




文章目录
说明
- 本文学自九天老师的课程,仅供学习和交流使用,最终著作权归原作者所有!
参考论文
DeepSeek-R1相关论文阅读
- DeepSeek-R1是深度开源的模型,模型的训练细节、模型架构、原创算法、蒸馏流程等均进行开源。
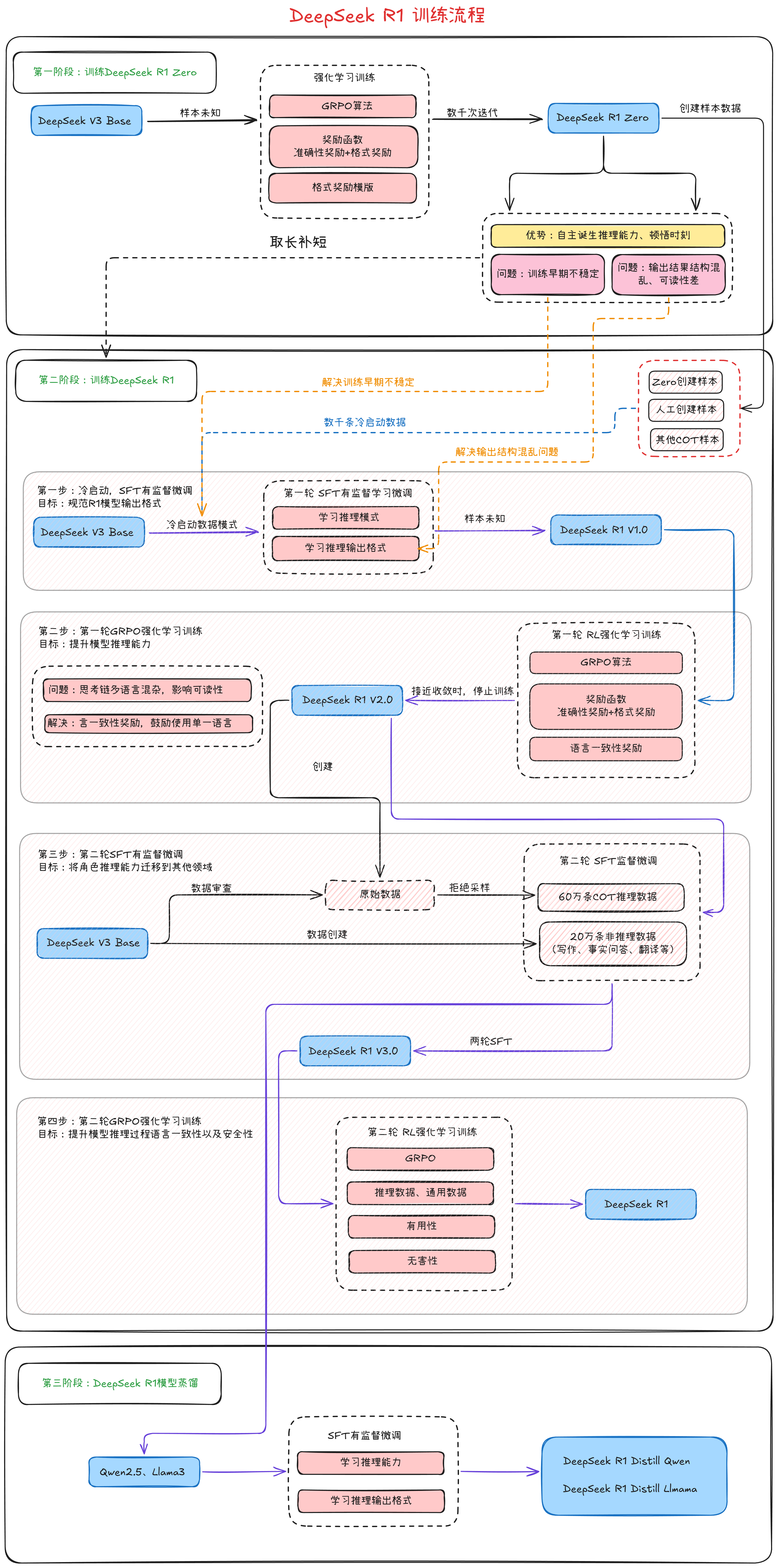
DeepSeek-R1的训练流程梳理
- 训练DeepSeek R1 Zero:介绍GRPO强化学习算法,训练DeepSeek R1 Zero模型。
- 训练DeepSeek R1:总结DeepSeek R1 Zero的模型,继续训练DeepSeek R1模型
- 进行R1模型蒸馏:由DeepSeek R1采用Llama和Qwen方式蒸馏出小模型。
摘要与简介
第一代推理模型
- 深度求索的第一代推理模型——DeepSeek-R1-Zero 和 DeepSeek-R1,旨在探索大模型在复杂推理任务上的极限。
- DeepSeek-R1-Zero:纯RL的探索与验证
R1-Zero是一次大胆的尝试:它完全依赖大规模强化学习(RL)进行训练,跳过了传统的监督微调(SFT)阶段。实验证明,这种“野生”训练方式能激发模型强大的、自发的推理能力。然而,纯RL也带来了副作用,比如输出内容可读性差、语言混杂等,使其难以直接应用。 - DeepSeek-R1:性能与实用性的平衡
为了解决R1-Zero的局限性,推出DeepSeek-R1。它采用了更稳健的训练策略:在RL之前,引入了多阶段训练流程和精心设计的冷启动数据。这一改进不仅有效提升了模型的输出质量,更使其推理性能达到了与 OpenAI o1 相当的水平,实现了高性能与高可用性的统一。 - 同时将DeepSeek-R1-Zero、DeepSeek-R1和基于Qwen和Llama模型蒸馏出的六个稠密模型(1.5B、7B、
8B、14B、32B、70B)开源,供业界专业人员研究学习。
模型后训练
-
在现代大模型的完整训练流程中,后训练已从一个可选步骤演变为不可或缺的核心环节。
-
研究表明,与资源消耗巨大的预训练相比,后训练是一种高性价比的优化手段。它专注于在预训练好的基础模型上进行“精雕细琢”,主要实现三大目标:
- 提升推理能力:让模型在复杂问题上表现得更准确、更深入。
- 实现价值对齐:确保模型的输出符合社会伦理和价值观,更安全、更负责任。
- 适应用户偏好:让模型的交互风格和回答方式更贴合用户的具体需求。
-
简言之,后训练是解锁模型“最后一公里”潜能的关键,它用相对较少的计算资源,实现了模型从“博学”到“好用”的飞跃。
纯强化学习的胜利:DeepSeek-R1探索大模型的推理极限
- 大语言模型正在走向通用人工智能,而后训练 已成为释放其潜力的关键。它以较低的计算成本,显著提升模型的推理、对齐和交互能力。在此背景下,OpenAI的o1系列通过 “推理时扩展” (增加思维链长度)取得了突破,但如何高效地实现这一目标仍是业界难题。现有方法如过程奖励模型、RLHF和搜索算法,都未能达到o1的通用推理水平。
- 我们的探索:纯强化学习能否自我进化出推理能力?
