message 有任意长度,所以向下切分为一个具有固定长度的 packet 作为资源分配的单位。
-
Packet:是 routing 和 sequencing 的基本单元。Control state 以 packet 单位来分配。每个 packet 有一个 header 记录 routing information(RI)和 sequence number(SN)。
-
Flit:由 packet 进一步切分得到。flit 是 bandwidth 及 buffer 容量分配的基本单位。同一个 packet 下的多个 flits,按照统一路由路径进行传输。Flit 头部包含 virtual-channel identifier(VCID),当多个 packets 通过同一物理 channel 同时传输时,用 VCID 分辨 flits 属于哪一系统。
-
Phit:是在一个时钟周期内,由一条 channel 发送的信息。
为何要将 packet 分为 flit,而不是在 packet 层对所有资源作分配?
为了减少 routing 和 sequencing 的成本,我们倾向于将 packet 长度作大;然而为了进行高效、细粒度的资源分配,减少 packet 阻塞的时延,我们倾向于将 packet 长度作小。引入 Flit 的层次,解决了这一矛盾。
以经验来说:
Phit 长度通常为 8bits。
Flit 长度通常为 64bits。
Packet 长度通常为 1Kbits。
Bufferless Flow Control
这是最简单的流控制策略,不使用 buffer。若多个 packet 同时申请资源,需进行仲裁。未获得资源的 packet,由于没有 buffer 进行暂存,被 drop 或 misroute。
对于 Bufferless 流控制方式,往往需要 ACK 或 NACK 机制,及时通知发送端 packet 是被 drop 还是被成功接收。
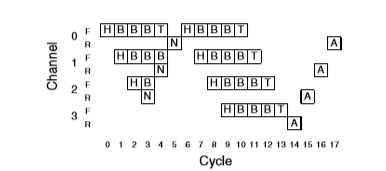
假设下面的场景:packet A与B在争用 channel,A获得 channel 的资源。B 被丢弃。
假设 packet B 是一个争用发生在 B 的第4跳。那么 B 传输过程中的 time-space 图如下。N 表示 NACK,通知 source packet B 被丢弃掉了需要重新发送。
可以看出在 Cycle 6 之前的 Channel 0、1、2 的资源全部被浪费掉了。
Bufferless 的流控策略,往往会造成大量资源的浪费。是非常低效的流控策略。因为他使用了宝贵的 channel 带宽传输 packet,这些 packet 之后极有可能会被丢弃,需要重新发送。
Buffered Flow Control
