







核心
- 一种基于潜扩散模型(Latent Diffusion Models, LDMs)的高分辨率视频生成方法,称为Video LDM。
- 通过在预训练的图像生成模型中引入时间维度,将其转化为视频生成模型,实现了高分辨率、长时间一致的视频合成。
- 在自动驾驶模拟和创意内容生成等领域展示了其应用潜力。
方法
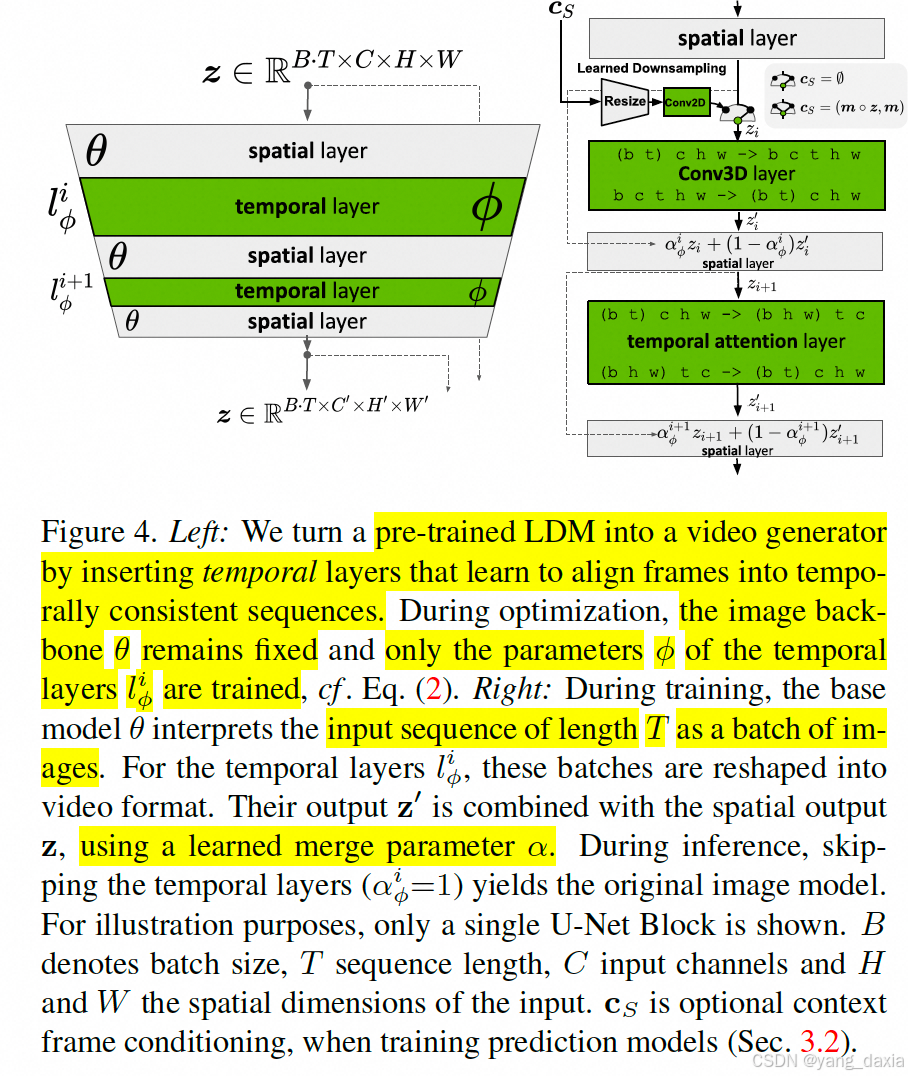
在已有的2d的生成模型基础上,插入conv3D和时间维度注意力机制。利用已有的图片生成模型的权重
- 预训练图像LDM:首先在大规模图像数据集上预训练一个LDM,学习图像的生成能力。
- 引入时间维度:通过在预训练的图像LDM中插入额外的时间层(temporal layers),这些时间层负责对齐图像序列,使其在时间上具有一致性。
- 时间对齐训练:固定预训练的图像生成部分,仅训练新引入的时间层,使其能够处理视频数据。
- 超分辨率模型的时间对齐:进一步对超分辨率扩散模型进行时间对齐,将其转化为视频超分辨率模型,以提高生成视频的空间分辨率。
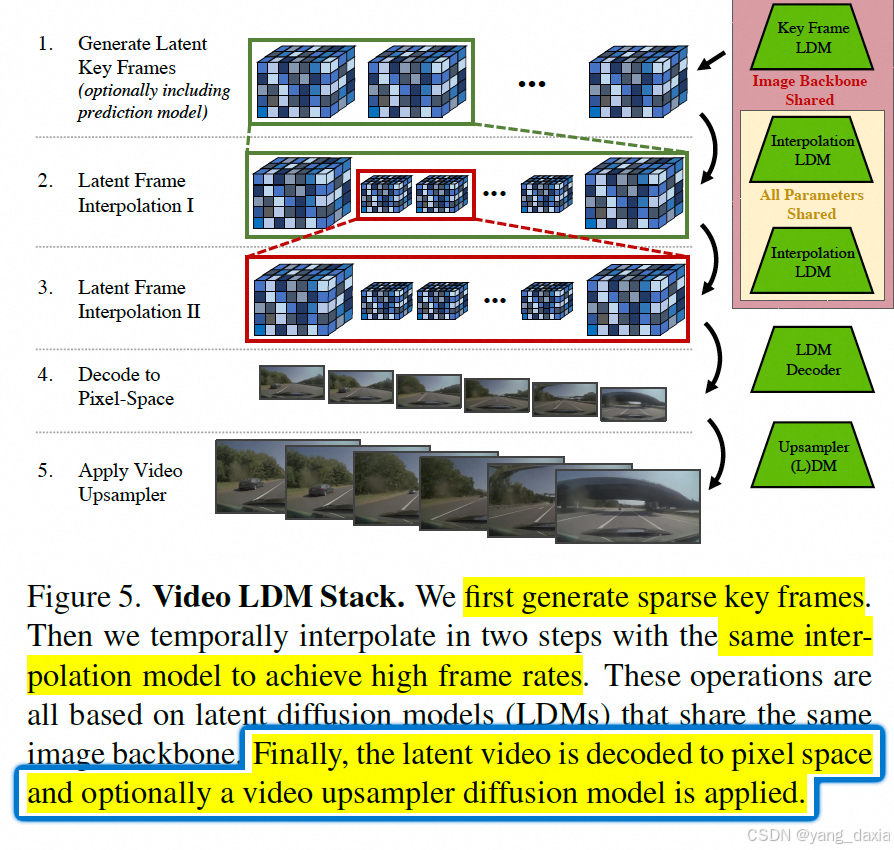
实验与结果
文章在两个主要任务上验证了Video LDM的性能:高分辨率真实驾驶场景视频合成和基于文本的视频合成(text-to-video)。
高分辨率驾驶视频合成
- 数据集:使用了一个包含683,060个视频的内部数据集,分辨率为512×1024,帧率高达30fps。
- 性能指标:使用帧级Fréchet Inception Distance(FID)和Fréchet Video Distance(FVD)进行评估。
- 结果:与之前的最佳方法Long Video GAN(LVG)相比,Video LDM在128×256分辨率下的FVD和FID指标均优于LVG。具体数值为:LVG的FVD为478,FID为53.5;Video LDM的FVD为389,FID为31.6。此外,Video LDM还支持条件生成,如根据日夜标签和场景拥挤程度生成视频。