为了回答这个问题,我们迈出了大胆的第一步:采用纯粹的强化学习,探索大模型在没有监督数据的情况下,仅凭自我进化发展出高级推理能力的潜力。 - 第一步:DeepSeek-R1-Zero —— 纯RL的“野性”实验
我们以DeepSeek-V3-Base为基础,采用GRPO强化学习框架进行训练。令人惊叹的是,经过数千步RL训练,DeepSeek-R1-Zero自然涌现出了强大的推理行为。
实验的代价:这种“野生”训练也带来了挑战,如输出可读性差和语言混杂,使其难以直接应用。 - 第二步:DeepSeek-R1 —— 从“野性”到“精炼”的工程进化
为了解决R1-Zero的实用性问题并进一步提升性能,我们推出了DeepSeek-R1。它引入了 “冷启动数据”和“多阶段训练流程”,将RL的强大能力与SFT的稳定性相结合。- 冷启动:用少量高质量数据微调基础模型,为RL训练提供一个良好的起点。
- 推理导向RL:进行与R1-Zero类似的强化学习。
- SFT数据迭代:当RL接近收敛时,利用其检查点通过拒绝采样生成新的SFT数据,并与通用SFT数据(写作、问答等)混合,重新训练模型。
- 全场景RL:最后,对新模型进行全面的强化学习,以适应所有场景。
- 最终成果
经过精密的流程设计,DeepSeek-R1不仅解决了可读性问题,其综合性能更达到了与OpenAI-o1-1217相当的水平。证明纯强化学习是激发模型推理潜能的有效路径,而合理的工程化设计是将其转化为顶尖实用模型的关键。
小模型,大智慧:DeepSeek-R1的蒸馏艺术
- 强大的推理能力不应是巨模型的专属。为了将
DeepSeek-R1的推理能力赋予更广泛、更易部署的模型,深度求索深入探索了模型蒸馏技术。 - 核心发现:推理模式的直接传递远胜于“重新学习”。以
Qwen2.5-32B为学生模型,进行了一项关键对比实验:- 方案A:直接用
DeepSeek-R1进行蒸馏。 - 方案B:对学生模型进行独立的强化学习训练。
结果明确显示,方案A的效果显著优于方案B。这有力地证明了:大型模型通过RL探索出的推理“模式”本身,就是一种宝贵的、可直接迁移的知识资产。让学生模型直接“模仿”这种高级模式,比让它自己“从头摸索”要高效得多。
- 方案A:直接用
第一阶段实验:DeepSeek R1 Zero训练
- DeepSeek-R1-Zero:直接将强化学习应用于基础模型,而不使用任何监督微调数据。
- 由于使用传统的强化学习需要收集和制作大量监督数据,该过程耗时且费力。DeepSeek-R1-Zero直接使用纯强化学习(深度求索自研GRPO算法)实现模型推理能力的自我进化。
GRPO算法奖励函数