Buffer 的引入能极大提升网络的效率,这是因为 Buffer 能将暂时无法发送的 packet 进行暂存,等待 channel 资源空闲时再进行发送。这相当于将 input channel 与 output channel 解耦。(在 bufferless 中,一个 packet 若要经过 router,必须将 input channel 和 output channel 同时分配资源。因为 packet 除了发送给下一段 channel,在 router 中无处暂存)
常用的 flow control 策略有两个层次:以 packet 为单位分配 buffer 和 channel;以 flit 为单位分配 buffer 和 channel。
以 flit 为单位分配在实际中使用更多。这是因为细粒度的分配单位能更高效地利用有限的资源,减少 router 中所需的存储空间。同时以 flit 为单位能提供 stiffer backpressure 机制,使当前路由感受到远端的拥塞发生。
Packet-Buffer Flow Control
以 packet 为单位进行资源分配,也就是 store-and-forward(存储转发)。每一个 node 必须等待一个 packet 完全被收到后,才可以转发到下一个 node。
在 packet 被转发之前,必须要得到两个资源:下一段信道的的使用带宽、下一跳 node 中可用的 buffer 容量。一旦 packet 全部被当前 node 接收,且取得了所需的资源,即可转发。
下图展示了 5-flit,4-hop 情况下 packet-buffer store-and-forward 流控的 time-space 情况:
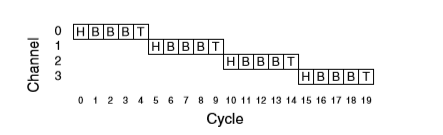
采用 cut-through(切片) 方式的流控,buffer 和 channel bandwidth 的资源同样是以 packet 单位来分配,区别在于每个节点在接收到 header 后,如果获取到了下一段转发所需要的 buffer 和 bandwidth 资源,则立即开始发送。
下图展示了无冲突和有冲突情况下 cut-through 流控的 time-space 情况:

虽然 cut-through 的流控方式减少了时延,但是以 packet 为单位分配资源是非常低效的空间利用方式。以 flit 为单位分配资源显然更加高效。当我们需要采用多个独立的 buffer 来减少拥塞和避免死锁时,按照 flit 分配则显得更加重要。
以 packet 为单位分配资源同时会增加冲突时延。假设一个高优先级的 packet 因 一个低优先级的 packet 正在传输而堵塞,高优先级 packet 必须等低优先级 packet 传输完才可以获得资源,而不能中途打断低优先级 packet 的传输。
所以一般情况下,为了存储空间的高效利用,减小网络的时延,多采取 flit-buffer 流控策略。