- 用户研究:在用户偏好测试中,Video LDM生成的视频在真实感方面优于LVG,且条件生成模型的样本更受用户青睐。
文本到视频合成
- 数据集:使用WebVid-10M数据集,包含1070万视频-字幕对,总时长52,000小时。
- 性能指标:除了FID和FVD外,还评估了CLIP相似度(CLIPSIM)和视频初始分数(IS)。
- 结果:在UCF-101和MSR-VTT数据集上的零样本(zero-shot)文本到视频生成任务中,Video LDM的性能优于多个基线方法,但在某些指标上略低于Make-A-Video。具体数值为:在UCF-101上,Video LDM的IS为29.49,FVD为656.49;在MSR-VTT上,CLIPSIM为0.2848。
- 个性化文本到视频生成:通过DreamBooth技术,将Stable Diffusion的图像生成能力与特定对象的身份绑定,并将其转化为视频生成能力。实验表明,这种方法能够生成个性化的连贯视频,捕捉到DreamBooth训练图像的身份特征。
关键结论
- Video LDM通过在预训练的图像LDM中引入时间对齐层,有效地将图像生成模型转化为视频生成模型,同时保持了计算效率。
- 在高分辨率驾驶场景视频合成任务中,Video LDM达到了最先进的性能,并能够生成长达数分钟的视频。
- 在文本到视频合成任务中,Video LDM能够生成高质量、多样化的视频内容,并支持个性化生成。
- 该方法为自动驾驶模拟和创意内容生成等领域提供了新的可能性,未来有望进一步推动高分辨率视频生成技术的发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