- 群组相对策略优化(Group Relative Policy Optimization,GRPO)算法,省略评估模型(Critic Model),并通过群体得分估算基准。有关内容可以参看模型微调GRPO算法的深入学习和理解
- 奖励是训练信号的来源,决定强化学习的优化方向。为训练DeepSeek-R1-Zero,采用一
种基于规则的奖励系统,主要由两种类型的奖励组成:- 准确性奖励(Accuracy rewards):准确性奖励模型评估响应是否正确。例如,对于具有确定结果的数学问题,模型需
要以指定格式提供最终答案,从而进行正确性验证。 - 格式奖励(Format rewards):格式奖励模型,要求模型将其思考过程放在
<think>和</think>标签之间。
- 准确性奖励(Accuracy rewards):准确性奖励模型评估响应是否正确。例如,对于具有确定结果的数学问题,模型需
- 格式奖励模版:为训练DeepSeek-R1-Zero,设计格式奖励模版,指导基础模型遵循指定的指令。模板要求DeepSeek-R1-Zero首先生成推理过程,然后给出最终答案。将约束限制在这种结构格式上,避免任何内容特定的偏见——例如,强制要求反思性推理或推广特定的解决问题策略——以确保我们能够准确观察模型在强化学习过程中的自然进展。
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the userwith the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </ answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:
DeepSeek R1 Zero训练流程
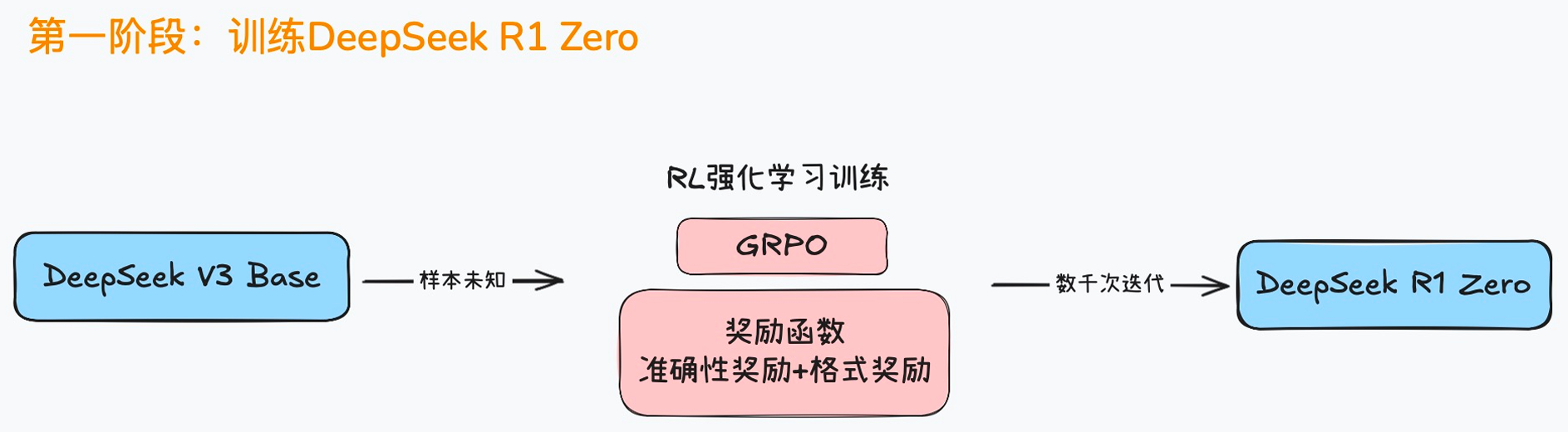
- 基座模型使用
DeepSeek V3 Base,通过大量无标注样本数据,采用GRPO算法和奖励含函数(准确性奖励和格式奖励)计算奖励值,经历数千次迭代优化,最终训练出DeepSeek R1 Zero模型。
R1 Zero证明GRPO算法威力
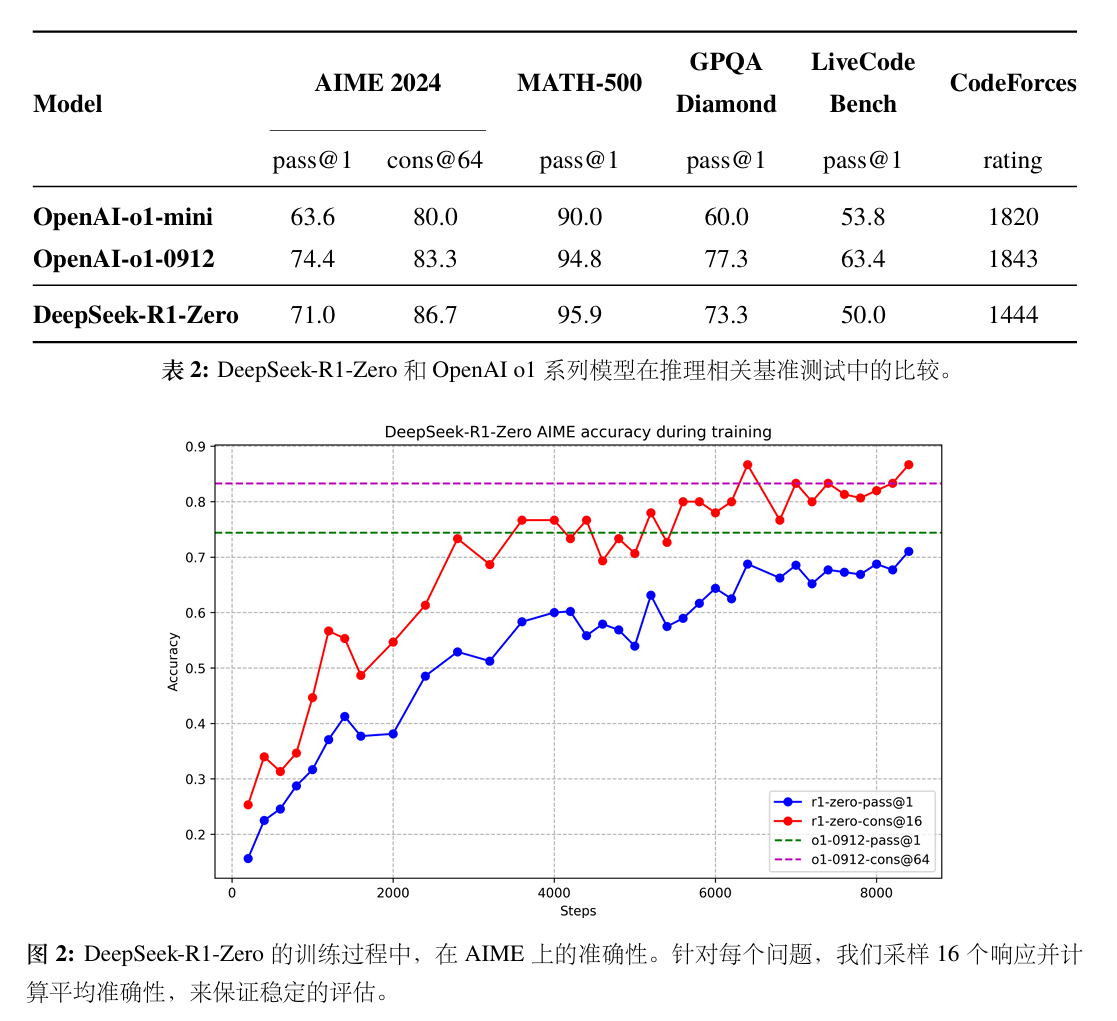
- 随着强化学习训练的推进,DeepSeek-R1-Zero的性能稳步而持续地提升,显著提升突显GRPO算法优化模型性能方面的有效性。
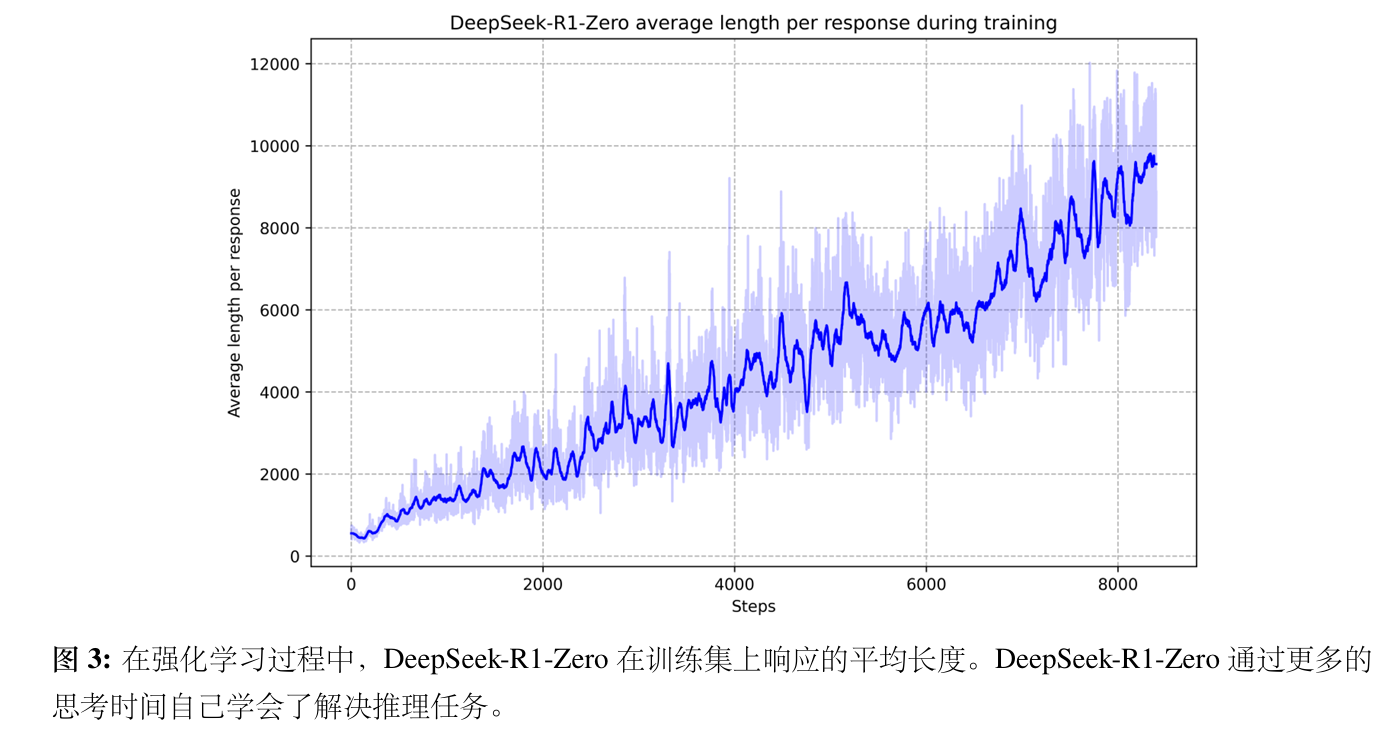
- DeepSeek-R1-Zero的自我进化,为强化学习驱动模型自主提升推理能力提供了关键启示。
- DeepSeek-R1-Zero的训练揭示了一个关键现象:模型学会了自主延长思考时间。