Flit-Buffer Flow Control
Wormhole Flow Control
与 cut-through 类似,但是按照 flit 为单位分配 channel 和 buffer 资源。
当 packet 的 head flit 到达节点时,需要获取下面三个资源后才可以继续向下一节点发送:
- Virtual Channel,包括 input virtual channel 和 output virtual channel,即一条由输入端口到输出端口的虚拟路径的使用权。
- 下一节点中:flit 容量的 buffer
- 到下一节点的 channel 上: flit 大小的 channel bandwidth
packet 的 body flit 到达节点时,使用之前 head flit 获得的 virtual channel,再需得到 flit 大小的 buffer 和 channel bandwidth 即可向前发送。
packet 的 tail flit 到达节点,同 body flit 一样需要得到 flit 大小的 buffer 和 channel bandwidth。在发送完成后释放 virtual channel。
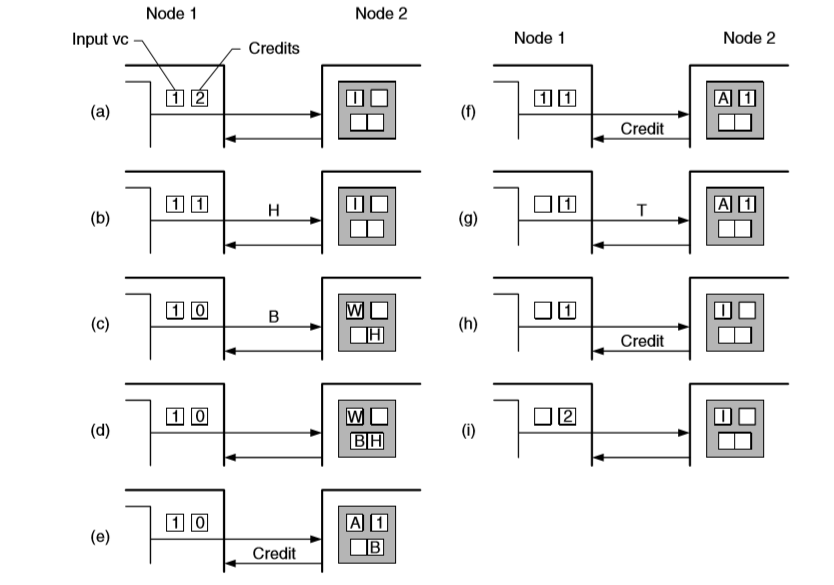
virtual channel 控制着协调处理 flit 所需的 channel 状态。包括 output channel 是否空闲,virtual channel 本身的状态(Idle,Waiting for resources,Active)。除此之外,可能还包括 flit 在 buffer 中的存放位置,下一跳中 buffer 的剩余容量。
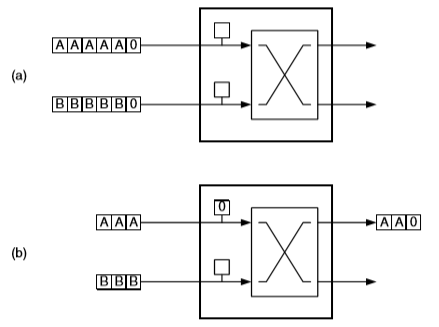
下图中,virtual channel 包含了 2 flit 大小的 buffer。4 flit 大小的 packet 希望从节点的 upper input port 发送至 upper output port。初始时,upper output port 被 lower input port 占用,virtual channel 处于 Wating 状态。一直到图(d),upper output port 开始空闲,重新分配。virtual channel 得到 output port 后,状态变为 Active,开始转发 flit。
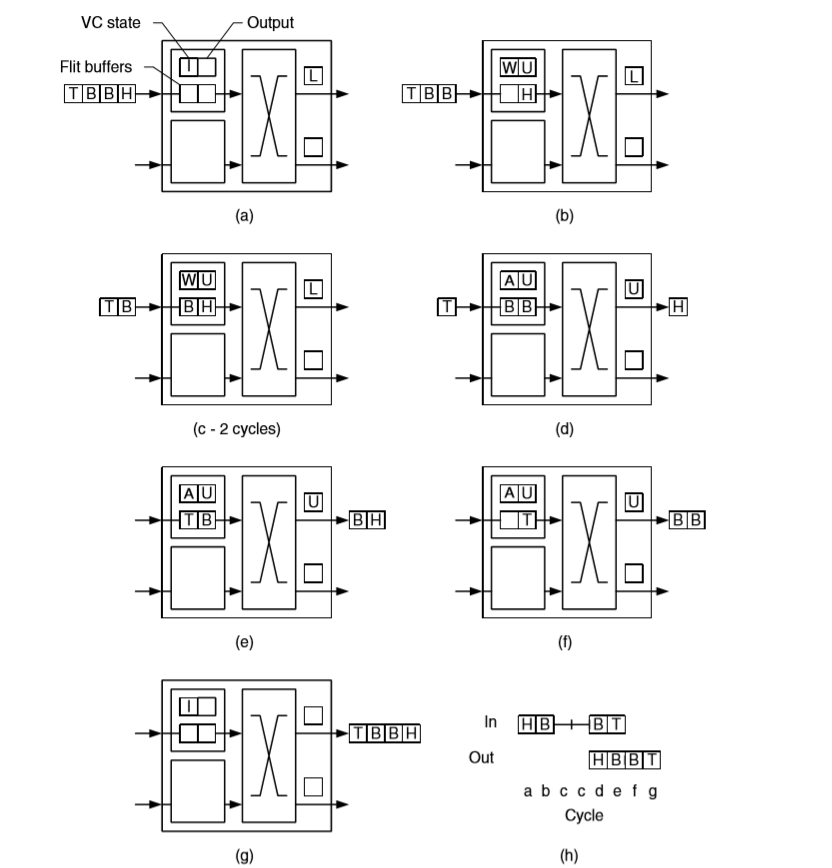
与 cut-through 相比,wormhole 对于 buffer 空间的利用率大大提升,每个 virtual channel 只需要少量的 flit buffer。(buffer 容量必须要满足两个节点间 round-trip latency 和 pipline delay)