- 内在进化:这种“思考时间”的增长是模型内在发展的结果,而非外部强制。
- 自然涌现:通过增加测试时计算(生成数千个推理标记),模型获得了处理更复杂任务的能力。
- 深度思考:更长的推理链,意味着模型能进行更深层次的探索和自我修正。
- 结论:模型可以自发学会“三思而后行”,这是纯强化学习赋予它的宝贵能力。
- DeepSeek-R1-Zero 的“顿悟”时刻。随着测试时计算的增加,出现了更为复杂的⾏为。例如,反思模型重新审视并重新评估其先前的步骤以及探索解决问题的替代方法。这些行为并非显式编程的结果,而是是模型与强化学习环境互动的自发产物。这种自发的发展增强了DeepSeek-R1-Zero的推理能⼒,使其能够更高效、更准确地处理更加挑战性的任务。

第二阶段实验:DeepSeek R1训练
- DeepSeek-R1:从一个经过数千个思维链(CoT)示例微调的检查点开始应用强化学习。
前置知识:PPO算法和GRPO算法
- 强化学习的目标是策略优化,本质上并不是有监督学习
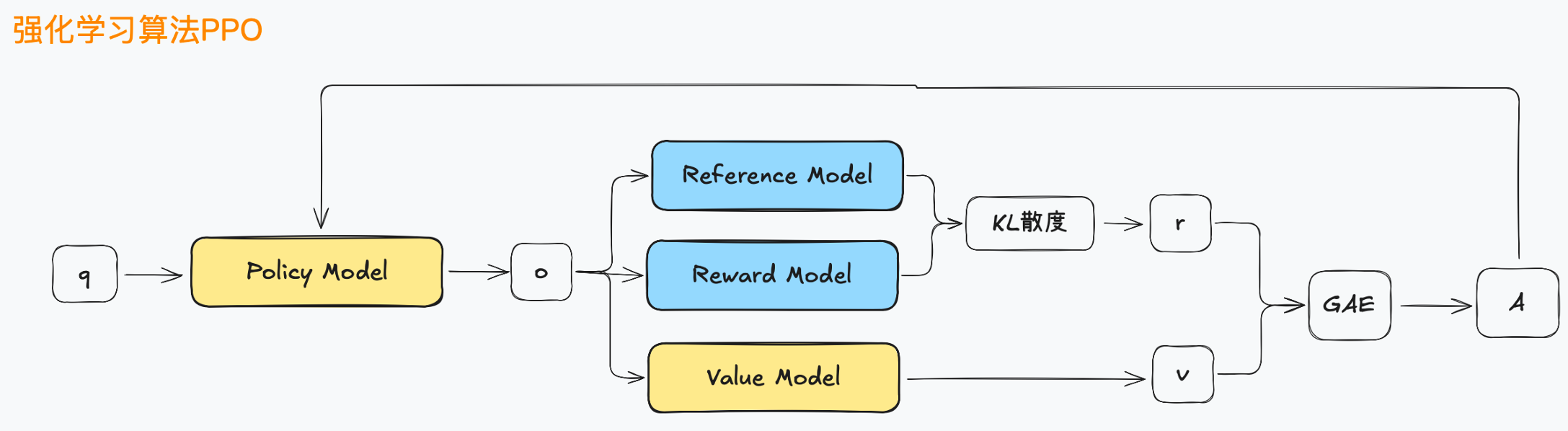
PPO模型组件
- Policy Model(策略模型):该模型负责基于当前状态生成行动,策略模型会输出一个动作 o ,并且使用 KL 散度来限制策略更新的幅度。
- Reference Model(参考模型):参考模型与当前策略进行对比,它的作用是提供参考标准,用来计算KL散度,确保策略更新不会偏离太远。
- Reward Model(奖励模型):奖励模型计算每个动作 o 所得到的奖励 r ,这是强化学习中用于指导学习的反馈信号。
- Value Model(值模型):值模型估算每个状态的价值 v ,用于评估在某一状态下采取特定动作的长远效果。
- GAE(Generalized Advantage Estimation):GAE 用于计算优势函数 A ,它综合了即时奖励和价值函数的估算值,通过这种方式来评估某个状态-动作对的好坏。
- KL:用于计算策略之间的 KL 散度,衡量当前策略与参考策略之间的差异。这个差异不能超过设定的阈值,以确保更新过程中不会发生剧烈的策略变动。
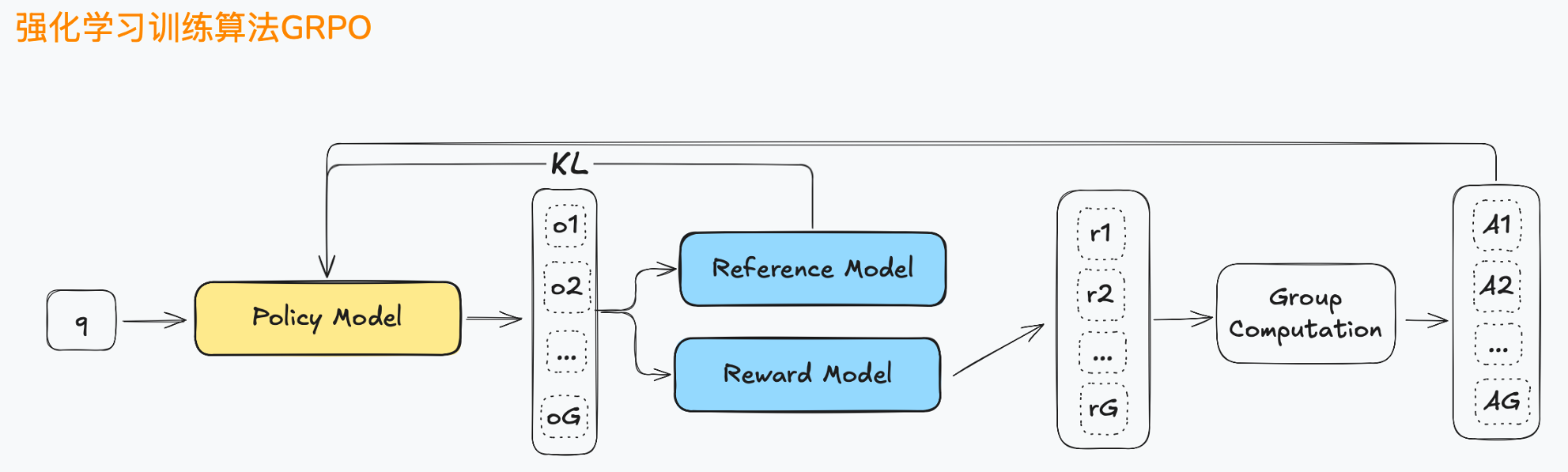
GRPO模型组件
- Policy Model(策略模型):该模型负责基于当前状态生成行动,策略模型会输出一个动作 o 。
- Reference Model(参考模型):与PPO中的单一参考模型不同,GRPO使用参考模型生成多个 o 1 , o 2 , … , o G o_1,o_2,\dots,o_G o1,o2,…,oG(多个候选动作),并进行对比。每个参考模型都提供不同的答案集合,这帮助GRPO进行相对优化。
- Reward Model(多个奖励模型):每个生成的动作 o i o_i oi都会通过相应的奖励模型 r i r_i ri来评估其效果。
- Group Computation(群体计算):通过对多个候选动作 o 1 , o 2 , … , o G o_1, o_2, \dots, o_G o1,o2,…,oG 和相应奖励 r 1 , r 2 , … , r G r_1, r_2, \dots, r_G r1,r2,…,rG 的相对比较,计算出最优的动作,并用这些最优结果来指导策略更新。通过这种"群体优化"的方法,GRPO能稳定地改进策略,避免PPO可能出现的策略震荡。
- KL:与PPO相似,GRPO也使用KL散度来确保新策略与参考策略之间的差异不会过大,但GRPO的多个参考模型提供了更多的候选集,从而优化的过程更加平滑和稳定。
- PPO和GRPO算法详细对比内容参看模型微调GRPO算法的深入学习和理解。
R1 Zero暴露的问题和解决思路
- 尽管DeepSeek-R1-Zero展示出强大的推理能力,并自主发展出意想不到且强大的推理行为,但它仍面临一些问题,如可读性差和多语言混合输出。
- 为了进一步提升推理性能,训练出一个能够生成清晰连贯COT(链式思维)、同时具备泛化能力的模型。深度求索设计了用于DeepSeek-R1(一种冷启动数据[cold-start data]的强化学习方法)。
DeepSeek R1训练流程
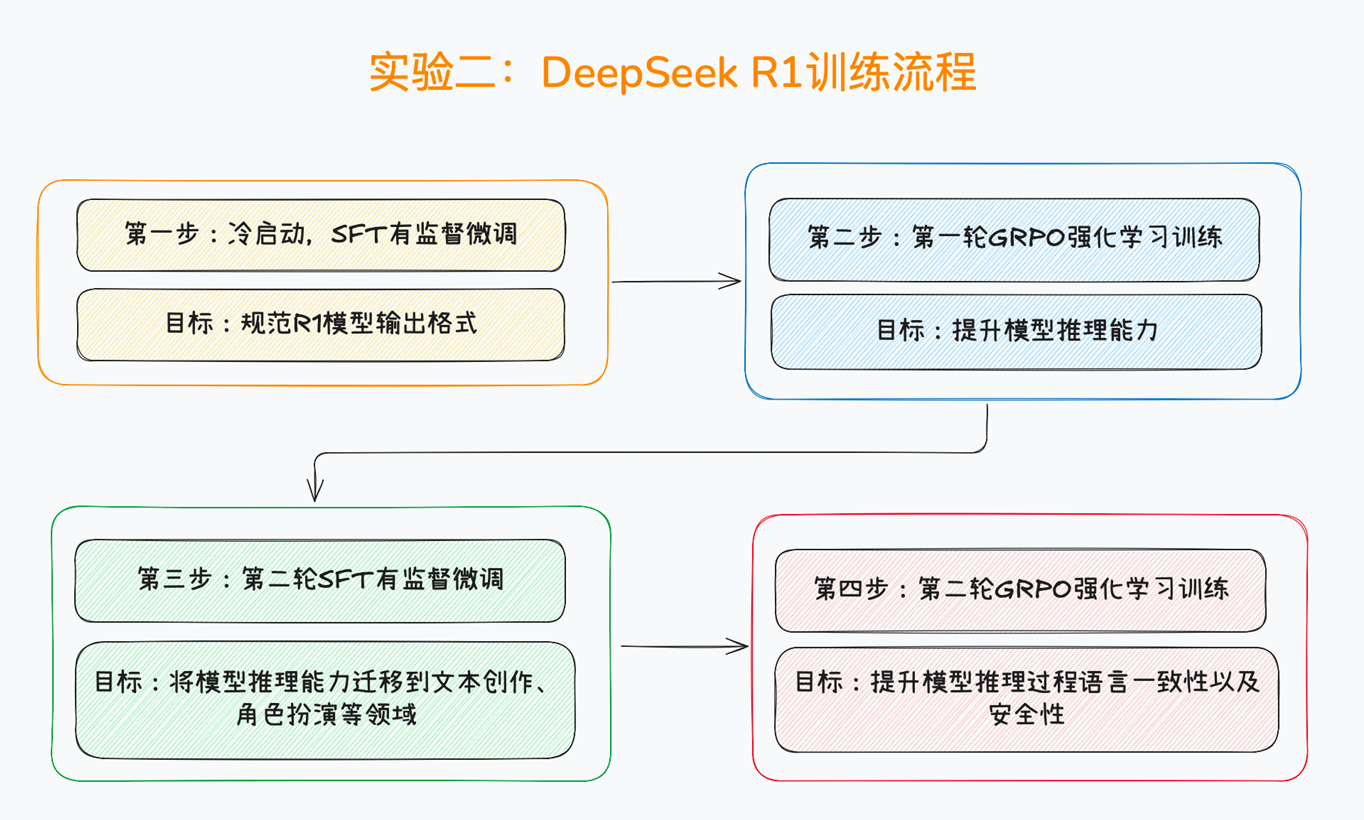
R1训练第一步:SFT有监督微调
R1训练第一步:冷启动数据模式
- 为了避免RL在训练基础模型早期不稳定冷启动阶段,深度求索构建并收集了一小部分长链式思维(COT)数据,微调模型,并将其作为初始的强化学习中的策略模型(RL Actor Model)。
DeepSeek-R1-Zero的输出内容可读性差。它的回答常常混杂多种语言,且缺乏清晰的格式,导致用户难以阅读和理解。为了引导模型生成人类可读的高质量内容,我们设计了一套基于冷启动数据的引导机制。- 核心架构:结构化输出模板:
|special_token|<reasoning_process>|special_token|<summary><reasoning_process>:承载模型的完整思维链。<summary>:对推理结果的精炼总结,直接面向用户。
该模板通过以下方式实施:
- SFT注入:在训练初期,通过少量高质量的模板数据,让模型学会这种“先思考,后总结”的模式。
- 数据过滤:在数据构建阶段,主动过滤不符合可读性标准的样本,确保初始数据池的纯净度。
- 架构优势与启示:这种架构设计带来的不仅是可读性的提升。性能数据显示,遵循良好先验模式的