然而这也带来了 throughput 的限制。wormhole 流控很可能会在发送一个 packet 的中途,阻塞 channel。如上图中的(c),节点在接受两个 flit 后,因为无法获取 output port,处于阻塞状态。channel 资源在阻塞时处于空闲状态,被浪费掉了。
这是因为,每条物理 channel 被一个 packet 单独占用,但是 buffer 是由 flit 为单位分配。即使在图(c)中,有其他的 packet 希望使用上端空闲的 channel,这也是不可能的。虽然我们按照 flit 来分配 channel bandwidth,但是只有同一个 packet 中的 flits 能使用这些 bandwidth。
这就引出了多个 virtual channel 的问题。
Virtual-Channel Flow Control
virtual-channel 流控,将多条 virtual channel(channel states 和 flit buffers)关联到一条实际的物理 channel ,克服了上面所提到的由于 packet 阻塞导致 channel 资源浪费的问题。
每条 virtual channel 被分配给一个 packet,多个 packet 的 flits 竞争使用实际物理 channel bandwidth。
在下图(a)中 wormhole 流控,packet B 阻塞,packet A 希望发送至 node 3。
由于 A 无法得到 chan p 的使用权,导致 chan p 和 q 的资源都被浪费掉了。
图(b)中,使用两个 virtual channel,避免了阻塞情况下的 channel 浪费。
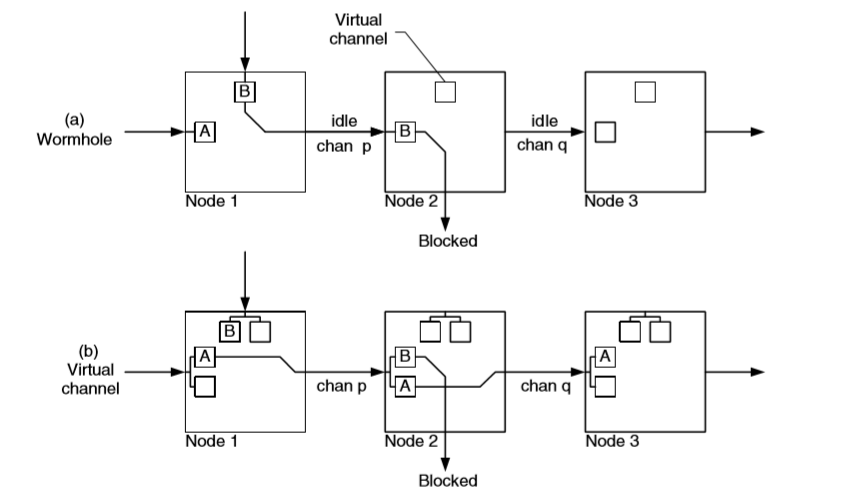
在正常情况下,多条 virtual channel 可以分享一条物理 channel 的 bandwidth。
下图中,packet A、B 从两个输入端口中进入,都希望从一个输出端口离开。每条 virtual channel 的 flit buffer 容量为 3。在 flit buffer 填满后,两条输入 channel 的速率也随之减半。
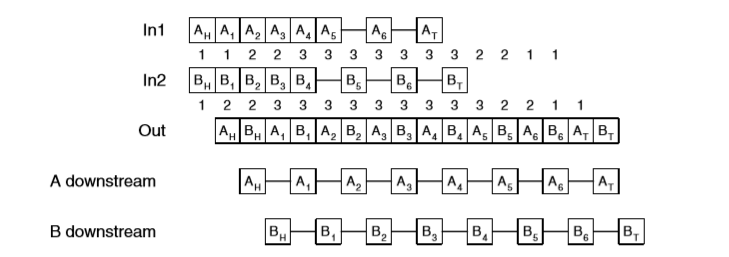
在这种情况下,物理 channel 成为了性能的瓶颈。下游的 channel 占用率降到满速率的一半。由于节点1的 buffer 全满,且受瓶颈的影响,导致上游节点向节点1发送 flits 的速率也降为满速率的一半,这会逐渐导致上游节点的 buffer 变满,反向传播堵塞。
对于长 packet,这种阻塞可能会反向传递到发送 packet 的 source 节点。
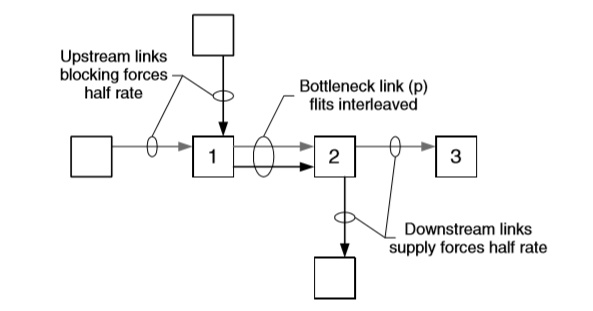