DeepSeek-R1在推理任务上超越了R1-Zero。这有力地证明了,在RL之前,通过SFT进行“行为塑造”是一种高效的训练策略。它将人类的逻辑和审美偏好“编码”进模型,为后续的强化学习指明了更优的进化方向。
R1训练第一步:SFT有监督微调流程
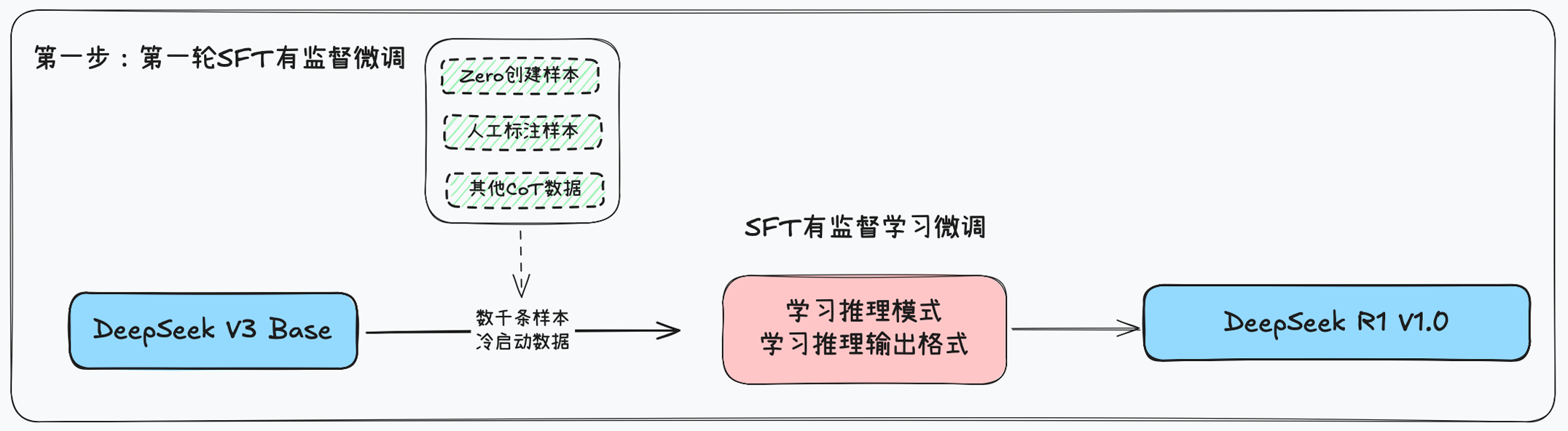
- 在DeepSeek-R1的训练中,第一步——有监督微调(SFT),扮演着至关重要的“地基”角色。它并非简单的数据投喂,而是一场精心设计的“行为塑造”过程,旨在将一个通用大模型,引导至推理能力的“起跑线”上。
- 第一次监督微调的过程,可以拆解为三环节:数据准备、模型微调和能力固化。
- 多源冷启动数据:冷启动数据集巧妙地混合三种不同类型的“冷启动数据”,包括Zero创建样本、人工标注样本、其他CoT数据。通过将这三者混合,模型从一开始就学会了在泛化、准确和深度思考之间取得平衡。
- SFT有监督微调:采用
DeepSeek-V3-Base作为基座模型,进行监督微调(SFT) 。模型通过模仿输入-输出对,学习:- 推理模式:学会像人类一样,面对复杂问题时,先分解步骤,再逐步推导,而不是直接“猜”答案。
- 输出格式:掌握一种清晰、结构化的表达方式,例如“先给出思维过程,再总结最终答案”,让输出内容更具可读性。
- 成果DeepSeek-R1 V1.0:经过微调训练,
DeepSeek-V3-Base升级为DeepSeek-R1 V1.0。它不仅能在数学、逻辑等任务上表现得更出色,其回答的结构和可读性也得到了质的飞跃。这个V1.0版本,就是DeepSeek-R1系列后续更高级训练(如强化学习)的坚实起点。
- SFT这一步的核心价值在于: 它通过少量、高质量、多维度的冷启动数据,高效地为模型“校准”了推理的“方向盘”和“油门”,为后续更复杂的自我进化(如强化学习)铺平了道路。
R1训练第二步:GRPO强化学习训练
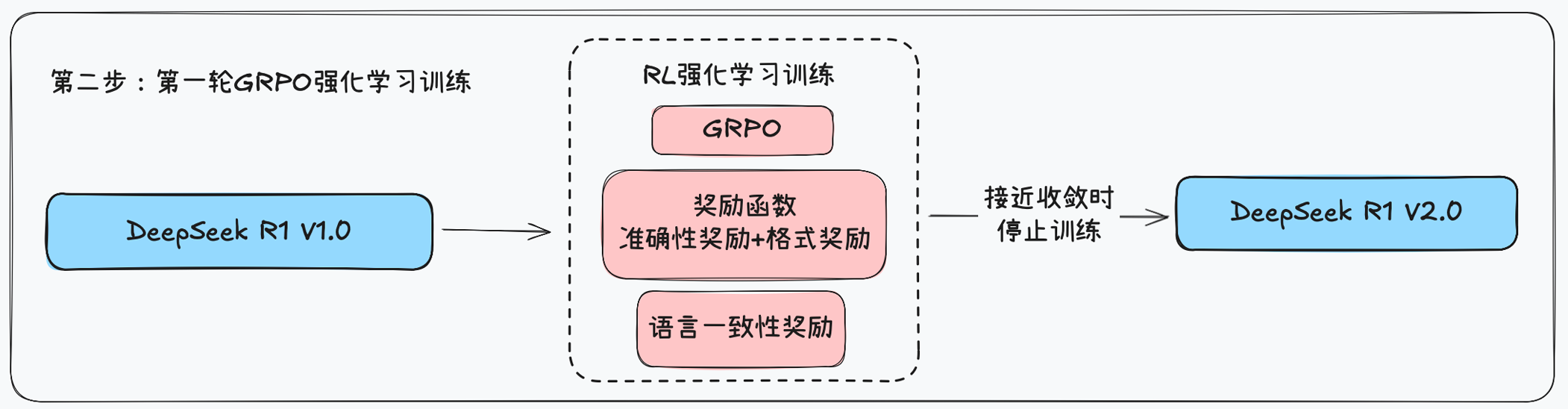
- 在通过冷启动数据为模型打下基础后,我们进入了训练的第二阶段:推理导向的强化学习(RL)。最终由
DeepSee R1 V1.0得到DeepSeek R1 V2.0。 - 这一阶段的目标很明确:将模型的推理能力推向极限。我们采用了与
DeepSeek-R1-Zero相同的大规模RL训练流程,专注于提升其在编码、数学、科学和逻辑推理等硬核任务上的表现。 - 挑战:RL带来的“语言混乱”:然而,纯粹的RL也带来了一个副作用:模型的思维链常常出现多语言混杂的现象,尤其是在处理多语言提示时,这严重影响了输出的可读性。
- 解决方案:引入“语言一致性奖励”: 为了解决这个问题,我们创新性地在奖励函数中引入了一个语言一致性奖励。它通过计算思维链中目标语言单词的比例,来鼓励模型用单一、清晰的语言进行思考。
- 这是一个典型的权衡:
- 代价:消融实验显示,这种约束会导致模型在部分推理任务上的性能有轻微下降。
- 收益:模型的输出变得更加符合人类偏好,可读性大大提升。
- 最终策略:最终将推理任务准确性和语言一致性奖励直接相加,形成了最终的奖励函数。引导模型在保持顶尖推理能力的同时,也学会了如何清晰、规范地表达,最终训练至收敛。
R1训练第三步:SFT微调微调
R1训练第三步:SFT微调微调数据集创建
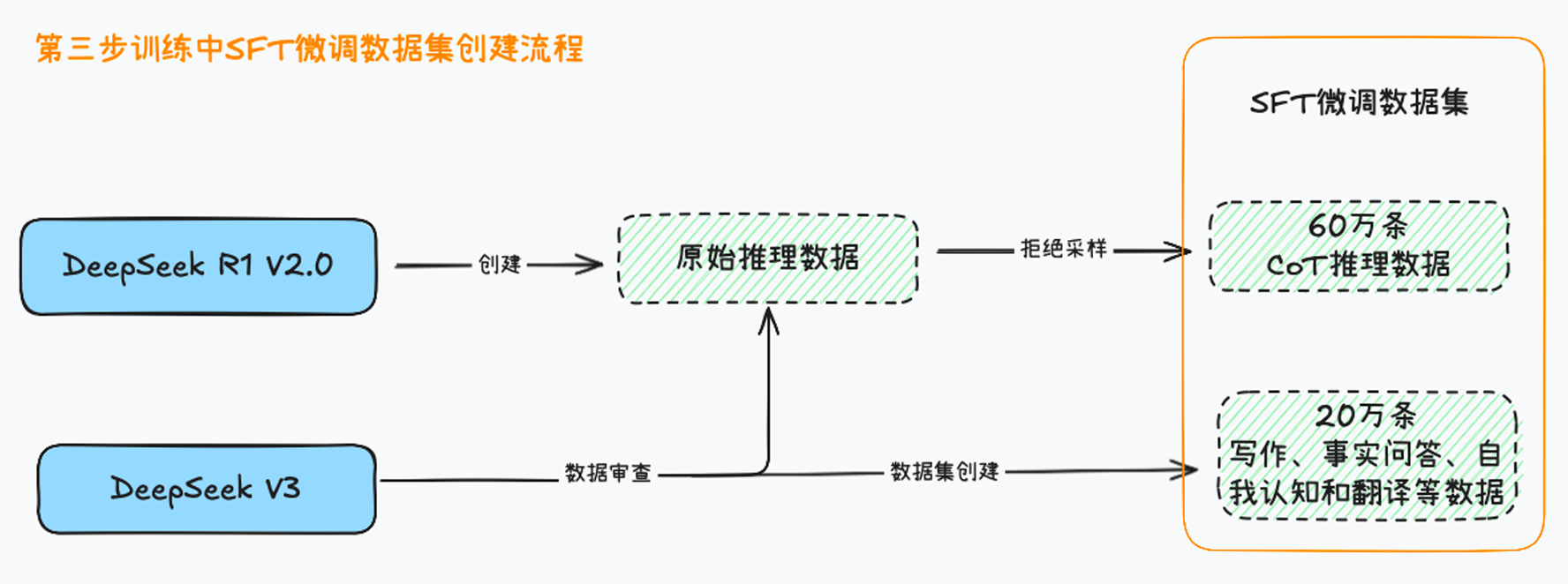
- 当面向推理的强化学习(RL)训练达到收敛时,产生的“学霸”模型,利用其来生成下一轮更优质的“教材”(SFT数据)。
- 这个阶段的目标是让模型从“推理专才”进化为“全能通才”。因此,我们的数据策略也分为两大板块:
-
推理数据:从“学霸”身上精炼“解题思路” 与最初的冷启动数据不同,这次的推理数据来源更高级、更精细:
- 来源:策划更复杂的推理提示,然后对RL训练出的最佳检查点进行拒绝采样。简单说,就是让“学霸”模型对同一道题生成多个答案,只“录取”那些完全正确的。
- 拒绝采样:一种数据筛选策略,通过生成多个候选响应,并依据一个预定义的评估标准(或“评判者”)来决定接受或拒绝每个候选,从而构建一个仅包含高质量样本的数据集。
- 扩展与评估:引入生成式奖励模型来评估的复杂数据,甚至让
DeepSeek-V3来当“裁判”,判断模型答案与真实答案的优劣。 - 质量过滤:为了确保可读性,严格过滤掉那些语言混杂、段落冗长或代码混乱的“病态”推理链。
- 成果:经过一系列“精挑细选”,获得了约60万条高质量的推理训练样本。
2。 无推理数据:补全通用能力的“拼图” 为了让模型不只是一个“解题机器”,我们为其注入了通用能力:
- 来源:复用
DeepSeek-V3在写作、事实问答、自我认知和翻译等领域的SFT数据。 - 智能融合:对于某些非推理任务,会先调用模型生成潜在的思维链,再让它回答问题,以增强其逻辑性。但对于“你好”这类简单查询,则不生成思维链,保持对话的自然流畅。
- 成果:收集了约20万条通用任务样本。
最终一步:融合
- 将这80万条(60万推理 + 20万通用)精心打磨的样本混合,用于
DeepSeek-V3-Base进行了两个周期的微调。
R1训练第三步:SFT微调微调流程
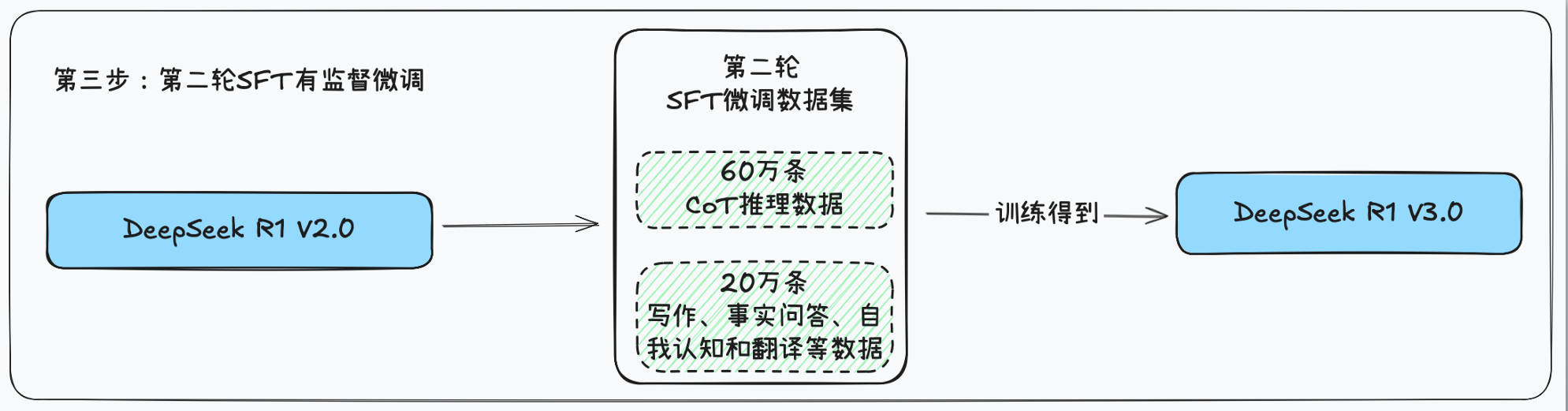
- 基于