造成以上结果的原因是采用了公平的 bandwidth arbitration 方法。
由于采取公平的仲裁方法,packet A 和 packet B 的延时都非常高。
一种降低时延的方式是采用 winner-take-all bandwidth arbitration。
节点会将物理 channel 的全部 bandwidth 交给一个 packet,直到该 packet 传输完成或者遭遇了阻塞。
同样是 packet A 与 packet B 从不同的端口进入,从同一端口离开。由于采取了不公平的 arbitration,packet A 无冲突地发送完成,packet B 的等待时延与上面采用公平的 arbitration 策略时一样。
可见,采用不公平的 bandwidth arbitration 策略能降低平均时延,同时不影响网络的 throughput。

通过 virtual channel,我们用二维的视角去组织 buffer 资源。
Router 每 input port 的 buffer 容量 = virtual channel 数量 * 每 virtual channel 的 buffer 容量
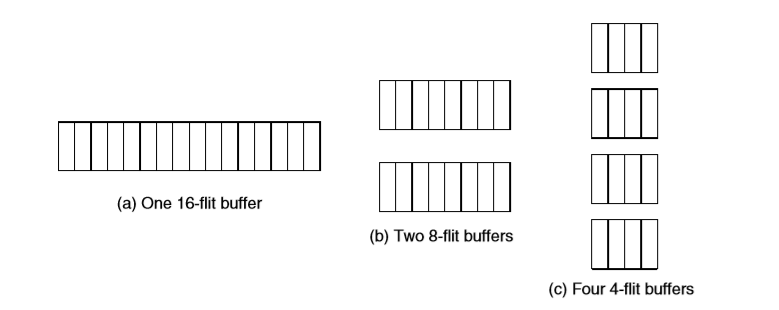
通常来说,每 virtual channel 的 buffer 容量不必过大,在容量超过 round-trip credit latency 所需之后,对于 throughput 的提升就微乎其微了。
Virtual Channel 是 互联网络中一个非常重要的技术,它使得 active packets 能够越过 blocked packets 进行传输。这对于死锁的避免、优先级/网络服务的设置都起到很大的作用。
Backpressure 机制
在流控策略中,对于上游节点,必须需要一种机制能够获悉下游节点的 buffer 使用情况,backpressure(反压机制)就是下游节点用来通知上游节点当前 buffer 使用情况的交流机制。
Credit-Based Flow Control
上游节点记录下一节点中 buffer 余量,每次上游节点发送 flit 后,记录的下游 buffer 余量减少。每次下游节点发送完成一个 flit 并释放相关 buffer 后,下游节点通过向上游节点发送 credit 通知上游节点自己释放了一个 buffer,上游节点记录的 buffer 余量增加。
credit-based 流控的 timeline 可以如下图表示:
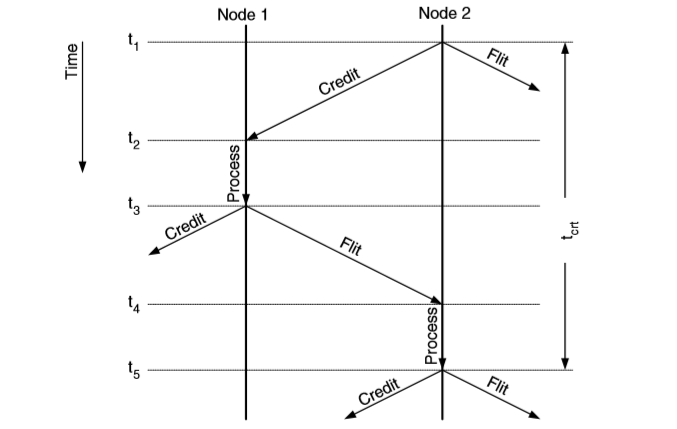
从节点1发送 flit 到节点2转发该 flit 返回 credit 的时间称为 credit round-trip delay。在上图中即是
t
c
r
t
=
t
5
−
t
1
t_{crt}=t_5-t_1
tcrt=t5−t1。
为了 channel 不必因为等待 credit 而被资源浪费,我们需要增大 flit buffer 的容量,使上游节点在得到第一个 credit 之前能够连续发送 flits。
即下游节点中 flit buffer 个数
F
≥
t
c
r
t
b
L
f
F\geq\dfrac{t_{crt}b}{L_f}
F≥Lftcrtb
其中 b 为 channel bandwidth,
L
f
L_f
Lf 为每个 flit 的长度。
对于 credit-based 流控,一个潜在的缺点在于:对于每一个接受到的 flit,下游节点都需要上行传输一个 credit 作为回复。credit 的回复会带来极大的额外开销。
On\Off Flow Control
On\Off 流控通过一个单独的比特位代表节点是否被允许向下游节点发送(On)或禁止发送(Off)flits。
在下游节点的空闲 flit buffer 数量小于阈值
F
o
f
f
F_{off}
Foff时,向上游节点发送 off 信号。
在下游节点的空闲 flit buffer 数量大于阈值
F
o
n
F_{on}
Fon时,向上游节点发送 on 信号。
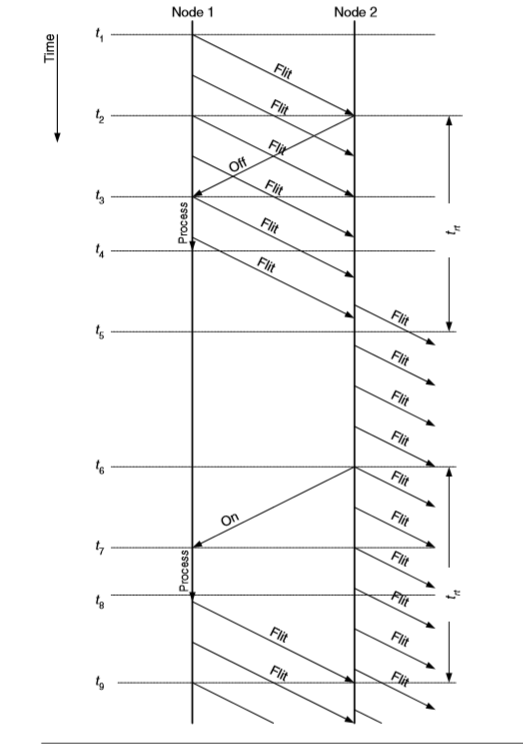
与 credit-based 类似,为了上游/下游的 channel 资源在 on/off signal 传递的过程中,不被浪费,对于发送 on/off 的上下阈值可以作如下约束:
F
o
f
f
≥
t
r
t
b
L
f
F_{off}\geq\dfrac{t_{rt}b}{L_f}
Foff≥Lftrtb
F
−
F
o
n
≥
t
r
t
b
L
f
F-F_{on}\geq\dfrac{t_{rt}b}{L_f}
F−Fon≥Lftrtb
在设置阈值时,越接近边界,需要发送的 on/off signal 次数就越少,上行反馈信号的开销就越小。
Ack/Nack Flow Control
上游的节点不会通过状态记录下游节点的 buffer 余量,下游节点在接受完成一个 flit 后返回 ACK,或因 buffer 容量已满返回 NACK。在上游节点接受到 ACK 时,需将该 flit 在 buffer 中一直保留。
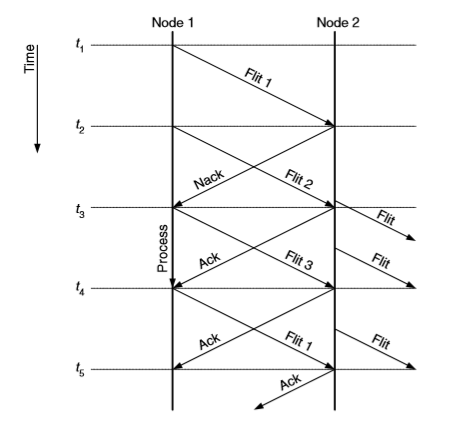
因为 ACK/NACK 方法需要将 buffer 保留较长的时间,且 bandwidth 效率较低,所以不常用。
Credit-Based 方法一般用于 flit buffer 数量较少的系统。
On/Off 方法一般用于 flit buffer 数量较大的系统。

















 2953
2953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