DeepSeek R1 V2.0使用80万的混合数据集(推理数据集+非推理数据集),通过两周期SFT微调得到DeepSeek R1 V3.0 - 核心洞察:这个阶段是一个“用RL的成果来优化SFT,再用更优的SFT去支撑更强的RL”的完美闭环。它让模型不仅会“深度思考”,还学会了“清晰表达”和“广泛交流”,为最终成为顶尖模型奠定了坚实基础。
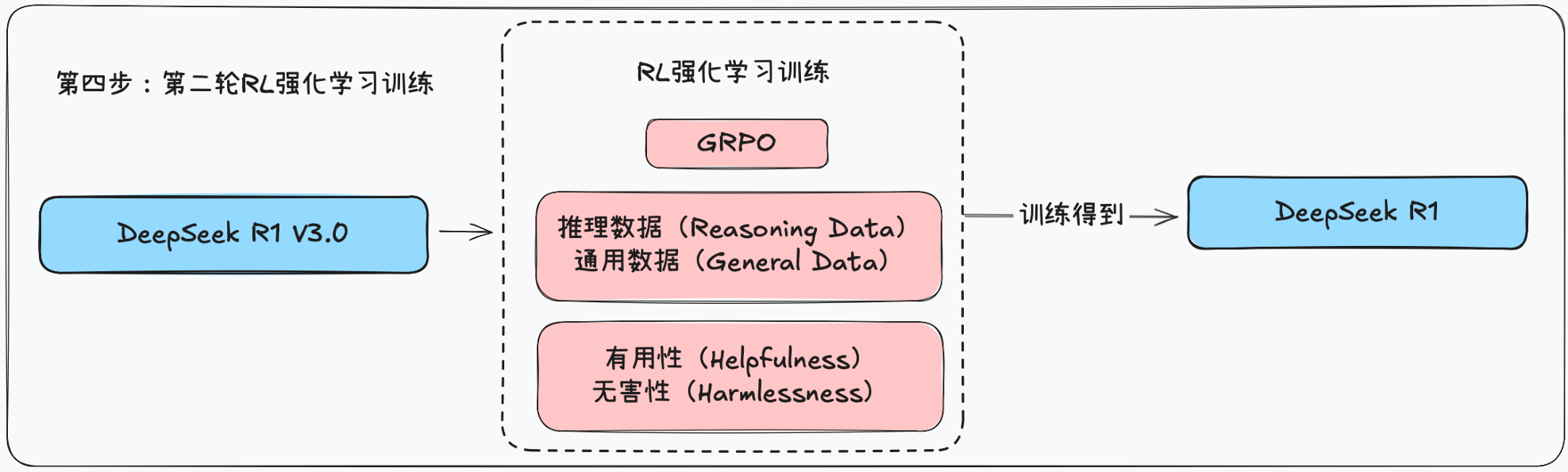
R1训练第四步:GRPO强化学习训练
- 此阶段目的:为了使模型对齐人类偏好,提升模型的有用性(helpfulness)和无害性(harmlessness),同时进一步优化推理能力。
- 训练方法:结合奖励信号(reward signals)和多样化提示分布(diverse prompt distributions)训练模型。
R1训练第四步:GRPO强化学习训练数据集
- 推理数据:遵循DeepSeek R1 Zero的方法,采用基于规则的奖励来引导数学、代码和逻辑推理领域的学习过程。
- 通用数据:对于广泛的任务,使用奖励模型捕捉人类在复杂和细微场景中的偏好。这部分训练基于DeepSeek V3训练流程,并采用类似的偏好对和训练提示分布。
R1训练第四步:GRPO强化学习训练奖励函数
- 有用性(Helpfulness):对在有用性训练中,专注于优化最终摘要,确保评估时关注回答的实用性和相关性,不会干扰底层的推理过程。
- 无害性(Harmlessness):在无害性训练中,评估整个模型的输出,包括推理过程和最终摘要,识别并缓解可能出现的风险、偏见或有害内容,确保模型生成的内容符合安全和伦理标准。
R1训练第四步:第二阶段GRPO训练流程
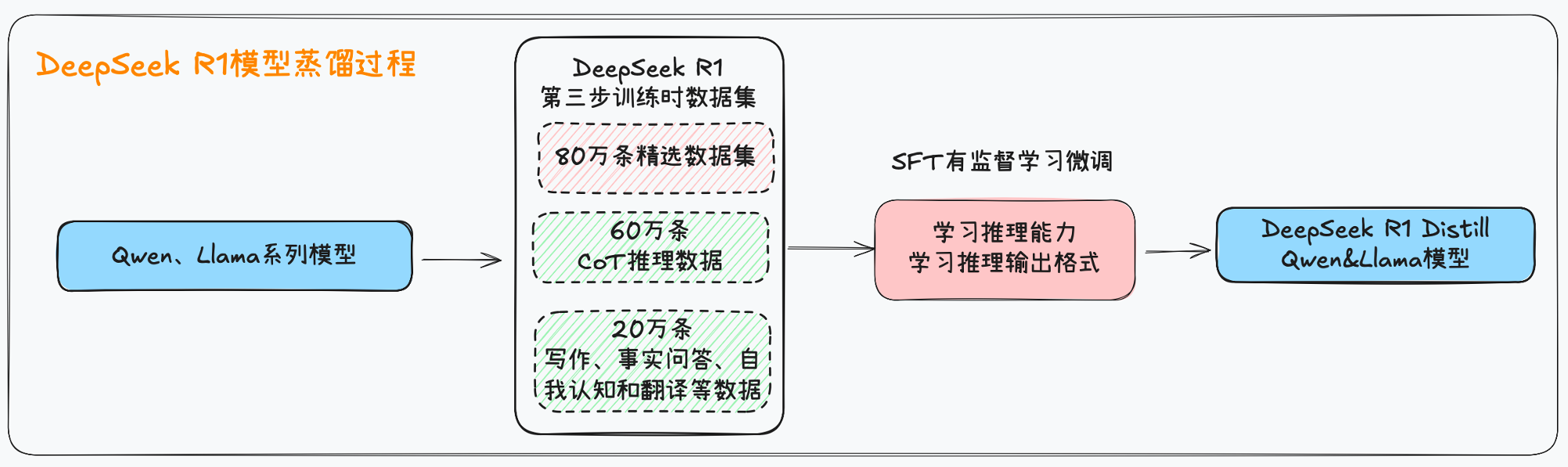
第三阶段实验:DeepSeek R1 模型蒸馏
- 为了将DeepSeek-R1的推理能力蒸馏到小型密集模型中,直接使用DeppSeek R1 V3和DeepSeek R1 V2.0共同整理的80万条数据,对开源模型(Qwen和Llama)进行微调。
- 使用的基座模型包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct。
- 对于蒸馏后的模型,仅使用监督微调,而未加入强化学习(主要目标是展示蒸馏技术的有效性)。
- 黑箱蒸馏:学生模型仅通过输入输出对来学习教师模型的行为,无需了解教师模型的内部结构和参数。
- 白箱蒸馏:学生模型不仅学习教师模型的输入输出对,还学习教师模型内部的结构和中间层输出(激活值、特征表示)。

















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









